最近一位律师朋友向我吐槽,即便在AI和数字化普及的今天,很多垂直行业的数据采集依然严重依赖人工。专利信息就是典型例子:律师或分析师需要分别访问美国专利商标局(USPTO)、谷歌专利(Google Patents)等各国网站,手动查询、记录,最后再汇总到Excel表格中。这个过程重复、琐碎,面对的是上百个国家、上亿条的数据量,效率极低。
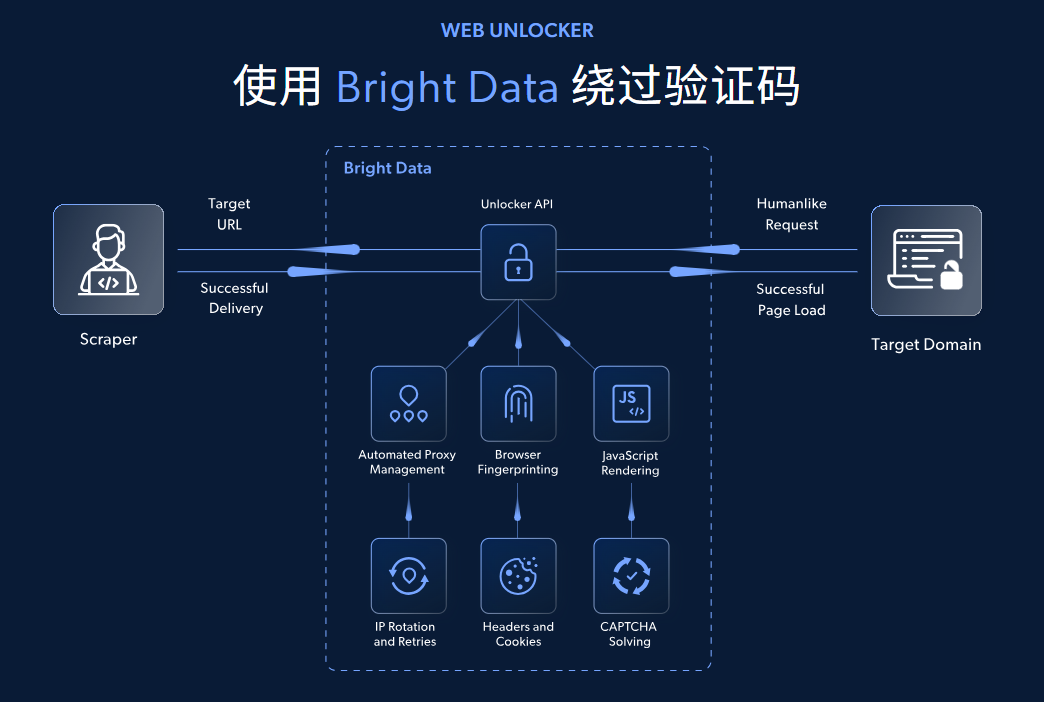
一个很自然的疑问是:为什么没有一个整合平台来统一采集和处理这些公开的专利数据?这背后其实存在三大技术难点。首先,数据源极其分散,且格式各异,有纯文本、数字表格、动态页面等,难以用统一方式高效检索。其次,各大专利数据库都设有严密的反爬虫机制,例如JavaScript动态渲染、CAPTCHA验证码、IP封锁以及浏览器指纹检测,极大地增加了自动化采集的难度。最后,数据采集过程必须保证合规与安全,既不能干扰目标网站的正常运行,也要遵循不同国家或地区的法规要求。
因此,我决定动手开发一个工具,尝试解决这个问题。我的方案是使用Python结合亮数据(Bright Data)的网页解锁(Web Unlocker)API来构建一个桌面GUI系统。该系统支持通过专利号或关键词检索多个专利源的信息,并将结果统一展示,同时提供一键导出为Excel的功能。
技术选型与思路
核心工具链选择了requests、pandas和tkinter。requests库负责通过亮数据API发送请求,直接绕过复杂的反爬机制,并确保请求的合规性。pandas则用于处理采集到的数据,进行格式转换和清洗。而tkinter作为Python的标准GUI库,足够轻量,非常适合构建这类功能明确的小型桌面应用。
整个项目的关键点在于如何稳定、合规地获取网页数据。这正是亮数据网页解锁API的价值所在。它将应对各类反爬技术(如代理IP池、验证码破解、浏览器指纹管理等)的复杂逻辑封装成了一个简单的API接口。开发者只需调用这个API,就能像真实用户一样访问目标页面,从而将精力集中于业务逻辑与数据分析,而非与反爬策略“斗智斗勇”。
需要强调的是,本文分享的GUI系统仅为个人技术研究的Demo版本,不用于任何商业用途。
准备工作与环境配置
-
Python环境:建议使用Python 3.8或更高版本。通过pip安装以下必要的第三方库(tkinter通常随Python安装,无需额外安装)。
requests: 用于发送HTTP请求,与亮数据API交互。beautifulsoup4: 用于解析返回的HTML内容。pandas: 用于数据处理和Excel导出。openpyxl: pandas导出Excel所需的引擎。
安装命令:
pip install requests beautifulsoup4 pandas openpyxl
-
获取亮数据API密钥:访问亮数据官网注册账号。登录控制台后,创建一个“Web Unlocker”代理基础设施项目。创建成功后,你将获得一个专属的API Key和Zone名称,这是调用服务的凭证,请妥善保存。
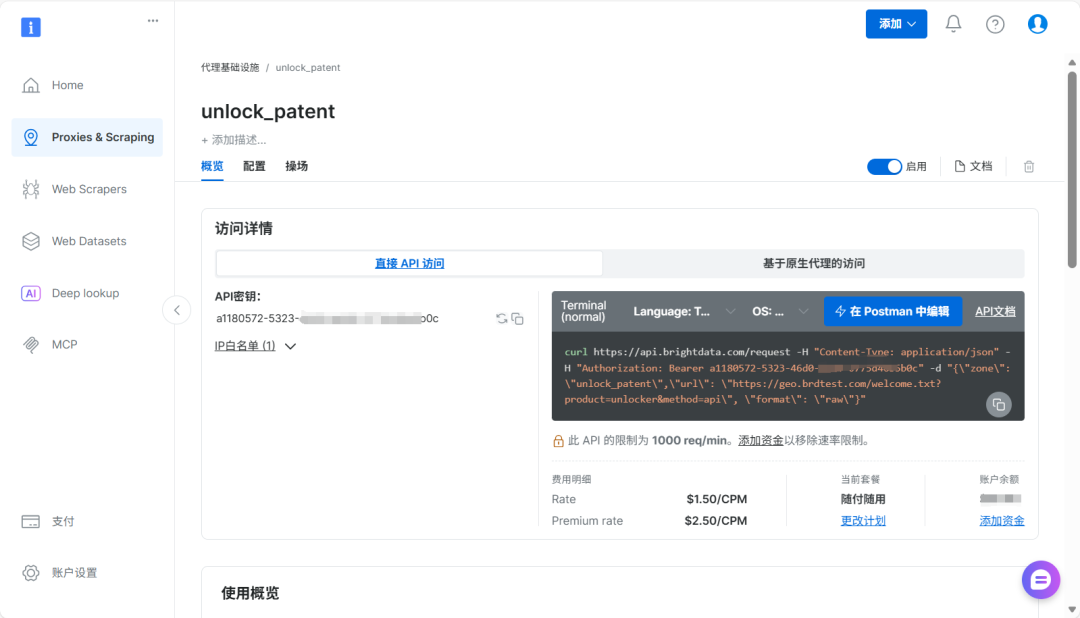
控制台会提供各语言的调用示例代码,这可以作为我们编写采集模块的绝佳起点。
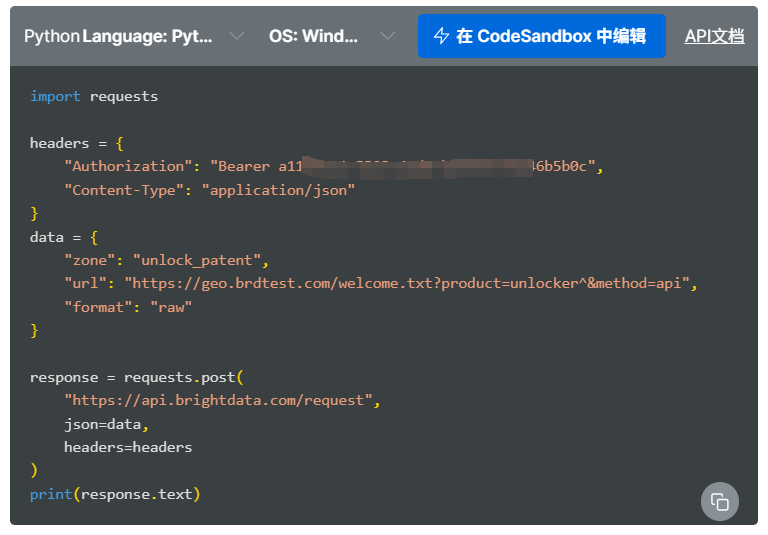
注意:免费试用账号通常有流量或频率限制,正式使用需根据需求购买相应套餐。
- 项目结构规划:创建一个清晰的项目目录,例如
patent_search_system,并在其中创建以下模块文件:
main.py: 程序主入口,启动GUI。patent_scraper.py: 封装亮数据API请求的核心模块。parser.py: 网页数据解析模块,针对不同数据源定制。gui_interface.py: GUI界面实现模块。excel_exporter.py: 数据导出模块。config.py: 配置文件,存放API密钥等敏感信息(注意不要提交到版本控制)。
系统设计与核心实现
本次Demo主要对接两个数据源:USPTO和Google Patents。为了系统具有良好的扩展性,我们采用了抽象工厂模式。为每个数据源实现统一的接口,包括:
detect_query_type(): 自动判断输入是专利号还是关键词。search(): 执行检索并解析返回的专利数据。batch_search(): 处理批量查询任务。
这样的设计使得未来新增数据源(如EPO、WIPO)时,只需添加新的解析类,而无需修改主程序逻辑。
为了实现跨数据源的统一展示,我们定义了一个标准的专利数据结构:
| 字段名 |
说明 |
数据类型 |
patent_number |
专利号 |
字符串 |
title |
专利标题 |
字符串 |
country |
国别(如 CN, US, EP) |
字符串 |
application_date |
申请日期 |
日期字符串 |
inventors |
发明人列表 |
列表 |
technology_field |
技术领域 |
字符串 |
source |
数据来源(如 “USPTO”) |
字符串 |
query_type |
查询类型(“fuzzy”/“exact”) |
字符串 |
所有数据源的解析结果都将被转换为此格式。
1. 封装Web Unlocker调用
这是数据采集的基石。我们创建一个PatentScraper类,封装与亮数据API的交互。
# patent_scraper.py
import requests
from typing import Literal, Optional
from config import BRIGHT_DATA_API_KEY, UNLOCKER_ZONE, UNLOCKER_ENDPOINT
class PatentScraper:
def __init__(self, api_key: str = BRIGHT_DATA_API_KEY, zone: str = UNLOCKER_ZONE):
self.api_key = api_key
self.zone = zone
self.endpoint = UNLOCKER_ENDPOINT
self.headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
def fetch(self,
url: str,
method: Literal["GET", "POST"] = "GET",
body: Optional[str] = None,) -> str:
payload = {
"zone": self.zone,
"url": url,
"format": "raw", # 返回原始 HTML
"method": method,
}
if body:
payload["body"] = body
response = requests.post(self.endpoint, headers=self.headers, json=payload)
return response.text
2. 实现数据解析器
针对不同的数据源,编写相应的解析函数。以Google Patents为例:
# parser.py (部分代码)
from bs4 import BeautifulSoup
from typing import Dict, Any, List
def parse_google_patent(html: str) -> Dict[str, Any]:
soup = BeautifulSoup(html, "html.parser")
result = {}
# 专利号 & 国别
patent_number = None
country = None
title_tag = soup.find("meta", {"itemprop": "publicationNumber"})
if title_tag and title_tag.get("content"):
pub = title_tag["content"] # 例如 "US1234567A"
patent_number = pub
country = pub[:2] # 简单取前两位作为国别代码
result['patent_number'] = patent_number
result['country'] = country
# 申请日
application_date = None
app_date_meta = soup.find("meta", {"itemprop": "filingDate"})
if app_date_meta and app_date_meta.get("content"):
application_date = app_date_meta["content"]
result['application_date'] = application_date
# 发明人
inventors: List[str] = []
for inv in soup.select("[itemprop='inventor']"):
name_tag = inv.find(attrs={"itemprop": "name"})
if name_tag:
inventors.append(name_tag.get_text(strip=True))
result['inventors'] = list(dict.fromkeys(inventors)) # 去重
# ... 解析标题、技术领域等其他字段
result['source'] = 'Google Patents'
return result
3. 开发数据导出功能
利用pandas,可以非常轻松地将结果列表导出为Excel文件。
# excel_exporter.py
import pandas as pd
from typing import List, Dict
import os
def export_to_excel(results: List[Dict], filename: str):
"""将专利搜索结果导出到Excel文件"""
if not results:
raise ValueError("没有数据可导出")
# 准备DataFrame
df_data = []
for idx, result in enumerate(results, 1):
row = {
'序号': idx,
'专利号': result.get('patent_number', ''),
'标题': result.get('title', ''),
'国别': result.get('country', ''),
'申请日期': result.get('application_date', ''),
'发明人': ', '.join(result.get('inventors', [])),
'技术领域': result.get('technology_field', ''),
'来源': result.get('source', ''),
'查询类型': result.get('query_type', ''),
}
df_data.append(row)
df = pd.DataFrame(df_data)
# 确保目录存在
os.makedirs(os.path.dirname(os.path.abspath(filename)), exist_ok=True)
df.to_excel(filename, index=False)
print(f"数据已成功导出至: {filename}")
4. 构建GUI交互界面
最后,使用tkinter将上述模块整合成一个可视化的桌面应用。
# gui_interface.py (部分代码)
import tkinter as tk
from tkinter import ttk, scrolledtext, messagebox, filedialog
import threading
from patent_scraper import MultiSourcePatentEngine # 假设有一个整合了多个源的引擎类
class PatentSearchGUI:
def __init__(self, root):
self.root = root
self.root.title("专利数据采集系统")
self.root.geometry("1000x700")
# 创建专利搜索引擎实例
self.engine = MultiSourcePatentEngine()
self.results = []
self.setup_ui()
def setup_ui(self):
# 创建查询设置、输入框、按钮、结果表格、日志区域等控件
# ... (详细的UI布局代码)
pass
def on_search(self):
# 绑定搜索按钮事件,在新线程中执行搜索,避免GUI卡顿
keyword = self.entry.get()
if not keyword:
messagebox.showwarning("提示", "请输入查询关键词或专利号!")
return
def search_task():
self.log("开始搜索...")
try:
results = self.engine.search(keyword)
self.results = results
# 更新结果表格
self.update_result_table(results)
self.log(f"搜索完成,共找到 {len(results)} 条结果。")
except Exception as e:
self.log(f"搜索出错: {e}")
messagebox.showerror("错误", f"搜索过程中发生错误: {e}")
threading.Thread(target=search_task, daemon=True).start()
def on_export(self):
# 绑定导出按钮事件
if not self.results:
messagebox.showinfo("提示", "没有数据可导出")
return
filename = filedialog.asksaveasfilename(defaultextension=".xlsx",
filetypes=[("Excel文件", "*.xlsx")])
if filename:
try:
export_to_excel(self.results, filename)
messagebox.showinfo("成功", f"数据已导出至:\n{filename}")
except Exception as e:
messagebox.showerror("导出失败", str(e))
# ... 其他方法
运行与效果展示
完成所有模块开发后,在main.py中启动GUI程序。
# main.py
from gui_interface import PatentSearchGUI
import tkinter as tk
if __name__ == "__main__":
root = tk.Tk()
app = PatentSearchGUI(root)
root.mainloop()
运行main.py,即可打开我们构建的专利数据采集系统。
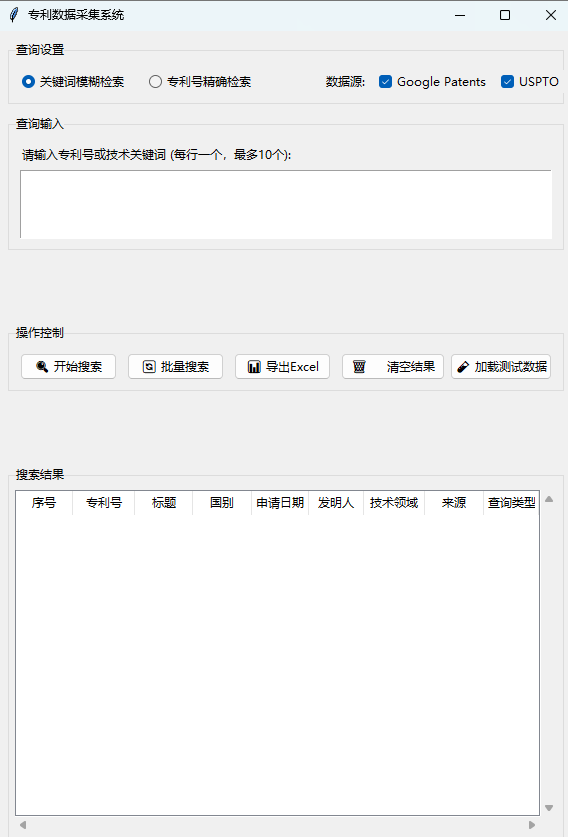
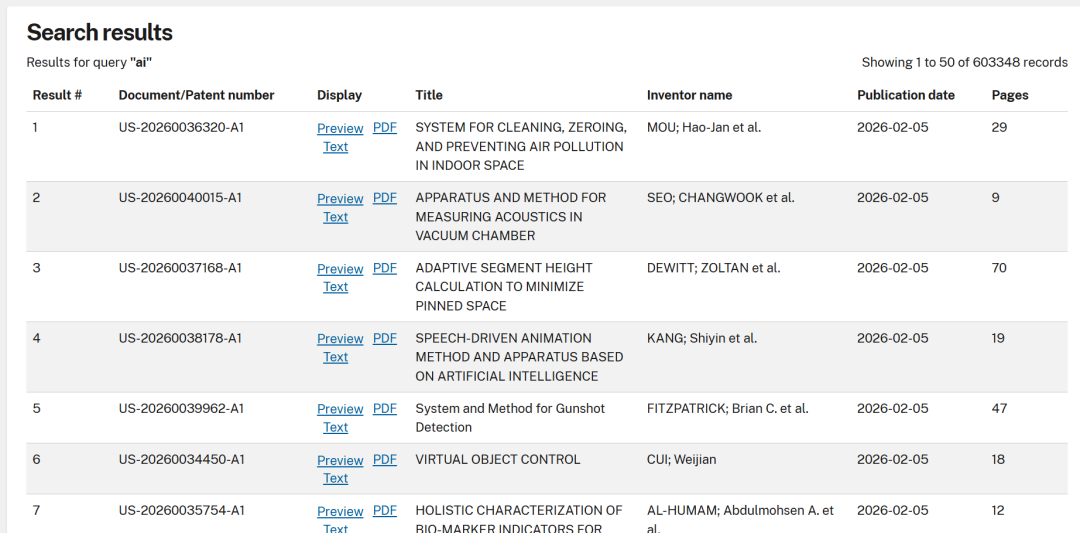
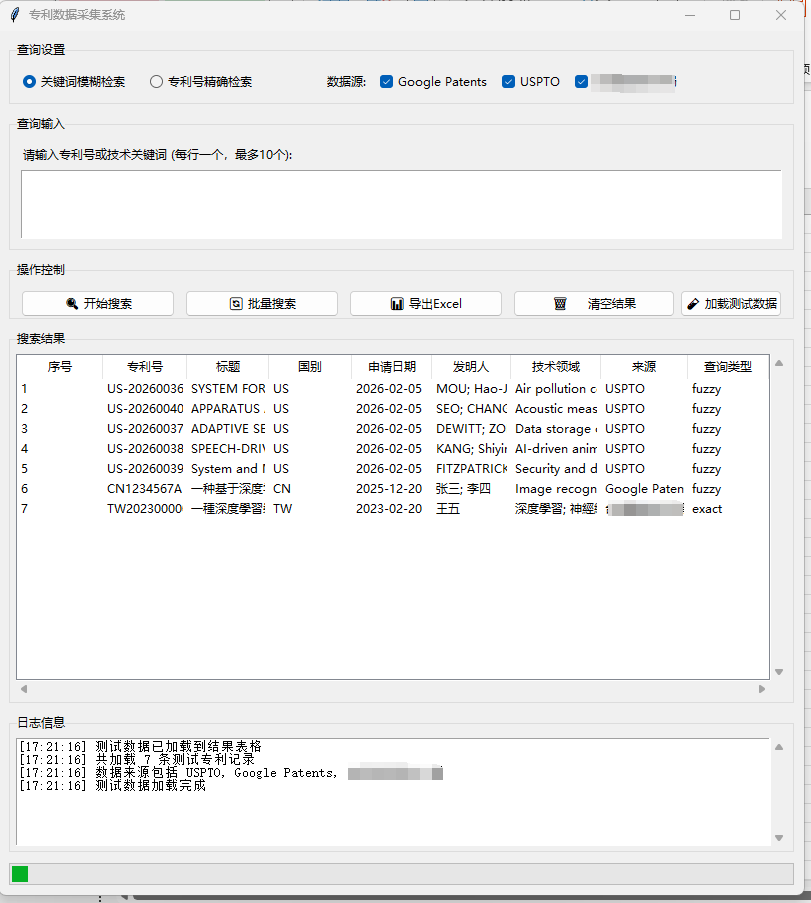
在查询输入框中输入技术关键词(例如“AI”),选择数据源和查询类型,点击“开始搜索”。系统会通过亮数据API并行查询多个专利数据库,并将解析、清洗后的结果统一展示在表格中。
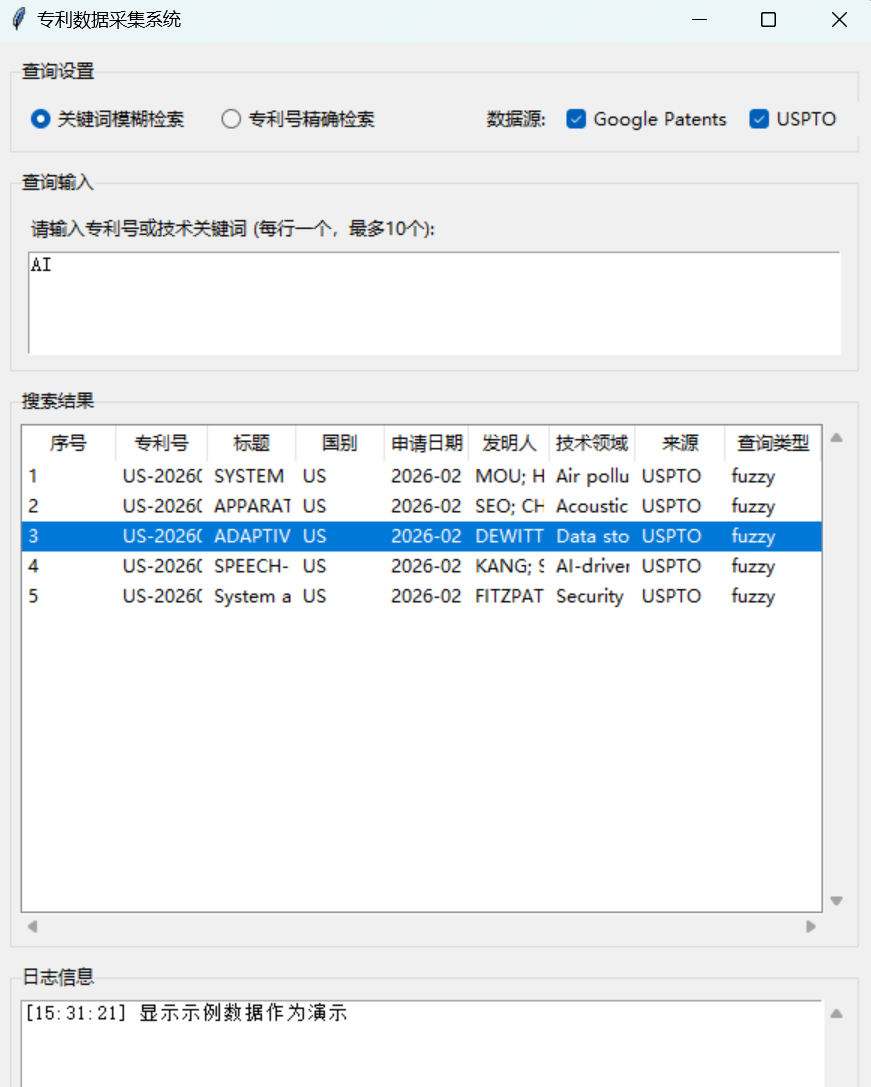
点击“导出Excel”,即可将所有搜索结果保存为结构清晰的电子表格,供后续分析使用。
总结
通过这个项目,我们成功利用Python和亮数据的Web Unlocker API,构建了一个能够自动、合规地采集多源专利数据,并具备友好图形界面的工具。它虽然是一个简化版本,但清晰地展示了如何将分散的数据源、复杂的反爬机制与最终的用户需求连接起来,形成一个可用的数据采集解决方案。这不仅是技术上的实践,也为解决类似的数据整合难题提供了一种可行的思路。
如果你想了解更多关于Python自动化或网络数据采集的实战技巧,欢迎来云栈社区交流探讨。
 发表于 2026-2-11 10:38:07
|
查看: 269|
回复: 0
发表于 2026-2-11 10:38:07
|
查看: 269|
回复: 0
