本文首发于Ressmix个人站点:https://www.tpvlog.com
引言
在系统性能优化的道路上,我们通常会先考虑从存储层面入手,比如读写分离和分库分表。但计算能力呢?当单台服务器的处理能力到达天花板,无论怎么优化硬件都无济于事时,我们就需要构建高性能集群来提升系统的整体吞吐量。
高性能集群的核心思想很简单——增加服务器数量。但其设计复杂度,往往就体现在如何将任务合理、高效地分配到集群中的每一台服务器上。这个负责分配任务的关键角色,就是我们今天要深入探讨的负载均衡器。
常见的负载均衡系统主要分为三大类:DNS负载均衡、硬件负载均衡和软件负载均衡。它们各自扮演着不同的角色,也适用于不同的场景。在许多成熟的后端 & 架构实践中,这三种方式常常被组合使用,以构建层次化、高可用的服务架构。下面,我们先来逐一拆解它们。
三种常见的负载均衡机制
DNS负载均衡
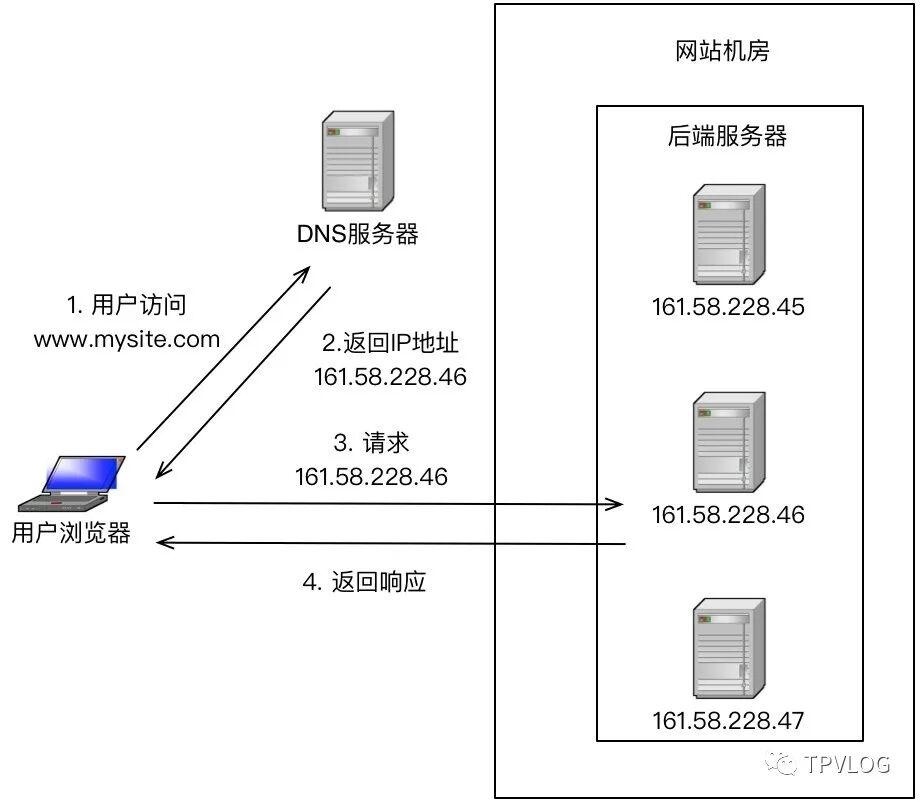
DNS负载均衡是最简单、也最常见的一种方式,通常用于实现地理级别的流量调度。举个例子,让北方用户访问北京的机房,南方用户访问上海的机房。它的工作原理并不复杂:DNS服务器在解析同一个域名时,可以根据请求者的地理位置等信息,返回不同的IP地址。
例如,当你访问 www.baidu.com 时,北方的用户可能拿到的是北京机房的IP(如61.135.165.224),而南方的用户拿到的则是上海机房的IP(如14.215.177.38)。
下面是DNS负载均衡的简单工作流程示意:
优点:
- 实现简单,成本低:无需自研或维护专门的负载均衡设备,直接利用现有的DNS服务。
- 就近访问:通过将用户引导至最近的机房,可以有效降低网络延迟,提升访问速度。
缺点:
- 生效延迟:DNS记录存在多级缓存,修改配置后不会立即对所有用户生效,可能导致部分用户访问失败。
- 控制权受限:负载均衡策略受制于域名服务商,难以根据自身业务特点进行深度定制和功能扩展。
- 策略简单:支持的负载均衡算法有限,且无法感知后端服务器的实时状态(如CPU、负载、连接数等),无法做到真正的智能调度。
硬件负载均衡
硬件负载均衡,顾名思义,是通过专用的硬件设备来实现负载均衡功能,你可以把它看作是一种特殊的网络设备。业界知名的代表有F5和A10。这类设备性能强悍、功能全面,但价格也相当昂贵,通常是大型企业或对性能有极致要求的核心业务才会考虑。
优点:
- 功能强大:支持从网络层到应用层的全方位负载均衡,算法丰富,并能实现复杂的全局负载均衡策略。
- 性能卓越:硬件加持下,并发支持能力可达百万级别,远超软件方案。
- 高稳定性:作为成熟的商用产品,经过严格测试和大规模实践验证,稳定性极高。
- 安全性集成:除了负载均衡,通常还集成了防火墙、防DDoS攻击等安全功能。
缺点:
- 昂贵:购置和维护成本高。
- 不够灵活:定制化开发相对困难,功能扩展依赖厂商。
软件负载均衡
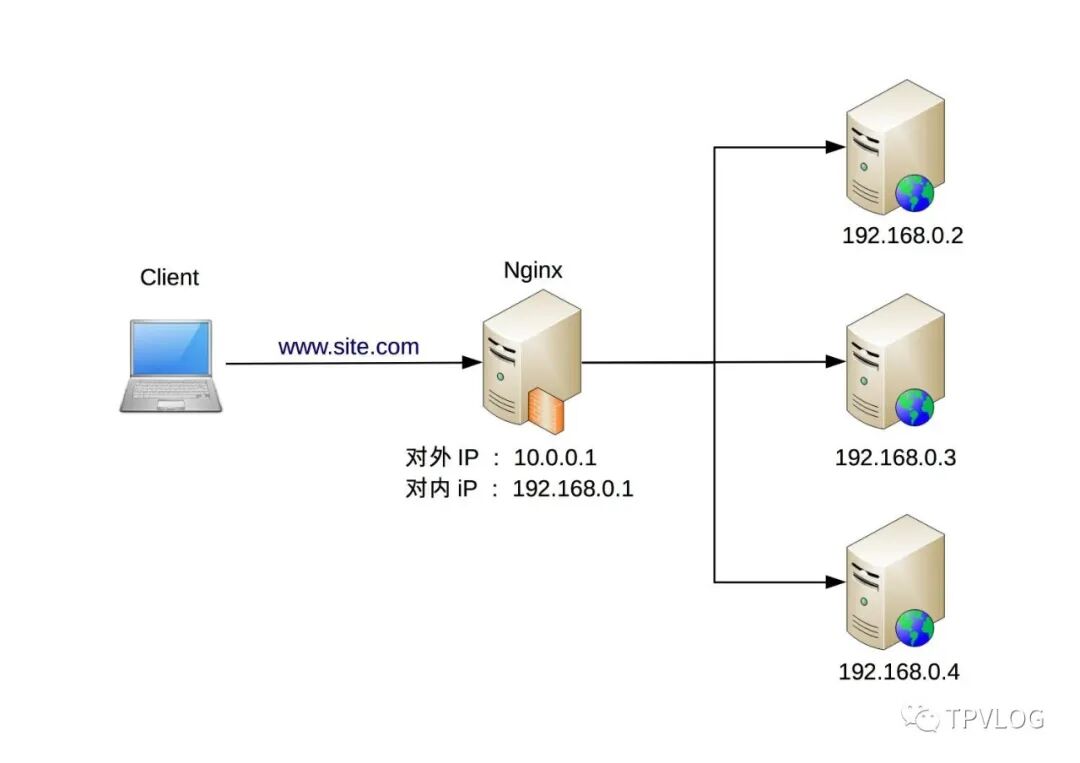
软件负载均衡通过在服务器上安装专门的软件来实现,是目前互联网公司中最主流的方案。其中最著名的两个代表是 Nginx(应用层,7层负载均衡)和 LVS(网络层,4层负载均衡)。
下图展示了一个典型的Nginx作为软件负载均衡器的架构:
4层与7层的区别:简单来说,4层(传输层)负载均衡基于IP和端口进行转发,不关心应用协议,几乎对所有应用都通用(如数据库、自定义协议服务)。7层(应用层)负载均衡则能解析HTTP等应用层协议,可以根据URL、Header等信息进行更精细化的路由,但性能开销相对稍大。
优点:
- 成本低廉:开源软件,只需准备标准的Linux服务器即可部署。
- 简单灵活:部署和维护相对简单,并且可以根据业务需求选择4层或7层模式,通过插件或模块进行功能扩展。
- 性能足够:对于绝大多数业务场景,Nginx(万级并发)和LVS(十万级并发)的性能已完全足够。
缺点:
- 性能上限:相比顶级硬件设备,性能存在上限。
- 额外工作:像防火墙、高级安全防护等功能需要自行集成或通过其他方案解决。
负载均衡的层次化架构
我们介绍了三种负载均衡机制,每种都有其优缺点。但在实际的大型系统设计中,我们往往不会只选择其中一种,而是根据它们的特点进行组合使用,形成多层次的负载均衡架构。一个通用的组合原则是:
- DNS负载均衡:用于实现地理级别的负载均衡(用户->最近机房)。
- 硬件负载均衡:用于实现集群级别的负载均衡(机房入口->内部集群)。
- 软件负载均衡:用于实现机器级别的负载均衡(集群入口->具体服务器)。
下面我们通过一个假想的实例来直观感受这种层次化架构:
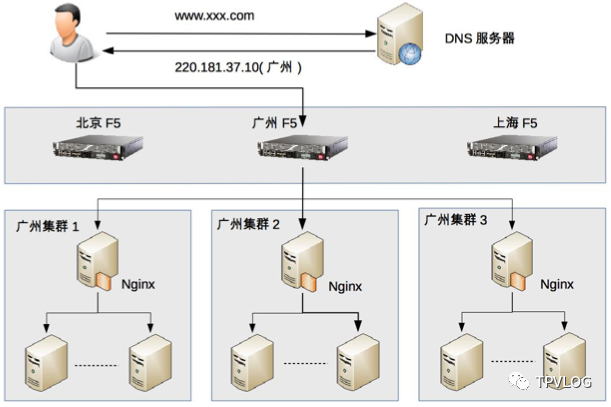
如图所示,整个请求的流转过程分为三层:
- 地理级别负载均衡:用户访问
www.xxx.com,DNS根据其IP判断地理位置,返回广州机房的入口IP 220.181.37.10。
- 集群级别负载均衡:请求到达广州机房入口的F5设备,F5根据策略将请求分发到该机房内的某个具体集群,例如“广州集群2”。
- 机器级别负载均衡:“广州集群2”入口的Nginx服务器收到请求,按照既定算法,将请求转发给集群内的一台应用服务器进行处理并返回响应。
重要提示:上图展示的是一个面向海量用户、跨地域部署的大型业务架构。对于普通的内部管理系统或中小型项目,完全不必如此复杂,很可能只需要一个Nginx做简单的反向代理和负载均衡就足够了。架构设计一定要匹配业务的实际规模与需求。
负载均衡算法详解
负载均衡器如何决定把下一个请求分给谁?这就依赖于负载均衡算法。根据算法的目标,我们可以将它们分为以下几大类:
- 任务平分类:追求绝对或加权意义上的公平分配。
- 负载均衡类:根据服务器的实时负载(CPU、连接数等)进行分配。
- 性能最优类:追求最快的用户响应,将请求分配给响应时间最短的服务器。
- Hash类:保证同一类请求总是落到同一台服务器,常用于会话保持。
接下来,我们详细看看几种最常见的算法。
1. 轮询
这是最简单的算法,负载均衡器将请求按顺序依次分配给后端服务器列表中的每一台。它完全不关心服务器的状态,实现简单。但如果某台服务器宕机,需要负载均衡器能够及时检测并将其从列表中剔除,否则会导致部分请求失败。
2. 加权轮询
这是轮询算法的增强版。它给每台服务器分配一个权重(通常根据CPU核数、内存大小等硬件配置静态设定),权重高的服务器被分配到的请求比例也更高。这解决了服务器处理能力不均的问题,但和普通轮询一样,依然无法感知服务器的实时状态。
3. 最小连接数(负载最低优先)
负载均衡器会实时追踪每台服务器当前的活跃连接数,并将新请求分配给连接数最少的服务器。这相当于认为连接数越少,服务器压力越小,是一种动态感知服务器状态的策略。
在4层负载均衡(如LVS)中,这通常是核心算法。在7层,虽然Nginx标准版不直接支持,但可以通过扩展实现类似的思路,例如跟踪HTTP请求数。如果自己设计算法,还可以根据业务类型选择核心指标,如CPU密集型服务看CPU负载,I/O密集型服务看I/O利用率。
这种算法的代价是复杂度高:负载均衡器需要持续收集和计算所有后端服务器的状态数据,这个收集过程本身就有开销。同时,状态统计的采样频率(是看1分钟负载还是15分钟负载)也需要根据业务特点仔细权衡。
4. 最快响应时间(性能最优优先)
这个算法从客户端体验出发,负载均衡器会记录请求的历史响应时间,并将新请求分配给平均响应时间最短的服务器。其本质也是通过外部指标(响应时间)来感知服务器状态。
它的复杂度和“最小连接数”算法类似,甚至更高,因为统计和分析响应时间本身消耗较大。为了降低开销,可能需要采用抽样统计,但这又引入了采样率如何设置的新问题。
5. Hash类算法
这类算法的目的不是均衡,而是“绑定”。通过对请求中的某个关键信息(如源IP地址、Session ID、用户ID)进行Hash计算,将相同Hash结果的请求总是发送到同一台服务器。
这主要服务于有状态业务的场景。例如:
- 源地址Hash:保证来自同一客户端的请求总落到同一台服务器,便于在服务器内存中维持会话状态(如临时购物车)。
- Session ID Hash:基于会话ID进行绑定,能达到和源地址Hash相同的效果,且更准确(在客户端IP变化时仍有效)。
总结
负载均衡是构建高并发、高可用分布式系统的基石技术。本文系统梳理了从DNS、硬件到软件的三种实现方式,解析了如何将它们组合成高效的层次化架构,并深入介绍了常见的负载均衡算法及其适用场景。
对于绝大多数开发者而言,软件负载均衡器,尤其是Nginx和LVS,是我们最需要掌握和深入理解的工具。它们的灵活性和足以应对海量并发的性能,使其成为互联网云栈社区中各类技术架构的标配组件。理解其背后的原理与算法,能帮助我们在实际工作中做出更合适的技术选型和配置,真正驾驭好流量,让集群的每一份算力都发挥出最大价值。
 发表于 2026-2-7 03:38:56
|
查看: 185|
回复: 0
发表于 2026-2-7 03:38:56
|
查看: 185|
回复: 0
