在多线程编程中,如何高效安全地保护共享数据是一个核心议题。传统的互斥锁(std::mutex)虽然简单可靠,但存在一个明显的缺陷:无论是读操作还是写操作,它都只允许一个线程独占访问。这在“读多写少”的场景下,会造成巨大的性能浪费,因为大量的读操作本可以并发进行。
为了解决这个问题,C++17 标准正式引入了 std::shared_mutex,它实现了经典的“读写锁”(Readers-Writer Lock)机制。其核心思想是允许多个读线程同时访问共享资源,而写线程则独占资源。这在高并发读取的场景下,能显著提升程序的吞吐量。本文将从使用方式入手,深入探讨其设计考量,并通过对主流 GCC 实现的源码剖析,彻底理解其内部的加解锁机制与实现原理。如果你想深入了解 C++ 更多同步机制和高级用法,可以参考我们 云栈社区 上的相关内容。
1. std::shared_mutex 的核心接口和使用
1.1 核心成员函数
std::shared_mutex 的接口清晰地分为“独占锁操作”(用于写)和“共享锁操作”(用于读)两类:
// 独占锁(写锁)接口
void lock(); // 获取独占锁,阻塞直到成功
bool try_lock(); // 尝试获取独占锁,立即返回
void unlock(); // 释放独占锁
// 共享锁(读锁)接口
void lock_shared(); // 获取共享锁,阻塞直到成功
bool try_lock_shared();// 尝试获取共享锁,立即返回
void unlock_shared(); // 释放共享锁
1.2 配套使用锁模板
直接调用 lock() / lock_shared() 等方法存在忘记解锁而导致死锁的风险。因此,C++ 提供了基于 RAII 思想封装的锁模板,强烈推荐优先使用:
std::unique_lock:用于管理独占锁(写操作),功能灵活,支持手动解锁、超时等。std::shared_lock:用于管理共享锁(读操作),仅支持共享锁的相关操作。std::lock_guard:轻量级 RAII 封装,但仅支持独占锁,且不提供手动解锁接口。
2. std::shared_mutex 的设计考量
在动手实现一个读写锁之前,我们需要明确几个关键的设计决策。这直接影响了锁的行为特性和性能表现。
首先,是优先级问题:
- 读者优先(Read-preferring):只要有一个读锁持有者,新的读锁请求就可以立即获取,写锁必须等待所有读锁释放。这可能导致写线程“饥饿”(长时间无法获得锁)。
- 写者优先(Write-preferring):一旦有写锁在等待,后续的读锁请求将被阻塞,直到所有写锁完成。这可能导致读线程“饥饿”。
C++ 标准并未强制规定 std::shared_mutex 采用哪种策略,但主流实现通常倾向于写者优先,以避免写线程被大量读线程长时间阻塞,这对于保证数据及时更新至关重要。
其次,需要考虑状态跟踪。一个读写锁需要维护以下核心状态信息:
- 当前持有的读锁数量。
- 是否有写锁被持有或正在排队。
- 等待队列(包括读等待和写等待)。
理解了这些设计考量,我们就能更好地解读其源码实现了。
3. std::shared_mutex 源码剖析(GCC 实现 libstdc++)
有趣的是,GCC 的 std::shared_mutex 实际上有两种后备实现,具体使用哪一种取决于编译时的配置:
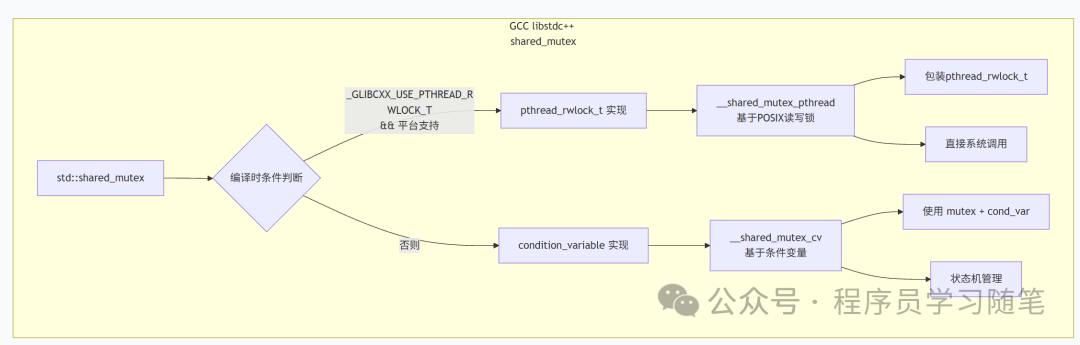
3.1 基于 pthread_rwlock_t 的实现
当平台定义了 _GLIBCXX_USE_PTHREAD_RWLOCK_T 宏时,会使用这种实现。它本质上是对操作系统原生 POSIX 读写锁的封装。
#if _GLIBCXX_USE_PTHREAD_RWLOCK_T
class __shared_mutex_pthread {
pthread_rwlock_t _M_rwlock;
// ... 包装了POSIX读写锁的所有操作
};
这种实现的性能通常更好,因为它直接利用了操作系统内核的优化。
3.2 基于 condition_variable 的纯 C++ 实现
当平台不支持原生读写锁时,GCC 会使用一个完全用 C++ 标准库组件(mutex 和 condition_variable)实现的版本。这是我们分析的重点,它能让我们透彻理解读写锁的内部机理。
3.2.1 核心状态表示
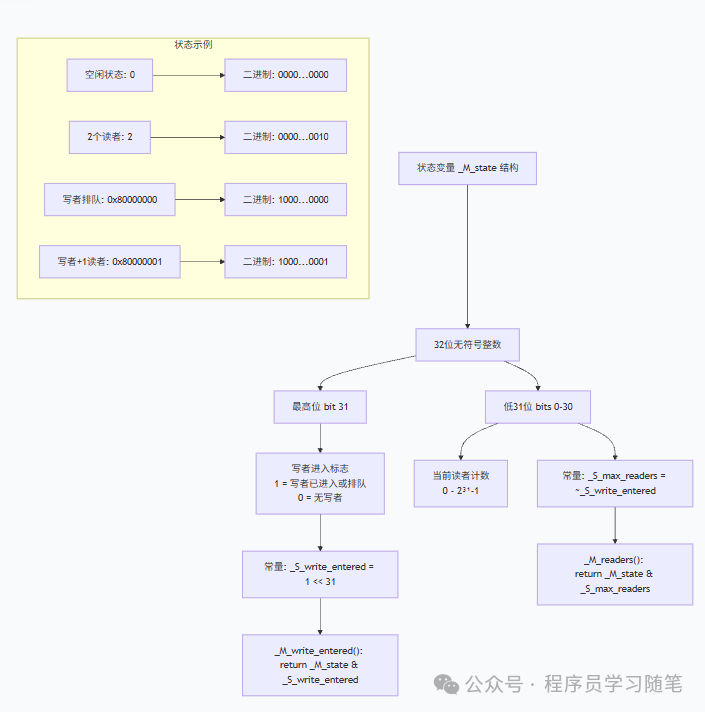
其状态管理非常巧妙,仅使用一个原子变量 _M_state 来同时表示写者标志和读者数量。
// The high bit of _M_state is the write-entered flag which is set to
// indicate a writer has taken the lock or is queuing to take the lock.
// The remaining bits are the count of reader locks.
static constexpr unsigned _S_write_entered = 1U << (sizeof(unsigned)*__CHAR_BIT__ - 1);
static constexpr unsigned _S_max_readers = ~_S_write_entered;
bool _M_write_entered() const { return _M_state & _S_write_entered; }
unsigned _M_readers() const { return _M_state & _S_max_readers; }
- 最高位:用作“写者进入标志”(
_S_write_entered)。为 1 表示有写者已持有锁或正在排队。
- 低31位:表示当前持有读锁的读者数量。
这种“状态压缩”设计减少了需要同步的变量数量,提升了效率。
3.2.2 核心同步变量
为了实现写者优先的策略,该实现使用了两个条件变量:
condition_variable _M_gate1; // 用于控制读者和写者的入口
condition_variable _M_gate2; // 专门用于写者等待所有读者离开
_M_gate1 是“入口门”,控制线程能否开始尝试获取锁。_M_gate2 是“清场门”,写者在此等待所有现有读者离开。
3.2.3 加解锁机制详解
理解了核心状态和同步变量后,我们来看具体的加解锁流程。
1)获取读锁(lock_shared)
void lock_shared()
{
unique_lock<mutex> __lk(_M_mut);
_M_gate1.wait(__lk, [=]{ return _M_state < _S_max_readers; });
++_M_state;
}
- 条件判断
_M_state < _S_max_readers:这个条件同时检查了两件事:(1) 读者数量未达到上限;(2) 写者进入标志未被设置。这是实现“写者优先”的关键——一旦有写者设置了这个标志,新来的读者就会在 _M_gate1 上等待。
- 原子性:在互斥锁
_M_mut 的保护下,检查状态和增加读者计数的操作是原子的。
2)释放读锁(unlock_shared)
void unlock_shared()
{
lock_guard<mutex> __lk(_M_mut);
__glibcxx_assert( _M_readers() > 0 );
auto __prev = _M_state--;
if (_M_write_entered()) {
// 有写者在等待
if (_M_readers() == 0) {
_M_gate2.notify_one(); // 唤醒一个写者
}
} else {
// 无写者等待
if (__prev == _S_max_readers) {
_M_gate1.notify_one(); // 可能唤醒其他读者或写者
}
}
}
释放读锁的逻辑包含一个智能的唤醒策略:
- 有写者等待时:只有当最后一个读者(
_M_readers() == 0)离开时,才通过 _M_gate2 唤醒一个写者。这避免了不必要的唤醒。
- 无写者等待时:仅当之前的读者数量达到上限(
__prev == _S_max_readers),意味着可能有其他读者在 _M_gate1 上等待时,才去唤醒。
3)获取写锁(lock)
void lock()
{
unique_lock<mutex> __lk(_M_mut);
// 第一阶段:等待写者进入标志可设置(排队)
_M_gate1.wait(__lk, [=]{ return !_M_write_entered(); });
_M_state |= _S_write_entered; // 设置写者进入标志
// 第二阶段:等待所有现有读者离开
_M_gate2.wait(__lk, [=]{ return _M_readers() == 0; });
}
写者获取锁是一个两阶段过程,完美体现了写者优先:
- 排队阶段:在
_M_gate1 上等待,直到没有其他写者已设置进入标志(!_M_write_entered())。一旦成功,立即设置 _S_write_entered 标志。这个标志会阻止所有新来的读者通过 _M_gate1。
- 清场阶段:在
_M_gate2 上等待,直到所有已存在的读者(_M_readers() == 0)都释放了锁。
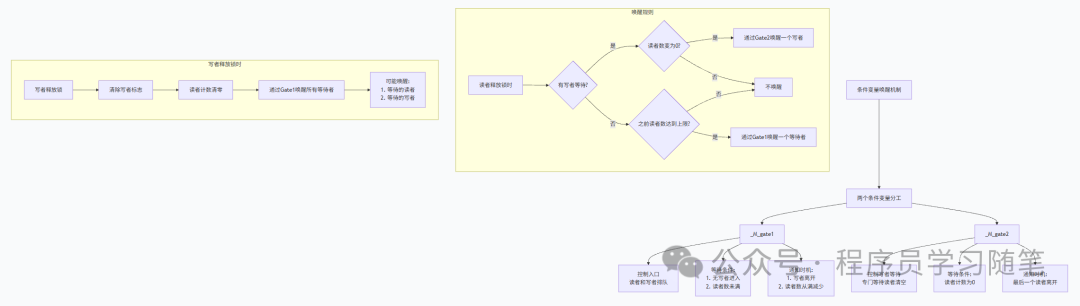
4)释放写锁(unlock)
void unlock()
{
lock_guard<mutex> __lk(_M_mut);
__glibcxx_assert( _M_write_entered() );
_M_state = 0; // 清除所有状态(写者标志和读者计数)
// 在持有互斥锁的情况下通知,防止竞争
_M_gate1.notify_all();
}
写者释放锁时,直接将 _M_state 清零,一次性清除写者标志和读者计数(理应始终为0)。随后,它在持有互斥锁的情况下调用 _M_gate1.notify_all(),唤醒所有在入口处等待的读者和写者。这确保了唤醒信号不会丢失,对于多线程同步的正确性至关重要。
4. 总结
通过对 GCC libstdc++ 中 std::shared_mutex 实现的分析,我们可以总结出以下几个精妙的设计要点:
- 写者优先策略:通过“写者进入标志”和双条件变量(
_M_gate1, _M_gate2)的配合,有效防止了写线程的饥饿。
- 状态压缩:使用一个原子变量同时编码读者计数和写者状态,极大减少了同步开销。
- 最小化唤醒:在释放锁时,根据具体上下文(有无写者等待、是否最后一个读者)决定唤醒哪个条件变量上的多少个线程,避免了大量不必要的线程上下文切换。
- 异常安全:利用 RAII 管理互斥锁,确保在异常发生时资源能被正确释放。
- 平台适配:提供 POSIX 原生实现和纯 C++ 标准库实现两种后备方案,保证了最佳的可移植性和性能。
这种实现的复杂性,恰恰是为了在各种边界条件下保证其正确性和高性能。理解这些底层机制,不仅能让我们更自信地使用 std::shared_mutex,也能在需要定制同步原语时提供宝贵的思路。对于热衷于挖掘底层实现细节的开发者,这样的源码分析是提升对操作系统和并发编程理解的绝佳途径。
最终建议:在绝大多数应用场景中,直接使用标准库提供的 std::shared_mutex 是正确且高效的选择。我们应该相信并利用标准库实现者处理好的这些复杂同步细节。只有在有极特殊的性能调优需求,或纯粹出于学习研究目的时,才需要考虑自己动手实现类似的机制。
 发表于 2026-2-9 00:31:57
|
查看: 180|
回复: 0
发表于 2026-2-9 00:31:57
|
查看: 180|
回复: 0
