
你是否曾看着你的 Python 程序,在等待网络请求或读写文件时“傻傻地”挂起,而 CPU 却在悠闲地“喝茶”?今天,我们就来聊聊如何用 asyncio 打破这种“同步阻塞”的魔咒,让你的程序学会“一心多用”。
你是否也曾遇到过这样的场景?写了一个网络爬虫,每个请求都要等前一个完成才能继续,速度慢得像蜗牛;或者开发了一个 Web API,同时处理多个请求时就卡顿不堪。如果你曾为此烦恼,那么今天的内容将彻底改变你对 Python 并发编程的认知。
引言:从“单线程排队”到“协作并发”
想象一下,你有一个网络爬虫程序。在传统的同步模式下,它就像只有一个收银员的超市:处理完一个顾客(下载完一个网页)后,才能服务下一个。即使这个顾客只是在掏钱(网络 I/O 等待),收银员也只能干等着。
异步编程改变了这个模式。它让一个“收银员”(主线程)可以同时服务多个“顾客”(任务)。当一个顾客在掏钱时,收银员可以转身去给另一个顾客结账。这就是 asyncio 带给我们的核心能力:在单个线程内通过协作式调度,实现高效的并发 I/O 操作。
同步 vs 异步:到底差在哪里?
在深入了解 asyncio 之前,我们先搞清楚一个基本问题:同步和异步编程到底有什么不同?
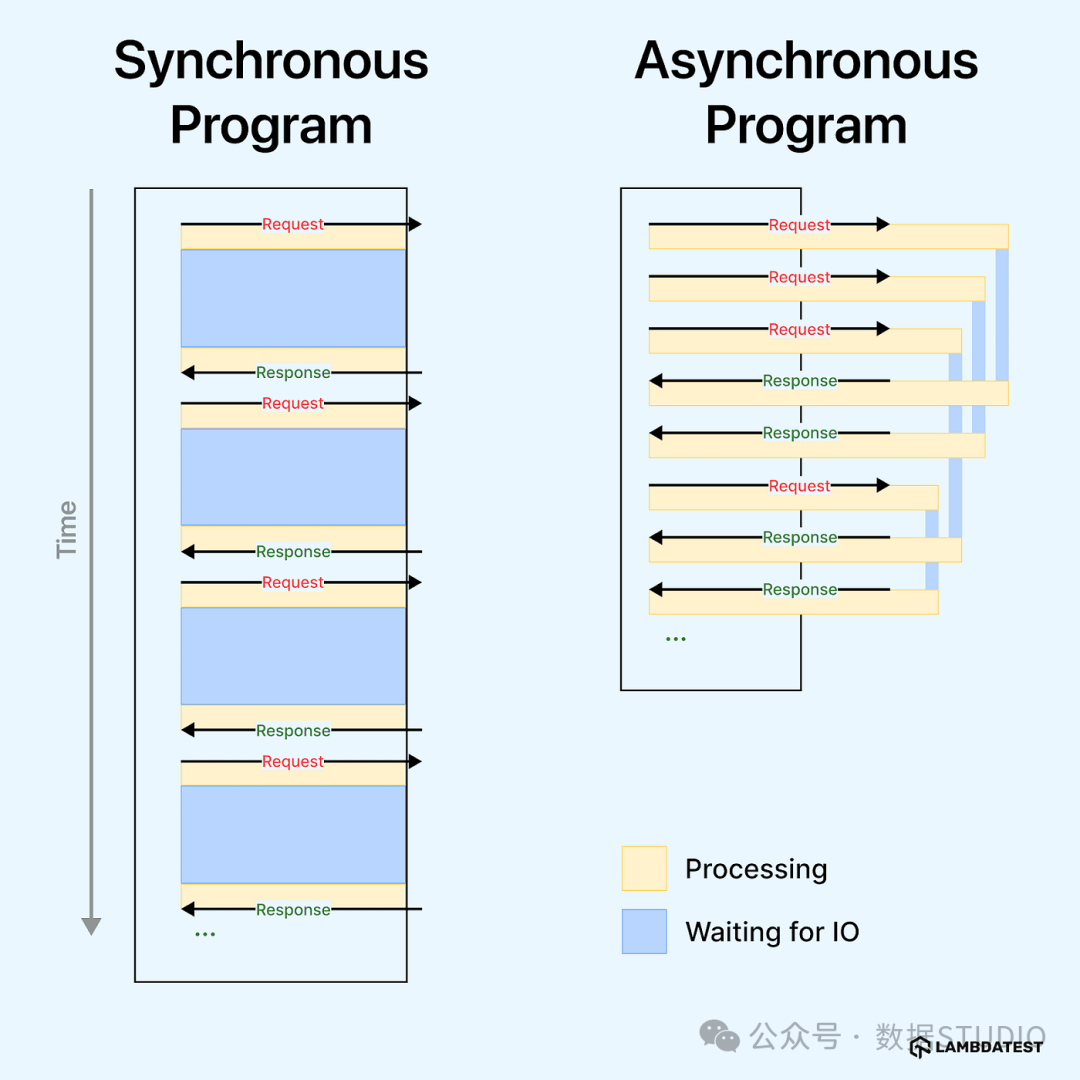
想象一下你去餐厅点餐:
- 同步方式:你点了一道菜,然后就在柜台前死等,直到厨师做好、服务员端给你,你才点下一道菜。这期间你什么都做不了。
- 异步方式:你点完菜后拿到一个取餐号,然后去找座位、玩手机、或者点其他菜。当菜做好时,服务员会叫你的号码。
这就是同步和异步的本质区别!
在代码层面,同步程序执行任务时,每个任务必须完全完成(包括等待 I/O 的时间)才能开始下一个。而异步程序可以在任务等待时切换到其他任务,让多个任务并发执行。
# 同步方式:一个接一个执行
import time
def sync_task(n):
print(f"任务{n}开始")
time.sleep(1) # 模拟I/O等待
print(f"任务{n}结束")
return n
# 顺序执行,总共需要3秒
start = time.time()
result1 = sync_task(1)
result2 = sync_task(2)
result3 = sync_task(3)
print(f"同步执行耗时: {time.time() - start:.2f}秒")
# 异步方式:并发执行
import asyncio
async def async_task(n):
print(f"异步任务{n}开始")
await asyncio.sleep(1) # 异步等待
print(f"异步任务{n}结束")
return n
async def main():
start = time.time()
# 同时启动三个任务
tasks = [
async_task(1),
async_task(2),
async_task(3)
]
results = await asyncio.gather(*tasks)
print(f"异步执行耗时: {time.time() - start:.2f}秒")
print(f"结果: {results}")
# 运行异步程序
asyncio.run(main())
运行上面的代码,你会看到同步方式需要大约 3 秒,而异步方式只需要大约 1 秒!这就是异步编程的魅力所在。对于开发需要处理大量网络连接的后端服务,这种效率提升是革命性的。
一、核心概念:事件循环与协程
要理解 asyncio,必须先掌握它的两个心脏:事件循环(Event Loop) 和 协程(Coroutine)。
1. 协程:可暂停和恢复的函数
普通函数(子程序)从开头跑到结尾,一次执行完毕。协程则不同,它可以在执行过程中暂停(await),将控制权交出去,等时机合适时再恢复,从暂停的地方继续执行。
定义一个协程很简单,只需使用 async def:
import asyncio
# 这是一个协程函数
async def fetch_data(url):
print(f'开始获取: {url}')
# await 是协程的“暂停点”
await asyncio.sleep(2) # 模拟网络请求的等待
print(f'获取完成: {url}')
return f'{url}的数据'
# 运行协程需要事件循环
asyncio.run(fetch_data('https://example.com'))
关键点:
- 协程用
async def 定义
- 使用
await 来暂停协程,等待异步操作完成
- 协程本身不会执行,需要事件循环来驱动
2. 事件循环:背后的总指挥
你可以把事件循环想象成交响乐团的指挥。它掌握着所有乐手(协程任务)的乐谱,指挥哪个乐手该演奏(执行),哪个该休息(等待 I/O)。它的工作就是不停地循环,检查哪些协程的“等待”结束了,然后让它们继续执行。
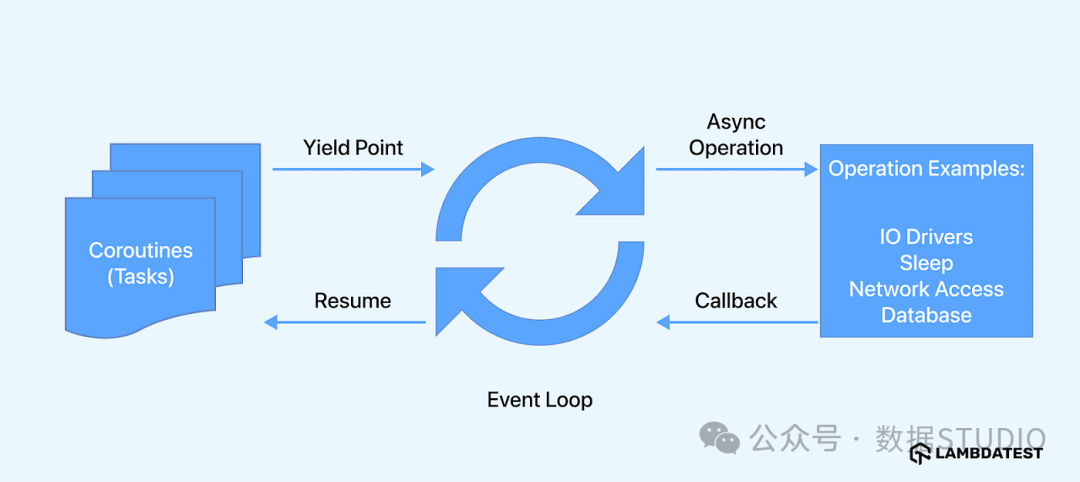
事件循环的工作流程:
- 维护一个任务队列。
- 从队列中取出一个就绪的任务执行。
- 当任务遇到
await 时,将其挂起,并记录它正在等待什么(比如一个计时器或 Socket 数据)。
- 立即切换到队列中的下一个任务。
- 当外部事件发生(如计时器到期、网络数据到达),将对应的任务标记为就绪,重新放回队列。
- 重复步骤 2-5。
import asyncio
async def task(name, seconds):
print(f"{name}: 开始等待{seconds}秒")
await asyncio.sleep(seconds)
print(f"{name}: 等待结束")
return f"{name}完成"
async def main():
print("=== 事件循环演示 ===")
# 创建多个任务
tasks = [
task("快速任务", 1),
task("中等任务", 2),
task("慢速任务", 3)
]
# 事件循环会同时管理这三个任务
# 它们会并发执行,而不是顺序执行
results = await asyncio.gather(*tasks)
print(f"所有任务完成: {results}")
asyncio.run(main())
二、实战核心:创建与管理任务(Task)
协程本身不会并发执行,它需要被包装成 Task 并由事件循环调度。Task 是 asyncio 进行并发编程的主要载体。
1. 创建任务:asyncio.create_task()
这是最常用的方法,它将一个协程“打包”成任务,并立即交给事件循环去调度执行(注意:是立即调度,并非立即执行)。
import asyncio
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
# 创建任务,它们开始“在后台”运行
task1 = asyncio.create_task(say_after(1, 'Hello'))
task2 = asyncio.create_task(say_after(2, 'World'))
print('任务已创建,主协程继续运行...')
# 等待两个任务都完成
await task1
await task2
print('所有任务完成!')
asyncio.run(main())
关键点:create_task 后如果不 await 或不保存任务对象的引用,该任务可能被垃圾回收而无法完成。对于“发后即忘”的任务,务必将其加入一个集合来保持引用。
# 错误示例:任务可能永远不会执行
async def wrong_way():
# 没有保持引用,任务可能被垃圾回收
asyncio.create_task(download_file("file.txt", 1))
await asyncio.sleep(0.1) # 时间太短,任务可能来不及执行
# 正确示例:保持任务引用
async def right_way():
task = asyncio.create_task(download_file("file.txt", 1))
await task # 明确等待任务完成
2. 并发收集结果:asyncio.gather()
当你需要并发运行多个协程并统一收集它们的结果时,gather 是你的好帮手。
import asyncio
async def factorial(name, number):
result = 1
for i in range(2, number + 1):
print(f'任务 {name}: 计算 factorial({number}),当前 i={i}')
await asyncio.sleep(1) # 模拟计算耗时
result *= i
print(f'任务 {name}: factorial({number}) = {result}')
return result
async def main():
# 并发执行三个阶乘计算
results = await asyncio.gather(
factorial("A", 2),
factorial("B", 3),
factorial("C", 4),
)
print(f'最终结果列表: {results}') # 结果顺序与传入顺序一致
asyncio.run(main())
3. 更安全的选择:任务组(TaskGroup)【Python 3.11+】
TaskGroup 是更现代、更安全的管理一组任务的方式。它最大的优点是:如果组内任何一个任务抛出异常,所有其他任务都会被自动取消,避免了资源泄露。
import asyncio
async def worker(name, seconds):
await asyncio.sleep(seconds)
print(f'{name} 完成')
return f'{name}-result'
async def main():
try:
async with asyncio.TaskGroup() as tg: # 进入任务组上下文
# 在组内创建任务
task1 = tg.create_task(worker("任务1", 1))
task2 = tg.create_task(worker("任务2", 2))
# 退出上下文时,自动等待所有任务完成
except* Exception as eg: # 注意这里使用 except* 处理任务组异常
print(f'有任务出错: {eg.exceptions}')
else:
print(f'所有任务成功,结果: {task1.result()}, {task2.result()}')
asyncio.run(main())
TaskGroup 的优点:
- 自动等待所有任务完成
- 如果一个任务失败,自动取消所有其他任务
- 提供更清晰的异常处理
4. 并发执行模式对比
asyncio 提供了多种并发执行模式,适用于不同场景:
import asyncio
async def worker(name, processing_time):
"""模拟工作进程"""
print(f"{name}: 开始处理")
await asyncio.sleep(processing_time)
print(f"{name}: 处理完成")
return f"{name}_结果_{processing_time}"
async def demo_gather():
"""使用gather并发执行"""
print("\n=== 使用asyncio.gather ===")
# gather会等待所有任务完成,返回结果列表
results = await asyncio.gather(
worker("任务A", 1),
worker("任务B", 2),
worker("任务C", 3),
return_exceptions=True # 将异常作为结果返回,而不是抛出
)
print(f"所有结果: {results}")
async def demo_as_completed():
"""使用as_completed按完成顺序处理"""
print("\n=== 使用asyncio.as_completed ===")
tasks = [
worker("任务X", 3),
worker("任务Y", 1),
worker("任务Z", 2)
]
# 按照完成顺序处理结果
for future in asyncio.as_completed(tasks):
result = await future
print(f"收到结果: {result}")
async def demo_wait():
"""使用wait控制执行"""
print("\n=== 使用asyncio.wait ===")
tasks = [worker(f"任务{i}", i) for i in range(1, 5)]
# 等待第一个任务完成
done, pending = await asyncio.wait(
tasks,
timeout=2.5,
return_when=asyncio.FIRST_COMPLETED
)
print(f"已完成: {len(done)}个任务")
print(f"仍在进行: {len(pending)}个任务")
# 取消剩余任务
for task in pending:
task.cancel()
async def main():
await demo_gather()
await demo_as_completed()
await demo_wait()
asyncio.run(main())
三、进阶技巧与避坑指南
1. 超时控制:别让任务无限等待
网络世界充满不确定性,必须为所有 I/O 操作设置超时。
import asyncio
async def eternity():
await asyncio.sleep(3600) # 睡1小时
print('这个任务完成了,但你等不到!')
async def main():
try:
# 方法1:使用 wait_for
await asyncio.wait_for(eternity(), timeout=1.0)
except asyncio.TimeoutError:
print('任务超时,被取消了!')
# 方法2:使用 timeout 上下文管理器 (Python 3.11+)
try:
async with asyncio.timeout(1.0):
await eternity()
except TimeoutError:
print('同样,超时了!')
# 方法3:保护某些操作不被取消
try:
async with asyncio.timeout(1):
# shield可以保护内部任务不被取消
result = await asyncio.shield(eternity())
print(f"受保护的结果: {result}")
except TimeoutError:
print("外部超时,但内部任务仍在运行...")
# 关键任务仍然在后台运行
asyncio.run(main())
2. 屏蔽取消:保护关键操作
有时,你希望即使外层任务被取消,某个关键子操作也能继续执行完成(比如写日志、关闭连接)。这时可以使用 asyncio.shield()。
import asyncio
async def critical_operation():
try:
await asyncio.sleep(2)
print('关键操作完成!')
return '重要数据'
except asyncio.CancelledError:
print('关键操作内部感知到取消请求,但我们可以选择继续执行')
await asyncio.sleep(1) # 继续完成清理
print('清理完成')
raise # 重新抛出取消异常
async def main():
task = asyncio.create_task(critical_operation())
await asyncio.sleep(0.5) # 让关键操作开始
task.cancel() # 取消任务
# 使用 shield 保护,await 会立即触发 CancelledError,
# 但被保护的任务会在后台继续运行直到完成或自己处理取消
try:
result = await asyncio.shield(task)
except asyncio.CancelledError:
print('主协程的 shield 等待被取消了')
# 但 task 可能还在运行
await asyncio.sleep(2.5) # 等足够长时间,让关键操作完成
# 现在可以安全地再 await 一次(如果任务已结束,会立刻返回)
# result = await task
asyncio.run(main())
3. 处理阻塞代码:to_thread
asyncio 的优势在于 I/O 密集型操作。如果你有一段 CPU 密集型 或调用 阻塞式 I/O 库 的代码(比如某些同步的数据库驱动),它会阻塞整个事件循环。此时,应当将其放到单独的线程中执行。
import asyncio
import time
def blocking_io_operation():
# 这是一个会阻塞的同步函数
time.sleep(2)
return "来自阻塞函数的结果"
async def main():
print('开始异步部分...')
await asyncio.sleep(1)
# 将阻塞函数丢到线程池运行,不阻塞事件循环
result = await asyncio.to_thread(blocking_io_operation)
print(f'得到结果: {result}')
print('继续处理其他异步任务...')
asyncio.run(main())
4. 实际案例:异步 Web 请求
让我们看一个更实际的例子:并发获取多个网页内容。这类操作正是异步编程大展身手的领域,它能显著优化涉及网络 I/O 的应用性能。
import asyncio
import aiohttp # 需要安装: pip install aiohttp
from datetime import datetime
async def fetch_url(session, url, timeout=5):
"""异步获取URL内容"""
try:
start = datetime.now()
async with session.get(url, timeout=timeout) as response:
content_length = len(await response.text())
elapsed = (datetime.now() - start).total_seconds()
return {
"url": url,
"status": response.status,
"size": content_length,
"time": elapsed
}
except Exception as e:
return {
"url": url,
"error": str(e),
"status": "failed"
}
async def fetch_multiple_urls(urls, max_concurrent=3):
"""并发获取多个URL"""
print(f"开始获取{len(urls)}个URL,最大并发数: {max_concurrent}")
# 创建TCP连接器,限制连接数
connector = aiohttp.TCPConnector(limit=max_concurrent)
async with aiohttp.ClientSession(connector=connector) as session:
tasks = []
for url in urls:
task = asyncio.create_task(fetch_url(session, url))
tasks.append(task)
# 等待所有任务完成
results = await asyncio.gather(*tasks, return_exceptions=True)
# 显示结果
print("\n=== 获取结果 ===")
for result in results:
if isinstance(result, dict):
if "error" in result:
print(f"失败: {result['url']} - {result['error']}")
else:
print(f"成功: {result['url']} "
f"- 状态: {result['status']} "
f"- 大小: {result['size']}字节 "
f"- 耗时: {result['time']:.2f}秒")
return results
async def main():
# 要获取的URL列表
urls = [
"https://httpbin.org/delay/1", # 延迟1秒
"https://httpbin.org/delay/2", # 延迟2秒
"https://httpbin.org/delay/3", # 延迟3秒
"https://httpbin.org/status/404", # 404错误
"https://httpbin.org/status/200", # 成功
"https://不存在的网站.com", # 会失败
]
start_time = datetime.now()
await fetch_multiple_urls(urls, max_concurrent=2)
elapsed = (datetime.now() - start_time).total_seconds()
print(f"\n总耗时: {elapsed:.2f}秒")
print("注意:虽然每个请求都有延迟,但并发执行让总时间大大减少!")
# 运行示例
asyncio.run(main())
四、常见陷阱与最佳实践
陷阱1:在异步函数中调用阻塞函数
# ❌ 错误示例
async def bad_example():
import time
await asyncio.sleep(1)
time.sleep(2) # 这会阻塞整个事件循环!
# ✅ 正确做法
async def good_example():
await asyncio.sleep(1)
# 如果必须使用阻塞函数,放到线程中
await asyncio.to_thread(time.sleep, 2)
陷阱2:忘记 await
# ❌ 错误:忘记await,协程不会执行
async def forgot_await():
coro = some_async_function()
# 缺少await!coro永远不会执行
return coro
# ✅ 正确:使用await
async def correct_way():
result = await some_async_function()
return result
陷阱3:过度并发
# ❌ 一次性创建太多任务
async def too_many_tasks():
tasks = []
for i in range(10000): # 太多!
tasks.append(asyncio.create_task(some_async_function()))
await asyncio.gather(*tasks)
# ✅ 使用信号量控制并发数
async def controlled_concurrency():
semaphore = asyncio.Semaphore(10) # 最多10个并发
async def limited_task(i):
async with semaphore:
return await some_async_function()
tasks = []
for i in range(1000):
tasks.append(asyncio.create_task(limited_task(i)))
await asyncio.gather(*tasks)
最佳实践总结
- 始终使用 async/await 语法:避免手动管理事件循环
- 合理控制并发数量:使用 Semaphore 或连接池限制
- 为所有异步操作设置超时:防止程序挂起
- 正确处理异常:使用 try/except 包装 await 调用
- 避免在异步函数中调用阻塞函数:使用 to_thread 包装
- 保持任务引用:防止任务被垃圾回收
- 使用 TaskGroup 管理相关任务(Python 3.11+)
写在最后
asyncio 为 Python 的并发编程打开了一扇新的大门。它通过单线程内协作式多任务的模型,以极小的资源开销,轻松应对成千上万的网络连接,是构建高性能网络服务(如 Web 服务器、爬虫、微服务、实时应用)的利器。
通过今天的学习,我们深入探讨了 Python asyncio 的核心概念和实用技巧。从基本的协程和事件循环,到任务管理、并发控制,再到实际应用场景,希望你已经对异步编程有了更清晰的认识。
记住,asyncio 并不是万能的银弹。它在 I/O 密集型场景(如网络请求、文件操作、数据库查询)中表现卓越,但对于 CPU 密集型任务,可能还需要考虑多进程或其他方案。
核心要点回顾:
- 异步编程的核心是在等待时做其他事
async/await 是语法基础,定义了可暂停的协程- 事件循环是发动机,负责所有协程的调度与执行
- Task 是并发单元,使用
create_task 或 TaskGroup 来创建和管理
- 善用超时与取消,保证程序的健壮性
- 隔离阻塞操作,使用
to_thread 防止事件循环被“卡住”
实践是最好的老师。建议你从一个小项目开始,比如写一个异步的网页爬虫,或者优化现有的 I/O 密集型代码。在实际操作中,你会遇到各种问题,解决它们的过程就是你真正掌握 asyncio 的过程。
异步编程的思维模式与同步编程略有不同,需要一些时间来适应。但一旦掌握,你将能编写出效率远超从前的程序。
最后的思考:异步编程是一种思维方式的转变。一旦你习惯了这种“在等待时做其他事”的模式,你会发现它能极大地提升程序性能和响应能力。虽然学习曲线有点陡峭,但掌握后的收益绝对是值得的。
下次当你看到程序在“傻等”时,不妨想想:这里能不能用异步优化?也许,一个简单的 async/await 就能让性能提升数倍!
祝你在异步编程的旅程中一帆风顺!🚀
希望这篇关于 Python asyncio 的深入解析能对你有所帮助。如果你想了解更多技术干货或与更多开发者交流,欢迎访问 云栈社区。

 发表于 2026-2-11 11:00:54
|
查看: 168|
回复: 0
发表于 2026-2-11 11:00:54
|
查看: 168|
回复: 0
