在推进一个AI安防项目时,我遇到了一个颇为棘手的性能瓶颈:经过AI分析处理的视频流延迟极高,常常达到2-5秒。这意味着当监控画面中的人员已经离开,报警信息才迟迟触发,这在实际安防场景下几乎是不可用的。
我尝试了各种常规优化手段,从更换视频编码器、调整GOP(图像组)大小到修改网络缓冲区,但收效甚微,延迟问题始终如影随形。问题的根源似乎不在于参数,而在于架构。传统的做法是将AI推理后的视频帧编码,再通过RTMP协议主动推送给流媒体服务器(如ZLMediaKit),最后由服务器转换为WebRTC供浏览器播放。这个“推流”模型不可避免地会在发送端积累缓冲,从而引入难以消除的延迟。
后来,我观察到当ZLMediaKit直接通过RTSP协议拉取摄像头原始流时,其WebRTC播放几乎是实时的。这给了我一个关键启发:如果我将AI处理后的视频也封装成一个标准的RTSP流,让ZLMediaKit主动来拉取,是否能绕过推流缓冲,从根本上解决延迟问题?
思路明确后便立即动手。基于live555库,我开发了一个轻量级的RTSP服务器,并与NVIDIA的NVENC硬件编码器深度集成。最终的结果令人振奋:端到端延迟成功降至50-100毫秒。这不是一次简单的优化,而是一次从“秒级”到“毫秒级”的架构性质变。
项目简介
这是一个专为实时AI视频分析场景设计的超低延迟RTSP服务器。它的核心任务是接收来自AI推理程序(例如经YOLO检测并绘制了边界框的帧)的图像数据,进行实时编码,并通过标准RTSP协议发布视频流。
流媒体服务器(如ZLMediaKit)可以直接拉取这个RTSP流,并将其转换为WebRTC协议,从而实现浏览器端的超低延迟播放。整个数据链路采用了“拉流”而非“推流”的架构,从设计上规避了因缓冲队列堆积带来的固有延迟。
核心功能
- 多格式输入:支持接收OpenCV
cv::Mat 或NumPy数组格式的视频帧。
- 高效编码:支持NVIDIA NVENC硬件编码(首选)或FFmpeg x264软件编码(备用)。
- 标准流发布:通过RTSP协议发布视频流(例如
rtsp://localhost:8554/ai_stream)。
- 自动服务发现:可配置为自动向ZLMediaKit注册流信息,简化WebRTC播放的配置流程。
- 多路并发:支持为多路摄像头创建独立的服务器实例。
- 高可用性:具备网络中断后的自动重连机制,保障服务的持续可用。
技术特点
- 极致低延迟:采用单帧缓冲策略,真正做到来一帧、编一帧、发一帧,无队列堆积。
- 硬件加速:利用NVIDIA GPU的NVENC编码器,单帧编码延迟可低于5毫秒。
- 开箱即用:服务器启动后,配合ZLMediaKit可自动发现流,无需手动配置复杂的拉流任务。
- 多语言集成:提供C++原生库和Python绑定(通过pybind11),集成到现有AI程序中往往只需一行代码。
- 部署灵活:支持在同一端口通过不同URL路径发布多路流,也支持为每个摄像头绑定不同端口。
- 强容错性:当检测到系统无NVIDIA GPU时,会自动无缝回退至CPU软件编码,保证基础功能可用。
技术栈与架构
项目底层基于 live555 实现RTSP服务端协议栈。视频编码优先使用 NVIDIA NVENC 硬件编码器,以确保最低的编码延迟;如果系统没有NVIDIA GPU,则会自动、无缝地切换至 FFmpeg + x264 进行软件编码。
整个通信架构的核心是 拉流模式:由ZLMediaKit主动从本RTSP服务器拉取视频流。这逆转了传统的数据推送方向,从根源上避免了发送端缓冲区堆积问题。Python接口通过 pybind11 封装,能够很好地兼容OpenCV及主流AI框架(如PyTorch, TensorFlow)的输出格式。
完整的低延迟数据流如下所示:
摄像头 → AI推理程序(目标检测+画框) → RTSP服务器(NVENC硬件编码) → ZLMediaKit(WebRTC协议转发) → 浏览器/客户端
效果对比
实测数据清晰地展示了架构改变带来的巨大优势:
| 方案 |
端到端延迟 |
用户体验 |
| 传统RTMP推流 |
2-5秒 |
报警严重滞后,常用于事后追溯 |
| 本方案RTSP拉流 |
50-100毫秒 |
近乎实时同步,可实现事中干预 |
在局域网环境下,原始摄像头画面与叠加了AI分析结果的画面几乎完全同步,肉眼难以分辨先后顺序。这使得安防系统的报警响应从“事后查看录像”变成了真正的“事中实时干预”。
下面是实际运行的效果对比截图:
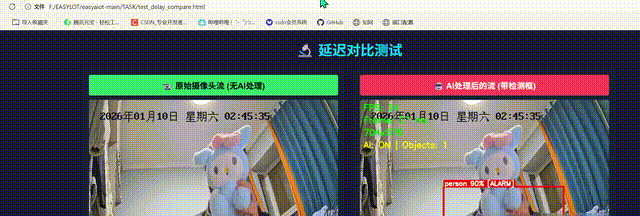
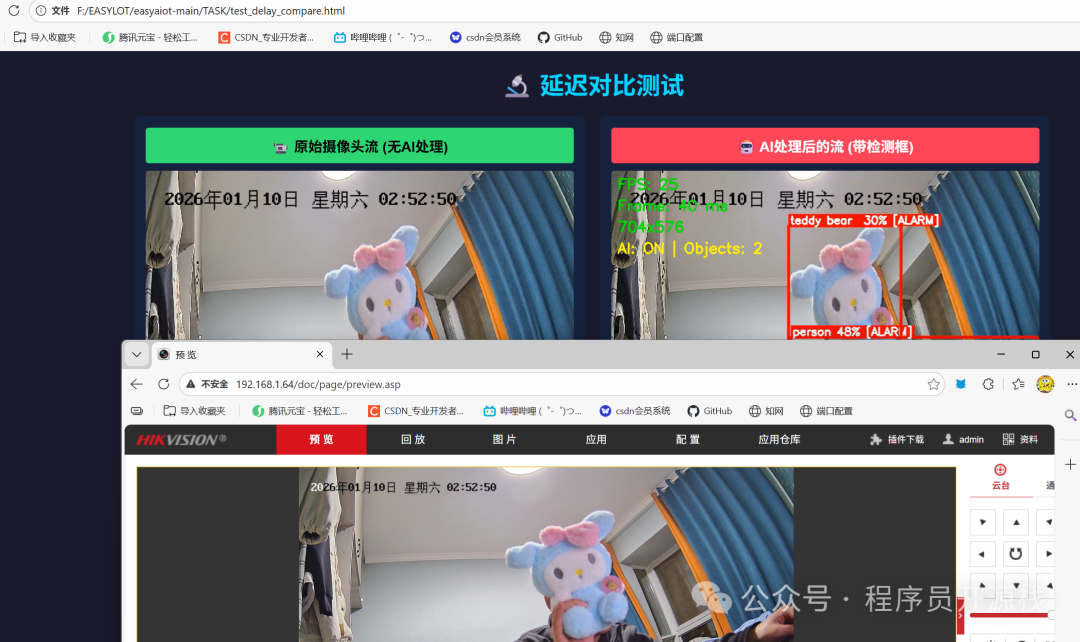
左侧是摄像头的原始画面,右侧是经过AI目标检测并标注了边界框的画面,两者时间戳基本一致,达到了近乎同步的播放效果。
项目源码与集成
项目已在Gitee平台开源,目录结构清晰,便于理解和二次开发:
rtsp_server/
├── RTSPServer.h/.cpp # 核心C++实现类
├── example_main.cpp # 独立运行示例
├── build.bat # Windows编译脚本
├── python/ # Python绑定目录
│ ├── rtsp_server_pybind.cpp
│ └── example.py
└── 3rdparty/live555/ # 内置的live555依赖库
C++集成示例 非常简洁:
RTSPServerWrapper server;
// 初始化:端口、流名称、宽、高、帧率
server.init(8554, "ai_stream", 704, 576, 25);
server.start();
// ... 在你的AI推理循环中
server.pushFrame(frame); // 只需这一行代码!
Python集成 同样简单直接:
import rtsp_server
server = rtsp_server.RTSPServer(8554, "ai_stream", 704, 576, 25)
server.start()
# ... 在推理循环中
server.push_frame(frame) # 也只需这一行代码!
项目地址:https://gitee.com/volara/rtsp-server
总结与思考
这个项目源于一个非常具体的工程痛点——AI视频分析的实时性要求。最终,通过颠覆传统的“推流”思维、拥抱“拉流”架构、实施极简缓冲策略并充分利用硬件加速能力,我们实现了延迟的数量级下降。
它并非一个追求功能大而全的流媒体服务器,而是精准聚焦于“超低延迟”这一核心目标。对于智能监控、工业视觉质检、远程实时巡检等对延迟极度敏感的AI视频应用,本方案提供了一条经过验证的、行之有效的低延迟技术路径。
它再次印证了一个道理:在面对顽固的性能瓶颈时,最有效的优化往往不是对现有方案参数的微调,而是跳出来,重新审视和设计整个系统架构。希望这个基于RTSP拉流的实战经验,能为面临类似挑战的开发者提供一个新思路。也欢迎大家在云栈社区交流关于实时音视频、高性能网络编程的相关技术问题。
 发表于 2026-2-24 01:58:15
|
查看: 331|
回复: 0
发表于 2026-2-24 01:58:15
|
查看: 331|
回复: 0
