面对突发性的 Linux 系统宕机,运维人员和开发者们往往会感到头疼不已。传统方法需要深入分析复杂的内核日志和庞大的内存转储文件,整个过程不仅耗时费力,更对内核知识储备有极高的要求。现在,阿里云操作系统控制台的宕机智能诊断功能,正通过 AI 技术的融合应用,让这一复杂的分析流程变得前所未有的简单高效。这背后,是阿里云对运维与系统稳定性长期深耕的结晶,其经验与解决方案值得广大从业者参考。
传统宕机分析的“三座大山”
要理解新工具的价值,我们得先回顾下过去解决宕机问题时遭遇的那些典型挑战。
第一座大山:日志分析如同“看天书”
服务器宕机后,查看 dmesg 日志通常是第一步。然而,呈现在眼前的往往是下面这种令人困惑的信息片段:
[ 69518574.393036] Code: e8 38 ac e8 88 0b ff ff 0f 0b 48 c7 c7 d0 e8 38 ac e8 7a 0b ff ff 0f 0b 48 89 f2 48 89 fe 48 c7 c7 90 e8 38 ac e8 66 0b ff ff <0f> 0b 48 89 fe 48 c7 c7 58 e8 38 ac e8 55 0b ff ff 0f 0b 48 89 ee
[ 69518574.393070] RSP: 0018:ffffb0d3c0a3bb98 EFLAGS: 00010282
[ 69518574.393085] RAX: 0000000000000054 RBX: ffff9fbe07b158c0 RCX: 0000000000000000
[ 69518574.394079] RDX: ffff9fbeddf703e0 RSI: ffff9fbeddf5fb40 RDI: ffff9fbeddf5fb40
Kernel panic - not syncing: Fatal exception
这些对于大多数运维人员而言无异于天书,而真正的核心问题,往往就隐藏在数千行这样的日志之中,需要耗费大量时间进行人工排查。要有效分析 hardlockup、hungtask 等问题,你还需要对 CPU 调度、中断处理、自旋锁、进程状态转换等内核知识有深入理解。
第二座大山:VMCORE 分析耗时又费力
对于更复杂的问题,光看日志是不够的,通常需要获取 VMCORE(内存转储)文件进行深入分析。一个完整的 VMCORE 分析流程往往包括:
- 加载 VMCORE 文件到调试工具(如
crash 或 gdb)。
- 执行一系列复杂的调试命令,手动提取信息。
- 分析各种输出,尝试拼凑出问题的完整链条。
- 整个过程可能持续数小时甚至数天,对分析人员的系统底层认知是极大的考验。
第三座大山:找补丁如同“寻宝游戏”
好不容易定位到问题根源,寻找合适的修复补丁又是一项艰巨任务。Linux 内核 Git 仓库拥有三十多年的演进历史,超过百万次提交。人工从中筛选与特定问题相关的修复,不仅效率低下,而且极易遗漏关键信息。
这三大挑战使得传统宕机分析成本高昂。阿里云操作系统控制台(SysOM是其中的运维组件)推出的宕机智能诊断功能,正是为了攻克这些难关而生。
什么是宕机智能诊断?
宕机智能诊断是阿里云操作系统控制台提供的一项系统场景诊断功能。它基于大模型技术,深度融合了内核调试技术和海量故障案例,能够自动完成从日志解析、问题定位到补丁推荐的全流程,从而将原本复杂的宕机分析变得简单高效。
阿里云操作系统控制台地址:https://alinux.console.aliyun.com
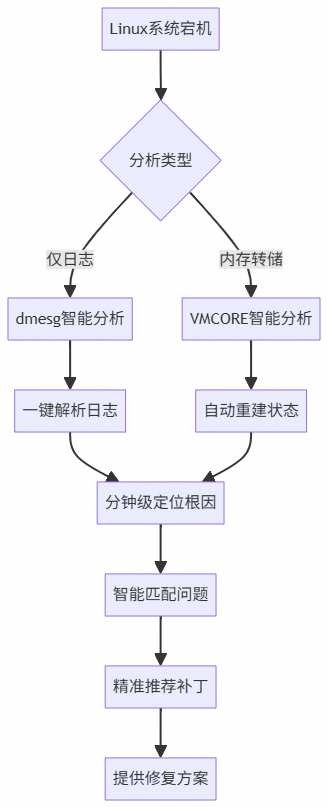
三大核心能力,直击痛点
1. 智能日志解析,告别“天书”
再也不用逐行研读复杂的内核日志了。宕机智能诊断的日志解析功能能自动提取关键信息,为后续的 AI 分析提供结构化的数据基础。
- 结构化信息提取:自动从日志中提取内核版本号、崩溃标题、进程名、函数名、RIP 寄存器值、CPU 编号、加载模块等关键字段。
- 调用栈分层解析:智能识别并分离 NMI 栈、IRQ 栈、任务栈三层调用关系,过滤无效函数,提取 top-3 关键函数调用链。
- 故障类型识别:支持 hardlockup、hungtask、memory_error、softlockup、hardware_error 等主流内核故障类型的快速判定。
- 错误日志聚合:自动按时间戳排序错误日志,过滤冗余调用栈信息,保留最关键的诊断线索。
实际效果:传统人工方式需要从数千行日志中大海捞针,而该系统能在秒级内完成日志解析和结构化提取,为 AI 诊断提供清晰的数据输入。
2. 专项诊断,精准打击
针对不同类型的内核问题,系统设计了专属的诊断能力,深度集成 drgn 内核调试器,可直接访问 VMCORE 中的内核数据结构,结合 AI 推理实现智能分析:
- Hardlockup 诊断:采用图遍历算法构建锁依赖图,自动检测循环等待和死锁场景,输出清晰的锁等待路径。
- Hungtask 诊断:实现链式追踪算法,从 D 状态进程开始逐级分析等待链,定位终端阻塞点,给出完整的资源等待路径。
- Memory Error 诊断:识别 use-after-free、空指针解引用、野指针等典型内存错误类型,追踪内存分配和释放路径。
- Softlockup诊断:分析调度延迟、CPU 占用模式,检测软锁和响应超时问题。
3. 智能补丁匹配,一步到位
系统采用混合向量检索技术进行补丁搜索。它首先将问题描述转换为向量,在面向 Linux 内核历史提交构建的向量数据库中进行语义相似度检索。
- 第一阶段-向量检索:快速从海量 commit 中召回 top-k 个最相关的候选补丁。
- 第二阶段-智能排序:利用大模型对每个候选补丁进行深度分析,评估其与当前问题的相关性(1-10分),并给出详细的原因说明。
系统支持按内核版本过滤,最终返回多个最相关的补丁,每个都包含 commit ID、摘要、评分和推荐理由。
实战效果:Hardlockup 死锁问题的智能诊断
以一个真实的生产环境 Hardlockup 故障为例。服务器突发系统无响应并崩溃,运维人员通过控制台发起诊断后,系统在5分钟内生成了完整的诊断报告。

报告包含了以下关键信息:
- 故障类型识别:自动判定为 Hardlockup 死锁问题。
- 死锁链路分析:识别出三方 CPU 间的循环等待关系,包括各 CPU 持有和等待的锁。
- 根因定位:指出导致死锁的关键代码路径和函数调用。
- 修复建议:提供 4 条针对性的缓解措施。
- 补丁推荐:从 Linux 内核百万级提交中检索出 3 个高度相关的补丁,按相关性排序并说明推荐理由。
对于此类复杂的多方死锁,传统人工分析通常需要数小时甚至数天,而宕机智能诊断在几分钟内就完成了从问题分析到补丁推荐的全流程。
快速上手:两种使用方式
宕机智能诊断支持 .rpm 包格式的主流 Linux 发行版,如 Alibaba Cloud Linux、CentOS、Anolis OS、Rocky Linux 等。
推荐方式:通过 SysOM MCP 使用(AI 助手集成)
SysOM MCP 是阿里云开源的系统诊断工具集,基于 Model Context Protocol 协议,将宕机智能诊断能力封装为标准化的 MCP 工具。你可以通过 AI 助手(如 qwen-code)用自然语言直接发起诊断。
项目地址:https://github.com/alibaba/sysom_mcp
配置完成后,在 AI 助手中可以这样使用:
示例 1:调用宕机智能诊断
请帮我分析一个宕机问题,vmcore 下载链接:https://path/to/your/vmcore
说明:
- API 接受 HTTP/HTTPS 下载链接,请确保链接有适当访问权限。
- 对于 Rocky Linux、AlmaLinux 等发行版,需额外提供 debuginfo 下载链接。暂不支持 .deb 包格式发行版(如 Ubuntu)。
示例 2:查询历史诊断任务
查看我最近 7 天的宕机诊断记录,并返回上一次的诊断结果
高阶方式:直接调用 OpenAPI 接口
如需集成到自动化运维系统,可直接调用 OpenAPI 接口。详细文档请参考:https://next.api.aliyun.com/api/SysOM/2023-12-30/CreateVmcoreDiagnosisTask
总结
借助 AI 技术与专业内核调试工具的深度融合,阿里云操作系统控制台的宕机智能诊断功能,正在让复杂的 Linux 宕机分析走出专家的“象牙塔”,成为每一位运维和开发者都能轻松使用的得力工具。它直面传统分析中的日志、内存转储、补丁匹配三大难题,实现了从分钟级定位根因到智能推荐修复方案的全流程自动化。在这个追求高效运维的时代,这样的工具无疑能让我们在面对系统突发故障时更加从容。如果你也想告别这些烦恼,不妨亲自体验一下,或许能让你的下一个不眠之夜变得更加平静。欢迎在 云栈社区 分享你的使用心得或探讨更多系统稳定性的实践。
 发表于 2026-2-6 02:42:51
|
查看: 181|
回复: 0
发表于 2026-2-6 02:42:51
|
查看: 181|
回复: 0
