xxl-job 是一款在 Java 开发中广泛使用的分布式任务调度框架。它的核心功能,就是帮你定时、可靠地触发并执行预设的任务。很多人可能只是简单地配置和使用它,那它底层究竟是怎么运转的呢?
咱们先把结论放这儿:xxl-job 调度中心本质上是一个 Spring Boot 应用,其 Web 界面由 Spring MVC 负责渲染。而在 Spring Boot 应用启动时,它会额外创建两类关键的线程来驱动整个调度引擎。
第一类:一个以秒为单位的“死循环”线程。它每秒醒来一次,核心工作就是去数据库里“扫一眼”,检查有没有任务到了该执行的时间点。
第二类:由两个线程池构成的执行器——一个“快”线程池,一个“慢”线程池。系统会记录每个历史任务的执行耗时,并将新任务智能地分配到对应的池子里。这样做的目的,是让耗时短的任务和耗时长任务相互隔离,避免“一颗老鼠屎坏了一锅粥”。
逻辑详细解析
当我们查看 JobScheduleHelper 的启动代码时,会发现它启动了多种辅助线程,但我们最需要关注的是最后一个——核心调度线程。
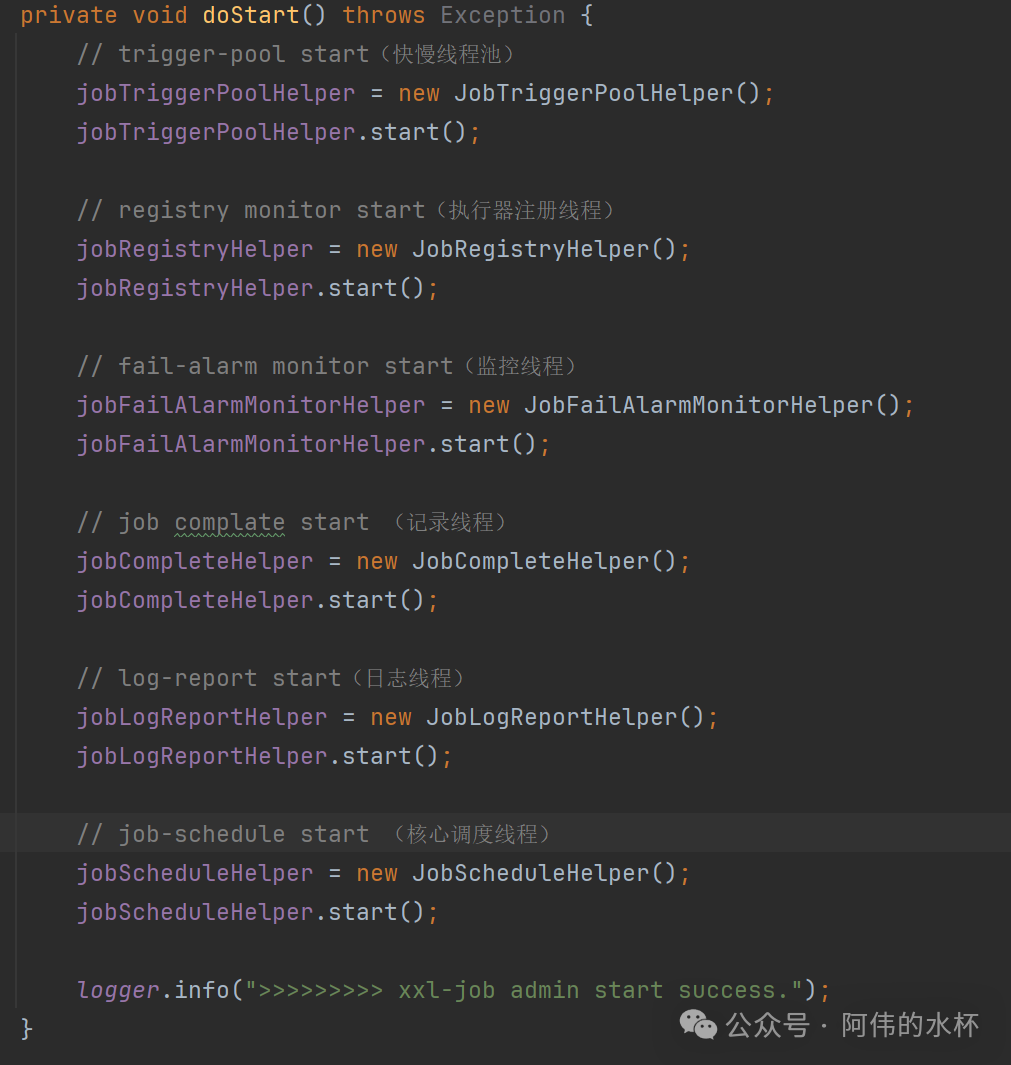
核心调度线程:一个精密的循环
这个线程的主体是一个 while 循环,它不断执行两个核心步骤:加锁和等待。
第一步:获取分布式锁
因为 xxl-job 的调度中心支持多机部署以实现高可用,所以同一时间只能有一台机器上的调度线程真正干活,这就需要用锁来协调。它没有依赖 Redis,而是巧妙地使用了 MySQL 的 SELECT ... FOR UPDATE 行锁来实现。
<select id="scheduleLock" resultType="java.lang.String">
SELECT * FROM xxl_job_lock WHERE lock_name = 'schedule_lock' FOR UPDATE
</select>
这条 SQL 会在事务中锁定 schedule_lock 这条记录。在多机环境下,只有一个线程的事务能成功加锁,其他线程会阻塞等待,直到锁被释放。
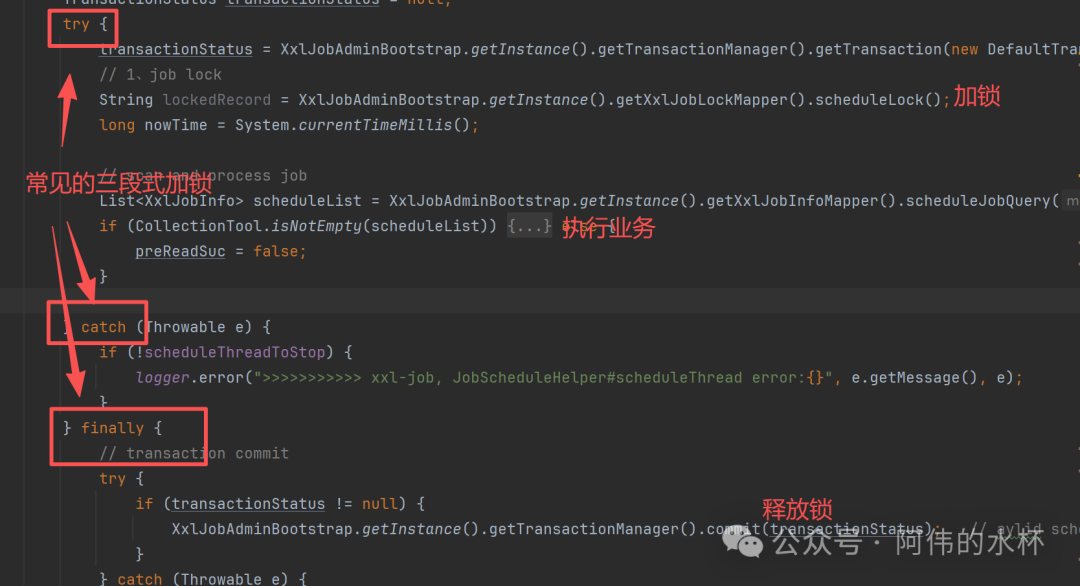
从代码结构可以看出,它采用了经典的 try...finally 模式来确保锁的释放。巧妙之处在于,它把整个调度逻辑都包裹在了一个数据库事务里。注意看 finally 块,无论业务代码执行成功还是抛出异常,事务最终都会提交。
你可能会问:如果提交时系统挂了呢?这正是设计的精妙之处。如果 xxl-job 进程崩溃,MySQL 会检测到会话丢失或事务超时,从而自动回滚这个未完成的事务。事务一回滚,FOR UPDATE 锁自然也就释放了。这样,仅依靠 MySQL 和事务机制,就实现了一个简单可靠的 分布式锁。
第二步:等待与时间对齐
拿到锁之后,线程并不是立刻开始下一轮循环,而是需要“等待”一下,以避免空转导致 CPU 占用过高。它的目标是精确地在每个整秒的时刻醒来。
// Wait seconds, align second
if (cost < 1000) { // scan-overtime, not wait
try {
// pre-read period: success > scan each second; fail > skip this period;
TimeUnit.MILLISECONDS.sleep((preReadSuc?1000:PRE_READ_MS) - System.currentTimeMillis()%1000);
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
这段代码的逻辑是:如果上一轮调度总耗时(cost)已经超过了1秒,说明“忙不过来”了,那就别睡了,赶紧继续下一轮工作。如果耗时少于1秒,则计算当前时间戳对1000毫秒取模的余数(即这一秒已经过去了多少毫秒),然后睡眠剩余的时间,这样醒来时恰好是下一个整秒。
这里还有一个重要的性能优化:线程在查询数据库时,并不是只查“当前这一秒”要执行的任务,而是会一次性预读取未来5秒内所有需要执行的任务。这些任务会被提前加载到内存中的一个“等待池”里。
三层调度架构解析
现在我们可以总结一下整体的调度执行逻辑了:
- 核心调度线程 不断循环,每次获取锁后,从数据库查询未来5秒内需要执行的任务,然后放入 内存等待池。如果没查到任务,就睡眠到下一秒再查。(注意:被查出来放入内存池的任务,其数据库中的“下次触发时间”会被立刻更新,这样就不会被重复查询到)。
- 内存等待池 会由一个独立的线程监控,它会实时检查池中任务的实际触发时间。一旦某个任务的确切执行时间点到了,就把它捞出来。
- 捞出来的任务,会根据其历史执行表现,被投递到最终的 快线程池 或 慢线程池 中真正执行。
为什么要设计成这样三层结构?好处很明显:
- 减少数据库压力:入口处批量查询5秒的任务,将高频的“每秒查询一次”变成了低频率的批量操作。
- 解耦与缓冲:内存等待池将耗时的数据库I/O操作与精确的时间触发逻辑解耦。即使某次数据库查询慢了零点几秒,只要任务在5秒内被加载进内存,依然能保证在精确的时间点被触发。
- 执行隔离:快慢线程池是最终的执行阵地,到了这里就只关心“执行”本身,不再受定时逻辑的干扰。
快慢线程池的隔离策略
所有任务第一次执行时,都会进入快执行池。执行完毕后,系统会记录它是否超时(默认超时阈值为500ms)。如果一个任务在1分钟内累计超时次数超过10次,它就会被“降级”到慢执行池。
这样设计的初衷是为了隔离“快任务”和“慢任务”。那些响应迅速的任务可以在快池中得到及时处理,保证调度的实时性;而那些本身就比较耗时的任务,反正延迟已经较高,就把它们统一赶到慢池里慢慢执行,避免它们阻塞快池中的其他任务。
任务的最终执行过程
当任务被提交到线程池后,执行线程会进行一系列操作:
- 根据配置获取目标执行器的地址(可能涉及路由策略,如轮询、故障转移等)。
- 准备好任务参数、重试策略等信息。
- 通过 HTTP 调用向目标执行器发起远程请求。
- 同步等待执行器返回结果。
- 将执行结果(成功/失败)记录到数据库日志中,至此,一次完整的调度周期结束。
线程池的配置决定了系统的并发处理能力。下面是快线程池的初始化代码:
new ThreadPoolExecutor(
10,
XxlJobAdminBootstrap.getInstance().getTriggerPoolFastMax(),
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-job, admin TriggerPool FastThread");
}
},
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 记录日志,任务被拒绝
}
}
);
可以看到,快线程池的核心线程数是10,最大线程数可配置,任务队列容量为2000。慢线程池的配置类似,但最大线程数通常更小(如100)。这意味着每个池子能同时执行的任务数量是有限的,超出承载能力的任务会被拒绝,这本身就是一种保护机制。
整个 xxl-job 调度中心的设计哲学,始终围绕着 “风险隔离” 与 “资源保护” 这两个核心点。通过分层、分池的策略,在尽力保证任务按时触发的同时,确保单个任务的异常不会扩散、系统资源不被耗尽。这种在 Spring Boot 应用内部构建复杂异步逻辑的思路,非常值得我们在设计自身业务系统时借鉴。

作为开发者,阅读并理解像 xxl-job 这样优秀的 开源实战 项目源码,是提升架构设计能力的最佳途径之一。希望这次对调度原理的剖析,能帮助你更深入地使用这个强大的工具。如果你对 MySQL 实现分布式锁或者其他分布式系统设计细节有更多兴趣,欢迎在云栈社区继续交流探讨。
 发表于 2026-2-11 10:24:28
|
查看: 208|
回复: 0
发表于 2026-2-11 10:24:28
|
查看: 208|
回复: 0
