
🪄 你的 Dashboard 好看又精准吗?或许,是时候让 AI 来严肃地打一次分了。
引言:当 AI 开始 “看图思考”
在这个“数据驱动决策”的时代,图表早已不是“锦上添花”的装饰——它是传递复杂信息的“核心语言”:
- 生活里,我们通过新闻图表了解经济走势、疫情数据;
- 学术中,研究者用折线图、柱状图呈现实验成果;
- 企业里,管理层靠 Dashboard 快速掌握业务动态……
但现实中,“翻车”的图表比你想象得多:
- 工作汇报时,精心做的图表因坐标轴混乱,被老板质疑“数据是不是编的”;
- 刷财经新闻时,“某行业增速超 500%” 的标题下,图表纵轴从 90% 开始,实际增速仅 10%;
- 帮学生改作业,3D 饼图让扇区占比完全失真,却因“视觉好看”被当成优秀案例……
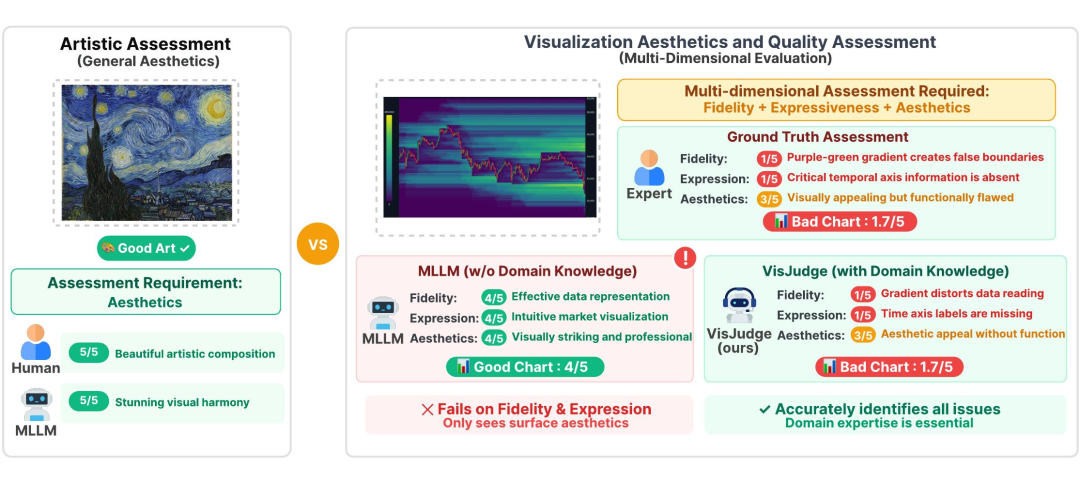
“好看”就是“好”吗?
看上图右侧:一张缺失了关键标签(X 轴/图例)的金融热力图,人类专家一眼判为废图(1.7分),而 GPT-5 却因其“长得专业”而给出了 4 分的高评。这种“懂艺术不懂数据”的尴尬,正是我们需要专业评估的原因。
谁来为图表的“质量”把关?目前还没有一把专门量图表好坏的“标尺”。企业和研究者大多依赖经验、审稿人或设计师的主观判断,可视化质量成了数据能不能被正确理解、负责任传播的关键瓶颈。
对任何追求“通用智能”的多模态大模型来说,理解和评估可视化的能力,不仅是“看得懂图”,更是要“看得准、看得深”:既要分辨数据有没有被歪曲,也要判断信息有没有说清楚、设计是否合理友好。
尽管当前多模态大模型(如 GPT-5、Claude、Qwen-VL 等)在图文问答、推理甚至代码生成上表现亮眼,但它们是否真正理解图表背后的数据关系、设计意图与视觉逻辑,至今还缺少一套系统、可量化的评估方式。
为此,来自香港科技大学(广州)、DeepWisdom(MetaGPT)与蒙特利尔大学提出了 VisJudge-Bench —— 一个衡量多模态大模型在可视化理解、审美与表达质量上的全新基准。

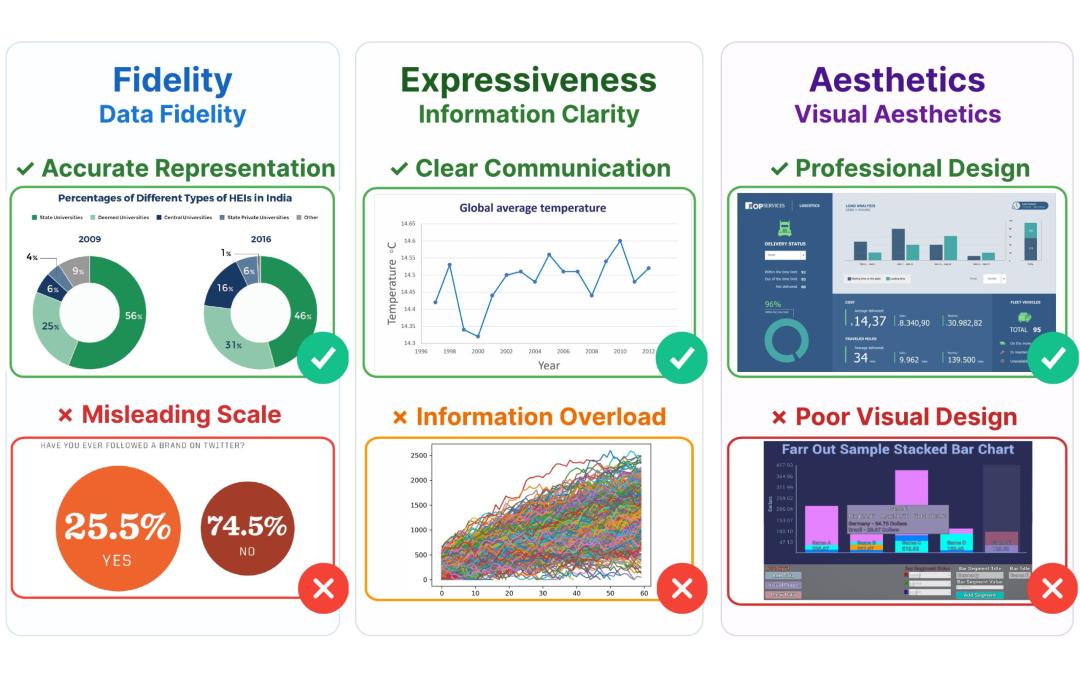
我们借鉴经典翻译理论中的“信、达、雅”准则,并融合图形感知与可视化设计理论,构建了全新的三维评估框架:
- 信(Fidelity):数据忠实度 —— 数据与图表是否匹配,不歪曲事实
- 达(Expressiveness):信息表达力 —— 信息传达是否有效,能否发现洞察
- 雅(Aesthetics):视觉美感 —— 设计与审美是否协调,符合认知直觉
破局:全球首个可视化质量评估基准 VisJudge-Bench
为了给 AI 模型提供统一的“评估标准”,我们打造了 VisJudge-Bench —— 一个覆盖多场景、多类型图表的高保真可视化质量评估基准。
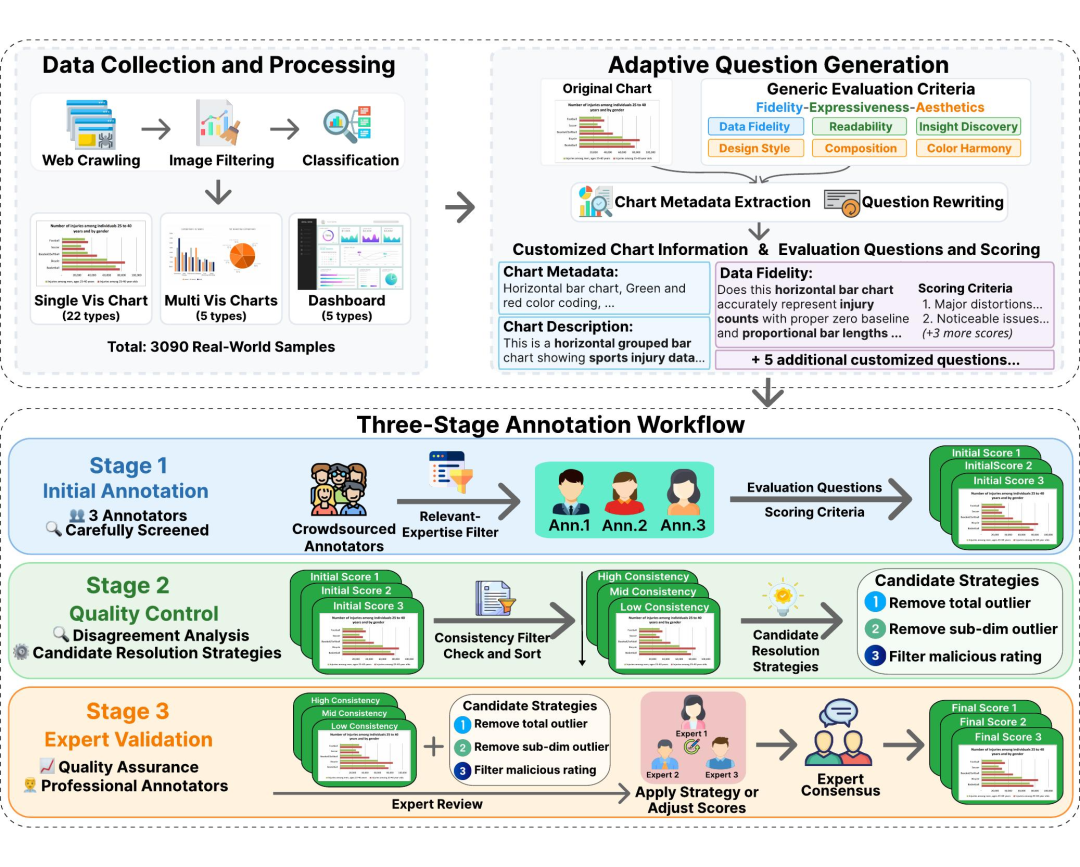
数据层面,VisJudge-Bench 共收录 3,090 张标注图表,覆盖 32 种图表类型,从最常见的柱状图、折线图,到桑基图、Treemap、热力图、日历图,再到多视图组合和仪表盘,既有单张图表,也有跨页对比图和企业级 BI Dashboard。场景来源涵盖学术论文、商业报表、新闻报道等真实应用。
为了保证评分可靠,我们采用“三阶段标注 + 专家终审”的流程:先通过严格筛选招募 603 名众包标注者,每个样本由 3 名标注员独立打分,再通过算法自动筛出分歧较大的样本,最后由 3 名可视化领域专家逐一仲裁,形成尽可能贴近“集体专业判断”的参考答案。
此外,VisJudge-Bench基准还针对不同图表类型设计了“自适应评估机制”:同样是 1–5 分的质量评分,背后关注的点并不相同。横向堆叠条形图更强调分类是否完整、百分比是否合理;时间序列图更看重时间轴的连续性和异常值标注;而 Dashboard 则要综合考量 KPI 是否突出、多图联动是否清晰。这让评估更贴近真实使用场景,而不是一刀切的抽象打分。
VisJudge 模型:比 GPT-5 更懂图表的 “AI 图表评审官”
基于 VisJudge-Bench 数据集和三维评估框架,我们对 Qwen2.5-VL-7B 模型进行了定向训练,得到专门面向图表质量评估的 VisJudge 模型。
在训练上,我们采用监督微调结合 GRPO 式强化学习的方式,让模型逐步对齐专家的评分逻辑。数据划分上保持常规的 7:1:2(训练 / 验证 / 测试),避免数据泄露。评估指标上对“数据忠实度”等关键维度加权,让模型更重视“不要冤枉好图,也不要放过坏图”。
在这个基准上,我们对当前主流多模态模型做了一次全面体检:包括 GPT-5、GPT-4o、Claude-4、Gemini-2.5-Pro、Qwen2.5-VL 系列等在内,共 12 个代表性模型参与测试。
各模型在 648 张测试集图表上与人类专家给出的“标准答案”进行对比,我们采用误差指标(平均绝对误差 MAE、均方误差 MSE)、与专家评分的一致性(Pearson 相关系数),并分析分数分布以识别系统性偏差。
整体来看,闭源商用模型仍然领跑,开源模型紧随其后,且模型越「大」,模型越「强」 的趋势在这个任务上依然成立。但即便是当前最强的 GPT-5,在图表质量判断上也远未达到“安心托付”的程度。
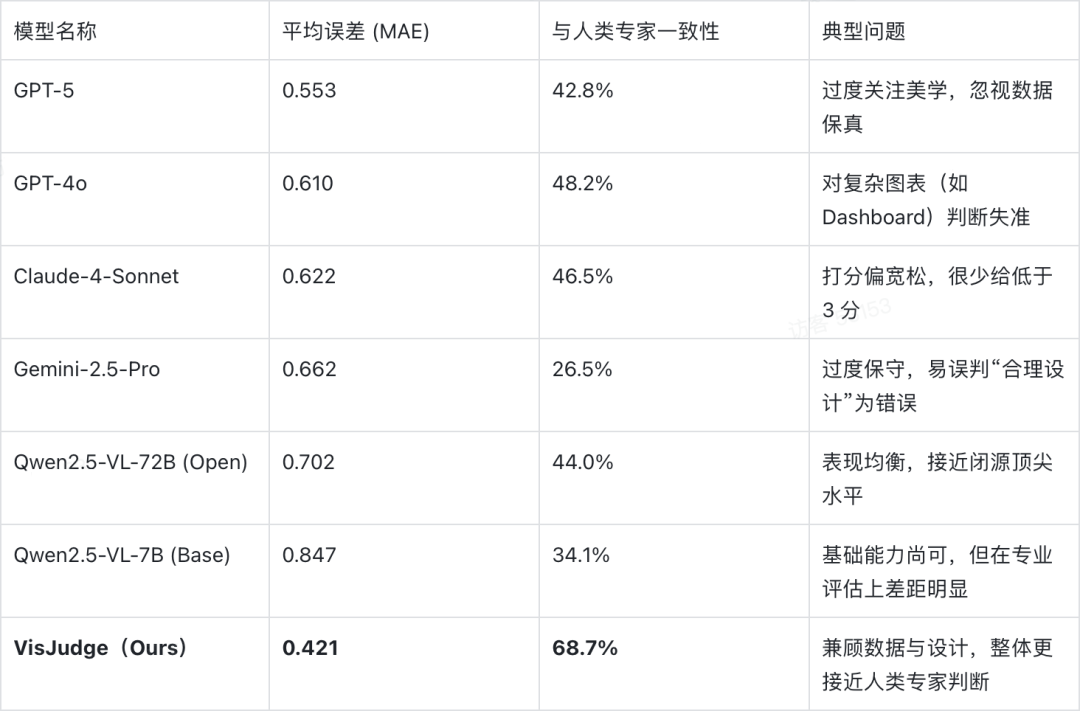
可以看到,多数通用大模型与专家的一致性不足 50%,几乎相当于“每两次判断就有一次不靠谱” ,很难直接拿来做生产环境里的“图表裁判”。而 VisJudge 在多个细分维度上都明显优于 GPT-5:不仅平均误差更低,在数据忠实度、视觉构图协调等与“是否靠谱”高度相关的维度上,提升尤为明显,更接近人类专家的整体判断。
真实案例:VisJudge 如何“火眼识真”?
单看数字有时候抽象,我们挑了两个典型案例,来看看“泛用大模型”和“专门训练过的评审官”之间的差别。
1. 拒绝“老好人”:一眼识破混乱布局
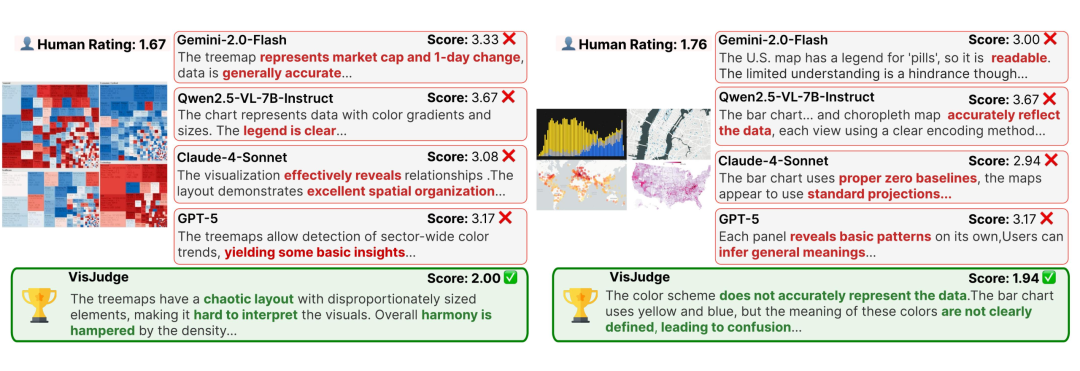
这是一张布局极度混乱的 Treemap(上图左),人类专家只给了 1.67 分。但 Qwen2.5-VL-7B 却给出了 3.67分 的高分,理由竟然是“图例清晰”,完全无视了内容的可读性硬伤。相比之下,VisJudge 给出 2.00 分,并准确指出了“布局混乱、难以解读”的核心问题。
2. 告别“过敏症”:读懂复杂仪表盘
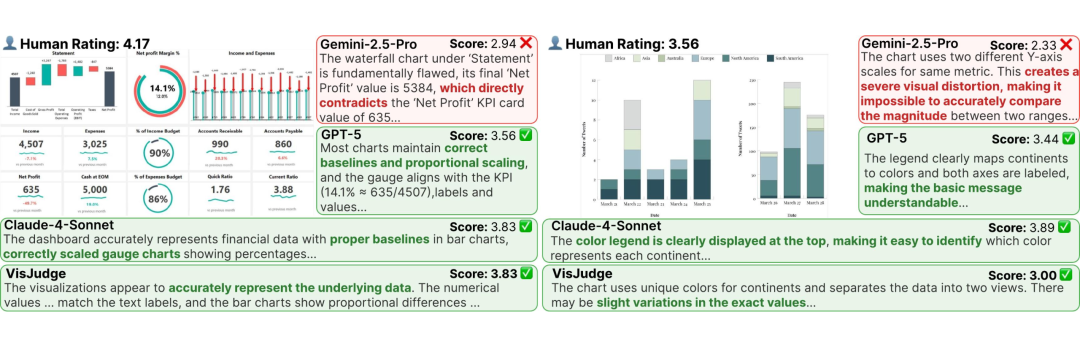
这是一个设计精良的财务 Dashboard(上图左下),人类专家给出了 4.17 分 的高评。然而 Gemini-2.5-Pro 却只给了不及格的 2.94 分 ,因为它“过度敏感”地认为数据存在矛盾(实际上是合理的 KPI 展示)。而 VisJudge 给出了 3.83 分 ,正确识别了其在基准线对齐、比例缩放上的专业设计。
这样的案例在我们的评测中并不少见:通用大模型更像是“看热闹”的观众,而 VisJudge 更接近“看门道”的评审官 。 论文将这类行为归纳为两种系统性偏差:
- 分数膨胀(score inflation):对低质量图表普遍给高分(如 Qwen、Claude-3.5 均值接近 3.9,而人类专家约 3.13),甚至夸赞“图例清晰”“空间组织优秀”,忽视布局混乱等硬伤。
- 过度保守(overly conservative):对高质量图表过分苛刻(如 Gemini-2.5-Pro 均值仅 3.02),揪住单点“数据不一致”或双 Y 轴等设计取舍,给出明显偏低的分数。
核心发现:AI 在图表评估上的短板与启示
把所有实验结果和案例放在一起看,会发现几个非常鲜明的趋势。
首先是普遍的“系统性偏差”。通过分析评分分布(如下图),我们发现通用大模型很难像人一样“客观中立”。
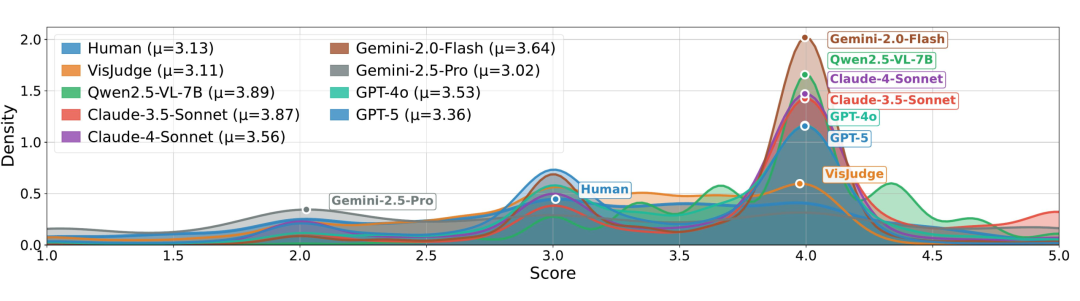
- “老好人”现象(分数膨胀):大多数模型给分明显偏高。人类专家的平均分是 3.13,而 Qwen2.5-VL-7B 和 Claude-3.5-Sonnet 的平均分接近 3.9,倾向于给大多数图表打高分,导致很难区分出真正的好图和坏图。
- “过度保守”现象:Gemini-2.5-Pro 则走向了反面,对设计稍有瑕疵的图表容易给予过严的惩罚。
- VisJudge 的对齐:经过专项训练的 VisJudge(红色曲线)平均分为 3.11,其分布形态几乎完美复刻了人类专家(灰色阴影)的评分模式。
其次是“偏科严重”。
在明显的数据错误上,大模型往往能给出正确判断,例如坐标轴被截断、百分比相加不为 100% 等“硬伤”;但一旦涉及信息层次组织、叙事逻辑,或者更主观的视觉美感,表现就明显乏力,容易被“好看的皮囊”迷惑,也很难系统地评价“这张图是否真的帮人看懂了数据”。
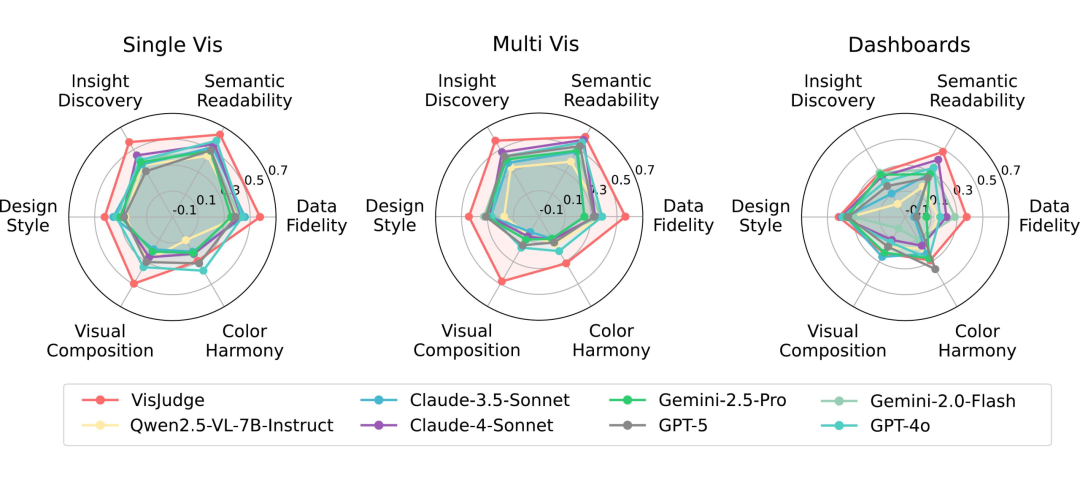
上图从左到右分别为单图、多图与 Dashboard 上各模型在六个评估维度(数据忠实度、语义可读性、洞察发现、设计风格、视觉构图、色彩协调)上的表现对比,可以直观看到各模型在“偏科”与场景上的差异。
再次,Dashboard 成了当前大模型的“噩梦场”。当需要跨多张图表去理解全局信息、梳理指标之间的关系时,部分通用模型甚至出现了与专家评分“负相关”的极端情况:模型越喜欢的设计,专家越不认可。相比之下,VisJudge 虽然也还不完美,但已经能够在“多图联动”和“信息优先级”上做出相对合理的判断。
最后,专业数据能让小模型实现“逆袭”与“实战”。
没有在可视化质量上做过专项训练的大模型,本质上是在用“通用语言能力”硬扛专业任务,就像让语文老师去改高数卷子。而实验表明,微调后的 3B 小模型(相关性 0.648)在专业评估能力上竟然超越了未微调的 72B 开源大模型(0.440)甚至 GPT-5。
更重要的是,VisJudge 不仅能当“裁判”,还能当“教练”:将其作为奖励模型(Reward Model)集成到 MatPlotAgent(生成)和 HAIChart(推荐)系统后,下游任务的效果分别提升了 6.07 分 和 5.3% 。这证明了 VisJudge 在自动化数据分析(AutoDA)链路中巨大的实战价值。
结语:让 AI 真正成为你的 “视觉评审官”
从 VisJudge-Bench 的实验结果可以看出,今天的大模型已经具备了一定的图表理解能力,闭源商用模型整体领先,开源模型也在快速追赶,且模型越「大」,模型越「强」的趋势依然存在。
但同时,它们在图表质量评估上的短板也被暴露得很清楚——在数据忠实度评估上容易误判,对美学和多图协同理解不足,在复杂仪表盘场景中尤其容易“翻车”。
VisJudge-Bench 希望提供的,不只是一个给模型打分的排行榜,更是一面镜子:让研究者看到可视化智能真正难在哪里,让从业者知道现阶段可以放心把什么交给 AI、什么仍然必须由人来把关。
论文已被人工智能顶级会议 ICLR 2026 接收,数据集与代码也已在 GitHub 开源。
我们期待,未来会有更多工作在这套基准上迭代,让 AI 不仅能画出“好看的图”,更能读懂、评价、甚至协助优化图表设计,真正成为数据分析流程中的那位“视觉评审官”——而不是又一个制造信息噪声的黑箱。
关于云栈社区
如果你对数据可视化、多模态大模型的前沿研究与应用实践感兴趣,欢迎来云栈社区与更多开发者和研究者交流。这里汇聚了大量关于人工智能、数据科学的技术干货、开源项目讨论和行业洞察,是技术成长与思维碰撞的理想之地。
 发表于 2026-2-23 04:07:36
|
查看: 261|
回复: 0
发表于 2026-2-23 04:07:36
|
查看: 261|
回复: 0
