今天我们来聊聊百度在2026年初发表的一篇关于CTR预测的新工作——GRAB。这篇论文提出了一种受大语言模型(LLM)启发的、序列优先的点击率预测建模新范式,并在百度首页信息流广告场景中取得了显著的业务收益。
论文原文可以在这里查看:https://arxiv.org/pdf/2602.01865
模型核心思想:序列优先与GPU并行计算
GRAB的核心思路与传统的CTR建模方法有很大不同。它摒弃了为每个“用户-候选物品”对单独建模、并进行大量填充对齐的做法,转向了一种更接近处理文本序列的“序列优先”范式。
简单来说,GRAB将整个批次(batch)内所有用户的历史行为序列和待预测的多个候选物品,打包成一个连续的、无需填充的长序列,然后利用GPU的并行计算能力一次性完成所有预测。这听起来是不是有点像是用处理一段超长文本的方式来处理用户行为?没错,这正是其灵感来源。
GRAB是如何工作的?
GRAB的整个流程可以概括为四个步骤,其端到端的架构如下图所示:
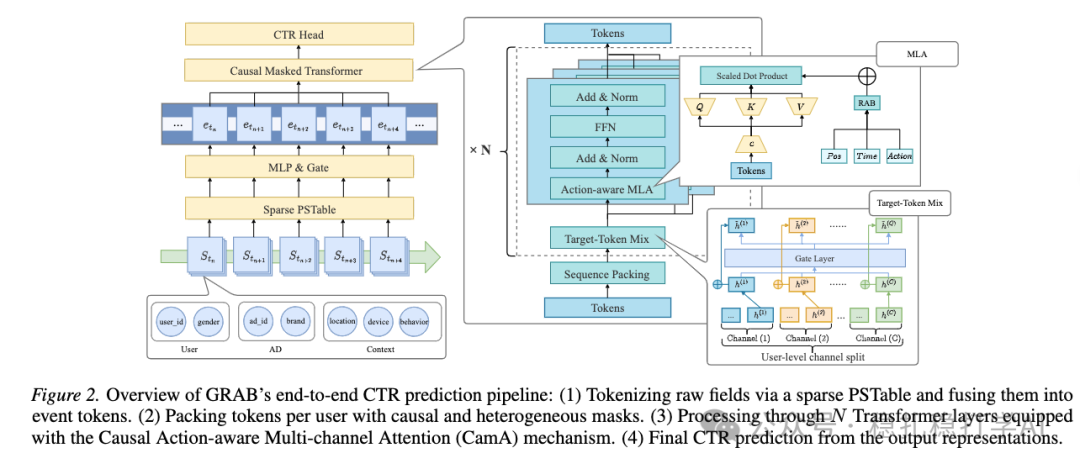
图:GRAB端到端CTR预测流程概述:(1) 通过稀疏查找表对原始字段进行分词并融合为事件令牌。(2) 为每个用户打包令牌,并应用因果和异构掩码。(3) 通过N层配备了因果动作感知多通道注意力(CamA)机制的Transformer层进行处理。(4) 从输出表示中得到最终的CTR预测。
下面我们来拆解其中的几个关键技术点。
1. 多用户、多候选的序列构建
这是GRAB实现高效并行的基础。具体做法是:
- 将单个用户按时间排序的历史行为序列作为一个连续段。
- 在这个用户行为段的后面,拼接上多个待预测的候选物品。
- 将一个批次内所有用户的这种“行为段+候选物品”片段,首尾相连地拼接起来,形成一个超长的连续序列。
这样做的好处是完全消除了填充操作,极大地提升了计算效率,尤其适合在GPU上进行并行计算。
2. 双令牌表示与门控MLP融合
在GRAB中,每个物品(无论是历史行为还是候选物品)都用两个令牌(Token)来表示:
- 部分令牌 (Partial Token):包含时间戳、物品ID、行为类型、上下文信息等。
- 完整令牌 (Full Token):在部分令牌的基础上,额外加入了用户ID、性别等用户侧信息。
在自注意力计算时,部分令牌只关注其他的部分令牌和自身;完整令牌也遵循同样的规则,实现了信息的分层流动。这些离散的特征通过一个 GateMLP 进行融合:e = GateMLP(v),从而得到稠密的令牌表示。
值得注意的是,用户行为序列不仅包含了正向互动(如点击),也明确包含了负向行为(如曝光未点击),这为模型提供了更全面的信号。
3. 定制化的因果与异构掩码
为了保证预测的合理性和用户间的隔离,GRAB设计了一套精巧的掩码机制:
- 用户隔离:确保在计算注意力时,一个用户的令牌不会看到另一个用户的令牌,防止信息泄露和跨用户干扰。
- 因果性:在单个用户序列内部,采用因果自注意力(Causal Attention),即一个令牌只能看到它自身以及它之前的令牌,看不到未来的令牌。这就像我们预测下一个词时,只能基于已经出现的上文。
最终,整个注意力掩码矩阵就像一个分块的、下三角的矩阵,严格规定了信息流动的路径。
4. 增强的注意力机制:动作感知多通道注意力(CamA)
GRAB没有使用标准的Transformer自注意力,而是对其进行了增强,提出了 CamA(Causal Action-aware Multi-channel Attention) 机制。
- 动作感知:在计算query和key的相关性时,除了它们本身的内容,还考虑了行为之间的相对时间、动作类型(如点击、曝光)以及相对位置信息。
- 多通道并行:这部分的思路与混合专家(MoE)模型有些相似。模型将用户行为序列拆分成多个通道特定的子序列,每个通道使用独立的网络参数计算因果自注意力,最后将这些通道的结果进行加权求和。这种方法旨在从不同维度捕捉用户行为的复杂模式。
5. 两阶段交替训练策略
为了平衡序列建模能力和对海量稀疏ID特征的鲁棒性,GRAB采用了一种两阶段交替训练的策略:
- 序列阶段:冻结稀疏嵌入表,端到端地优化稠密Tokenizer和Transformer部分的参数,训练重点是学习序列中的时序推理模式。
- 稀疏阶段:冻结稠密参数,切换到传统的独立曝光样本格式进行训练,优化重点是学习长尾ID特征的鲁棒表示。
这种交替训练的方式,让模型既能把握宏观的序列规律,又能打磨微观的特征嵌入。
效果如何?线上AB测试见真章
理论说得再好,最终还是要看业务效果。GRAB在百度首页信息流广告场景中进行了为期一个月的线上AB测试(10%流量)。
- CTR提升:+3.49%
- CPM(千次展示收益)提升:+3.05%
这意味着广告的平均收入获得了超过3%的增长,是一个非常有说服力的业务提升。此外,论文中提到,GRAB在推理时的成本与传统的DLRM模型相当,目前已经在百度相关场景全量上线。
个人解读与思考
通读这篇论文,我有以下几点感受:
- 效率与效果的双赢:“序列优先”+“定制掩码”的设计,巧妙地解决了多用户、多候选物品并行预测的难题,在放弃低效填充对齐的同时,充分榨取了GPU的并行计算能力。这是其能处理超长序列、从而带来效果增益的基础。
- 特征工程的演进:与之前Twitter开源的算法一样,GRAB也倾向于减少复杂的人工特征工程,更多地依赖模型从原始ID和上下文序列中自动学习模式。这或许是工业界推荐系统发展的一个趋势。
- 核心收益来源:个人认为,本文的主要收益正是来自于能够高效且有效地建模足够长的用户行为序列。更长的序列意味着更丰富的用户兴趣上下文,这对于CTR预测的准确性至关重要。
当然,论文在部分细节的阐述和可读性上或许还有提升空间,但其创新的思路和扎实的线上收益,足以让它成为值得推荐系统从业者仔细研读的工作。对这类将大模型思想与传统业务深度结合的前沿实践感兴趣的朋友,也可以在云栈社区的人工智能和算法板块找到更多相关的深度讨论与技术资源。
 发表于 2026-2-9 00:29:10
|
查看: 241|
回复: 0
发表于 2026-2-9 00:29:10
|
查看: 241|
回复: 0
