在对新接触 PostgreSQL 的开发者,尤其是那些有着深厚 MySQL 背景的朋友们来说,其中一些核心概念上的差异往往会带来初期的困惑。还记得上一期我们完成了 PG 18 的安装,那么这一期,我们就用一个更直观的方法,结合大家熟悉的 MySQL 架构,来彻底讲清楚 PostgreSQL 中的 database、schema 和用户这三者之间到底是什么关系。
MySQL 的 Database 与 Schema:一对同义词
在 MySQL 的世界里,database 和 schema 这两个词指的完全是同一个东西,它们就是一对可以互换的同义词。
这一点在 MySQL 官方文档中也得到了明确的证实。在 CREATE DATABASE 的语法说明页 (https://dev.mysql.com/doc/refman/8.0/en/create-database.html) 里有这么一句关键的话:“CREATE SCHEMA is a synonym for CREATE DATABASE.”,这直接指明了 SCHEMA 就是 DATABASE 的同义词。
我们来具体看一下语法:
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
| ENCRYPTION [=] {'Y' | 'N'}
}
从语法上你也能看出,DATABASE 和 SCHEMA 是平级可选的。
光说不练假把式,我们直接动手测试一下,看看创建 database db1 和创建 schema db1 是否会冲突:
root@localhost [(none)] 20:06:29 > create database db1;
Query OK, 1 row affected (0.09 sec)
root@localhost [(none)] 20:06:33 > create schema db1;
ERROR 1007 (HY000): Can't create database 'db1'; database exists
root@localhost [(none)] 20:06:38 > create schema db2;
Query OK, 1 row affected (0.01 sec)
root@localhost [(none)] 20:06:44 > show databases like 'db%';
+----------------+
| Database (db%) |
+----------------+
| db1 |
| db2 |
+----------------+
2 rows in set (0.04 sec)
测试结果一目了然:当我们尝试创建一个名为 db1 的 schema 时,系统报错提示 “database exists”。随后我们成功创建了 db2,并在 SHOW DATABASES 的结果中看到了 db1 和 db2 被并列列出。这充分证明了在 MySQL 中,database 和 schema 就是同一层级、同一含义的对象,只是两个不同的名字而已。
PostgreSQL 的 Database 与 Schema:完全不同的层级
当我们切换到 PostgreSQL 时,情况就截然不同了。在 PostgreSQL 中,database 和 schema 是两个完全不同的概念,它们有着明确的层级关系:database 之间是相互隔离的,而 schema 存在于 database 内部。
首先,我们创建两个数据库 db1 和 db2。
postgres=# \l+
数据库列表
名称 | 拥有者 | 字元编码 | Locale Provider | 校对规则 | Ctype | Locale | ICU Rules | 存取权限 | 大小 | 表空间 | 描述
-----------+------------+----------+-----------------+----------+-------+--------+-----------+---------------------------+---------+------------+--------------------------------------------
postgres | postgres18 | UTF8 | libc | C | C | | | | 7798 kB | pg_default | default administrative connection database
template0 | postgres18 | UTF8 | libc | C | C | | | =c/postgres18 +| 7641 kB | pg_default | unmodifiable empty database
| | | | | | | | postgres18=CTc/postgres18 | | |
template1 | postgres18 | UTF8 | libc | C | C | | | =c/postgres18 +| 7854 kB | pg_default | default template for new databases
| | | | | | | | postgres18=CTc/postgres18 | | |
(3 行记录)
postgres=# create database db1;
CREATE DATABASE
postgres=# create database db2;
CREATE DATABASE
创建成功后,我们连接到 db1,并在其中创建一个名为 sch1 的 schema,然后在这个 schema 下创建一张表 t1。
postgres=# \c db1
您现在已经连接到数据库 “db1”,用户 “postgres18”.
db1=# create schema sch1;
CREATE SCHEMA
db1=# create table sch1.t1(id int primary key,info text);
CREATE TABLE
查看一下 db1 中的 schema 列表和表,确认创建成功。
db1=# \dn+
架构模式列表
名称 | 拥有者 | 存取权限 | 描述
--------+-------------------+----------------------------------------+------------------------
public | pg_database_owner | pg_database_owner=UC/pg_database_owner+| standard public schema
| | =U/pg_database_owner |
sch1 | postgres18 | |
(2 行记录)
db1=# \dt sch1.*
List of tables
架构模式 | 名称 | 类型 | 拥有者
----------+------+--------+------------
sch1 | t1 | 数据表 | postgres18
(1 行记录)
现在,最关键的一步来了:我们切换到 db2 数据库。
db1=# \c db2
您现在已经连接到数据库 “db2”,用户 “postgres18”.
db2=# \dn+
架构模式列表
名称 | 拥有者 | 存取权限 | 描述
--------+-------------------+----------------------------------------+------------------------
public | pg_database_owner | pg_database_owner=UC/pg_database_owner+| standard public schema
| | =U/pg_database_owner |
(1 行记录)
看到了吗?在 db2 中,我们只能看到一个默认的 public schema,之前在 db1 中创建的 sch1 和表 t1 在这里完全不存在,也访问不到。这就是 PostgreSQL 中 database 的隔离性。
一张图看清架构差异
为了让这个对比更加清晰,我们可以用下面这张架构对比图来总结:
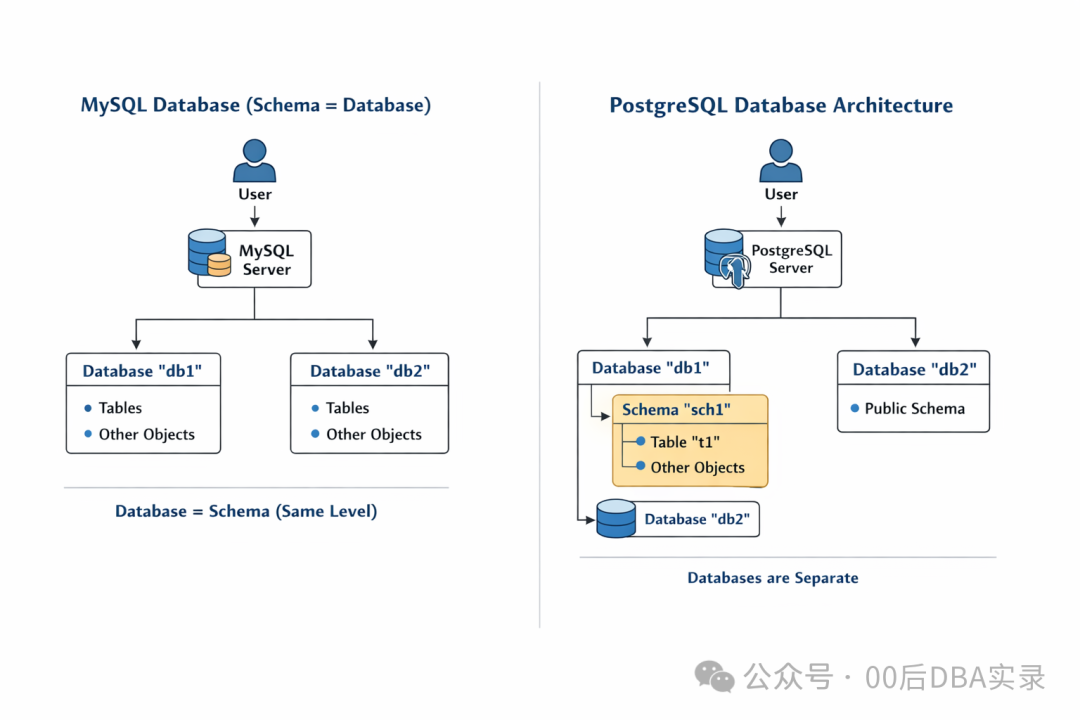
通过上面的讲解和图解,我们可以建立一个非常直观的理解模型:
- 在 PostgreSQL 中,一个
database 的逻辑隔离级别,相当于一个独立的 MySQL 实例。
- 而这个 PostgreSQL
database 内部创建的多个 schema,则相当于一个 MySQL 实例内部的多个 database。
- 不同的 PostgreSQL
database(类比不同的 MySQL 实例)之间,数据是完全隔离的,在不使用 dblink 等扩展工具的情况下无法直接互通。而同一个 database 下的不同 schema(类比同一个 MySQL 实例下的不同 database)则可以方便地互相访问。
User(角色)的对比:全局 vs 实例级
除了 database 和 schema,用户(在 PostgreSQL 中更准确地称为“角色”)的管辖范围也存在显著差异。
在 PostgreSQL 中,用户(角色)是 全局性 的。我们在 db2 中创建一个用户 u1,然后切换到 db1,会发现这个用户同样存在。
db2=# \du
角色列表
角色名称 | 属性
------------+--------------------------------------------
postgres18 | 超级用户, 建立角色, 建立 DB, 复制, 绕过RLS
db2=# create user u1;
CREATE ROLE
db2=# \du
角色列表
角色名称 | 属性
------------+--------------------------------------------
postgres18 | 超级用户, 建立角色, 建立 DB, 复制, 绕过RLS
u1 |
db2=# \c db1
您现在已经连接到数据库 “db1”,用户 “postgres18”.
db1=# \du
角色列表
角色名称 | 属性
------------+--------------------------------------------
postgres18 | 超级用户, 建立角色, 建立 DB, 复制, 绕过RLS
u1 |
而在 MySQL 中,用户则是 实例级别 的(注意,这里的一个 MySQL 实例对应的是 PostgreSQL 的一个 database 的逻辑层级)。用户及其权限的管理基本被限定在单个实例内部。
总结
希望这次通过对比的方式,能够帮助从 MySQL 转向 PostgreSQL 的开发者快速建立起两者在核心对象上的对应关系认知。简单总结一下:
- PostgreSQL 的
database ≈ 一个完整的 MySQL 实例(隔离级别)
- PostgreSQL 的
schema ≈ MySQL 的 database / schema(组织级别)
- PostgreSQL 的
user (角色):全局存在。
- MySQL 的
user:实例内存在。
理清这些基础概念的对应关系,是后续进行库表设计、权限规划和运维管理的重要前提。如果你在迁移或学习过程中还有其他困惑,欢迎到 云栈社区 的数据库板块与大家一同交流探讨。
 发表于 2026-2-9 07:08:55
|
查看: 186|
回复: 0
发表于 2026-2-9 07:08:55
|
查看: 186|
回复: 0
