AI圈在新年初就打响了双响炮——Anthropic刚刚发布了Claude Opus 4.6,OpenAI也紧随其后,推出了GPT-5.3-Codex。后者已经在Codex应用里上线。这两个重磅模型的同步登场,让我们不得不立刻审视它们在各项基准测试中的表现,探讨其强化了哪些能力,以及除了模型本身,这次更新还带来了哪些值得关注的生态变化。
基准测试表现速览
Anthropic这次为Opus系列模型首次引入了100万tokens的上下文窗口。在MRCRv2(大海捞针)测试中,其表现相比Sonnet 4.5提升了57个百分点,这巨大的记忆能力提升,让人忍不住想立刻在相关人工智能应用场景中体验一番。
除了记忆能力,Opus 4.6在GDPval-AA(一项涵盖44个不同岗位知识工作任务的测评)上的得分也超越了GPT-5.2超过200分,预示着它在多任务协作工具中的潜力将进一步释放。
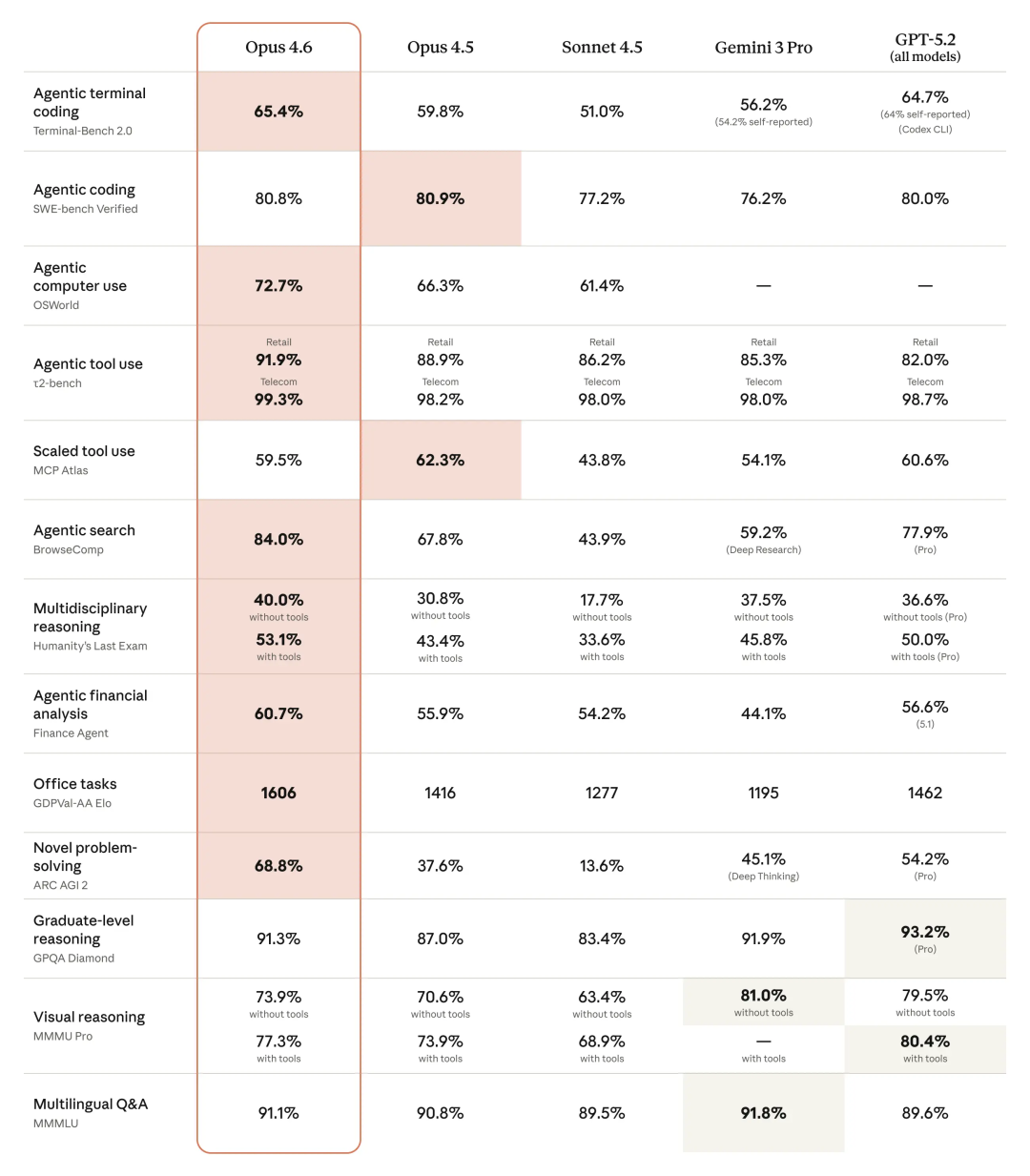
另一方面,新发布的GPT-5.3-Codex定位为编程模型,它融合了GPT-5.2-Codex的编码能力和GPT-5.2的推理与专业知识,官方称其速度提升了25%。更令人印象深刻的是,它在OSWorld-Verified(视觉桌面操作)基准上的表现,相比前代提升了近30个百分点,这个进步幅度相当显著。
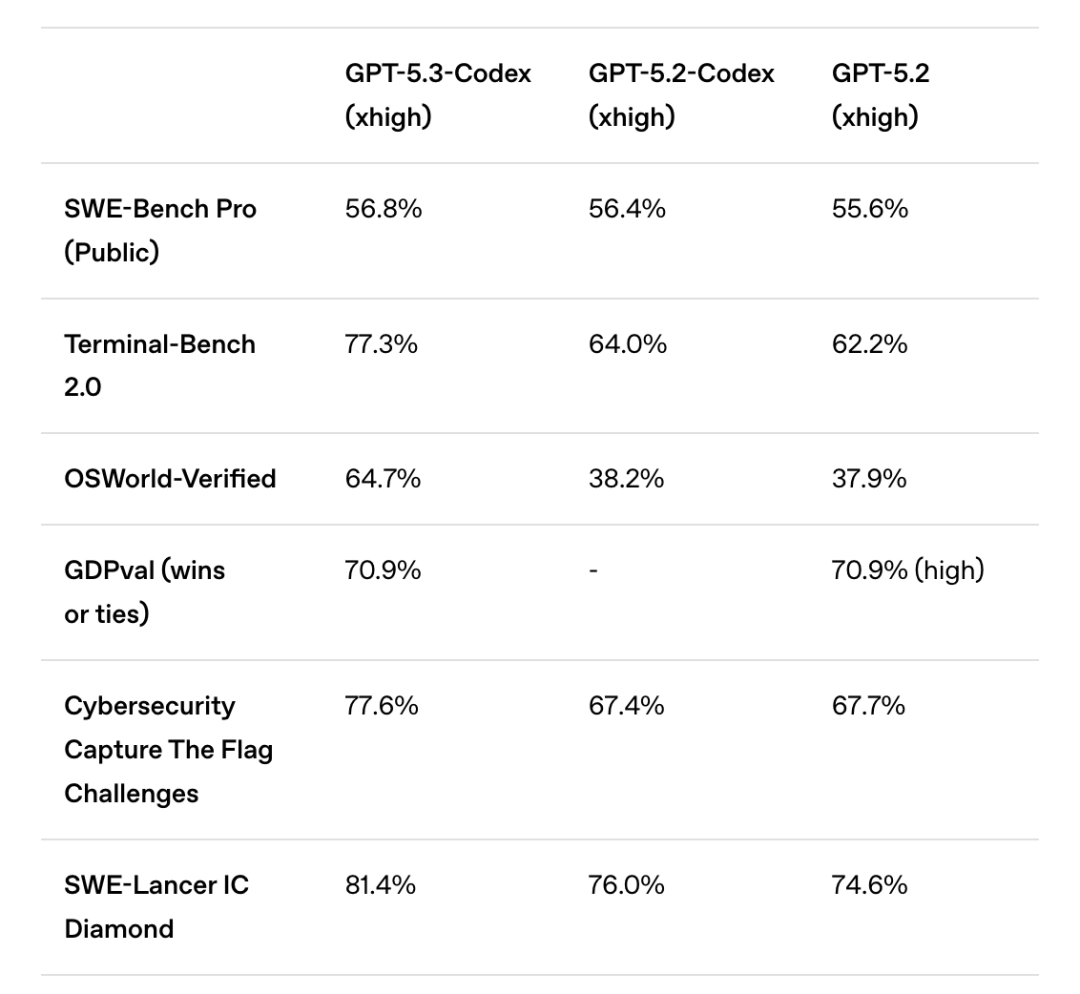
仔细对比两家官方放出的数据表格,会发现它们直接重合的数据集只有一个——Terminal-Bench 2.0(在终端命令行中进行编程的测试)。仅看这一项,GPT-5.3-Codex以高出约12个百分点的优势,表现优于Claude Opus 4.6。
不过,其他展示的数据不能简单地进行横向对比。例如,在SWE-Bench(智能体编程)数据集上,OpenAI使用的是包含了四种语言的Pro版本,而Claude Opus 4.6测评的SWE-Bench Verified只测试Python。同样,OpenAI测试的OSWorld-Verified相比Claude测试的OSWorld,由于修复了300多个数据问题,其结果也更具可信度。
我们还是分别看看它们各自突出的单项能力。
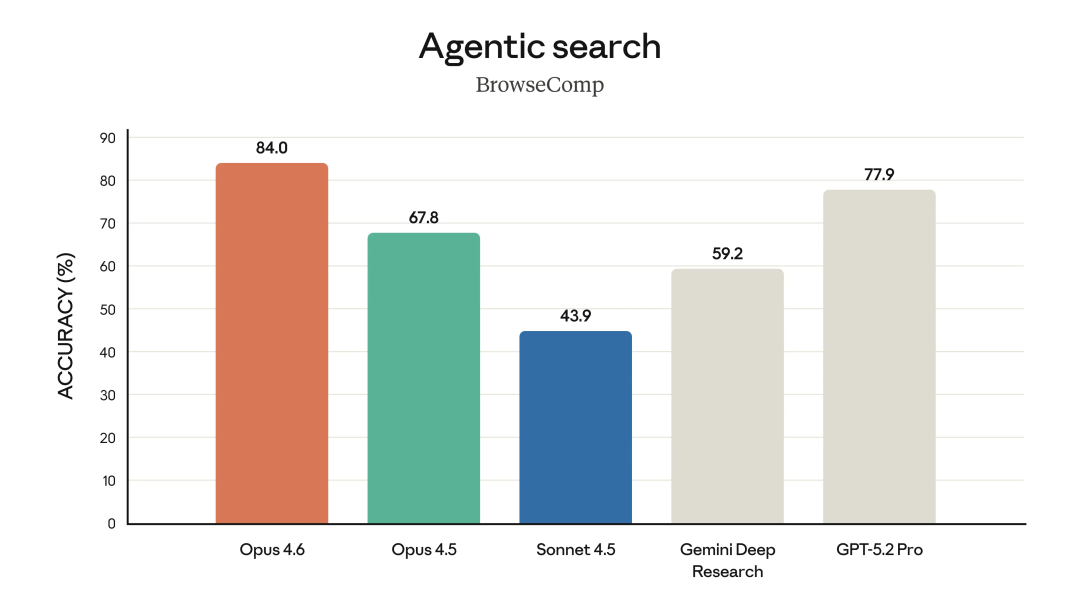
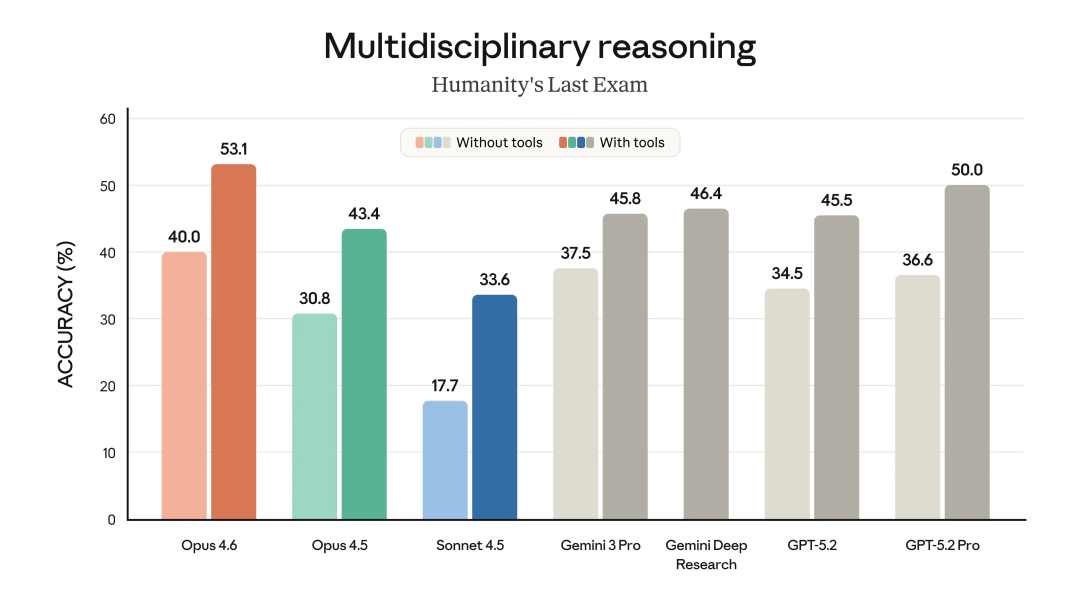
Claude Opus 4.6在高难度的Agent搜索(DeepSearchQA / BrowseComp)上,单智能体表现比GPT-5.2 Pro高出6个百分点。在多学科推理(Humanity‘s Last Exam / ARC AGI 2)测试中,在工具配置拉满的情况下,也比GPT-5.2 Pro高出3个百分点。
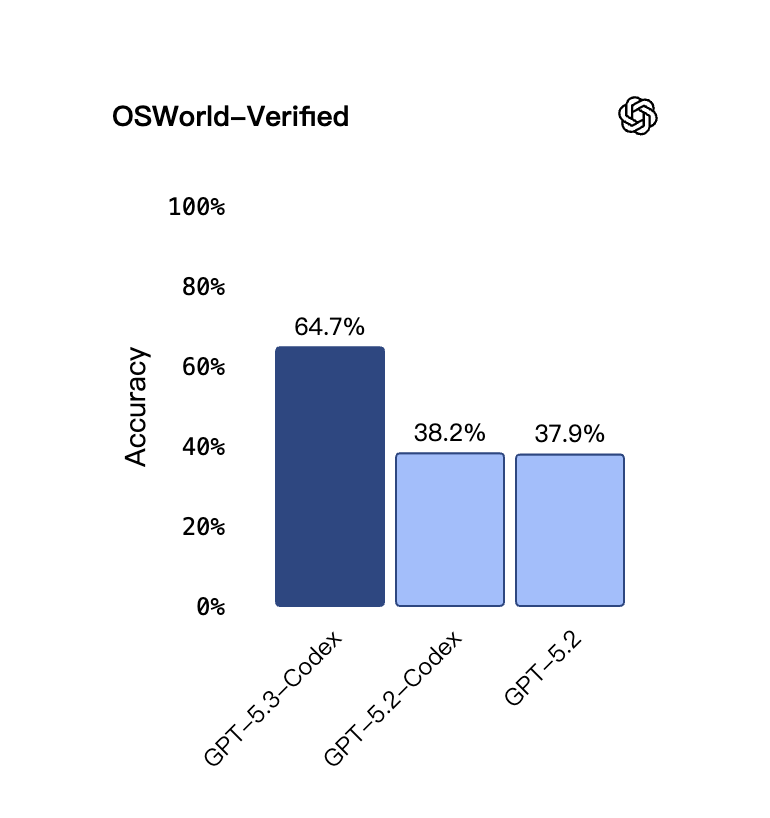
GPT-5.3-Codex则有一个指标高得离谱——OSWorld-Verified(视觉桌面操作)。简单来说,这项测试要求AI根据屏幕截图完成各种电脑任务,人类基准是72%。前代模型GPT-5.2-Codex得分38.2%,GPT-5.2得分37.9%。而融合了两者优势的GPT-5.3-Codex,直接将分数干到了64.7%。相比之下,它在SWE-Bench Pro(智能体编程)、Cybersecurity Capture The Flag Challenges(智能体安全攻防)和SWE-Lancer IC Diamond(修bug挑战)等其他项目上5到6个百分点的提升,都显得像是常规操作了。
应用与生态更新
看完成绩单,再来看看实际应用案例。有趣的是,Anthropic这次并没有放出Claude Opus 4.6的具体用例演示,而是选择更新了自家产品线。
Claude Code增加了“智能体团队”(agent teams)新功能,允许多个Agent并行工作。这非常适合像大规模代码审查这类可以被拆分成许多独立子任务的场景。
Claude in Excel也迎来了更新,新增了规划模式,并且能够自动为杂乱的非结构化数据匹配合适的表格结构。
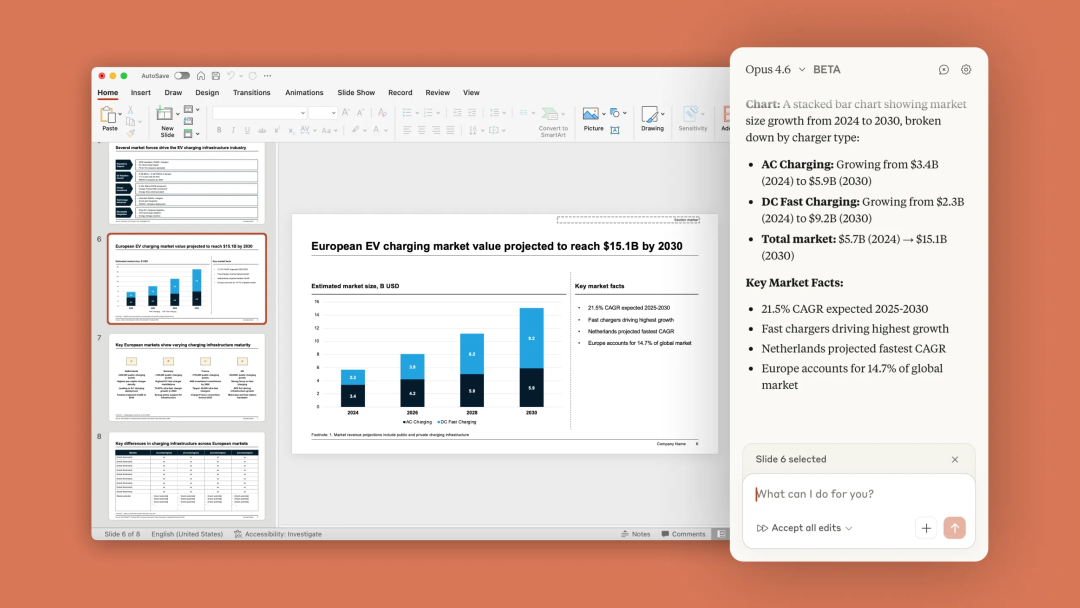
此外,还为PPT推出了研究预览功能。Claude现在能够识别公司品牌的PPT模板,确保布局、字体、颜色等风格不变。它可以针对单张幻灯片简化文本、添加图表,也能够一次性生成多达10张幻灯片供用户后续微调。
OpenAI则把更多精力放在了成果展示上。他们发布了两款使用GPT-5.3-Codex构建的新游戏,但这次没有像发布GPT-5.2-Codex时那样公布完整的提示词。
他们还展示了一个略显“蠢萌”的网页案例,理由是GPT-5.3-Codex在制作价格页面时,会把年费展示成折扣后的月费,而不是总金额。这个细节让人不禁会心一笑。
API、定价与安全
在API和定价方面,Anthropic为API新增了“自适应思考”(Adaptive thinking)功能,由Claude自行判断何时开启深度思考模式。
同时还提供了四档“努力程度”(Effort)可选:低(low)、中(medium)、高(high,默认)和最大(max)。
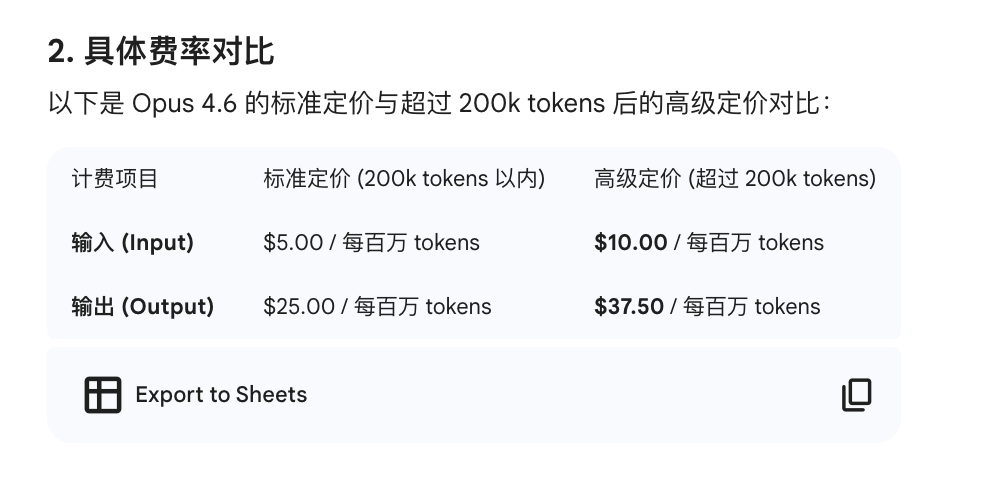
另一个Beta功能是上下文自动摘要:当长时间对话或AI Agent任务接近上下文长度上限时,系统会自动将部分上下文压缩成摘要,并用摘要替换原始内容,以节省token。具体定价对比如下:
GPT-5.3-Codex目前尚未提供独立API,但已经在Codex App、CLI、IDE插件及网页版中全面上线。这种“上线即全量”的风格,倒是有点不太像OpenAI以往的节奏。顺带一提,API形式的GPT-4o在一周后也将停止服务,这波更新确实带走了不少“时代的眼泪”。
最后,两家公司都花了相当篇幅讨论安全问题。
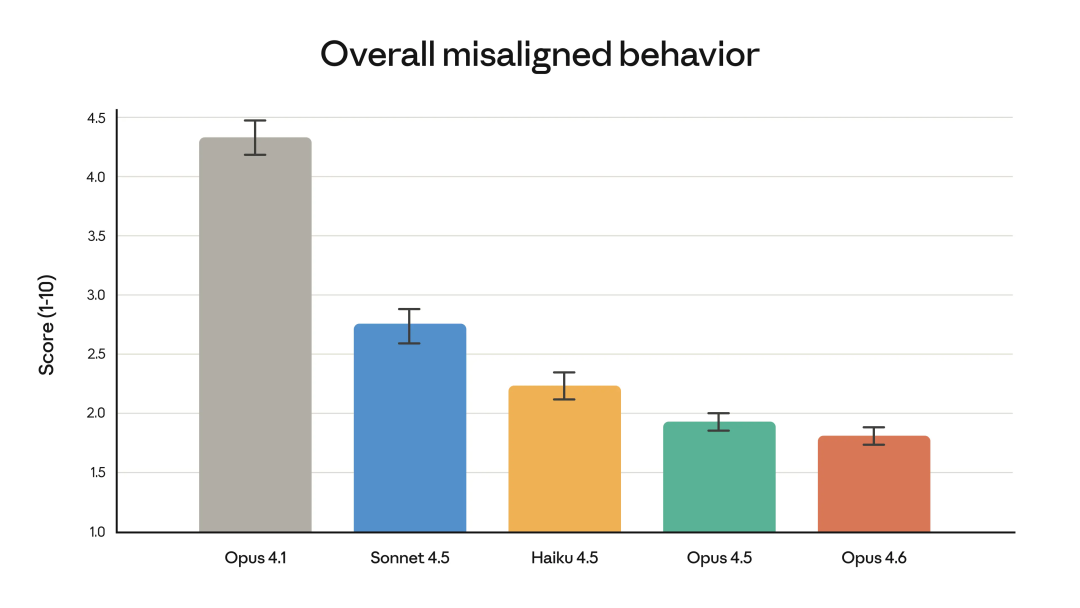
Anthropic首先用一张图表表明,此次性能升级并未影响模型的安全性。他们近期主要做了两件事:
- 探索模型可解释性的新方法,目标是让研究人员能“看见”模型做出特定回答的内部原因。这有助于在标准测试未能覆盖的边缘场景中,提前发现诸如模型突然变得极具误导性等风险。
- 在模型表现出色的领域(如网络安全)加强了防护。他们发现Opus 4.6在网络安全方面能力更强(既能修bug也可能被用于攻击),因此部署了六个新的网络安全探针,用于检测模型是否输出了可能被滥用的内容。
OpenAI在安全方面也下了苦功。他们现在为开源项目提供免费的安全体验,并将一些已知的恶意话术套路整理成识别规则。当用户提问与这些套路相似时,模型会自动降低回答的详细程度,以规避风险。
结语
这次模型更新后,一个明显的感受是大家对模型的期望值被拉高了。以前模型更新,我们还会兴致勃勃地测试其文本、代码、乃至3D生成的基础表现。但现在,随着Claude Code、Copilot等智能开发工具的接连冲击,我们对模型能力的评估似乎进入了一种“薛定谔的猫”状态——过于简单的测试显得索然无味,而利用现有工具链组合,我们似乎也能触及相近的能力上限;过于复杂的任务,则更倾向于将其以Agent的形式,嵌入到已有的工作流中进行长期、综合的评估。
或许在未来,大模型的版本迭代会成为一种更日常的节奏,盛大的发布会将不再是标配。竞争的焦点,可能会转向更实用、更集成的Agent形态与应用生态。作为一个使用者,最大的愿望或许是:别只跟“整理桌面”较劲了,我的桌面都快被清理得没文件了。
对于这次Claude Opus 4.6和GPT-5.3 Codex的更新,你怎么看?欢迎在云栈社区的开发者广场分享你的使用体验和看法。
 发表于 2026-2-7 05:05:00
|
查看: 227|
回复: 0
发表于 2026-2-7 05:05:00
|
查看: 227|
回复: 0
