音频令牌器作为连接原始音频信号与大语言模型的关键桥梁,其性能直接决定了后续音频理解、生成以及交互任务的上限。然而,现有的解决方案或多或少存在一些限制,要么架构存在偏见导致泛化能力不强,要么依赖于预训练编码器增加了系统复杂性,要么难以在高质量音频重建和语义对齐之间取得平衡。
近日,MOSI.AI 推出的开源项目 MOSS-Audio-Tokenizer,凭借其纯 Transformer 架构与端到端训练的设计理念,在 1.6B 参数规模下,实现了对语音、音效和音乐的全场景高质量令牌化。更引人注目的是,它成功支撑起首个在性能上超越非自回归系统的纯自回归 TTS 模型,为音频基础模型设定了一个全新的通用接口标准。接下来,我们将深入解析这篇论文,探究其背后的核心技术创新。
一、研究背景
音频令牌化的核心目标,是将连续的音频信号转化为离散的令牌序列,从而让大语言模型能够像处理文本一样去理解和生成音频。但传统的方案长期被几个关键问题所困扰,严重制约了音频基础模型的进一步发展:
(1)架构偏见,泛化能力受限
目前大多数音频令牌器依赖于卷积神经网络或其与 Transformer 的混合架构。CNN 固有的局部归纳偏置,使其难以有效捕捉音频中的长时依赖关系,导致模型对不同类型音频(如语音、音乐、环境音)的适配性较差。通常一个模型在单一场景下表现尚可,一旦跨场景应用,性能就会显著下降。
(2)训练割裂,性能天花板低
许多方案采用分阶段训练策略,例如先训练编码器,再训练量化器,最后训练解码器,或者依赖预训练好的语音编码器进行知识蒸馏。这种割裂的训练方式使得各个模块无法协同优化,最终结果往往是顾此失彼——要么重建的保真度不足,要么生成的令牌在语义和声学特征上存在冲突,难以同时满足“高保真重建”和“LLM友好”的双重需求。
(3)功能单一,场景适配性差
现有模型要么只支持固定码率,无法灵活应对不同带宽场景的需求;要么生成的令牌序列帧率过高,给下游 LLM 带来了沉重的建模负担;要么仅针对语音生成任务优化,难以支撑自动语音识别、音频理解等多样的下游任务,缺乏一个真正统一的音频离散化接口。
MOSS-Audio-Tokenizer 的设计目标,正是为了系统性地解决上述三大痛点:通过纯 Transformer 架构消除归纳偏置,利用端到端训练实现模块间的深度协同,并采用低帧率与可变码率设计来适配多任务需求,旨在打造一个真正通用的音频令牌化解决方案。
二、核心创新点
MOSS-Audio-Tokenizer 能够实现全场景的卓越性能,并非依靠简单的参数堆砌,而是源于四个直指行业痛点的创新设计,从根本上革新了音频令牌化的技术范式:
模型摒弃了对传统 CNN 的依赖,提出了名为 CAT 的架构。该架构的编码器和解码器完全由因果 Transformer 块构成,从输入到输出全程没有任何 CNN 组件。
- 因果设计:每个令牌的生成仅依赖于历史的音频信息,这使其天然支持流式编码和解码,能够满足实时交互应用的需求。
- 分层下采样:通过在 Transformer 块之间插入 patchify 操作,逐步降低时序分辨率,最终将 24kHz 的原始音频压缩为 12.5Hz 的低帧率令牌序列,这大幅减轻了下游 LLM 的建模负担。
- 统一建模:由于没有引入特定的架构偏置,模型能够平等、有效地适配语音、音乐和环境音,避免了在单一场景上过拟合的问题。
这种设计完美契合了 LLM 的自回归建模逻辑,使得音频令牌与文本令牌的适配过程更加自然,为构建“音频语言模型”奠定了统一的基础。
2.2 端到端联合优化:实现模块深度协同
该模型打破了分阶段训练的局限性,将编码器、量化器、解码器、判别器以及用于语义对齐的 LLM 全部纳入一个统一的训练框架中,实现了全组件的协同优化。
- 无预训练依赖:所有模块均从零开始训练,不依赖任何预训练的音频编码器或语义教师模型,避免了外部依赖可能带来的能力上限束缚。
- 多目标融合:模型联合优化了五大核心目标,兼顾了声学保真度与语义对齐:
- 重建损失:采用多尺度梅尔谱损失,确保音频的高质量重建。
- 量化损失:结合承诺损失与码本损失,优化离散令牌的表征能力。
- 语义损失:通过自动语音识别、音频字幕等任务,迫使令牌序列蕴含丰富的语义信息。
- 对抗损失:引入判别器提升生成音频的感知质量。
- 动态适配:在训练过程中,各模块能够相互调整、适应,有效避免了“重建质量好但语义差”或“语义能力强但音质劣化”的单向短板问题。
2.3 可变码率设计:单模型适配全场景
通过采用 32 层残差向量量化 并结合量化器 dropout 技术,模型实现了从 0.125kbps 到 4kbps 的宽范围可变码率支持。
- 码率控制逻辑:在推理时,通过截断使用的 RVQ 层数量来灵活调节码率。例如,仅使用前 6 层对应 750bps,使用全部 32 层则对应 4kbps,无需更换模型或重新训练。
- 鲁棒性保障:在训练过程中,随机丢弃部分 RVQ 层,迫使解码器学会适应不同码率的输入,从而避免了在低码率下音质出现断崖式下跌。
- 场景适配:低码率模式适用于带宽受限的场景(如语音通话),而高码率模式则能满足高质量音频生成的需求(如音乐创作),单个模型即可覆盖全场景需求。
2.4 渐进式序列丢弃:解锁可变码率生成能力
针对下游的音频生成任务,论文提出了 Progressive Sequence Dropout 训练策略,使得单一的自回归生成模型能够支持可变码率生成。
- 训练逻辑:在训练生成模型时,随机丢弃部分 RVQ 高层的令牌,迫使模型学习基于有限码层信息进行生成的能力,同时保留核心的声学特征。
- 推理灵活:在推理阶段,通过直接指定 RVQ 的推理深度,即可控制生成音频的码率,无需对模型结构做任何调整。
- 效率优化:该策略显著降低了训练时的 GPU 内存消耗,同时保证了模型在不同码率下生成质量的一致性。
三、模型架构
MOSS-Audio-Tokenizer 的架构设计在性能、通用性和工程落地性之间取得了平衡,每一个细节都紧紧围绕“通用音频令牌化”这一核心目标展开。
模型整体包含五大核心组件,构成了一个“输入-编码-量化-语义对齐-解码”的完整闭环:
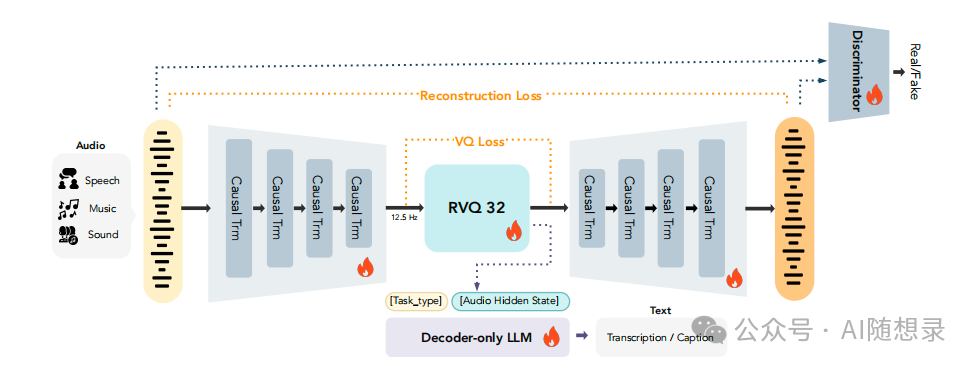
- 输入处理:直接接收 24kHz 的单声道原始音频波形,无需转换为梅尔谱等中间表征,减少了信息损失。
- 编码器:由 68 层因果 Transformer 构成,分为四个阶段进行逐步下采样,隐藏维度从 768 逐步增加至 1280,通过滑动窗口注意力机制来有效捕捉长时依赖。
- 量化器:采用 32 层 RVQ,每层码本大小为 1024,并使用了因子化向量量化技术来优化训练的稳定性。
- 语义对齐模块:集成一个 0.5B 参数的 decoder-only LLM,基于生成的令牌序列来预测对应文本,从而为令牌注入丰富的语义信息。
- 解码器:采用与编码器对称的 68 层因果 Transformer 结构,负责从离散令牌重建出 24kHz 的音频波形,并支持流式输出。
3.2 训练细节:大规模数据与高效优化
- 训练数据:使用了总计 300 万小时的多样化音频数据,涵盖纯净语音、嘈杂环境音以及各类音乐,同时包含了大量的音频-文本配对数据。
- 训练策略:采用两阶段训练法,首先进行 520k 步的非对抗预训练以稳定模型,随后进行 500k 步的对抗微调以提升感知质量。
- 优化配置:使用 AdamW 优化器,生成器学习率设为 1e-4,权重衰减为 0.01,采用 bfloat16 混合精度训练,全局批次大小最高可达 1536,确保了训练的效率与稳定性。
- 工程优化:利用 FlashAttention-2 加速注意力计算,支持分布式训练,能够在 1024 卡的集群上高效完成模型训练。
3.3 下游适配:令牌的全场景赋能
MOSS-Audio-Tokenizer 生成的令牌可以直接适配三大核心下游场景,无需额外的适配层:
- 音频重建:令牌直接输入解码器即可输出音频,可用于音频压缩、降噪等任务。
- 音频生成:基于该令牌训练自回归生成模型,可实现文本到语音或音乐的生成。
- 音频理解:令牌可以直接输入到大语言模型中,完成自动语音识别、音频分类等任务,无需专门的音频编码器。
四、实验结果
MOSS-Audio-Tokenizer 在音频重建质量、生成性能以及理解能力三大维度上均展现出全面领先的优势,多项指标刷新了开源音频令牌器的纪录。
4.1 音频重建:全码率、全场景领先
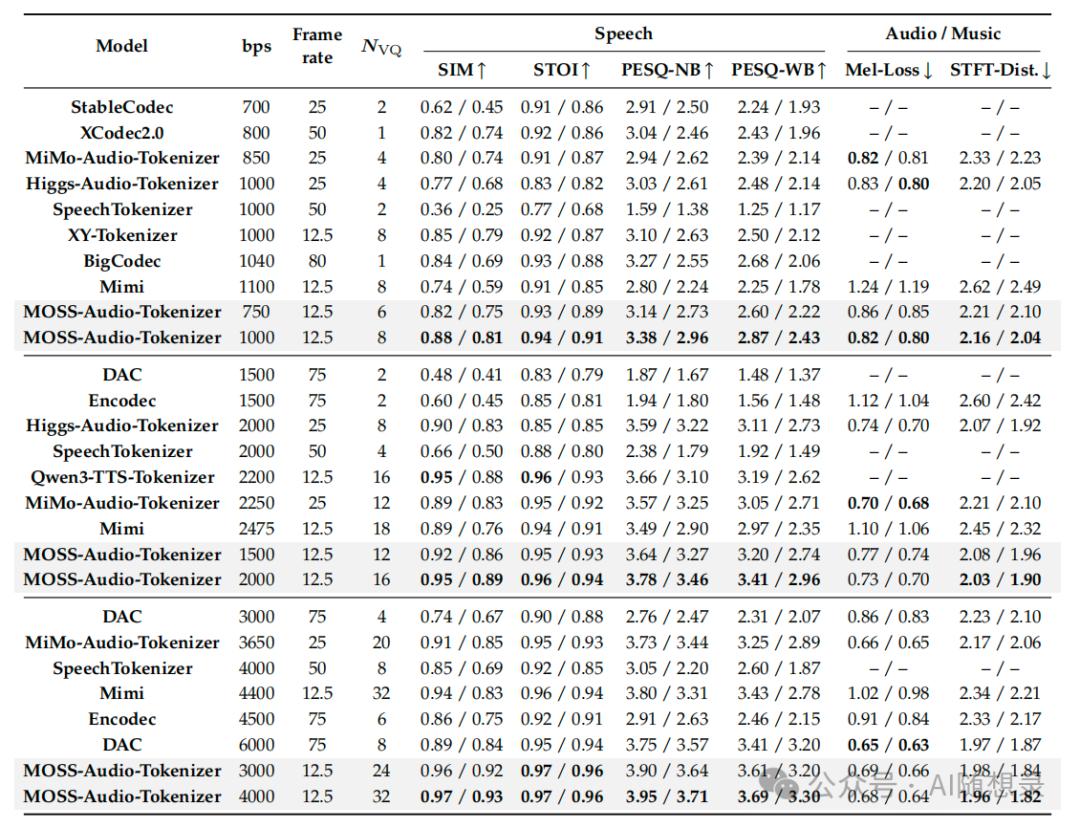
在语音、音乐和环境音三大场景的客观与主观评测中,该模型均大幅超越了 Encodec、DAC、SpeechTokenizer 等主流开源令牌器:
| 评测维度 |
关键结果 |
| 语音重建(中/英文) |
在 4kbps 码率下,PESQ-WB 指标达到 3.69/3.30,说话人相似度 SIM 达到 0.97/0.93,均排名第一;即使在 750bps 的低码率下,SIM 仍能保持 0.82/0.75,远超同类模型。 |
| 音乐/环境音重建 |
在 MUSDB 数据集上,梅尔损失为 0.64,STFT 距离为 1.82,显著低于其他对比模型,重建音质更接近原始音频。 |
| 主观评测 |
在全码率区间内的 MUSHRA 得分均超过 70 分,4kbps 时音质接近参考音频,且在低码率下音质衰减平缓,未出现断崖式下跌。 |
4.2 音频生成:纯自回归TTS首次超越非自回归
基于 MOSS-Audio-Tokenizer 的令牌,研究人员构建了纯自回归的 CAT-TTS 模型,其在 Seed-TTS-Eval 基准测试中表现卓越:
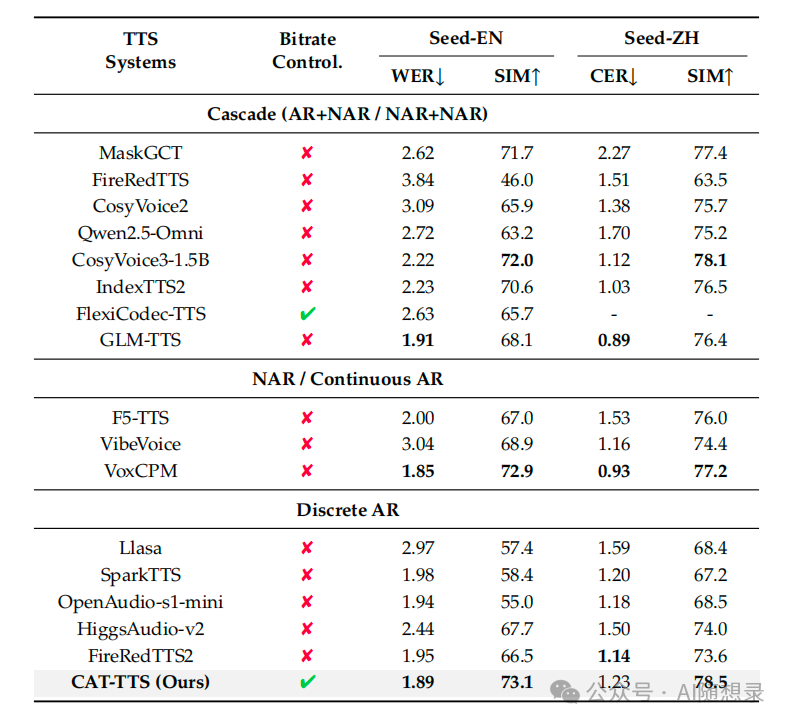
- 核心指标:在英文测试集上,词错误率 WER 为 1.89%,说话人相似度 SIM 为 73.1%;在中文测试集上,字符错误率 CER 为 1.23%,SIM 为 78.5%,其说话人相似度在开源模型中排名第一。
- 关键突破:这是首次有纯自回归的离散 TTS 系统,在性能上超越了非自回归系统以及复杂的级联系统。
- 可变码率能力:在 1kbps 到 4kbps 的码率范围内,生成语音的 WER 和 SIM 指标波动小于 3%,稳定性远超固定码率模型。
4.3 音频理解:无专用编码器实现有竞争力的ASR
直接将令牌输入 LLM 构建的 CAT-ASR 系统,无需任何专用音频编码器,仍取得了优异成绩:
- 在英文 LibriSpeech 测试集上,词错误率 WER 为 2.96%;在中文 AIShell-2 测试集上,字符错误率 CER 为 3.44%。
- 与 Qwen2-Audio、Baichuan-Audio 等专用 ASR 模型相比,CAT-ASR 在模型参数量更小的情况下仍保持了竞争力,这证明了其令牌本身具备强大的语义表征能力。
4.4 缩放特性:性能随规模稳步提升
模型展现了良好的缩放特性,验证了其架构的通用性和可扩展性:
- 参数缩放:当模型参数量从 319M 增加到 1.169B 时,语音重建的 PESQ-WB 指标从 2.49 提升至 3.34,未出现性能饱和的迹象。
- 数据缩放:随着训练批次大小指数级增加,STOI、SIM 等指标持续上升,证明大规模训练能够持续提升令牌质量。
- 端到端优势:与分阶段训练相比,采用端到端训练的模型在所有评测指标上均保持领先,且性能提升似乎没有上限,而分阶段训练的模型则较早进入了性能平台期。
五、核心挑战与未来方向
5.1 核心优点
- 架构通用:纯 Transformer 设计无归纳偏置,能完美适配语音、音乐、环境音全场景。
- 性能顶尖:在全码率下的重建质量、生成性能、理解能力均位居开源模型前列。
- 灵活可控:支持宽范围的可变码率,单模型即可满足多场景需求。
- 工程友好:支持流式推理、低内存训练,并开源了模型权重和代码,便于直接集成与落地。
- 生态兼容:令牌格式与 LLM 的自回归建模方式天然契合,为构建音频语言模型提供了统一的接口。
5.2 主要缺点
- 高码率音乐生成仍有提升空间:在 4kbps 音乐生成场景下,与专业的音乐生成模型相比,在音色丰富度和节奏一致性方面仍存在差距。
- 多声道支持缺失:当前版本仅支持单声道音频处理,尚未适配立体声、环绕声等多声道场景。
- 极端低码率语义保留不足:在 0.125kbps 的极低码率下,语音中的部分语义信息(如罕见词汇)可能丢失,会影响自动语音识别的准确率。
5.3 关键改进方向
- 多声道扩展:增加对多声道音频的建模能力,支持立体声、环绕声的令牌化与生成。
- 分层语义增强:引入更细粒度的音频语义任务,如情感识别、音效分类等,进一步提升令牌的语义表征能力。
- 轻量化优化:通过模型压缩、量化等技术,降低模型部署时的计算和存储成本,以适配边缘设备。
- 跨模态对齐:加强音频令牌与文本、图像等其他模态信息的对齐,为更复杂的多模态生成与理解任务提供支撑。
六、总结
MOSS-Audio-Tokenizer 的推出,不仅刷新了开源音频令牌器的性能上限,更重要的是重新定义了音频基础模型的发展方向。它推动技术范式从“单一场景专用”转向“全场景通用”,从“分阶段割裂训练”转向“端到端协同优化”,从“固定码率”转向“灵活适配”,为未来的音频理解、生成与交互任务搭建了一个统一的离散化接口。
对于研究人员而言,MOSS-Audio-Tokenizer 提供了一套基于纯 Transformer 架构的端到端训练范式,其展现出的缩放特性和多任务适配能力,为后续的相关研究提供了明确的参考路径。对于开发工程师来说,开源的模型权重和代码可以直接集成到音频压缩、语音合成、智能语音助手等产品中,能够大幅降低研发门槛和成本。而对于普通用户,这意味着未来的音频AI工具将变得更加灵活、智能和高质量,无论是低带宽下的清晰通话、高质量的AI音乐创作,还是实时的多场景音频理解,都将逐步成为现实。如果你想了解更多此类前沿技术的深度解析与实战应用,欢迎持续关注云栈社区的技术动态。
 发表于 2026-3-4 03:20:51
|
查看: 176|
回复: 0
发表于 2026-3-4 03:20:51
|
查看: 176|
回复: 0
