我们在此讨论监督微调(SFT)、离策略(Off-Policy)知识蒸馏、强化学习(RL)、在策略(On-Policy)知识蒸馏之间的联系和区别。
在强化学习(Reinforcement Learning)火起来之前,我们提到知识蒸馏(Distillation)几乎都是指离策略知识蒸馏。SFT 和离策略知识蒸馏都是离策略的,并且离策略知识蒸馏训出的模型通常比 SFT 要好。
RL 流行之后,我们提到的知识蒸馏逐渐变成了在策略知识蒸馏。RL 和在策略知识蒸馏都是在策略的,并且在某些场景下,知识蒸馏比 RL 更具优势。
从离策略知识蒸馏到在策略知识蒸馏比较好理解,核心区别是学生(student)策略和教师(teacher)策略在不同的数据分布下进行对齐。那么,从 SFT 到 RL 又该怎么理解呢?一种观点是,RL 本质上就是在策略的 SFT,这一点可以从策略梯度的公式推导中得到论证。
目标函数回顾
1.1 监督微调(离策略 SFT)
SFT 的目标函数旨在最大化在离策略数据集上的负对数似然:
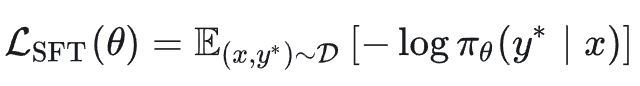
展开为逐词元(token)的形式:
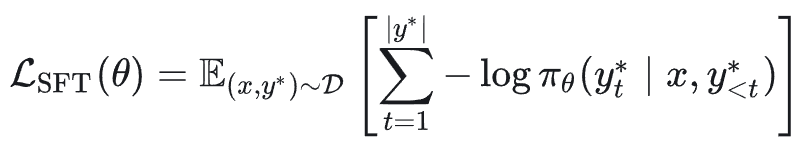
1.2 离策略知识蒸馏(Off-Policy Distillation)
离策略知识蒸馏旨在最小化学生策略 π_θ 与教师策略 π_teacher 在固定数据集 D 上的 KL 散度:
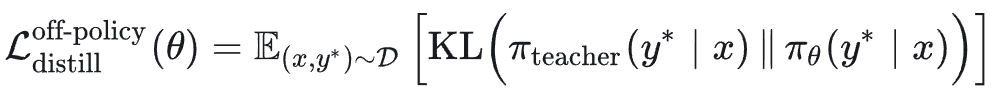
展开为:
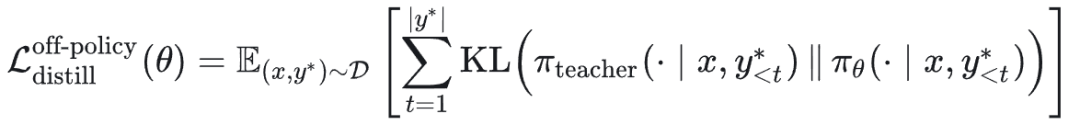
KL 散度有多种形式,最常见的是前向 KL 散度(Forward KLD)。在前向 KL 散度下,该目标等价于交叉熵损失:
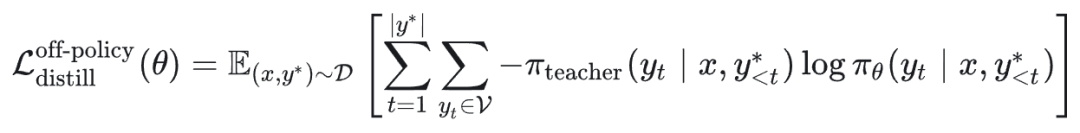
1.3 强化学习(本质是在策略 SFT)
强化学习的目标是最大化在某个环境下的期望奖励:
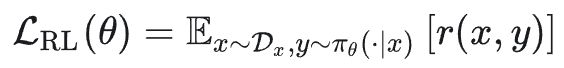
特别地,像 GRPO(Group Relative Policy Optimization)这类方法,其奖励估计采用序列级别的组内优势函数:
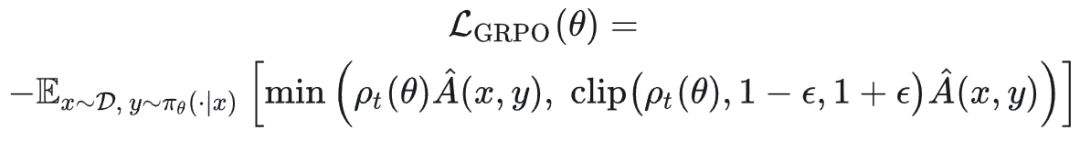
其中重要性采样比率 ρ_t(θ) 定义为:
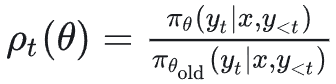
1.4 在策略知识蒸馏(On-Policy Distillation)
在策略知识蒸馏旨在最小化学生策略 π_θ 与教师策略 π_teacher 在学生策略自身生成的轨迹分布上的 KL 散度:
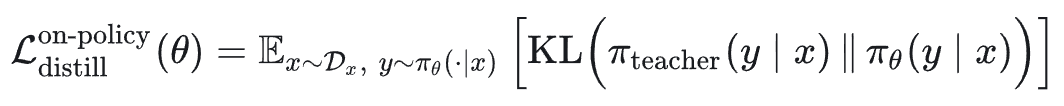
展开为:
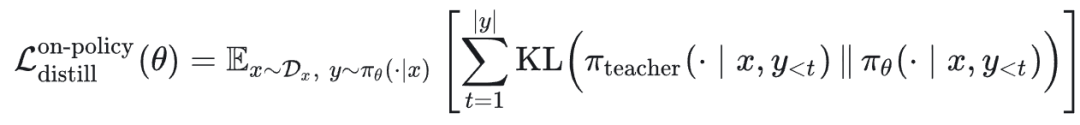
同样采用前向 KL 散度,但由于采样分布依赖于策略参数 θ,不能直接简化为标准的交叉熵形式,其完整表达式包含一项策略梯度:
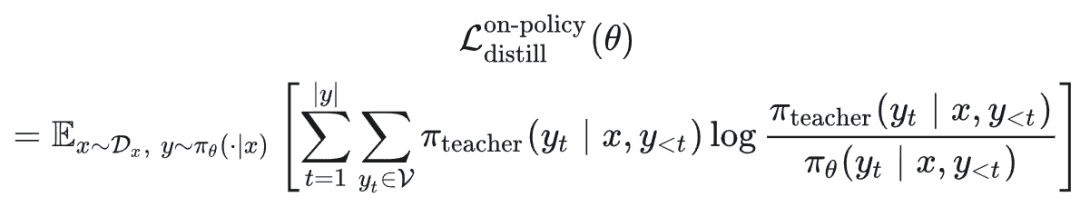
不过在实践和部分理论分析中,通常不考虑由采样分布变化引起的那一项策略梯度(即对采样过程做梯度截断处理),于是目标简化为:
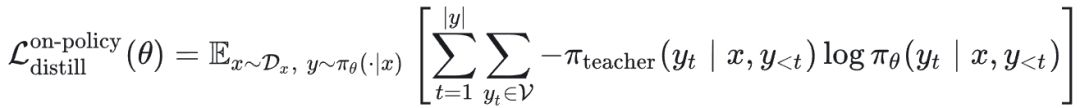
梯度对比
直观上看,上述四个目标函数联系不大。但如果我们从梯度的角度来分析,就能发现它们之间深刻的内在联系。
2.1 监督微调(SFT)
目标函数:
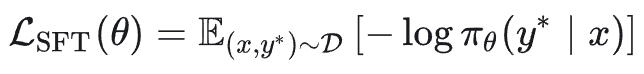
梯度推导:
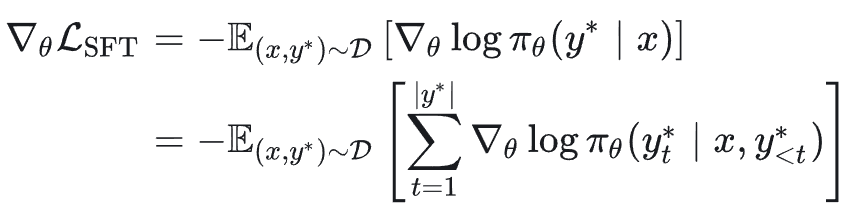
2.2 离策略知识蒸馏
目标函数:
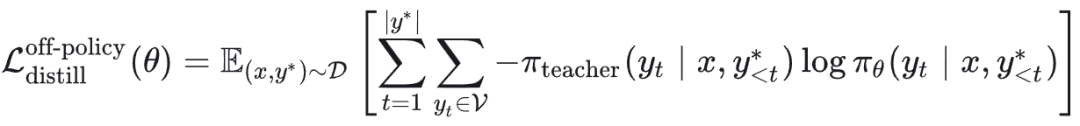
梯度推导:
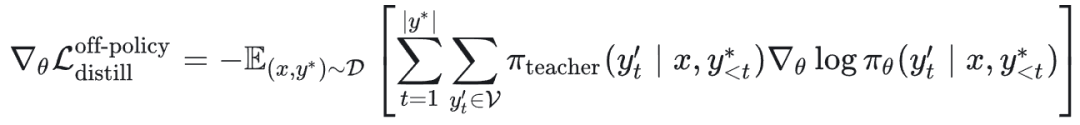
2.3 强化学习
目标函数:
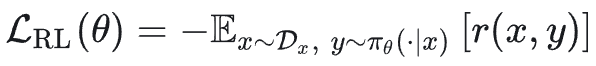
梯度推导(基于策略梯度定理,采样分布依赖于参数 θ):
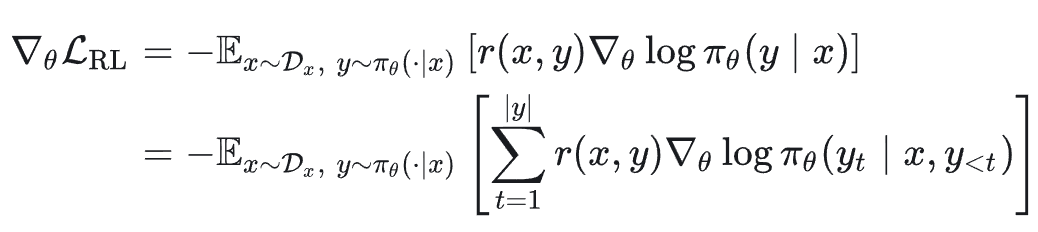
GRPO 的梯度形式:
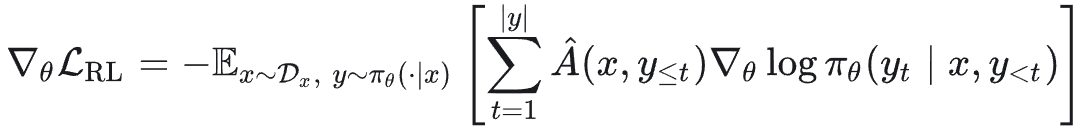
其中:
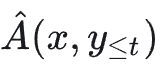
是 t 时刻的(组内)优势估计。
2.4 在策略知识蒸馏
目标函数:
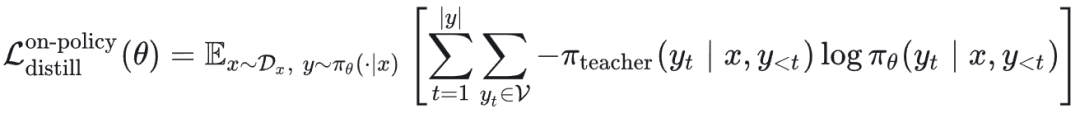
梯度推导(同样考虑采样分布中的 θ):
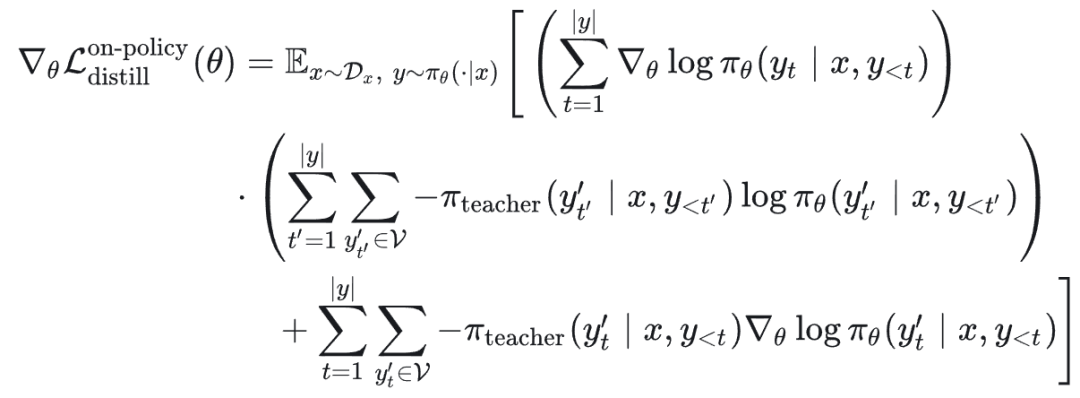
记 KL 散度项(简化为交叉熵形式)为:
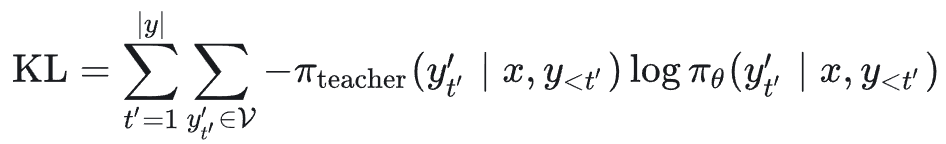
则梯度可以化简为两项之和:
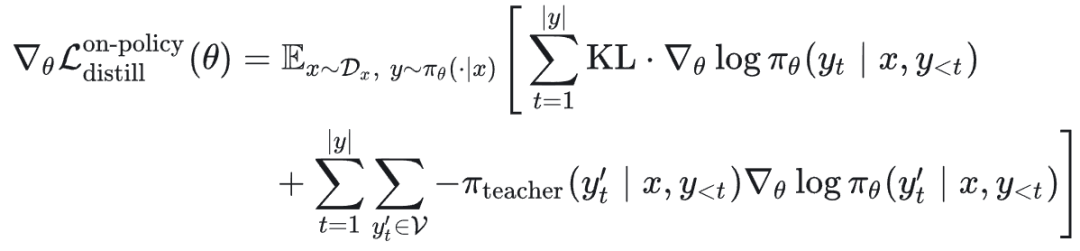
通常情况下,第一项(由采样分布变化引起的梯度)不参与优化(在蒸馏中被认为是梯度截断的),因此有效的梯度为:
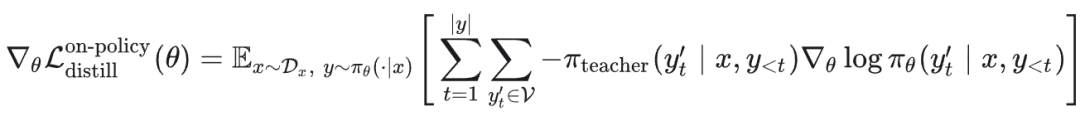
2.5 初步结论
SFT 与离策略知识蒸馏:
两者的梯度都作用于项:
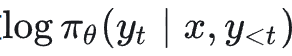
不同之处在于加权方式。SFT 直接使用“正确答案”的 one-hot 分布进行加权(即只有 ground truth y*_t 的梯度权重为 1,其余为 0)。而离策略知识蒸馏则使用教师模型输出的完整概率分布进行加权,对所有可能的词元 y'_t 都根据教师模型给出的概率 π_teacher(y'_t | ...) 分配权重。
RL 与在策略知识蒸馏:
RL 使用奖励信号 r(x, y) 或优势估计 Â(x, y≤t) 对基础项进行加权,且这种加权是“稀疏的”——只对模型实际采样到的轨迹 y 或词元 y_t 赋予非零权重。
而在策略知识蒸馏的加权则“稠密”得多,它使用教师模型的分布对所有可能的词元(而不仅仅是采样到的词元)的梯度进行加权。这使得知识蒸馏的信号覆盖更全面。
注: 本文主要讨论前向 KL 散度,因此使用教师模型的分布进行加权。如果是反向 KL 散度(Reverse KL),则会使用学生模型的分布进行加权,并且梯度表达式中还会包含额外的一项。
将梯度统一到在策略框架下
为了使比较更加公平,我们需要将 SFT 和离策略知识蒸馏的梯度也转换到“在策略”的视角下,即期望的采样分布改为当前策略 π_θ。这可以通过重要性采样技术实现:
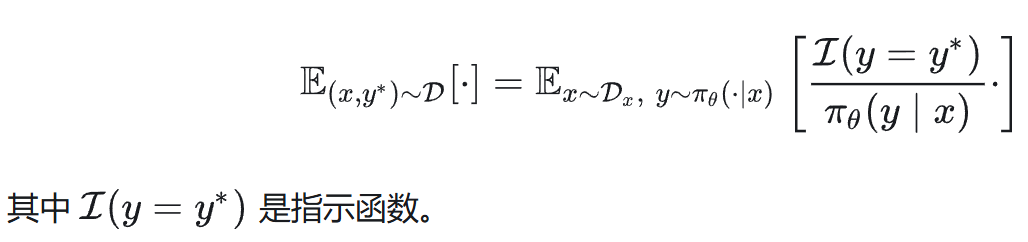
其中 I(y = y*) 是指示函数。
SFT 梯度可重写为:
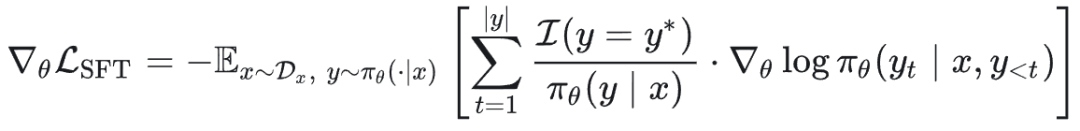
离策略知识蒸馏梯度可重写为:
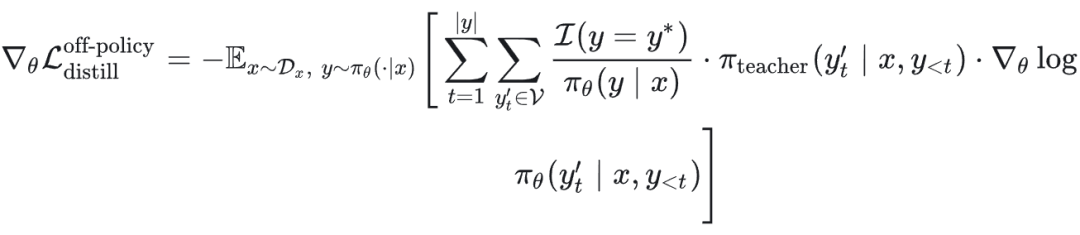
强化学习的梯度为:
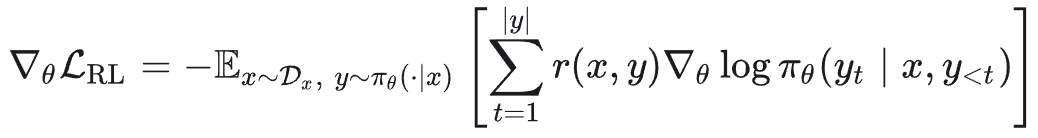
在策略知识蒸馏的梯度为:
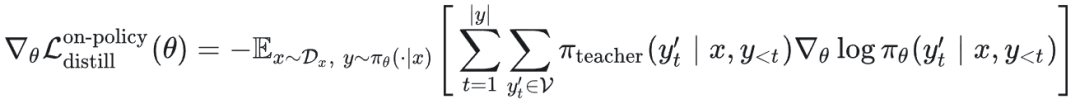
现在,我们可以清晰地看到四个目标函数梯度形式的统一结构:

所以,上面四个目标函数的不同之处,完全在于 ∇θ log π_θ(y'_t | x, y_{<t}) 前面的加权系数不同。SFT 和 RL 的加权是稀疏的(依赖于采样结果 y 是否等于 ground truth y* 或奖励 r),而知识蒸馏(无论是离策略还是在策略)的加权是稠密的(依赖于教师模型的分布 π_teacher)。特别地,*SFT 可以视为奖励模型为指示函数 `I(y = y)` 的一种稀疏强化学习** [4]。
补充:反向KL散度下的蒸馏梯度
作为知识补充,如果在知识蒸馏中使用反向 KL 散度(Reverse KL),其梯度形式会有所不同。
离策略知识蒸馏(反向KL)梯度可重写为:
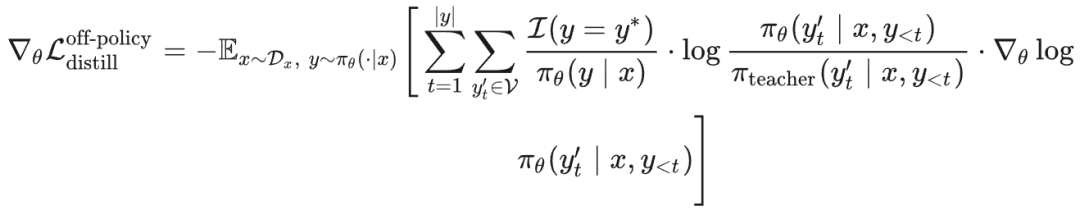
在策略知识蒸馏(反向KL)的梯度为:

可以看到,在反向 KL 下,梯度权重中包含了学生策略与教师策略的对数概率比值 log(π_θ / π_teacher),这与前向 KL 有显著区别。
参考文献
[1] Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models (On-policy和SFT)
[2] Self-Distillation Enables Continual Learning (On-policy和SFT)
[3] Reinforcement Learning via Self-Distillation (On-policy和RL)
[4] On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification (SFT和RL)
本文基于对 强化学习 与 监督微调 理论的理解,从策略梯度角度进行了公式推导与对比分析,揭示了它们之间深刻的联系。希望这些讨论能帮助大家更深入地理解 深度学习 模型对齐的底层逻辑。欢迎在 云栈社区 继续探讨相关技术话题。
作者:一木不,已获作者授权发布
来源:https://zhuanlan.zhihu.com/p/2004262797710738371
 发表于 2026-2-11 17:59:26
|
查看: 258|
回复: 0
发表于 2026-2-11 17:59:26
|
查看: 258|
回复: 0
