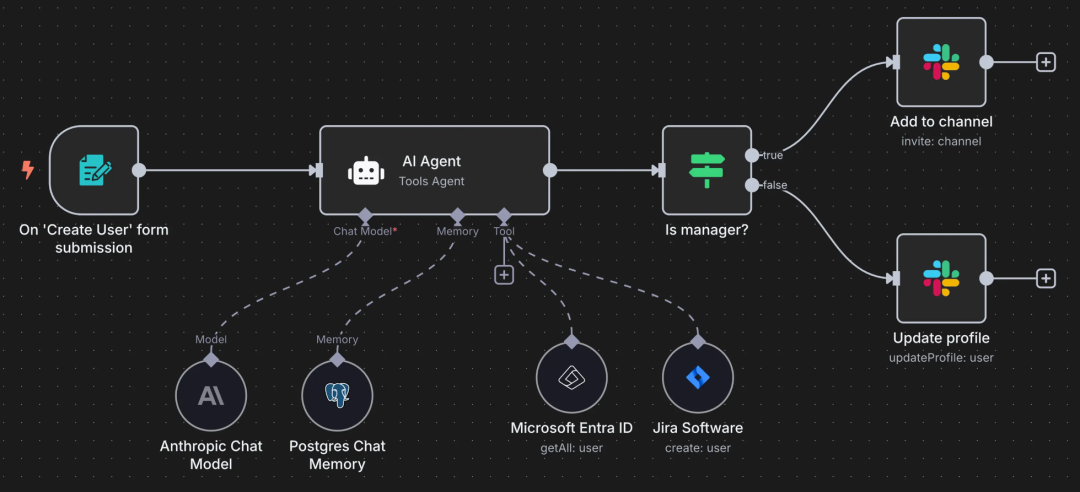
在低代码工作流自动化领域,n8n 以其强大的灵活性和丰富的节点生态,正成为越来越多开发者和运维人员的效率利器。它不仅能连接各种云服务 API,还能轻松集成本地部署的服务,比如数据库和 AI 模型。本文将带你从零开始,通过 Docker 快速部署 n8n,并实战搭建一个结合 AI 模型处理文本文件的自动化工作流,最后还会教你如何调用本地部署的 Ollama 大模型。
前置准备
使用 Docker 方式安装 n8n 无需操心 Node.js 环境,隔离性更好,是新手最推荐的方式。
首先,确保你的电脑已经安装了 Docker 环境。如果还没安装,可以通过以下方式快速获取:
- Windows:直接下载 Docker Desktop 安装;
- Mac:通过 Homebrew 或官网镜像安装;
- Linux:使用系统对应的包管理工具安装。
安装步骤
步骤 1:检查 / 安装 Docker
打开终端,执行以下命令检查 Docker 是否已安装:
docker -v
docker compose version # 检查 Compose(Docker 20.10+ 已内置)
如果未安装:
步骤 2:创建持久化目录(关键)
为了避免容器重启后工作流数据丢失,我们需要先在本地创建目录用于存储 n8n 的数据。
# macOS/Linux
mkdir -p ~/n8n/data
# Windows(PowerShell)
mkdir $HOME\n8n\data
步骤 3:启动 n8n 容器
使用 Docker Compose 来启动和管理容器是最方便的方式。
- 创建一个
docker-compose.yml 文件(可以放在 ~/n8n/ 目录下):
version: "3"
services:
n8n:
image: docker.n8n.io/n8nio/n8n
container_name: n8n
ports:
- "5678:5678"
volumes:
# n8n数据挂载(存储工作流、数据库)
- ${HOME}/n8n/data:/home/node/.n8n
environment:
- N8N_HOST=0.0.0.0
- N8N_PORT=5678
- N8N_LOG_LEVEL=info
restart: always # 开机自启/容器崩溃自动重启
- 进入
docker-compose.yml 文件所在的目录,执行启动命令:
docker compose up -d # -d 表示后台运行
步骤 4:访问与验证
- 打开浏览器,访问
http://localhost:5678,首次登录需要创建一个账号,之后即可进入 n8n 主界面。
- 可以通过以下命令查看容器状态,确认运行是否正常:
docker ps # 查看运行中的容器,能看到 n8n 容器即正常
docker logs n8n # 查看 n8n 日志,排查启动问题
步骤 5:常用 Docker 操作命令
掌握几个常用命令,方便日后维护:
# 停止 n8n 容器
docker stop n8n
# 重启 n8n 容器
docker restart n8n
# 彻底删除 n8n 容器(数据卷已持久化,删除容器不丢数据)
docker rm -f n8n
# 更新 n8n 镜像(升级版本)
docker pull docker.n8n.io/n8nio/n8n
docker compose down && docker compose up -d
使用入门:构建一个AI文本处理工作流
我们通过一个完整的例子来熟悉 n8n:读取一个本地 txt 文件,利用 AI 模型对内容进行优化改写,最后将结果保存为一个新的文件。
浏览器访问 http://localhost:5678 登录后,你会看到如下初始界面:

-
添加起始节点:点击画布中央的加号,可以看到右侧有丰富的节点分类。我们选择 Trigger manually 这个节点作为工作流的手动触发入口。
-
添加文件读取节点:点击 Trigger 节点右侧的加号,搜索并添加 Read/Write Files from Disk 节点,操作类型选择 Read File(s) From Disk。接下来需要配置要读取的文件路径。
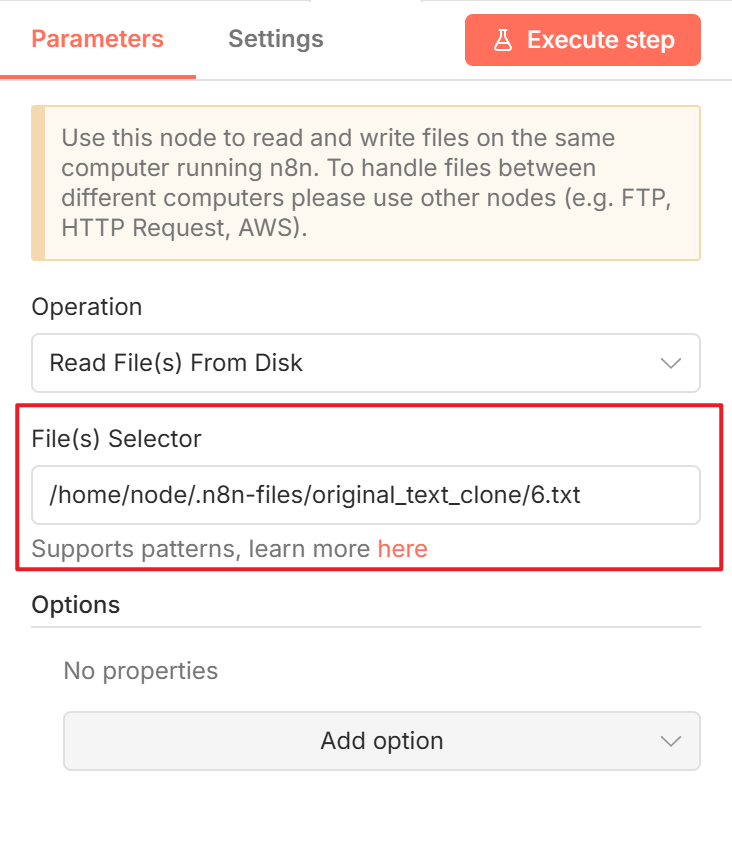
这里有个关键点:文件路径必须是 Docker 容器内的路径,而不是你电脑上的原始路径。还记得之前 docker-compose.yml 里配置的卷映射吗?最初只映射了数据目录:- ${HOME}/n8n/data:/home/node/.n8n。
你可能会想,把要读的文件放到 ~/n8n/data 目录下,然后在节点里配置 /home/node/.n8n/xxx.txt。想法没错,但实测 n8n 可能没有权限读取这个数据目录下的用户文件。
一个更清晰的解决方案是,专门为需要操作的文件新增一个映射目录。修改 docker-compose.yml 文件,在 volumes 部分增加一行:
volumes:
# 原有n8n数据挂载(存储工作流、数据库)
- ${HOME}/n8n/data:/home/node/.n8n
# 新增:本地文件目录 → 容器内可访问目录
- ${HOME}/n8n/files:/home/node/.n8n-files
修改后,运行 docker restart n8n 重启容器。同时,在你电脑的 ~/n8n/ 目录下新建一个 files 文件夹,并把要读取的 6.txt 文件放进去。
接着,回到 n8n 的 Read File 节点,配置正确的容器内路径:
/home/node/.n8n-files/6.txt
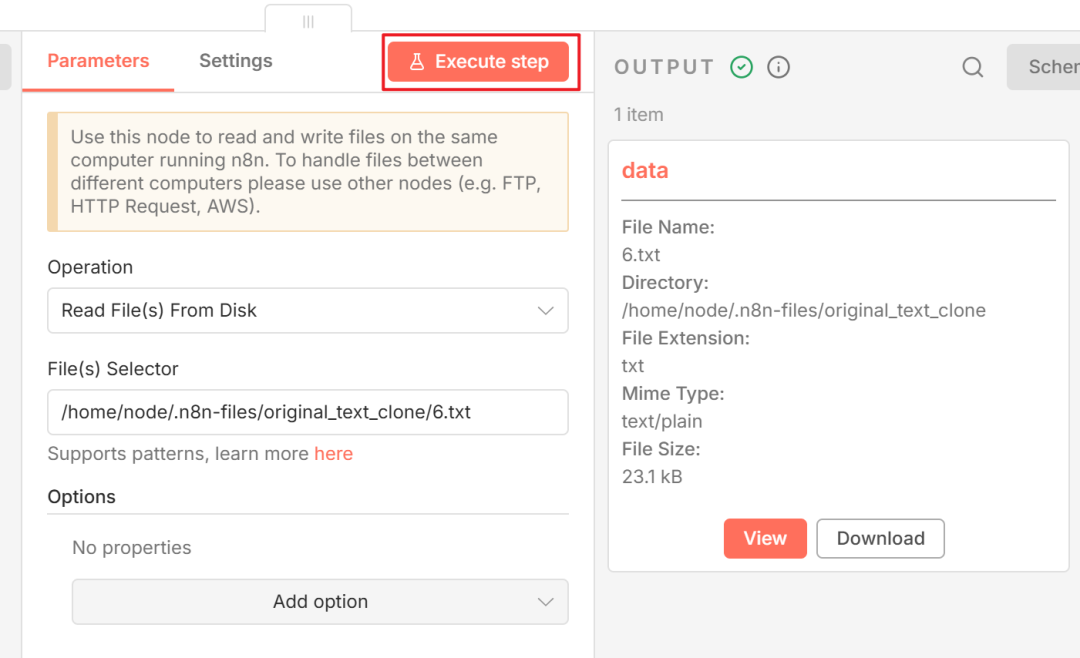
点击 Execute step 测试,如果右侧成功显示文件信息,说明读取成功。
-
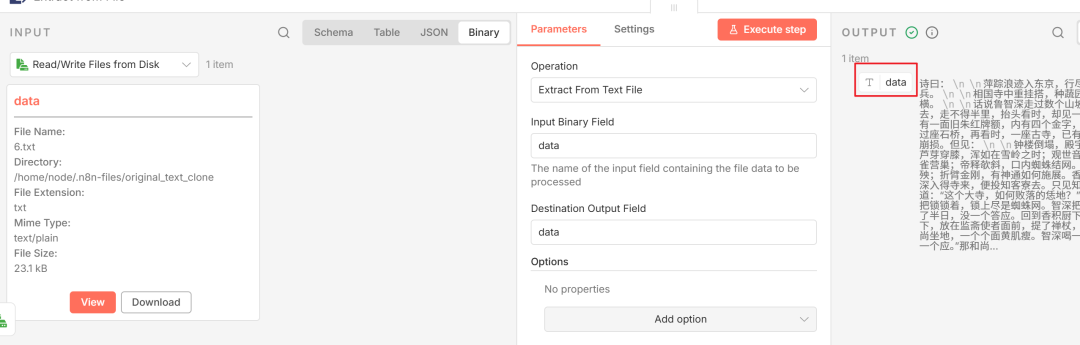
提取文件内容:Read File 节点输出的是二进制文件数据,需要连接 Extract from File 节点来提取其中的文本内容。添加该节点并点击 Execute step,就能在右侧看到文件的具体文本了。
-
调用 AI 模型处理文本:有了文本内容,现在可以调用大模型进行处理。搜索并添加 AI Agent 节点,然后将它的 Chat Model 接口连接到一个 DeepSeek Chat Model 节点(你需要先在 DeepSeek 平台注册并获取 API Key 来配置此节点)。
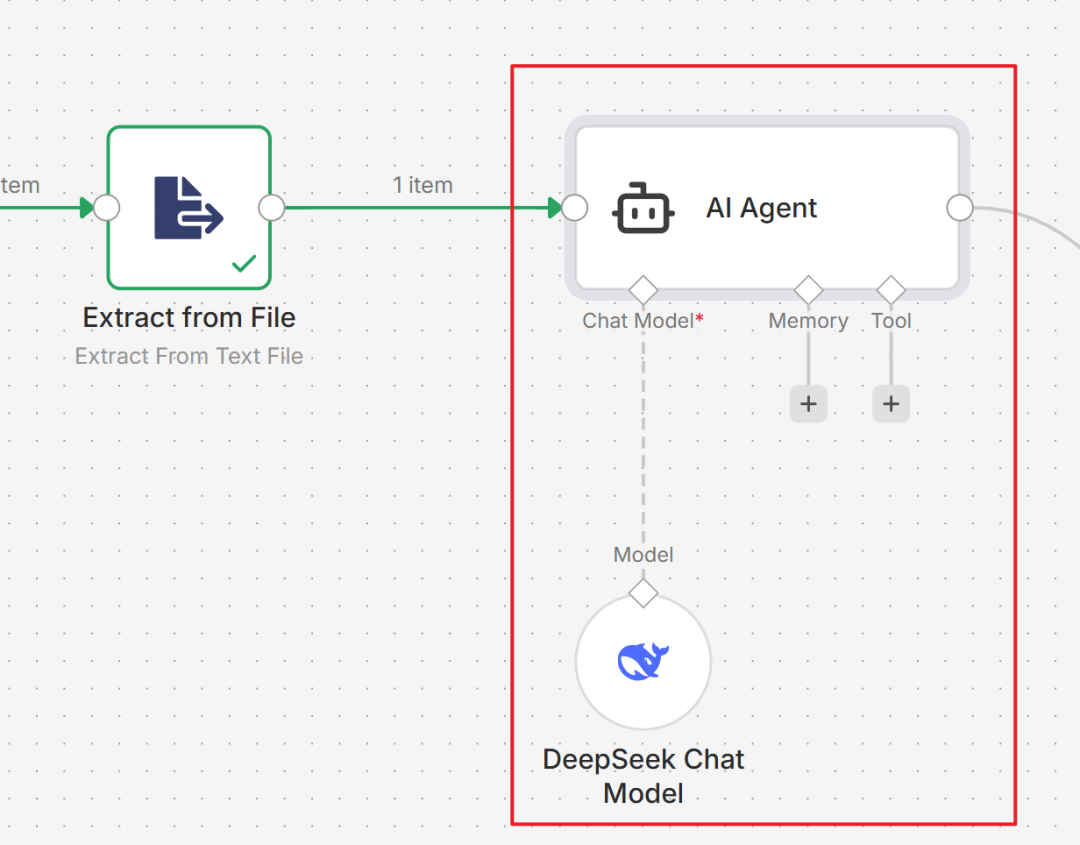
-
配置 AI 提示词:双击打开 AI Agent 节点,在 Source for Prompt 处选择 Define below。下方会出现 Prompt 输入框,在这里编写你的指令,例如“将以下文本改写为听书文案风格”。关键是,要将左侧输入区域中 Extract from File 节点输出的 data 字段拖拽到 Prompt 输入框中,这样工作流执行时才会把文件内容传给 AI。
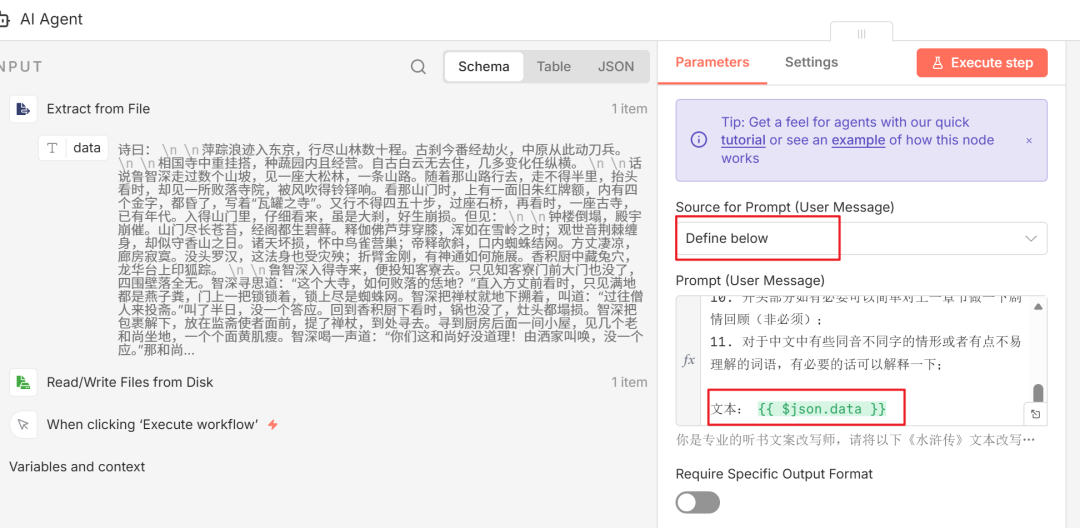
-
保存 AI 输出到文件:运行 AI Agent 节点得到结果后,我们需要将文本保存回本地文件。这个过程与读取相反,需要先将文本转换为文件对象,再写入磁盘。
- 首先添加
Convert to File 节点,配置 Text Input Field 为 AI 输出的字段(例如 output)。
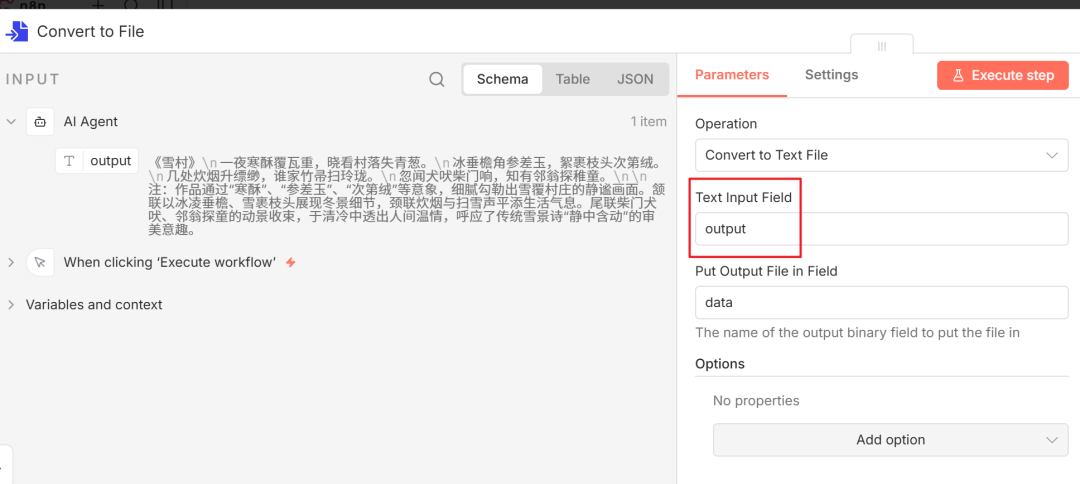
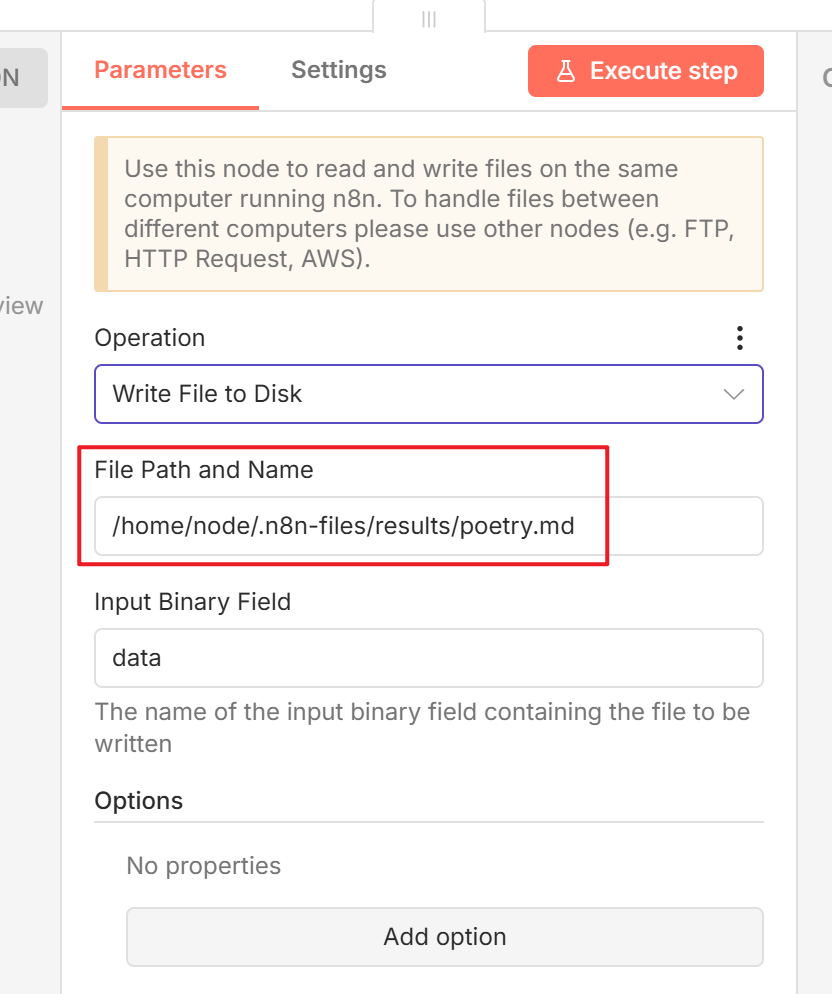
- 然后添加
Read/Write Files from Disk 节点,操作类型选择 Write File to Disk,配置好容器内的目标文件路径,例如 /home/node/.n8n-files/results/poetry.md。
运行整个工作流,检查 ~/n8n/files/results/ 目录下是否生成了新文件。
n8n 连接本地部署的 AI 模型
除了使用云端 API,n8n 也能轻松集成本地部署的大语言模型。Ollama 是一个简化大模型本地部署和管理的优秀工具,下面我们以它为例进行实践。
本地模型下载
- 访问 Ollama 官网下载并安装。
- 在官网模型库中找到 qwen3 系列模型,根据你的电脑配置选择合适尺寸的模型下载。
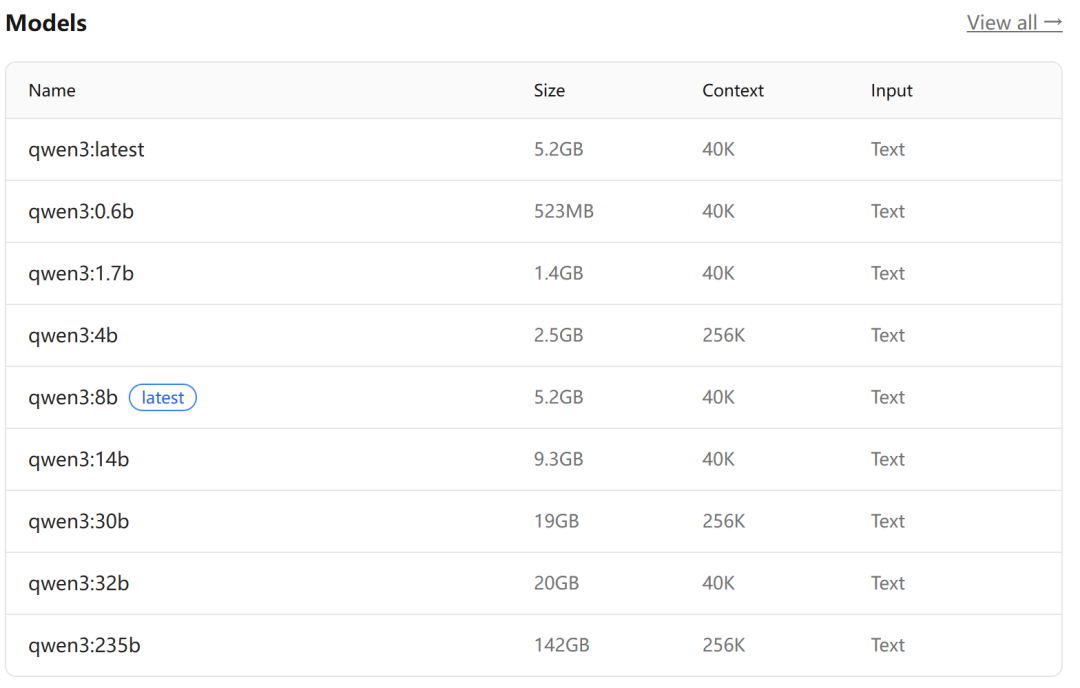
- 以
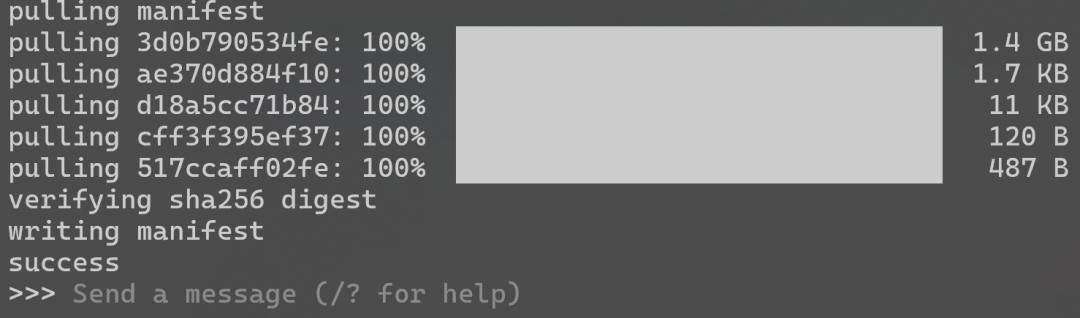
qwen3:1.7b 模型为例,复制对应的 CLI 命令 ollama run qwen3:1.7b,在终端中执行,它会自动下载并启动一个交互式对话。
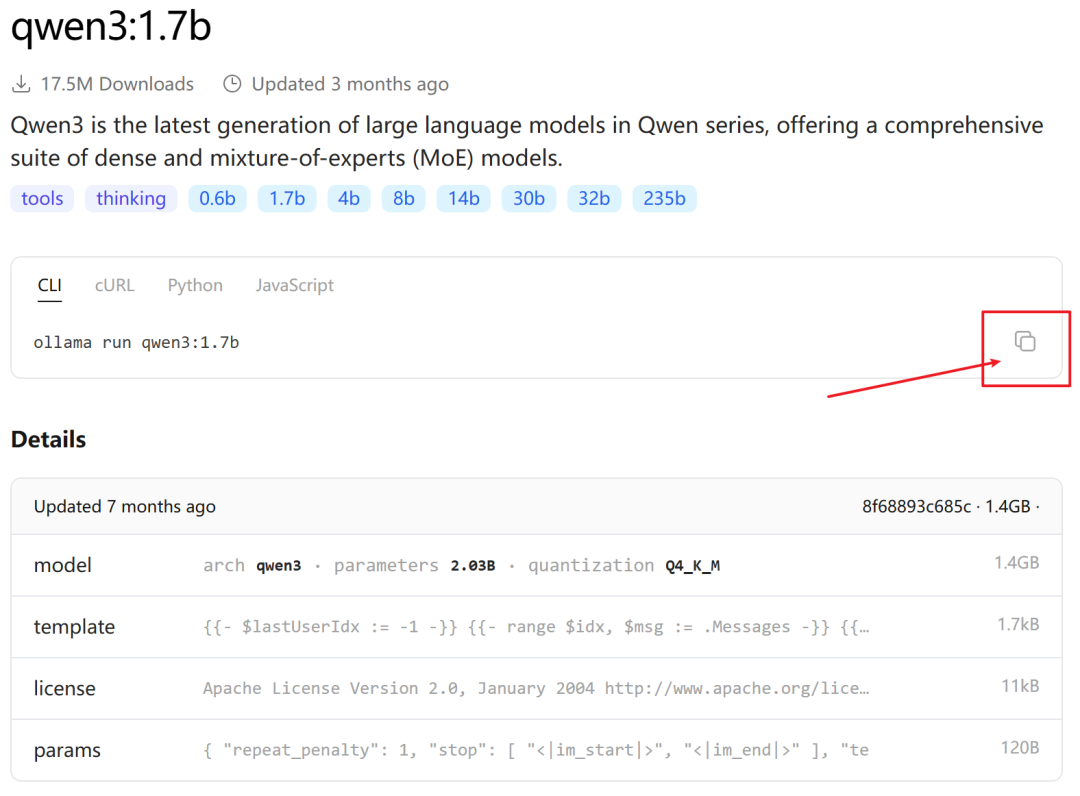
- 下载完成后会自动进入聊天界面。输入
/? 查看命令帮助,输入 /bye 退出。之后再次运行 ollama run qwen3:1.7b 会直接进入对话。
- 你也可以打开 Ollama 的桌面客户端,查看和管理已下载的模型。
在 API 测试工具中调用
除了命令行对话,Ollama 也提供了 HTTP API,方便在其他工具中集成。
- 在模型页面找到
cURL 命令示例并复制。
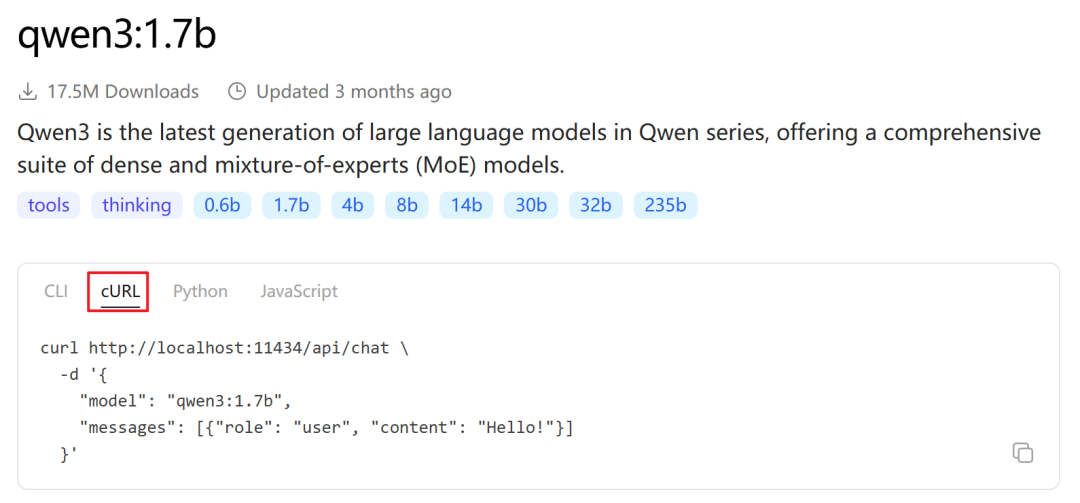
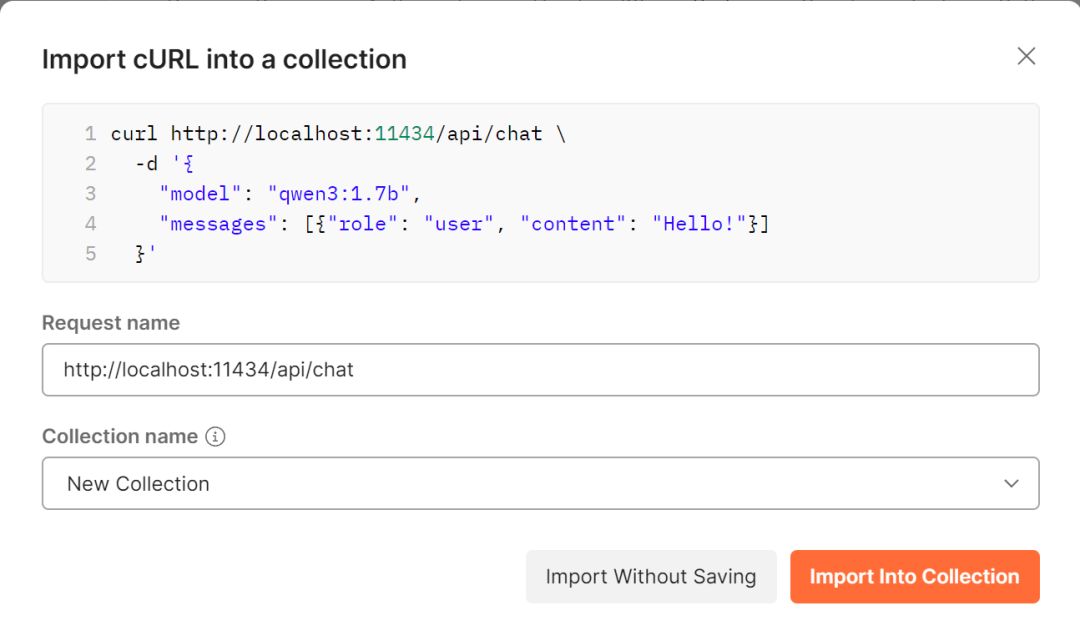
- 打开 Postman,点击
Import,选择 Raw text 粘贴复制的 cURL 命令,然后点击 Import Into Collection。
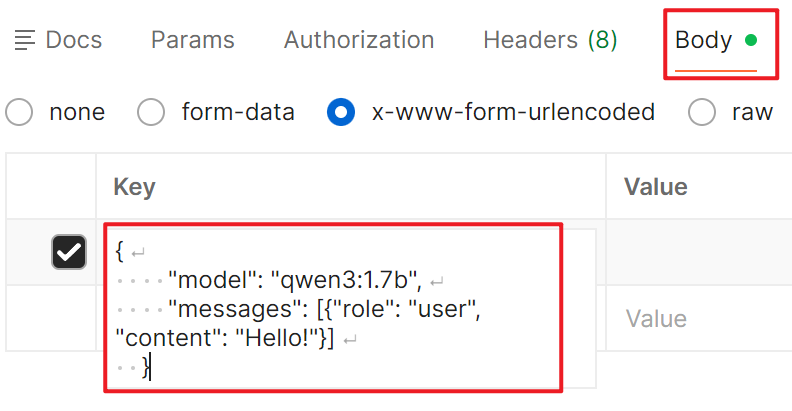
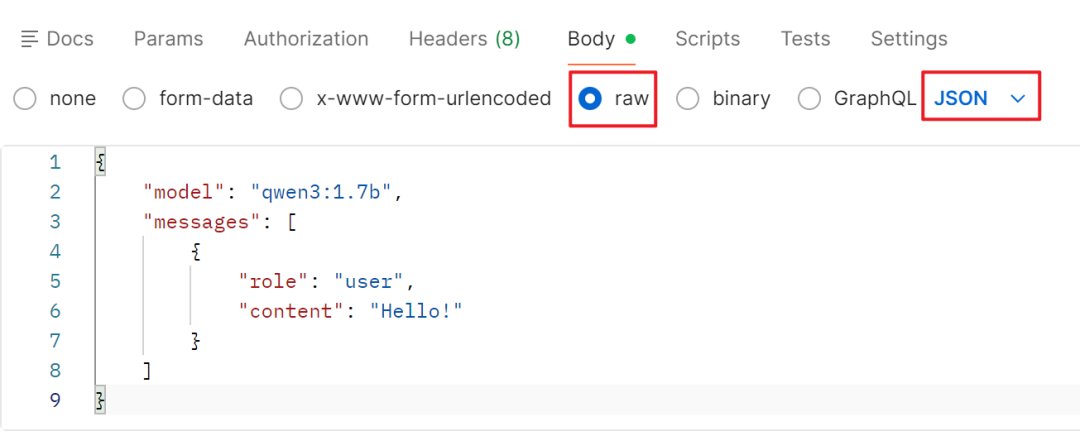
- Postman 默认可能以
x-www-form-urlencoded 格式解析 Body,你需要将其中的 JSON 参数复制,然后切换到 Body 标签下的 raw 格式,并选择 JSON,重新粘贴。
-
点击 Send 发送请求,即可在下方看到模型的流式响应。
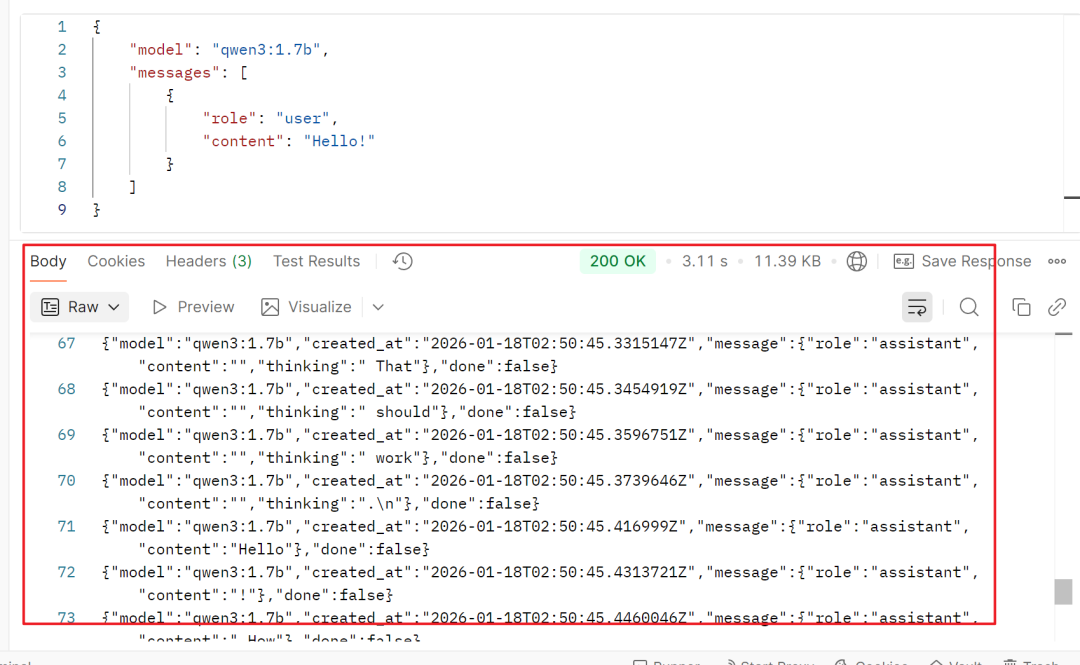
为了避免格式问题,你也可以直接使用下面这个显式指定 JSON 类型的 cURL 命令进行测试:
curl http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3:1.7b",
"messages": [{"role": "user", "content": "Hello!"}]
}'
提示:-d 参数里 messages 数组中的 content 就是你的对话内容,可以修改成任何你想问的问题。
国内开发者常用的 Apifox 等工具也支持类似操作,这里不再赘述。Apifox 的一个优点是能够自动合并流式响应返回的完整内容。

在 n8n 中添加 Ollama 节点
现在,我们回到 n8n,用本地模型替换掉之前的云端 AI 服务。
- 在工作流中,可以删除之前的
AI Agent 节点,搜索并添加 Ollama 节点。
- 在节点配置中,选择
Message a Model 操作,在 Model 下拉列表中选择你本地已下载的模型(如 qwen3:1.7b),在 Messages 中填写你的提示词。
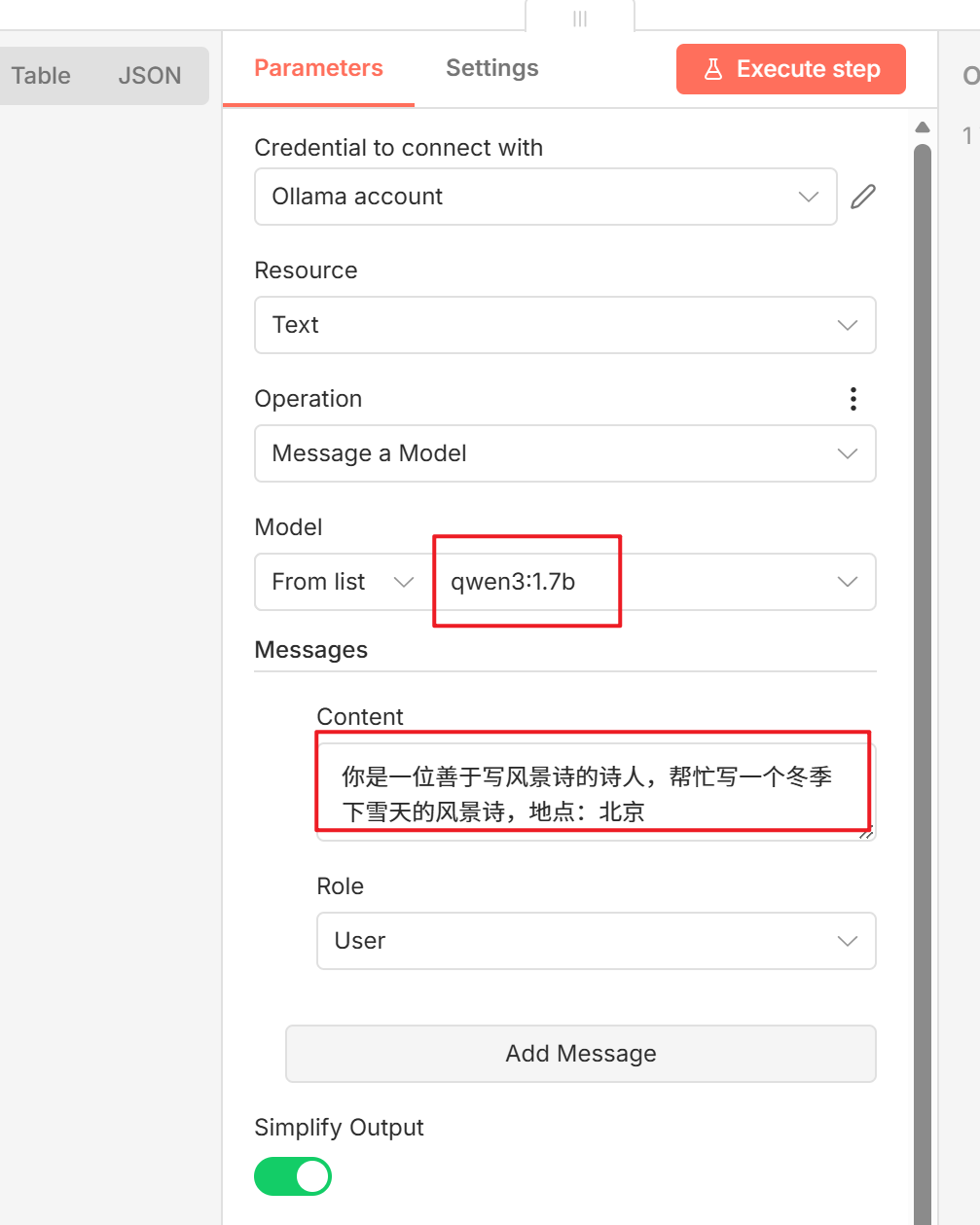
- 运行节点,n8n 便会调用你本地部署的 Ollama 模型并返回结果,后续可以继续连接文件写入等节点,完成自动化流程。
结语
通过本文的实战演练,你应该已经掌握了 n8n 的核心用法:从 Docker 部署、基础节点操作,到构建一个结合人工智能处理的完整工作流,乃至集成本地 Ollama 模型。n8n 的真正强大之处在于其“连接器”属性,它能以低代码的方式,无缝衔接数据库、本地脚本、云服务 API 和各类 AI 能力,将繁琐重复的操作串联成自动化流水线。
无论是个人用于提升效率,还是小团队用来简化业务流程,本地部署的 n8n 都是一个极具性价比的选择。希望这篇指南能帮助你入门,更多的节点组合与高阶玩法,欢迎在云栈社区与大家一起探索交流。
 发表于 2026-2-8 03:43:27
|
查看: 167|
回复: 0
发表于 2026-2-8 03:43:27
|
查看: 167|
回复: 0
