
本文介绍的是一种名为 Vivid-VR 的生成式视频复原算法,该成果已被顶级机器学习会议 ICLR 2026 收录。针对现有基于扩散模型的视频复原方法在微调时常见的“分布漂移”问题——这会导致纹理失真和时序不一致——Vivid-VR 创新性地提出了 “概念蒸馏” 训练策略。它利用文本到视频(T2V)基座模型自身来合成与文本完美对齐的训练数据,从而将其概念理解能力迁移至复原任务中。此外,文章还设计了控制特征投影器以过滤输入视频的退化伪影,以及双分支连接器以动态融合控制特征。实验表明,Vivid-VR 在真实拍摄视频和 AIGC 视频上,均在纹理真实感、视觉生动性和时序一致性方面显著优于现有的 SOTA 方法。
论文背景介绍
ICLR(国际表征学习大会)是机器学习领域的全球顶级学术会议,重点关注深度学习前沿研究。ICLR 2026 收到了近 19,000 篇有效投稿,整体录用率约 28%。这篇由淘天音视频技术团队完成的论文,属于基于生成式大模型的视频复原领域。
当前,尽管扩散模型在图像复原上成果显著,但如何将其成功应用于视频复原仍面临挑战。微调过程中存在的“分布漂移”问题,使得现有生成式视频复原方法在纹理真实感和时序一致性上表现不佳。为此,该团队自研了基于概念蒸馏的模型 Vivid-VR。该模型在多种视频类型上均表现出色,超越了现有方法。
论文下载链接: https://arxiv.org/abs/2508.14483
项目开源地址: https://github.com/csbhr/Vivid-VR
论文摘要
该论文提出了 Vivid-VR,一种基于 Diffusion Transformer(DiT)架构的生成式视频复原方法。该方法基于 T2V 基础模型构建,并利用 ControlNet 控制生成过程以确保内容一致性。
然而,传统微调方法由于多模态对齐不完美,极易导致“分布漂移”,从而降低生成视频的质量。为此,本文提出了一种“概念蒸馏”训练策略,利用预训练的 T2V 模型自身来合成内嵌文本概念的训练样本,从而将其概念理解能力“蒸馏”到复原模型中。
此外,为了增强生成可控性,本文重新设计了控制架构的两个关键组件:
- 控制特征投影器:用于过滤输入视频潜在空间中的退化伪影。
- 双分支连接器:结合 MLP 特征映射与交叉注意力机制,实现控制特征的动态检索。
大量实验表明,Vivid-VR 在合成数据集、真实世界视频以及 AIGC 视频上的表现均优于现有方法。

图1. 在真实拍摄视频(左)和AIGC视频(右)上的视频复原结果对比
具体方法
在生成式视频复原的新范式下,如何利用强大的 T2V 基座模型修复低质视频,同时避免模型在微调过程中“遗忘”原有的生成能力,是关键挑战。团队发现,现有微调方法会导致模型偏离其原始潜在分布,即“分布漂移”。Vivid-VR 从数据策略和模型架构两个维度进行了重构。
核心痛点
现有基于 T2V 的视频复原方法,通常需要“低质视频”和对应的“文本描述”作为输入。构建训练数据时,常用视觉语言模型(VLM)根据视频生成文本描述。但 VLM 生成的描述往往无法与视频内容完美对齐。在微调过程中,这种“图文不符”的噪声数据会导致“分布漂移”,表现为生成的视频纹理失真以及帧间闪烁或形变。
概念蒸馏训练策略
为了解决分布漂移问题,团队并未追求更昂贵的 VLM 标注模型,而是提出了一种巧妙的“概念蒸馏”策略,利用 T2V 基座模型本身的生成能力来构建训练数据。
海量高质量训练视频构建
为满足基于 DiT 架构方法的训练需求,团队收集了 300 万 个高清视频,涵盖人像、自然景观、动植物、城市景观等广泛场景。通过多种质量评估算子筛选后,使用 VLM 模型生成对应文本描述。最终精选的多模态训练数据集包含 50 万个 文本-视频对。
概念蒸馏样本合成
由于 VLM 模型的限制,构建的文本-视频数据对并未完美对齐,这可能导致微调期间出现“分布漂移”问题。开发更准确的 VLM 模型不仅成本高昂,且无法消除在 T2V 模型潜在空间的差异。
为此,团队采用 T2V 模型本身来执行文本引导的 Video-to-Video 任务,生成用于蒸馏的训练数据。具体来说,给定一个文本-视频对,对源视频施加特定强度的噪声,然后使用 T2V 基座模型在文本描述的引导下对噪声视频进行去噪重构。如图 2(第二行)所示,生成的视频很大程度上保留了源内容,但修改了一些概念以更好地与文本描述保持一致。团队生成了 10万 个这样的样本对,将其与原始训练数据集混合,用于对基于 DiT 的视频复原模型进行微调。
这一过程中,生成的视频在 T2V 模型的潜在空间中与文本描述实现了天然的完美对齐。将这些合成数据混合到训练集中,Vivid-VR 成功地将 T2V 基座模型对文本概念的深刻理解转移到了视频复原模型中,有效缓解了“分布漂移”问题。
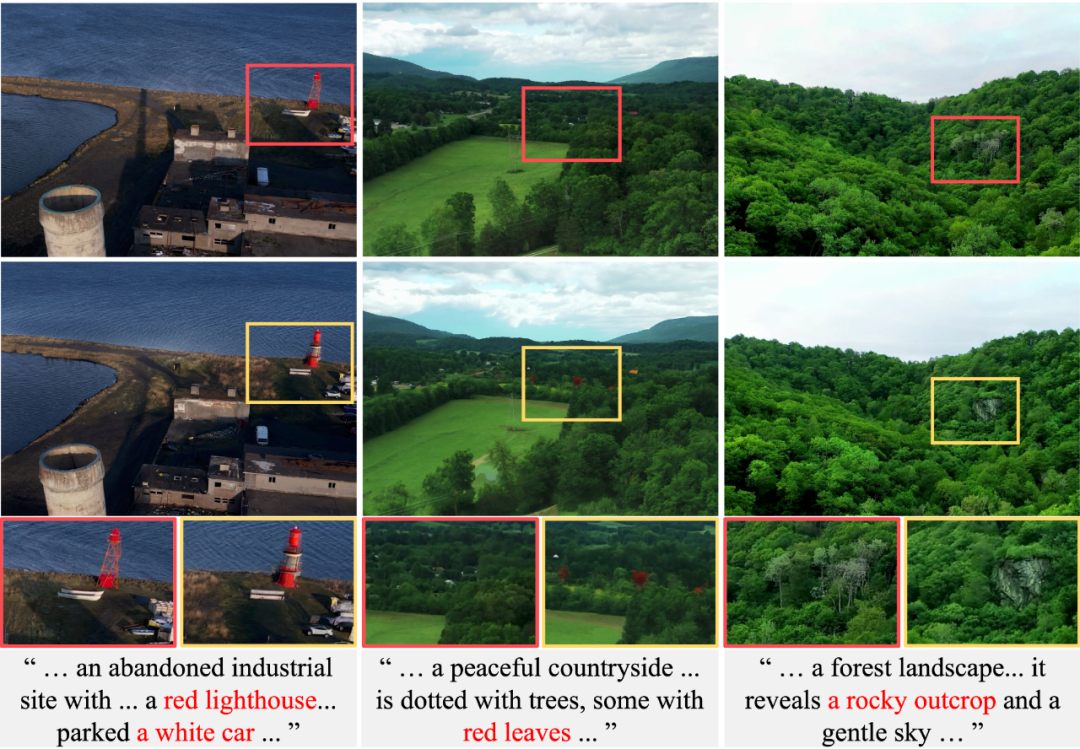
图2. 由概念蒸馏策略生成的示例视频。第一行显示源视频,第二行显示通过 T2V 模型嵌入文本概念后生成的视频。生成的视频具有更好的模态对齐。
模型架构
图3给出了 Vivid-VR 的模型架构示意图。除了数据策略,本文在架构设计上也针对 DiT 特性进行了两项关键改进。
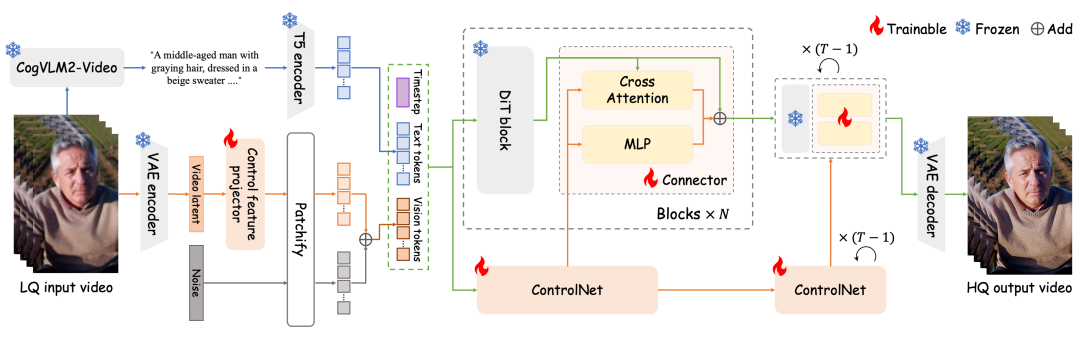
图3. Vivid-VR 模型架构示意图
控制特征投影器
直接将低质视频的潜在特征输入 ControlNet 会引入大量退化信息(如模糊、压缩伪影)。本文设计了一个轻量级的特征投影器,使其在特征进入生成流程前,有效滤除退化伪影,得到更纯净的控制信号。该投影器由三个级联的时空残差卷积模块组成,相比联合微调整个 VAE 编码器,该方案以极低的计算开销实现了类似效果。
双分支连接器
当前常用的 ControlNet 连接器(如 ZeroMLP、ZeroSFT)难以充分融合 DiT 特征。本文设计了全新的双分支连接器结构:
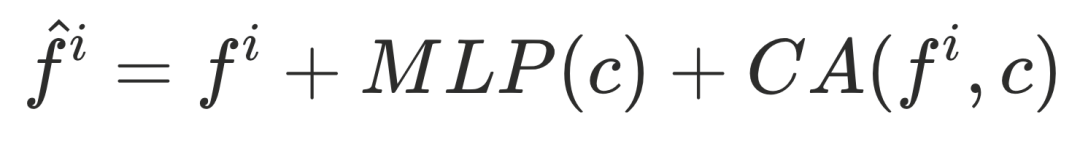
公式为:$\hat{f}^i = f^i + \text{MLP}(c) + \text{CA}(f^i, c)$,其中:
- MLP分支:负责控制特征的映射。
- Cross-Attention分支:利用注意力机制动态检索相关的控制特征。
这种设计既保留了控制特征的内容结构,又实现了对控制信号的自适应调制,显著提升了生成质量。
实验论证与结果
为全面评估 Vivid-VR 的性能,团队在合成数据集(SPMCS, UDM10, YouHQ40)、真实世界数据集(VideoLQ, UGC50)以及 AIGC 视频数据集(AIGC50)上进行了广泛测试,并与现有方法对比,包括基于重建的方法(Real-ESRGAN)、生成式图像复原方法(SUPIR)、生成式视频复原方法(MGLD, UAV, STAR, DOVE, SeedVR)。
定量评估
如表1所示,在 NIQE、MUSIQ、CLIP-IQA、DOVER、MD-VQA 等反映人类视觉感知的无参考质量评价指标上,Vivid-VR 取得了压倒性优势。特别是在 AIGC 视频增强任务中,Vivid-VR 展现了极强的泛化能力。
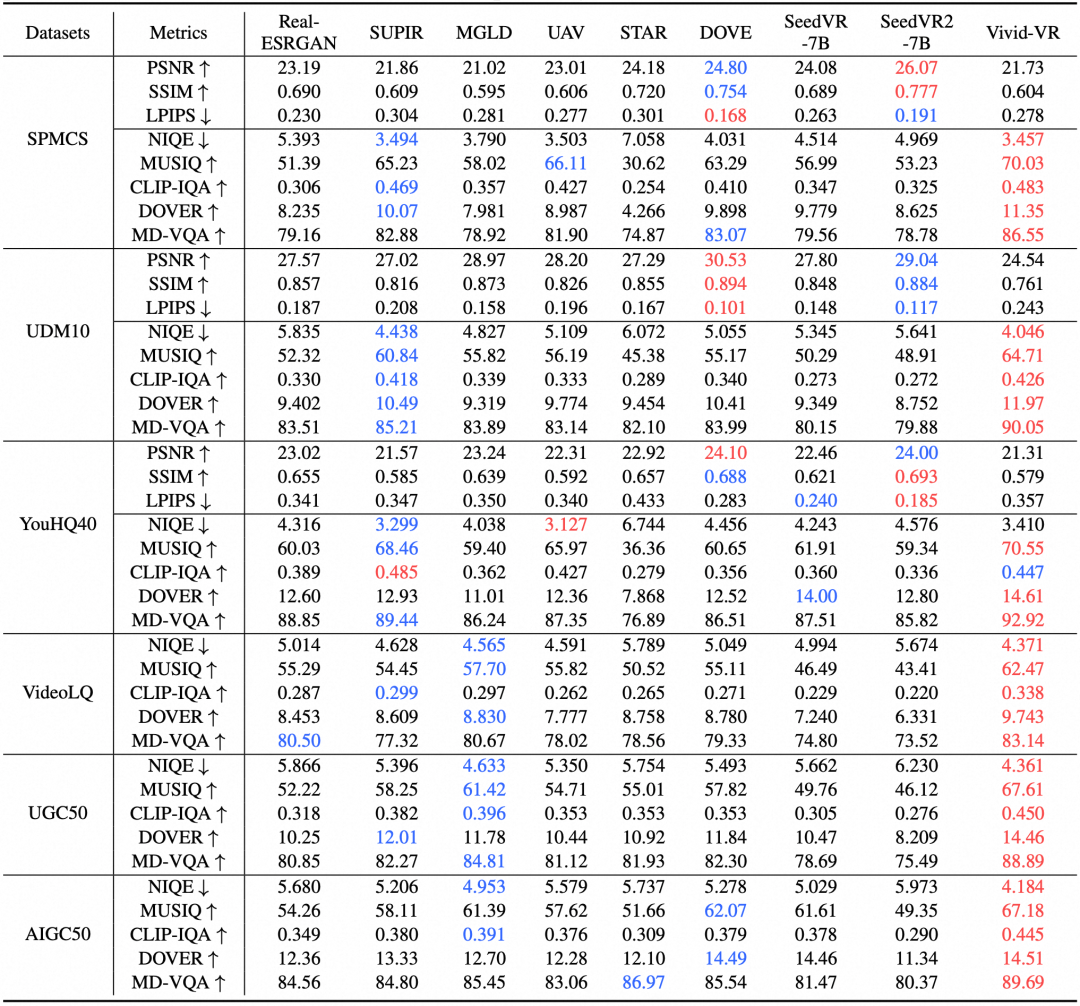
表1. 定量评估结果,涵盖合成视频、真实视频和 AIGC 视频
定性评估
可视化对比(图4、图5)展示了 Vivid-VR 在纹理真实感、视觉生动性、时序一致性上的出色表现:
- 结构重建:处理模糊的房屋结构时,Vivid-VR 能生成清晰、合理的门窗线条,而其他方法常出现结构扭曲。
- 纹理质感:在人像和动物毛发处理上,Vivid-VR 生成的发丝分明,肤质细腻自然,避免了“过度磨皮”或“油画感”。
- 时序一致性:Vivid-VR 在视频序列中能保持物体结构的高度稳定(如窗户形状不变形),而其他方法则出现纹理闪烁或帧间跳变。

图4. 定性评估结果,包括合成视频(第一行)、真实世界视频(第二行)和 AIGC 视频(第三行)

图5. 在时序一致性上的可视化比较结果
消融实验
为探索不同模块对模型性能的贡献,团队进行了消融实验。表2和图6的结果表明:控制特征投影器、双分支连接器、概念蒸馏策略均能有效提升模型性能。
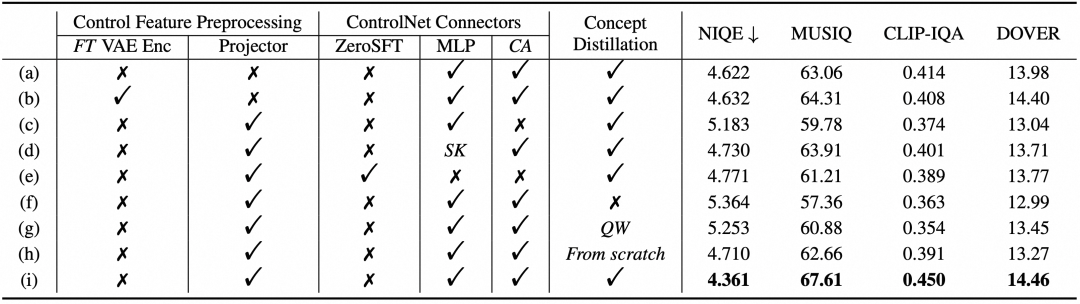
表2. 消融实验定量评估结果
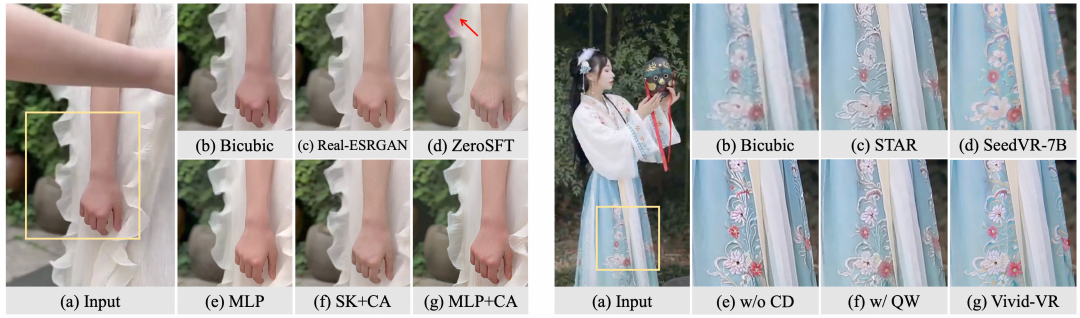
图6. 消融实验定性评估结果,左图展示双分支连接器的作用,右图展示概念蒸馏的作用
总结与展望
本文提出了一种基于 DiT 架构的生成式视频复原模型 Vivid-VR。通过创新性的概念蒸馏训练策略,有效解决了微调大模型时的分布漂移难题。配合轻量级的控制特征投影器和双分支连接器,Vivid-VR 在纹理细节、视觉生动性和时序连贯性上均显著优于现有 SOTA 方法。
尽管效果出色,但基于 5B 参数的 T2V 基座模型使得 Vivid-VR 的推理成本较高。未来的工作将致力于提升算法效率,例如探索单步/少步扩散模型技术,力求在保持高画质的同时实现更快的推理速度,推动该技术在实际工业场景中更广泛的落地。
对前沿的生成式AI技术、模型架构优化或视频处理算法有更多想法?欢迎到 云栈社区 的开源实战板块,与更多开发者和研究者交流探讨。
 发表于 2026-3-5 04:47:45
|
查看: 206|
回复: 0
发表于 2026-3-5 04:47:45
|
查看: 206|
回复: 0
