近日,全球领先的内容分发网络(CDN)与服务提供商Cloudflare再次发生服务中断,影响了大量互联网业务。
官方事故说明
根据Cloudflare官方博客发布的报告,本次事件时间线如下:
- 发生时间:2025年12月5日
- 持续时间:约25分钟(于09:12完全恢复)
- 影响范围:约28%的HTTP流量
官方明确指出,此次中断并非由网络攻击或恶意活动导致。根本原因是在尝试检测和缓解一个近期在 React服务器组件中披露的行业级漏洞 时,对其请求正文解析逻辑的更改意外触发了故障。
Cloudflare在公告中表示:“我们系统的任何中断都是不可接受的。继11月18日的事件之后,我们深知再次令依赖我们的互联网社区失望。我们将于下周公布防止此类事件再次发生的详细改进方案。”
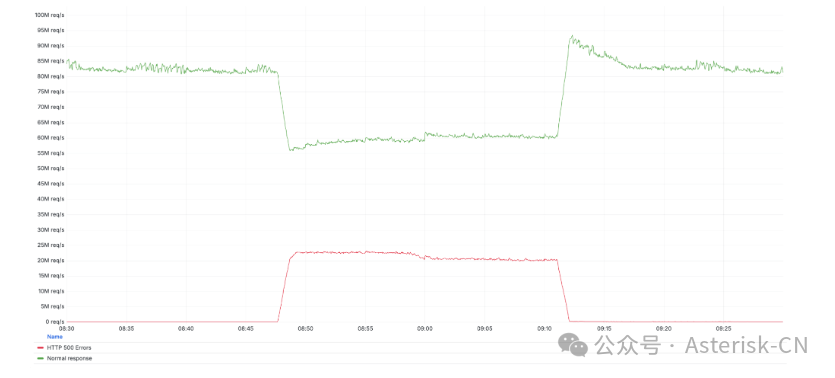
下图对比了故障期间产生的HTTP 500错误(红线)与网络总流量(绿线):
技术社区的反思与讨论
事件发生后,技术社区对此次宕机的原因进行了深度探讨。一种有代表性的观点指出,这暴露了更深层的架构问题:
“Lua脚本漏洞、上周的全球性长时间中断,以及此前的一系列类似事件,共同指向了底层架构的潜在风险。传统、分布式、去中心化的网络架构由众多异构节点管理,对全球性中断具有更强的抵抗力。而像Cloudflare这样高度同质化的系统,则更容易因单点问题导致大规模服务瘫痪。编程语言(如Rust)本身无法根除此类问题,因为人为错误始终存在。真正稳健的 云原生架构 应通过设计,避免单一错误使大量无关服务瞬间崩溃。”
总结
本次Cloudflare中断事件是一次典型的“为修复安全问题而引入运营故障”的案例。它警示所有技术团队,在进行安全更新、尤其是涉及核心流量处理逻辑时,必须辅以更严谨的测试与灰度发布机制。对于构建高可用性全球服务而言,架构的冗余性与故障隔离能力与代码质量同等重要。
参考来源:
|  发表于 2025-12-7 00:53:02
|
查看: 213|
回复: 0
发表于 2025-12-7 00:53:02
|
查看: 213|
回复: 0
