大模型在进行复杂的多跳推理时,一个不容忽视的问题是 token 消耗巨大。传统方法每增加一个推理步骤,往往意味着一次全新的检索、一轮新的 LLM 调用以及又一段可观的上下文消耗。很多时候,模型更像是在“烧钱”而非纯粹推理。
近期,由南京大学、同济大学、中南大学等机构联合发表的一篇论文提出了一种名为 CompactRAG 的新框架。它通过巧妙的架构设计,将多跳问答中的 LLM 调用次数成功压缩至仅 两次,同时显著降低了 token 开销,而最终的效果却能与传统方法持平甚至更优。

CompactRAG: Reducing LLM Calls and Token Overhead in Multi-Hop Question Answering
https://github.com/How-YoungX/CompactRAG.
https://arxiv.org/pdf/2602.05728
01 多跳问答的挑战:一次推理,多次调用
多跳问答(Multi-hop QA)是自然语言处理中的一个经典难题:回答一个问题需要串联起多个文档中的信息。例如:
《十二猴子》电影和它改编的剧集是不是同一家公司制作的?
要回答这个问题,你需要先找到电影的制作公司,再查找剧集的制作方,最后进行比较。
传统的 RAG(检索增强生成)系统通常采用“迭代式”方法:检索部分文档 -> LLM 推理 -> 根据推理结果再次检索 -> 再次推理…… 每进行“一跳”,就需要调用一次 LLM,导致 token 消耗和推理时间呈线性甚至指数级增长。
此外,实体漂移(entity drift) 问题也颇为棘手。例如,将问题分解为“谁发现了青霉素?”和“他出生在哪里?”,第二个问题中的代词“他”在检索时很容易丢失明确的指代,从而引发检索偏差,影响最终答案的准确性。
02 CompactRAG 的核心思路:分离“离线”与“在线”阶段
CompactRAG 提出了一种创新的解决方案:将语料预处理成原子化的 QA 对知识库,把推理过程中的检索和重写任务交给轻量级模块,而 LLM 只专注于最核心的问题分解与答案合成任务。
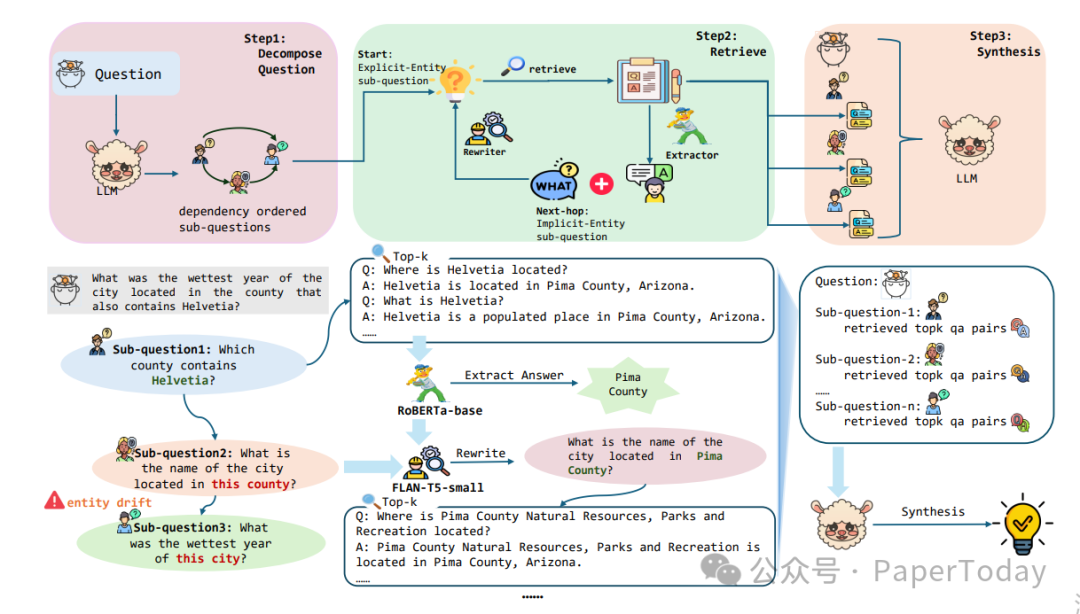
离线阶段:构建原子化知识库
利用 LLM 对整个语料库进行一次性处理,将其转化为一组原子 QA 对。每个 QA 对都是一个最小粒度的知识单元。例如:
Q:《十二猴子》电影是由哪家公司制作的?
A:环球影业。
通过这种方式,原始的非结构化语料被压缩、去冗余,转变为一个结构化的“知识卡片”库,为高效的在线检索奠定了基础。
在线阶段:两次 LLM 调用完成推理
- 问题分解:LLM 将复杂的原始问题分解为一系列有序的子问题(第一次调用)。
- 检索与轻量推理:
- 使用稠密检索模型从构建好的 QA 库中检索与每个子问题相关的候选对。
- 使用轻量级的 Answer Extractor(基于 RoBERTa)从候选 QA 对中精准抽取答案。
- 使用 Sub-Question Rewriter(基于 T5)将子问题中的模糊指代(如“他”、“该城市”)重写为具体的实体名称,解决实体漂移问题。
- 最终合成:将所有抽取出的子问题答案与原始问题一并提交给 LLM,由其综合生成最终答案(第二次调用)。
关键在于,无论原始问题需要多少“跳”推理,LLM 在整个过程中都只被调用两次。
03 实验结果:显著节省 Token,性能保持优异
研究团队在 HotpotQA、2WikiMultiHopQA 和 MuSiQue 这三个主流的多跳问答基准数据集上进行了测试。
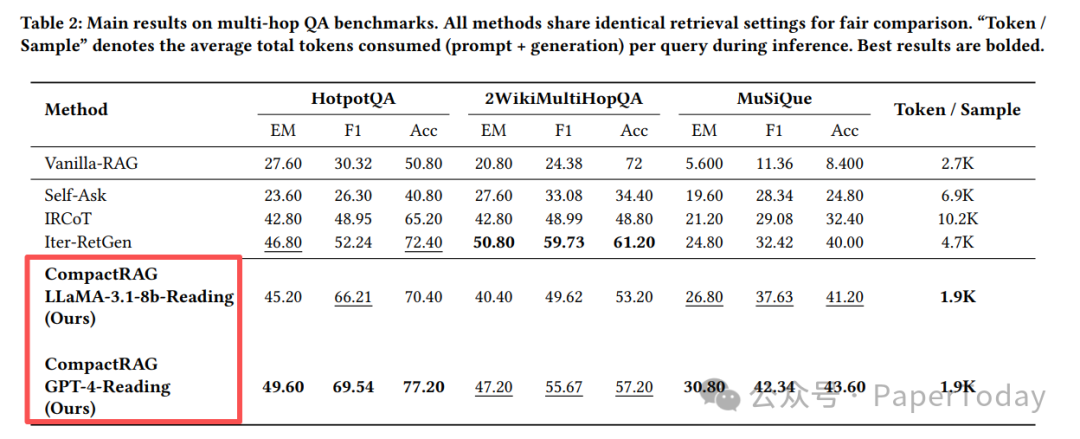
- 准确率:CompactRAG 与传统的迭代式 RAG 方法(如 Self-Ask、IRCoT)表现相当,甚至在某些指标上更优。
- Token 消耗:CompactRAG 平均每个查询仅消耗约 1.9K token,而对比方法普遍在 4K 到 10K 之间,成本优势明显。
- 扩展性:当问题复杂度增加时,CompactRAG 的 token 消耗几乎不会增长,展现了良好的可扩展性。
这意味着,CompactRAG 能够以更低的计算成本,实现同等甚至更优的复杂推理能力。
04 为什么这项研究值得关注?
在大模型的应用落地方案中,推理成本主要集中在 token 消耗和 LLM 调用次数上。尤其是在需要处理海量查询的工业级场景中,每节省一个 token、减少一次 API 调用,都意味着真金白银的成本下降。
CompactRAG 提供了一种极具启发性的架构设计思路:不必让 LLM 包揽所有任务,而是将可以离线预处理、能用轻量级模型替代的环节剥离出来。让 LLM 聚焦于其最擅长的高层次“理解”与“创造合成”工作,而让更高效、更经济的专用模块处理模式化的检索、重写和抽取任务。这种对 开源实战 项目中模块化思想的运用,为优化系统效率提供了新方向。
05 总结与展望
这篇论文的核心启示在于:大模型系统的性能优化,未必总是追求更大的模型规模或更多的参数调整。通过精巧的架构设计,对推理流程进行合理的拆解、模块化和轻量化,同样能够在效率与效果之间找到出色的平衡点。
展望未来,如果能将这种“离线知识库 + 轻量推理模块 + 极简 LLM 调用”的范式推广到更多任务场景(如复杂对话、智能推荐、深度文档理解等),或许能为大模型低成本、高可用的规模化落地开辟一条新的路径。对于希望深入理解此类系统设计精髓的开发者,查阅相关的 技术文档 和源码将是必不可少的学习步骤。
 发表于 2026-2-12 14:21:13
|
查看: 255|
回复: 0
发表于 2026-2-12 14:21:13
|
查看: 255|
回复: 0
