最早关注我的读者可能还记得,我大概、应该、也许算是全球最早让 ChatGPT 开口“说话”的人之一。
那是在 ChatGPT 刚发布不久,技术圈开始为之沸腾的时候。我亲手写了一段代码,并录了个视频,让 ChatGPT 3.0 用语音回答“乔布斯和马斯克谁更厉害”这个问题。视频发到 B 站后,一天播放量就破了十万,公众号也因此涨了一万多粉丝,全是来要代码的。
后来,不少做硬件的朋友找上门来谈合作,有的甚至当天就飞到了北京,都想把这套“能说话的 AI”方案落地到产品里。
但我心里清楚,一来我的兴趣点不完全在这个方向,二来总觉得当时的技术方案从根本上就不对路。那套方案本质是“语音转文字 → LLM 处理 → 文字转语音”的串联管道,延迟高、体验割裂。最关键的是,AI在说话时完全“听不见”你在说什么,就像个单向喇叭。
虽然我当时还加入了一些同步检测的逻辑来模拟双向交互,但那并非真正的端到端原生能力,只是我一个周末捣鼓出来的实验品,技术深度有限。
那时我就在想,真正理想的交互方案应该是全双工的、端到端的:AI 应该能一边说一边听,就像人和人面对面聊天一样自然流畅,感知不中断。
而现在,MiniCPM-o 4.5 来了,它几乎完美地实现了我当年的设想。

更值得一提的是,面壁智能这次非常大度地将它完全开源了。
重新定义交互:什么是“全双工”?
首先,我们来厘清一个核心概念:全双工。
传统的多模态大模型,其交互模式更像使用“对讲机”。你必须按着通话键说完,松开,等待对方回应;对方说话时,你也听不见任何背景音。映射到AI交互上,就是“你说完 → AI处理 → AI回答”,在AI“说话”期间,它的视觉和听觉模块在逻辑上是关闭的,无法感知环境变化。
而 MiniCPM-o 4.5 实现的是原生全双工。这意味着模型在生成语音输出的同时,其视觉和听觉编码器仍在持续工作,实时接收并处理外界信息。
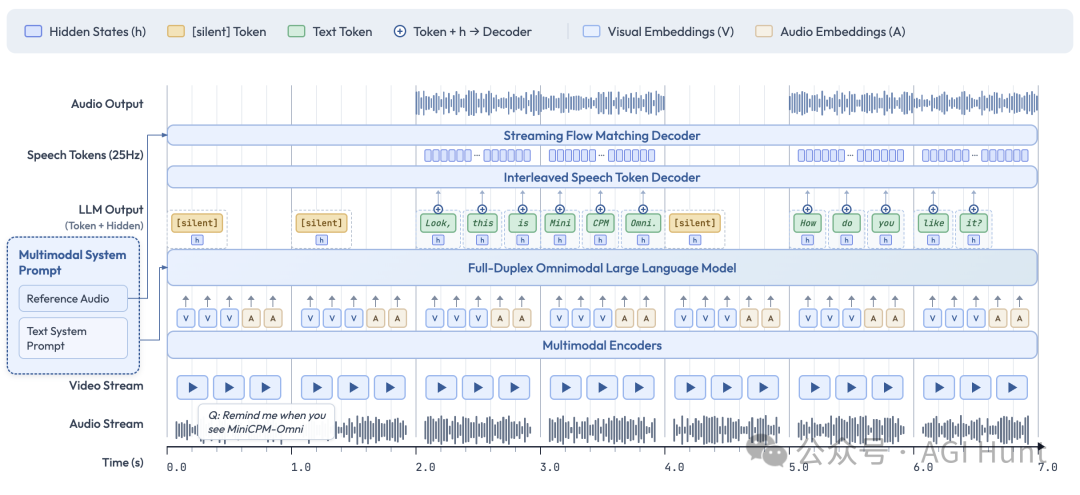
举个例子,你可以让它“帮我看一下电梯,到16层时告诉我”。在全双工模式下,它可以一边和你闲聊,一边持续观察电梯楼层的数字变化,并在目标楼层出现的瞬间,主动打断闲聊提醒你:“嘿,16层到了。”
这与市面上一些通过VAD(语音活动检测)等外部工程手段实现的“伪双工”有本质区别。后者仍是基于回合制的,只是通过工具让交互显得更流畅。MiniCPM-o 4.5则是在模型架构层面实现了感知不中断、交互零等待。
不止于响应:具备“主动性”的AI
除了全双工,MiniCPM-o 4.5 另一个颠覆性的能力是主动交互。
传统大模型严格遵守“一问一答”的范式,用户不提问,模型就保持沉默。但在真实的人类对话或协作场景中,一个得力的伙伴应该在合适的时机主动提供信息。
MiniCPM-o 4.5 能够根据环境信息的实时变化,自主决策对话策略。例如,在路口你让它“绿灯亮了就叫我”,它会持续观察交通信号灯,并在绿灯亮起的第一时间主动发出提醒,而不是被动等待你再次询问。
这背后是模型以 1Hz 的频率(每秒一次)自动判断当前是否应该发言。这种高频的实时决策能力,与全双工的持续感知能力相结合,共同构成了“主动提醒、主动评论”这类高级交互的基石。
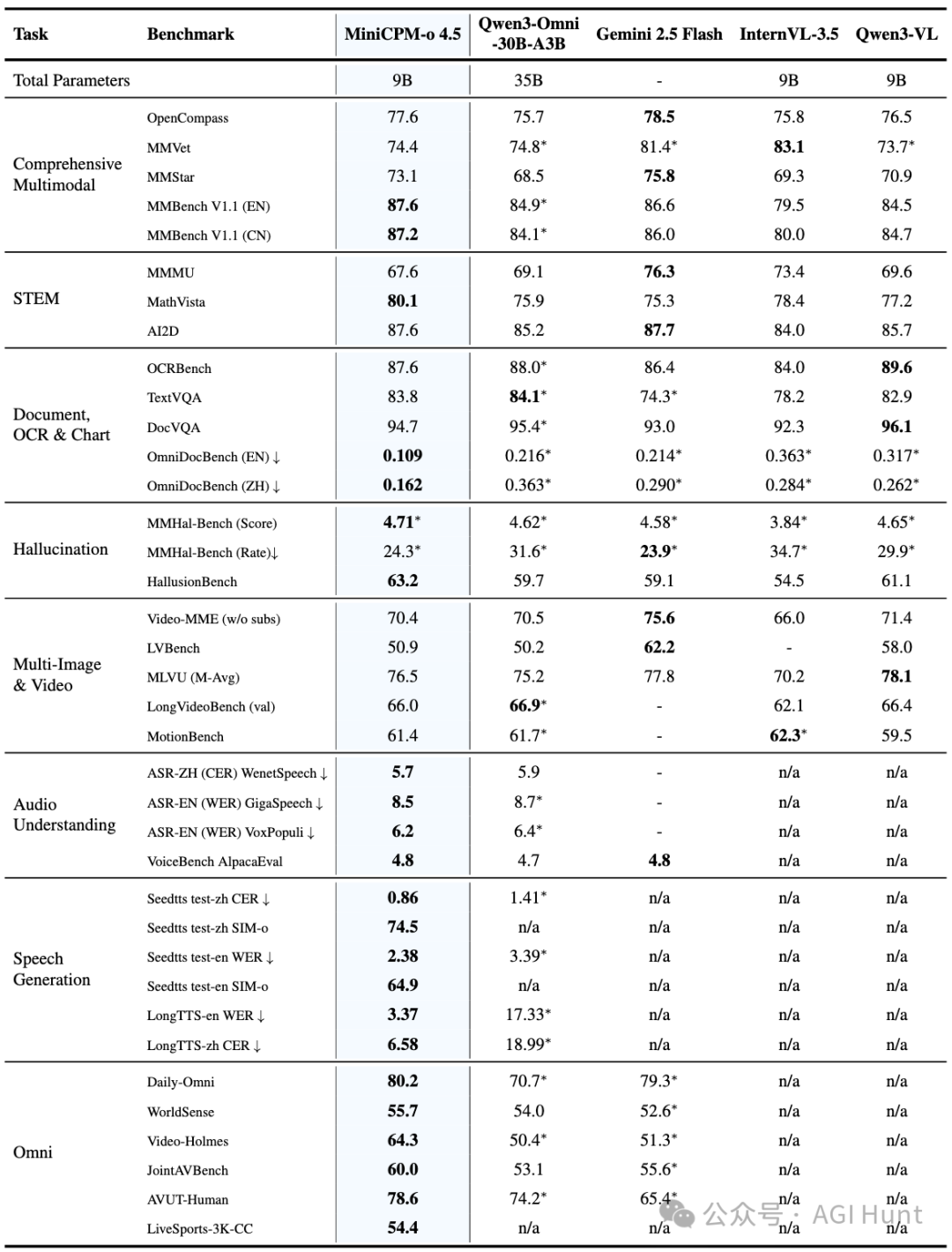
性能实测:小身材蕴含大能量
光有概念不够,硬指标才是试金石。根据官方发布的评测数据,MiniCPM-o 4.5 在多个维度表现惊人。
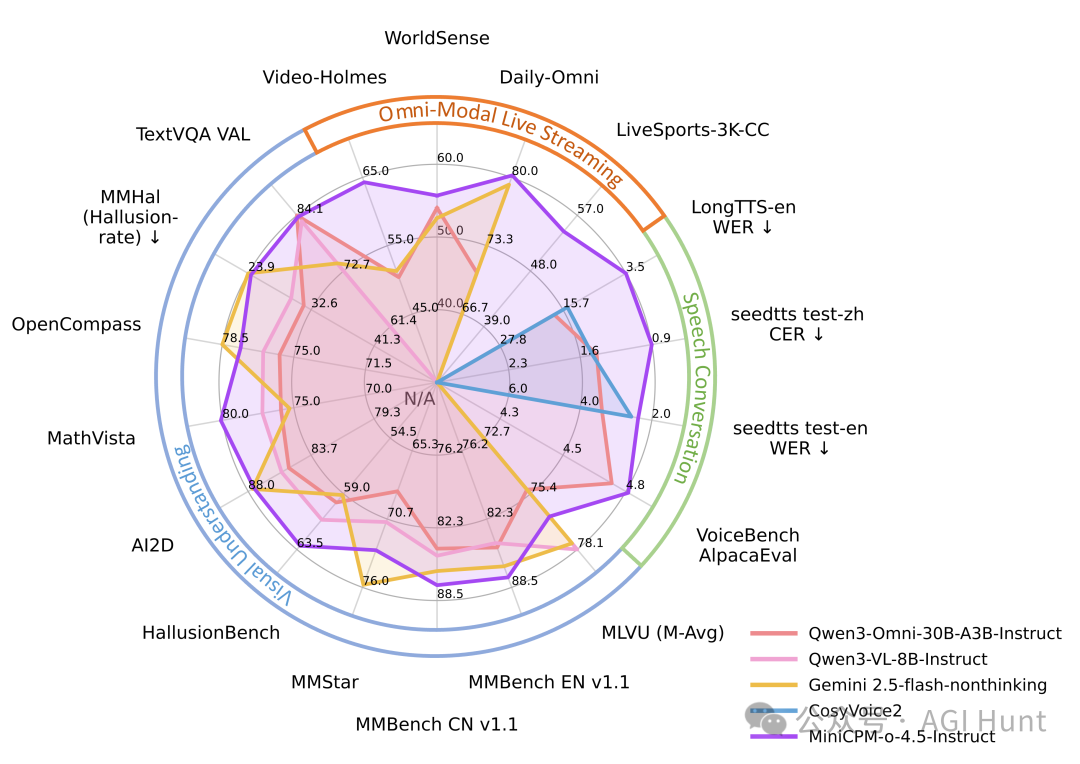
综合多模态能力
在权威评测集 OpenCompass 上,MiniCPM-o 4.5(9B)综合得分达到 77.6,表现超过了 GPT-4o 和 Gemini 2.0 Pro,直逼规模更大的 Gemini 2.5 Flash。
视觉理解(Instruct模式)
| 模型 |
OpenCompass |
MMBench EN |
MathVista |
MMMU |
| Gemini 2.5 Flash |
78.5 |
86.6 |
75.3 |
76.3 |
| MiniCPM-o 4.5 |
77.6 |
87.6 |
80.1 |
67.6 |
在 MMBench、MathVista 等核心视觉理解任务上,这个9B的“小钢炮”甚至拿下了多项第一。
语音生成质量
语音合成的准确性是自然对话体验的关键。在语音错误率评测上,MiniCPM-o 4.5 表现优异。
| 模型 |
seedtts test-zh CER↓ |
seedtts test-en WER↓ |
| CosyVoice2 |
1.45% |
2.57% |
| Qwen3-Omni |
1.41% |
3.39% |
| MiniCPM-o 4.5 |
0.86% |
2.38% |
其在长语音合成任务上优势更明显:英文长语音的 WER(词错误率)仅为 3.37%,而对比的 Qwen3-Omni 高达 17.33%。
推理效率与资源占用
9B 的参数量带来的不仅是性能,还有实实在在的部署优势。
| 模型 |
格式 |
解码速度 (tokens/s) |
首 Token 延迟 |
显存占用 |
| Qwen3-Omni (30B) |
int4 |
147.8 |
1.0s |
20.3GB |
| MiniCPM-o 4.5 |
bf16 |
154.3 |
0.6s |
19.0GB |
| MiniCPM-o 4.5 |
int4 |
212.3 |
0.6s |
11.0GB |
可以看到,即使在 bf16 全精度下,MiniCPM-o 4.5 的解码速度也很快,首 Token 延迟低至 0.6 秒。经过 int4 量化后,显存占用仅需 11GB,这使得在消费级显卡(如 RTX 4070)上本地部署成为可能。
对于希望深入探索多模态和Transformer架构的开发者来说,如此高效的模型无疑是一个绝佳的开源实战研究对象。
快速上手:部署与全双工推理代码
MiniCPM-o 4.5 提供了多种部署方式,支持 llama.cpp、Ollama、vLLM、SGLang 等主流推理框架。
1. 基础环境安装
pip install "transformers==4.51.0" accelerate "torch>=2.3.0" "minicpmo-utils[all]>=1.0.2"
2. 模型初始化与转换全双工模式
import torch
from transformers import AutoModel
model = AutoModel.from_pretrained(
"openbmb/MiniCPM-o-4_5",
trust_remote_code=True,
attn_implementation="sdpa",
torch_dtype=torch.bfloat16,
init_vision=True,
init_audio=True,
init_tts=True,
)
model.eval().cuda()
# 初始化TTS模块
model.init_tts(streaming=False)
# 关键一步:转换为全双工推理模式
duplex_model = model.as_duplex()
3. 全双工流式推理示例
以下代码展示了如何处理一段视频流,实现边看、边听、边说的全双工交互。
from minicpmo.utils import get_video_frame_audio_segments
# 提取视频的帧和音频片段
video_path = "your_video.mp4"
video_frames, audio_segments, stacked_frames = get_video_frame_audio_segments(
video_path, stack_frames=1, use_ffmpeg=True
)
# 准备全双工会话
ref_audio = None # 可提供参考音频以克隆音色
model.prepare(
prefix_system_prompt="Streaming Omni Conversation.",
ref_audio=ref_audio,
)
# 流式处理每个视频/音频片段
for chunk_idx in range(len(audio_segments)):
audio_chunk = audio_segments[chunk_idx]
frame_list = [video_frames[chunk_idx]] # 当前帧
model.streaming_prefill(audio_waveform=audio_chunk, frame_list=frame_list)
result = model.streaming_generate(max_new_speak_tokens_per_chunk=20)
# 根据模型决策输出结果
if result["is_listen"]:
print("模型正在聆听...")
else:
print(f"模型发言 > {result['text']}")
# result['audio_waveform'] 包含生成的语音波形数据
面壁智能还同步开源了 llama.cpp-omni 推理框架,配合 WebRTC Demo,可以在 MacBook 等本地设备上直接体验低延迟的全双工全模态对话。详细的部署指南和踩坑心得,都可以在云栈社区的技术板块找到分享。
社区反响与未来展望
模型一经发布,便在开发者社区中引发了热烈讨论。
许多开发者认为这是“开源社区的一个重要里程碑”。正如一位网友所说:“这不仅仅是多模态,这是真正的自然交互。全双工的看、听、说同时进行,还能主动提醒,感觉是迈向类人感知的第一步。”
的确,MiniCPM-o 4.5 带来的不仅是能力叠加,更是一种交互范式的改变。它从“你问我答”的回合制,转向了“同步感知、实时协作”的连续体。
9B 的参数量被广泛认为是一个“甜点级”尺寸。它足够小,可以塞进端侧设备,让实时交互成为可能;又足够大,能够承载复杂的多模态理解与生成任务。这意味着,无论是人工智能研究者、机器人开发者,还是普通极客,都有了在本地硬件上探索下一代人机交互的可能。
总结:推开一扇新的大门
MiniCPM-o 4.5 的开源意味着什么?
当科技巨头们还在为多模态实时交互设置技术壁垒时,面壁智能直接开源了“原生全双工”这一核心能力。

从今天起,开源社区第一次拥有了真正能“边看边听边说”的全模态模型底座,而不再是依靠外挂工具拼凑出的“伪双工”方案。
9B 的尺寸为它在端侧场景的应用打开了广阔天地:具身智能机器人、智能汽车座舱、个人电脑助手,甚至物联网设备。这些场景一直渴望一个能理解环境、实时沟通、自主交互的“大脑”,MiniCPM-o 4.5 有望补上这块关键的拼图。
当然,它目前并非完美。部署流程对新手仍有一定门槛,需要固定特定版本的 transformers,全双工模式依赖 FFmpeg 等外部工具。但作为一项刚刚开源的前沿技术,我们有理由相信生态会快速完善。
或许,一个更自然、更高效、更智能的人机协同新时代,真的就此拉开了序幕。
相关资源
 发表于 2026-2-6 05:24:32
|
查看: 220|
回复: 0
发表于 2026-2-6 05:24:32
|
查看: 220|
回复: 0
