
一、从“拼接式多模态”到“原生统一”:基础模型的范式转移
过去几年,大语言模型(LLM)和多模态模型的发展,沿着两条相互交织但并未完全重合的路径前进。以GPT、Claude、ERNIE等为代表的自回归语言模型,在知识、推理和代码生成上展现了强大能力;而像CLIP、LLaVA、Gemini-Vision等系统,则在持续提升“看、听、理解世界”的水平。
当这两条路径交汇时,实践中普遍采取“语言模型+模态编码器”的方案。主流做法有两类:
第一类是早期融合,将视觉或音频特征映射到语言模型的隐空间,与文本token一起输入Transformer。第二类是晚期融合,保持语言模型相对独立,只在需要时调用视觉或音频模块。
然而,这些方案都隐藏着一个深层次的矛盾:理解是统一的,但生成是割裂的。模型在理解多模态信息时使用一种表示空间,但在生成图像、视频或音频时,却要切换到独立的扩散模型、VAE或专用解码器。训练目标、优化方式和表示空间都不一致。
这种割裂带来了显而易见的问题:
- 跨模态表示难以真正对齐,影响深度多模态推理能力。
- 训练管线复杂,需要多个模型协同优化,工程难度大。
- 部署成本高、延迟大,系统不够优雅。
- 难以有效扩展到真正的万亿参数规模。
因此,学界和产业界逐渐形成一个共识:我们需要一个“原生统一”的多模态基础模型。它应该基于同一主干、同一训练目标,同时支持理解与生成,并且具备良好的可扩展性。
ERNIE 5.0的提出,正是为了回应这一核心挑战。它试图回答一个根本性问题:能否用单一的自回归框架,同时完成文本、图像、视频和音频的理解与生成任务?
二、统一自回归建模:Next-Group-of-Tokens Prediction 的理念
ERNIE 5.0的第一个核心创新,是将所有模态都纳入统一的自回归建模范式,即 Next-Group-of-Tokens Prediction。其核心思想直接而富有野心:只要拥有足够好的tokenizer,任何模态都可以被序列化为token,并由同一个Transformer主干进行建模。
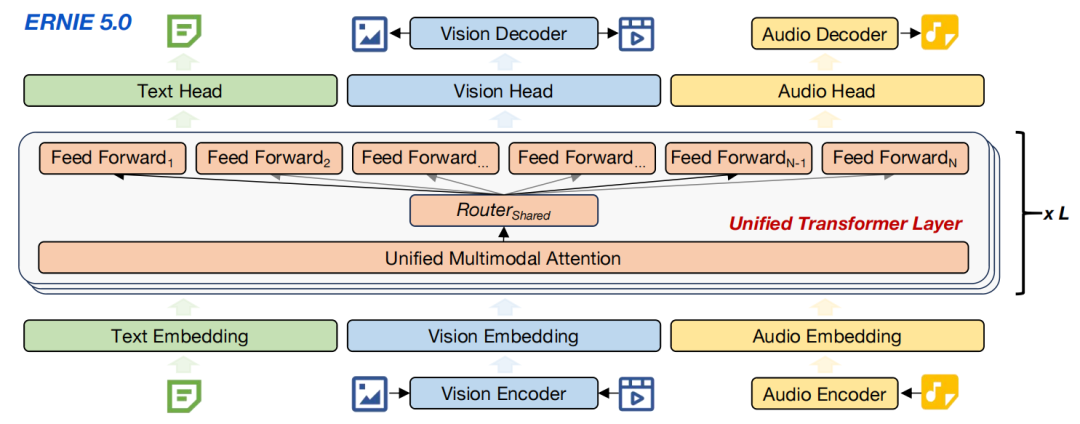
如图所示,模型从零开始就在统一自回归范式下进行训练。文本、视觉和音频首先由各自的编码器处理,并序列化为token,然后输入一个共享的超稀疏MoE主干。不同模态的token会通过一个模态无关的路由器,被动态分配到同一个专家池中进行计算。这个统一的模型既可用于多模态理解,也可直接用于图像、视频和音频的生成。
这一设计的深层意义在于:
- 不再区分“理解模型”和“生成模型”。
- 不再区分“语言主干”和“视觉/音频附属模块”。
- 不再需要多目标联合训练(例如同时使用自回归、扩散和对比学习目标)。
相反,ERNIE 5.0尝试用一个统一的序列建模目标来覆盖所有模态。从理论上看,这意味着模型不再是简单的“语言模型+感知模块”,而是一个真正的通用多模态序列建模器,其内部表示能够同时承载语义、空间、时间和声学信息。
三、视觉理解与生成的统一:从 Patch 到 Frame 的自回归
采用统一的自回归框架,并不意味着简单粗暴地“把图像当成文本来处理”。ERNIE 5.0在视觉侧进行了大量专门设计,以在融入自回归建模的同时,保留关键的空间结构信息。
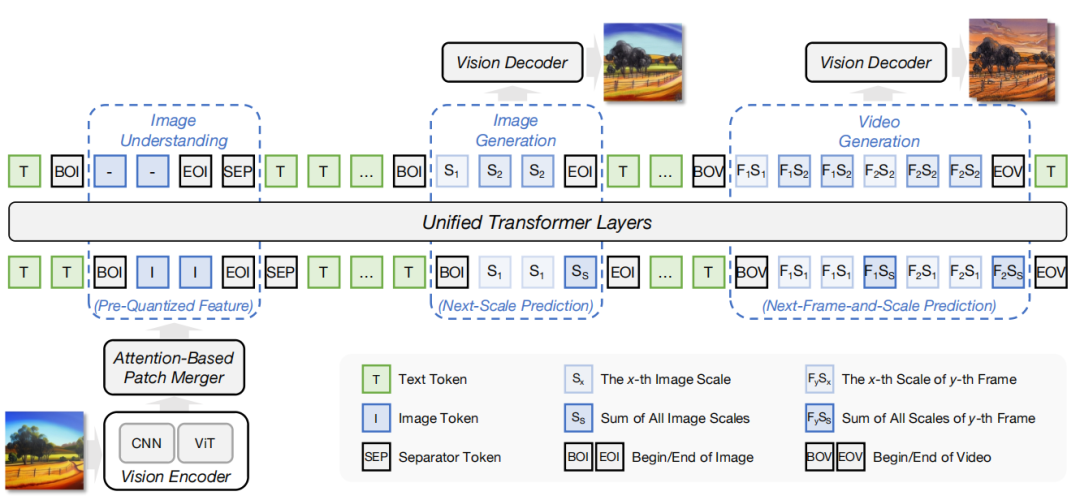
如图所示,在理解阶段,视觉信号首先由一个CNN-ViT混合表示模块来提取局部和全局特征,然后通过 Attention-Based Patch Merger 压缩为紧凑的token序列。这一步至关重要,它在保证信息完整性的同时,有效控制了token数量,使得大规模自回归建模成为可能。
在生成阶段,ERNIE 5.0提出了 Next-Frame-and-Scale Prediction:
- 对于单张图像,采用 Next-Scale Prediction,逐步细化生成图像的分辨率。
- 对于视频,则进一步引入 Next-Frame Prediction,在时间维度上进行自回归扩展。
这种设计的优势很明显:
- 保证了视频生成过程中的时间连贯性。
- 让图像/视频生成与文本生成共享同一套自回归逻辑。
- 使得模型能够在“理解—推理—生成”的流程中无缝切换。
本质上,ERNIE 5.0把“图像/视频生成”转化为了一个时间与尺度上的序列预测问题,而非传统的独立扩散过程。
四、音频理解与生成的层级自回归:Next-Codec Prediction
音频模态带来了另一大挑战:它既有时序结构,又涉及从波形、特征到语义、语言的多层次表征。
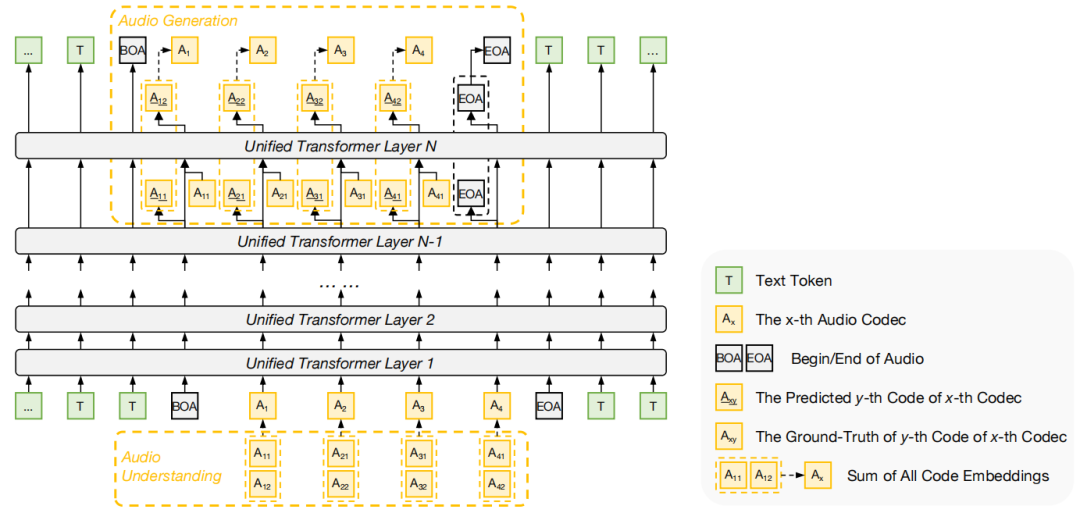
如图所示,在理解阶段,模型从多个残差层提取音频嵌入并进行加性融合,形成统一的音频token表示。在生成阶段,则引入了 Next-Codec Prediction,在Transformer层间进行层级预测,并将真实或预测的codec embedding反馈给后续层作为条件。
这一设计使得自动语音识别、语音理解、语音对话和语音合成等任务,都可以共享同一表示空间和同一主干模型。这避免了传统系统中“ASR一套、NLP一套、TTS再一套”的割裂局面,为实现真正的端到端语音智能奠定了基础。
五、超稀疏 MoE + 模态无关路由:可扩展的统一主干
统一多模态自回归建模面临一个现实问题:参数规模必须足够大以容纳多模态信息,但计算开销不能线性膨胀。为此,ERNIE 5.0采用了超稀疏混合专家架构。
在每一层,一个路由器会将不同模态的token分配到共享的专家池中。关键在于:这个路由过程完全是模态无关的,不会预先区分文本、视觉或音频专家。
这种设计带来了三大好处:
- 避免了人工划分专家所带来的工程复杂性。
- 允许不同模态自然地竞争或共享专家资源,形成更高效的计算模式。
- 在模型规模增长时,仍能保持可控的计算开销。
论文后续的专家利用分析表明,即便没有显式的模态标签,模型仍然会自发形成合理的专家分工,这可以看作是一种“自组织”行为。
六、弹性训练:从“训练一个模型”到“训练一族模型”
传统的模型训练范式通常是:先训练一个超大模型,然后通过蒸馏、剪枝、量化等手段,得到若干个小模型。
ERNIE 5.0提出了一个更激进的思路:在预训练阶段就同时优化不同规模的子网络,这就是 Elastic Training。
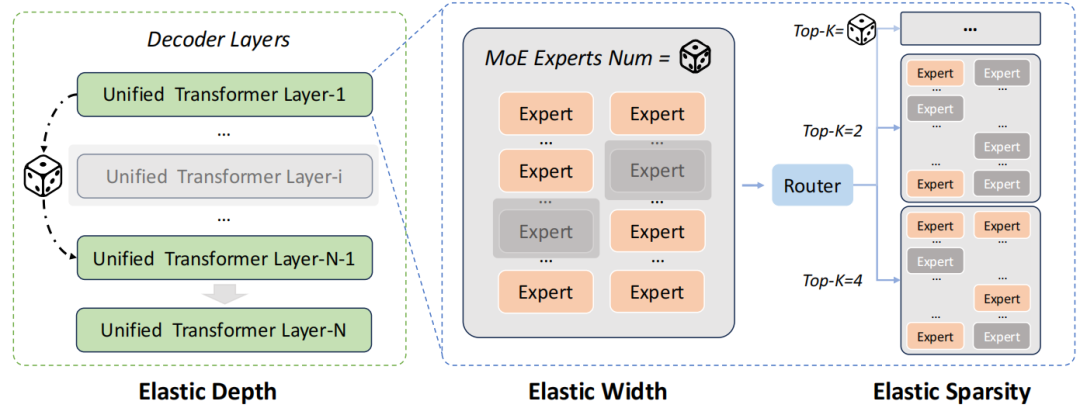
如图所示,弹性训练从三个正交维度引入了可变性:
- 弹性深度:训练时随机减少激活的Transformer层数。
- 弹性宽度:动态调整MoE中可用的专家总数。
- 弹性稀疏度:改变每个token所参与计算的top-k专家数量。
论文首先在受控的小模型上进行了系统性的消融实验:

表:弹性深度配置下的验证损失对比。弹性训练在缩减层数时性能平滑下降。

表:弹性宽度配置下的验证损失对比。弹性宽度在缩减专家数时仍能保持可用性能。
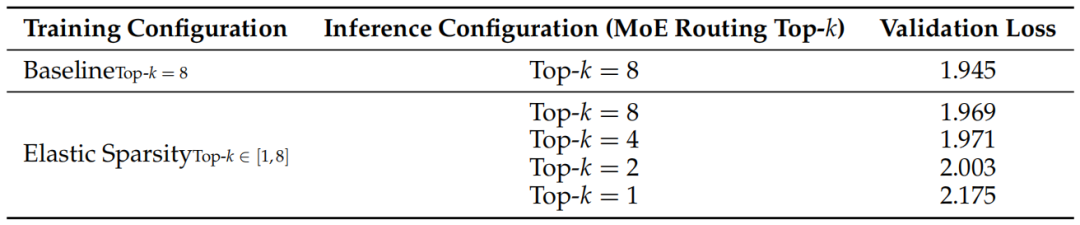
表:弹性稀疏度配置下的验证损失对比。模型能在不同路由预算下稳定工作。
在真实的ERNIE 5.0-Exp模型上进一步验证发现:
- 将路由top-k降至25%时,解码速度能提升15%以上,而性能基本保持不变。
- 在深度、宽度、稀疏度三个维度联合压缩后,仅使用35.8%的总参数,仍能达到接近完整模型的平均成绩。
这说明,弹性训练不是简单的“事后压缩”,而是一种面向效率的、前瞻性的预训练范式。
七、RL 训练的系统性挑战与解决方案
为万亿参数的多模态模型进行强化学习训练,面临三大难题:训练与推理的数值不一致、长尾样本导致的数据偏差,以及异构硬件利用率低下。
ERNIE 5.0为此设计了 无偏回放缓冲区。在传统的同步RL中,一个生成长度很大的样本会阻塞整个批次;而一些提升吞吐的方案(如APRIL)又会破坏数据的原始分布。U-RB方案则在等待长尾样本时,提前准备后续的批次,同时严格保持查询的原始顺序,从而兼顾了训练效率与数据的无偏性。
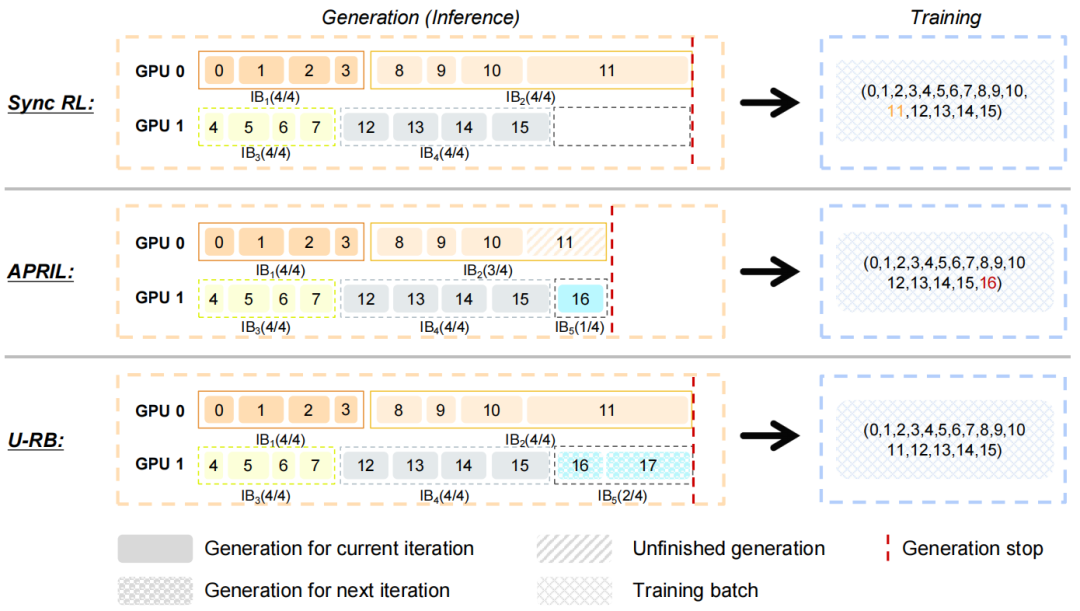
图:U-RB在等待长样本时提前准备后续数据,兼顾效率与无偏性。
同时,通过多粒度重要性采样裁剪,避免了训练早期出现的“熵坍塌”现象,确保了RL训练的稳定性。
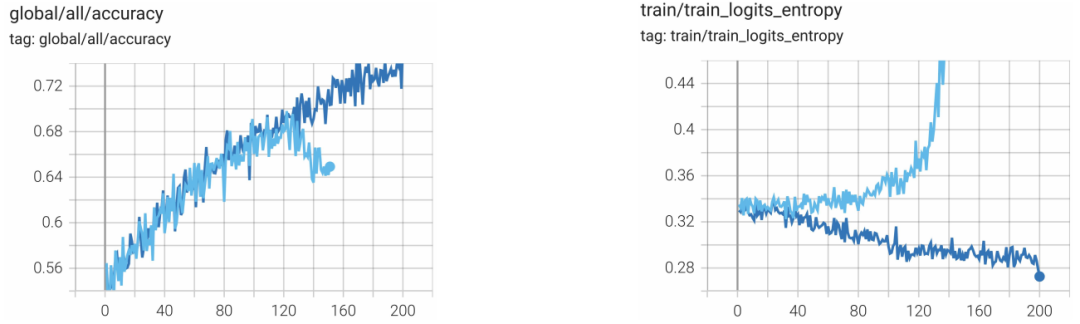
图:应用MISC后,训练准确率稳定上升,熵值波动得到控制。
此外,模型还引入了 think skeletons 作为自适应提示,帮助模型在稀疏奖励的场景下更快找到有效的推理路径,从而大幅提升样本效率。

图:通过增强提示引导模型进行分步思考,提升推理和答案质量。
八、系统基础设施:让万亿参数 MoE 可训练
超大规模MoE训练面临严峻的内存压力和通信开销挑战。为了支撑ERNIE 5.0的训练,系统层面采用了多维并行策略:
- 4路张量并行
- 12路流水线并行(虚拟阶段)
- 64路专家并行
- 结合ZeRO-1和上下文并行
并引入了多项优化技术:
- FP8混合精度训练
- 动态激活卸载
- 子批次内存分配
- CUDA VMM自动碎片整理
- DeepEP通信加速
这些软硬件层面的深度优化共同作用,才保证了万亿参数MoE模型的可训练性。
九、Tokenzier–主干解耦与FlashMask优化
不同模态的tokenizer计算特性差异巨大。ERNIE 5.0采用了Tokenizer与主干解耦的分布式架构,各模态tokenizer部署在独立节点,主干通过远程调用获取token表示,从而允许各自采用最优的并行策略,提升了整体系统效率。
针对多模态任务中注意力模式异构(文本需因果掩码,视觉需局部双向掩码)的问题,ERNIE 5.0采用了 FlashMask 方案。与传统FlexAttention相比,FlashMask在算子层面最高能带来200%的加速,整体训练加速超过20%,并且深度适配了上下文并行。
十、专家路由的自组织行为分析
尽管路由器不区分模态,但研究发现,模型中的专家仍然展现出了清晰的分工模式。
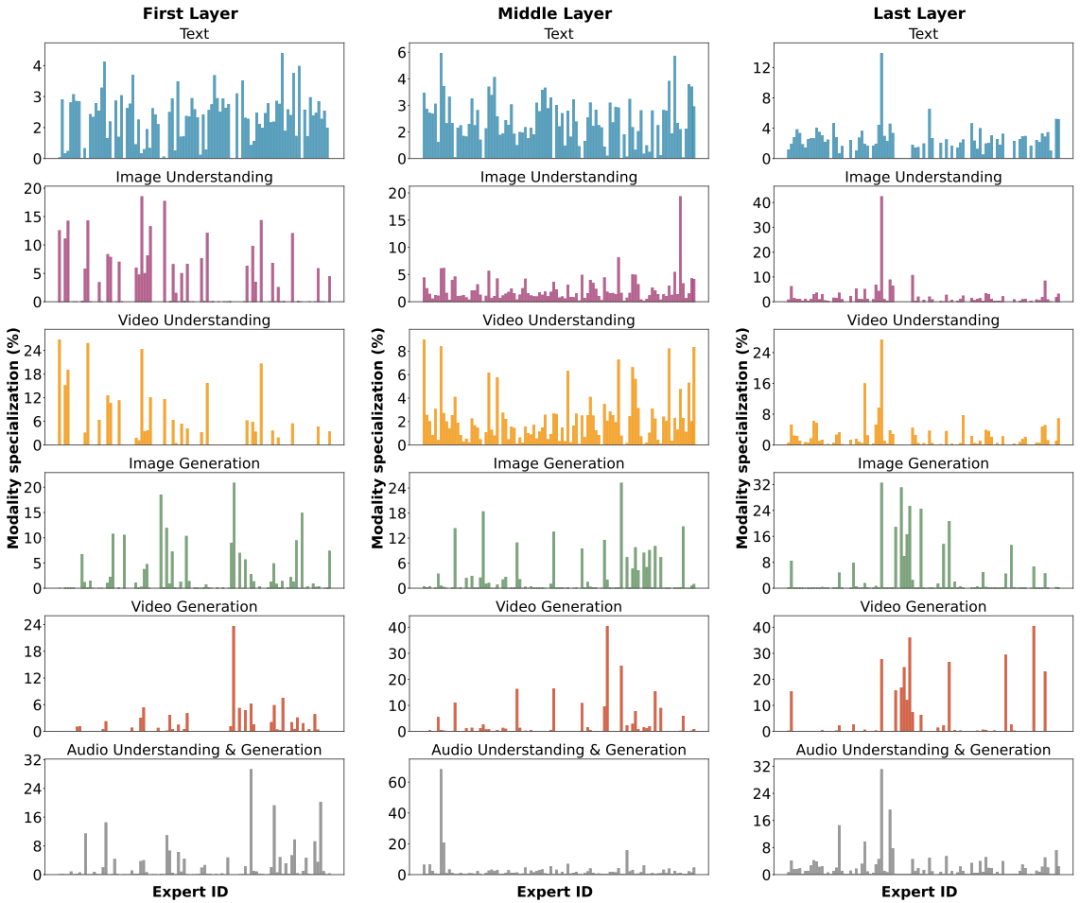
图:第一层、中间层和最后一层中,专家在不同模态任务上的专业化百分比。部分专家被所有模态共享,部分则明显偏向特定模态。
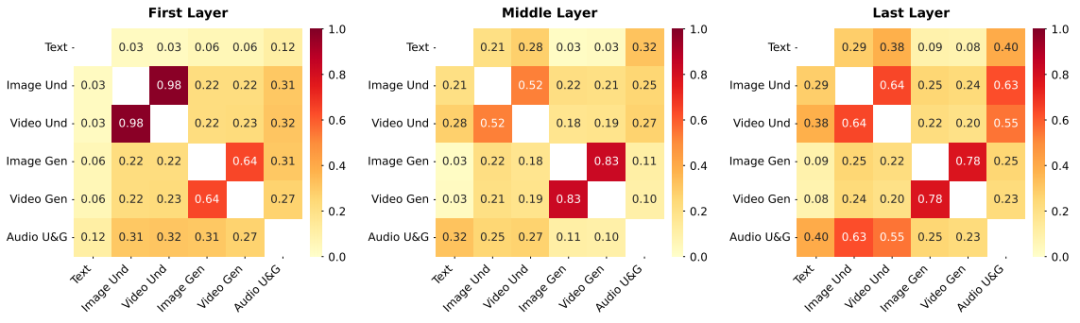
图:各模态任务在浅层相关性较低,在深层相关性增强,体现了从“感知”到“语义”的层级统一过程。
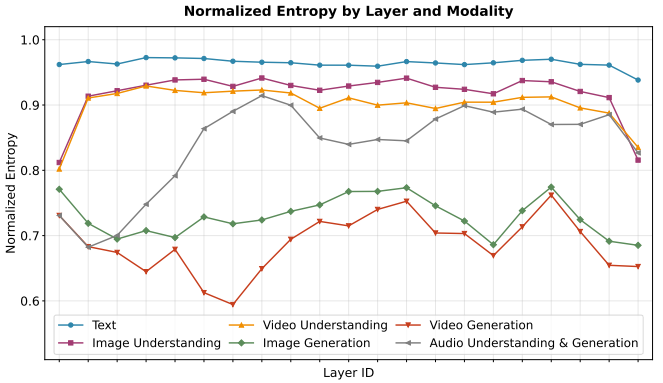
图:文本负载均衡,视觉/音频呈现“先分化、再整合”的层级演化,说明不同任务在不同深度需要不同专业化程度的专家。
分析表明,浅层专家更多表现出模态特异性,而深层专家中文本与视觉/音频的重叠度逐渐增加,这体现了信息处理从“感知”向“语义”的层级统一过程。
十一、文本能力评测:稳健而均衡
在预训练阶段,ERNIE 5.0-Base就展现出了全面而均衡的基础语言能力。
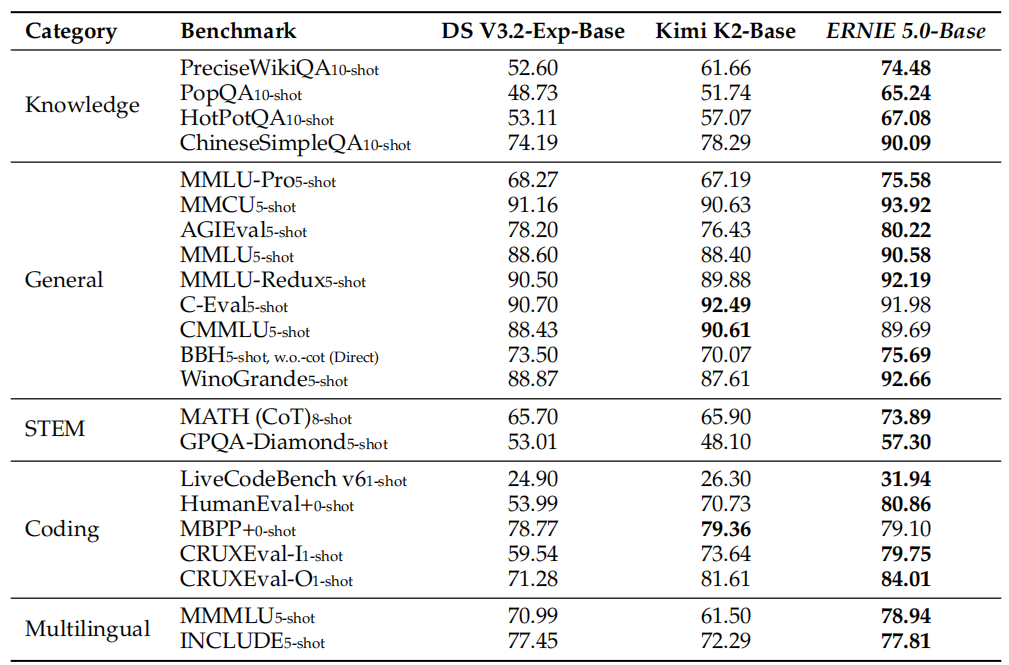
表:ERNIE 5.0-Base在多项基准测试上表现稳健,尤其在知识型和推理型任务上优势明显。
在后训练阶段,ERNIE 5.0在保持强大基础能力的同时,指令遵循与智能体能力得到了显著增强。
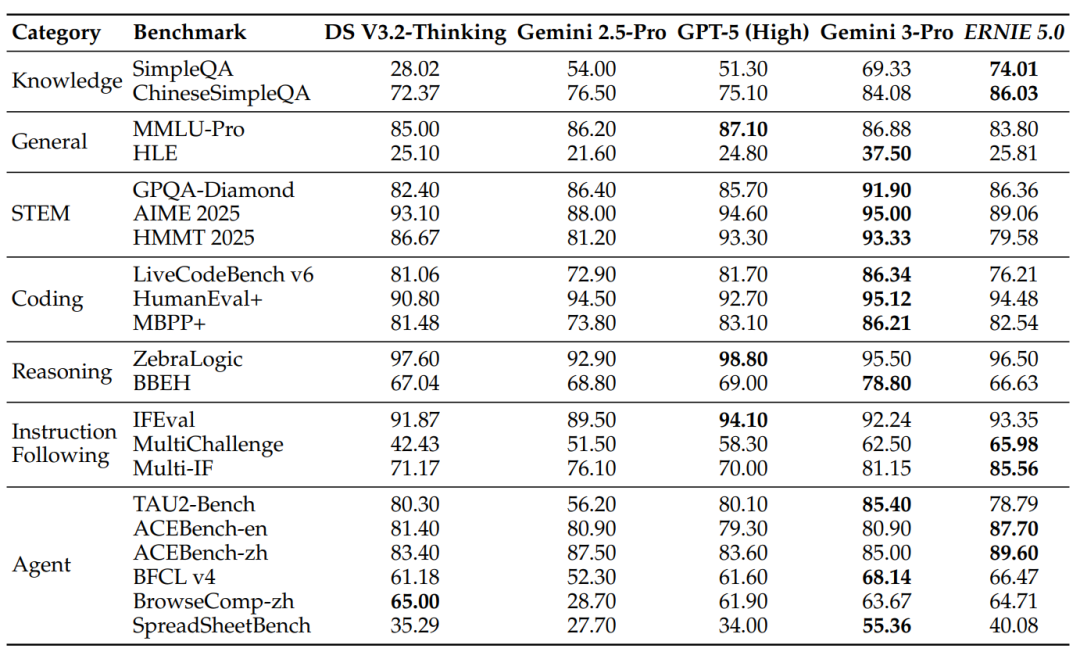
表:ERNIE 5.0在后训练后,在多挑战指令遵循和智能体任务中表现突出。
综合来看,ERNIE 5.0的文本能力路线体现了“稳健优先、均衡发展”的特点,预训练建立了扎实的知识与推理基础,后训练则显著提升了实用性与可控性。
十二、视觉能力评测:理解与生成并重
在视觉理解方面,无论是经过指令微调的版本还是基础版,ERNIE 5.0都表现出了强大的竞争力。
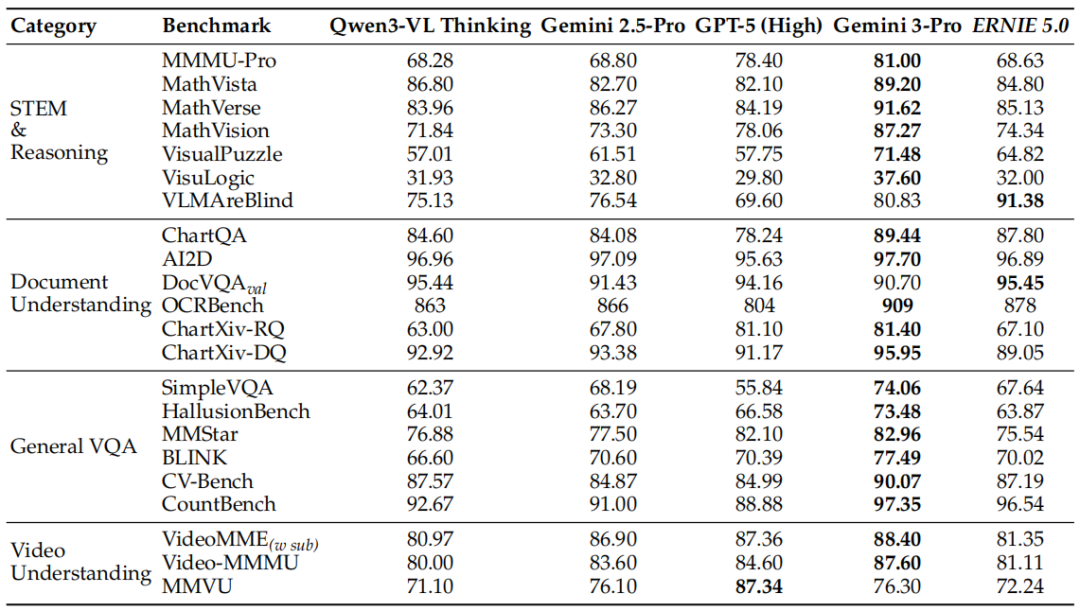
表:指令微调后,ERNIE 5.0在STEM与视觉推理、文档理解等任务上持续领先或保持高度竞争力。

表:未经指令微调的基础版已具备强大的原生多模态能力,说明其视觉能力根植于统一预训练。
在生成能力上,ERNIE 5.0同样表现不俗。

表:ERNIE 5.0在图像生成质量上与顶级商业模型处于同一梯队,验证了统一自回归范式在生成任务上的可行性。

表:ERNIE 5.0在视频生成的语义一致性上表现领先,兼顾了细节质量与时间连贯性。
十三、音频能力评测:统一框架的普适性验证
在语音识别、理解与生成方面,ERNIE 5.0在统一框架下取得了良好的平衡。
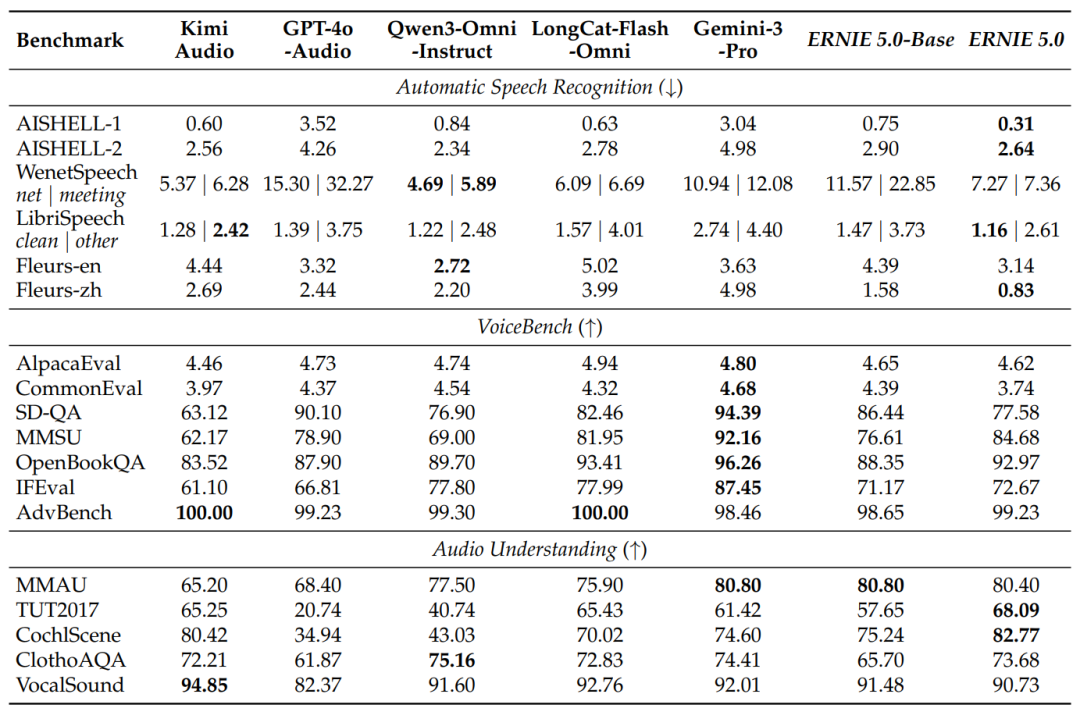
表:ERNIE 5.0在中文和英文ASR上达到低错误率,在语音-语言联合推理及通用音频理解任务上表现出色。
评测结果表明,ERNIE 5.0无需为语音识别、语音合成等任务进行专门训练,即可在统一的Next-Codec Prediction框架下实现可用乃至优秀的性能,进一步验证了其统一建模思想的普适性。
十四、总结:走向下一代基础模型
ERNIE 5.0的实践证明了:统一自回归建模 + 弹性预训练 + 超稀疏MoE,有潜力成为下一代基础模型的主流范式。
它不仅在各模态能力上达到了顶级水平,更重要的是在架构、训练和系统层面提供了一套可扩展的蓝图:
- 一个主干承载多模态:用统一的Transformer处理所有模态的理解与生成。
- 一次训练得到多规模模型:通过弹性训练,在预训练阶段即孕育出不同尺度的子网络。
- 一套基础设施支撑万亿参数RL:解决了超大规模模型训练中的内存、通信和效率难题。
这为AIGC的未来发展指明了方向。未来的演进可能包括更智能的层级专家分配、更高效的跨模态表示压缩、更强的长序列建模能力,以及更深度的工具使用与世界模型构建。
对于关注大模型前沿技术的开发者而言,理解ERNIE 5.0这类统一架构的设计哲学与技术细节至关重要。我们可以在像云栈社区这样的技术论坛中,持续追踪和探讨这些基础模型的演进,它们正在重新定义人工智能的边界。
 发表于 2026-2-11 15:33:39
|
查看: 170|
回复: 0
发表于 2026-2-11 15:33:39
|
查看: 170|
回复: 0
