近年来,搜索、推荐与广告系统在粗排与精排阶段的模型训练呈现出一个明确趋势:从单目标优化转向多目标建模与多目标融合。模型目标增多、融合公式日趋复杂,这对工程系统的可维护性以及算法迭代的效率都构成了不小的挑战。
为了能够直观、清晰地展示公式全貌,并方便算法工程师灵活决策和调整参数方向,我们迫切需要一种能够直接配置公式、并在线上自动计算(既支持精排预估目标融合,也支持业务条件动态调权)的解决方案。为此,我们设计并落地了 加乘树调参框架。从1.0版本持续优化至3.0,我们提供了一个Java版本的调参框架(引擎基建同学也同步落地了C++版),能够支持不同算法环节“公式即配即用”;同时构建了一个打通AB实验的一站式产品化平台,支持从“辅助配置 -> 调试 -> 开启实验 -> 变更管控”的全流程。
带来的收益是显著的:无论是粗排还是精排,“训练多目标模型、融合公式调参”已成为工业界的标准范式。在得物社区搜索与推荐的模型迭代实践中,我们也坚定地采用了“模型多目标训练 + 融合公式调参”这一路径。仅2025年,就在社区推荐与社区搜索场景落地了数十次LR(用于社区推荐内外流精排、粗排,以及社区搜索精排),以及近百次加乘树框架的全量推广。
即配即用:算法爆发的催化剂,工程稳定的绊脚石?
在算法领域,“即配即用”的工程框架多次成为推动算法快速迭代乃至“爆发式增长”的关键基础设施。面对粗排、精排“多目标建模 + 多目标融合”这一建模范式,社区算法与工程团队共同提出了如下基建目标:
- 即配即用提人效:实时调整配置,线上自动生效数学逻辑,使算法工程师从过去几天才能完成一次调参,转变为一天内可进行多次迭代,从而将精力聚焦于模型和融合公式本身的优化。
- 全量配置+增量配置范式:实验只需配置需要修改的几行代码,降低配错风险。全量配置保持不动,形成天然的降级能力。
- DSL可解释性强:粗排、精排的融合公式配置量大,数学变换复杂,容易出错。我们提供的DSL让算法工程师能直接书写数学公式和逻辑表达式。明文化的公式形成了策略全景图,便于算法同学决策调参方向。
- 编译校验与降级体系筑牢稳定性防线:“即配即用”与数学公式DSL的需求,给工程稳定性带来了巨大挑战。我们采用“编译语法校验 + 自动用全量配置降级 + 手动切换编译/解释模式”三位一体的策略来保障系统稳定。
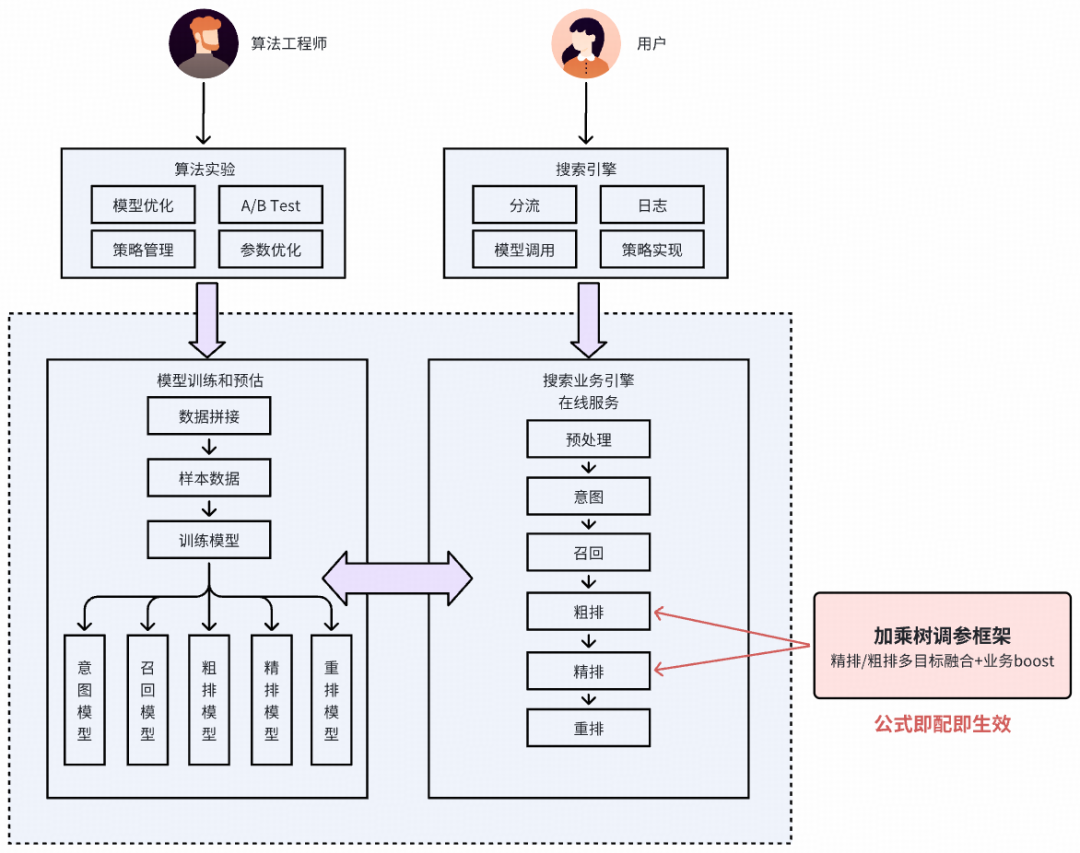
可信赖底座:让复杂公式配置既灵活又可靠
全量配置+增量配置范式
传统的KV、JSON或YAML等配置格式在面对上百行的数学公式时已显乏力:一方面配置体量大,人工修改易出错且缺乏有效的容错机制;另一方面可读性差,难以进行日常维护和审查。
我们采用了“全量配置+增量配置”的设计范式,从源头解决了使用门槛与自动降级问题:
- 只配增量,让使用更轻松、出错更可控:全量配置被锁定为只读状态,确保基线稳定;算法工程师只需声明需要新增或修改的增量配置。系统在运行时会将增量动态合并到全量配置中,生成最终生效的实验配置。这既简化了操作,又从根本上避免了误改全局核心参数的风险。
- 增量可试,基线兜底:增量配置如果存在错误,系统会自动回退至基线全量配置,形成了天然的降级机制。
以下是一个社区搜索主场景精排的配置样例:
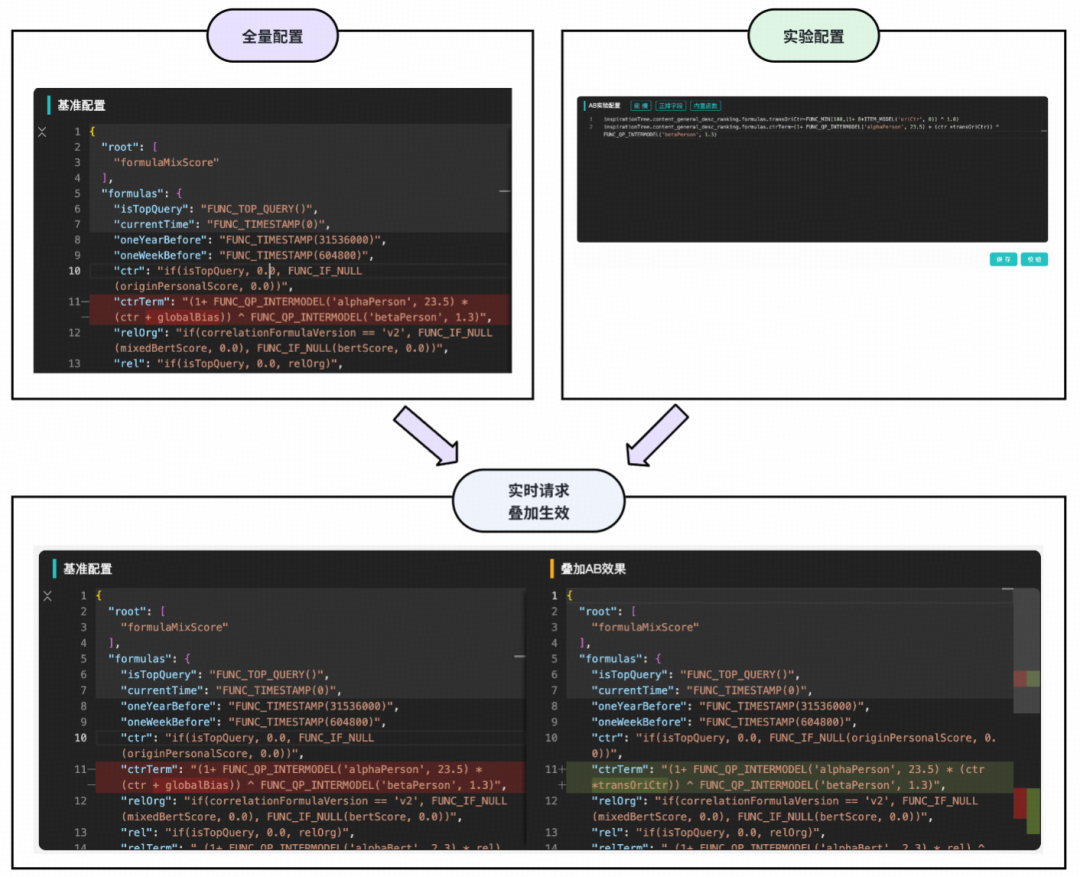
DSL接近数学公式/逻辑表达式明文
社区搜索与推荐的精排融合公式,服务于“多目标融合+业务Boost调权”,其语义涵盖了数学变换、逻辑判断和自定义UDF。当算法工程师写下一串类似 sin(log(max(UDF(x), y))) 的表达式时,框架必须能够稳稳托底,正确校验与执行,杜绝“配错即崩”的情况。
从加乘树1.0到3.0,公式解析的核心一直选用ANTLR。相比于手动编写“逆波兰表达式”解析器或使用Flex & Bison,ANTLR基于AST的校验方式更为可靠,且在Java生态中的开发门槛也更低。在实际的加乘树配置结构中,公式以键值对形式配置(Key为结果名,Value为表达式),并支持跨行引用——前序公式的输出可以作为后序公式的输入,从而形成一条可串联的计算链,直至计算出最终结果。
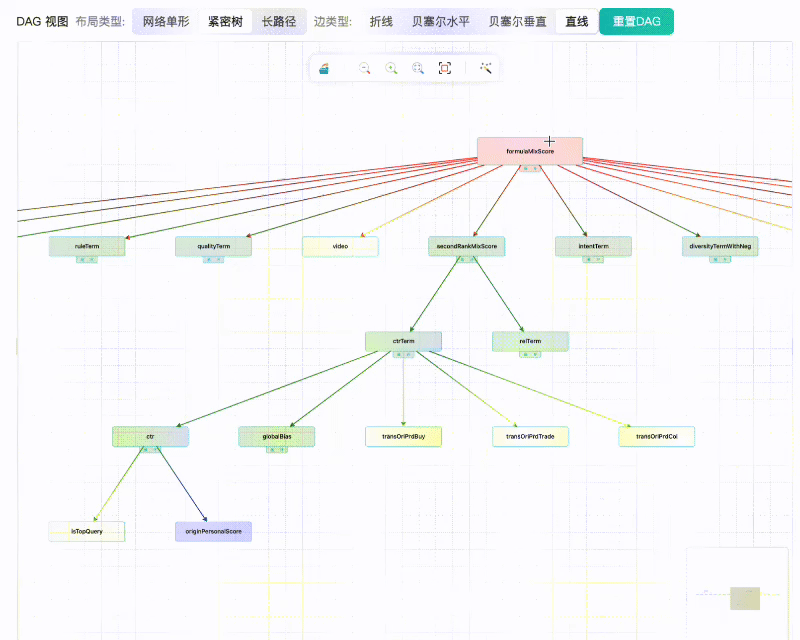
- 公式链转DAG:在加乘树3.0中,存在相互依赖关系的多行公式,会被框架自动解析成有向无环图。每个推荐物品都通过这套DAG计算融合分数,一个物品可能对应多个融合分,每棵DAG的根节点就对应一个融合分。
- AST驱动逐行校验:每一行公式都依托编译原理,被校验并解析为抽象语法树。结构化的AST为后续可靠的计算提供了坚实基础。
- 加乘树3.0把DAG和AST直接翻译成代码:框架将整个公式链直接翻译成可执行的Java代码,并利用字节码技术加载到JVM中。每个物品的计算直接调用生成的硬编码即可,效率极高。

编译校验与降级体系筑牢稳定性防线
“即配即用”为算法迭代提效带来了巨大便利,同时也给工程稳定性维护带来了严峻挑战。尤其是当加乘树需要处理的配置是可自由组合、千变万化的数学公式时,绝对不能出现“配错即崩”的情况。我们为此设计了一整套安全体系:
- 编译原理强校验:如何应对无限组合的公式配置?加乘树选择了编译原理进行强校验,使用ANTLR框架,将公式校验并解析成严谨、可程序化访问的抽象语法树结构。
- DAG强校验公式链:加乘树3.0在初始化阶段会自动解析公式链间的依赖关系,一边将公式链解析成DAG,一边进行强校验。只有能通过校验、最终能编排成合法DAG的公式,才会进入实际计算环节。那些危险的配置(如漏配公式、公式语法错误)都会在初始化阶段就被拦截,不会流入线上计算。
- 自动降级范式:加乘树设计了一套自动降级范式,方便实现“前置拦截错误、事中有效托底、后置发出告警”。一旦有错误的实验开启线上流量,加乘树在初始化阶段就会校验出错误,该次请求会忽略AB实验配置、直接使用全量配置进行计算,并及时发出“实验配置有误”的告警。
- 串行重算托底:如果存在“编译原理校验”和“DAG校验”都未能发现的意外情况怎么办?如果框架仅仅是在业务高峰期计算超时失败了怎么办?加乘树的最后一层安全托底是“用全量配置串行重算”。无论如何,都要保证线上服务的最终效果。
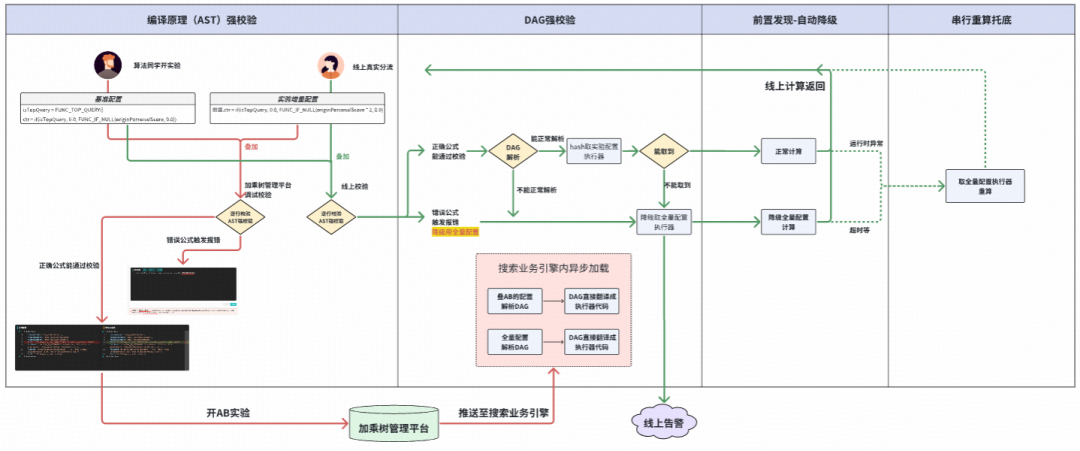
核心攻坚:加乘树3.0升级编译执行
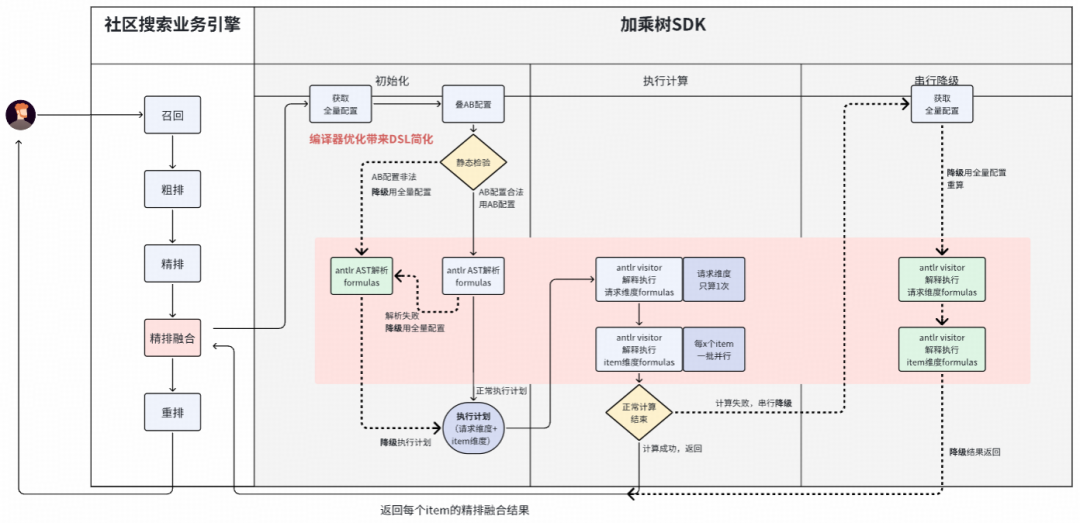
加乘树2.0在社区搜索落地后,在“每次请求处理3000个物品、线程并发度高”的场景下,暴露出消耗CPU和线程资源较多的弱点。同期,C++版本的加乘树替换了计算引擎,没有采用ANTLR Visitor解释执行数学运算的方式,而是使用了exprtk框架,从而获得了更高的性能。
受C++版加乘树的启发,我们计划对Java版加乘树的计算引擎进行升级,目标是降低CPU消耗和平响时间。加乘树3.0由此演进为“直接将配置翻译成代码,通过字节码加载,直接计算”的编译执行形态。
极致性能:配置直译硬代码,零中间损耗 + 最优 JIT
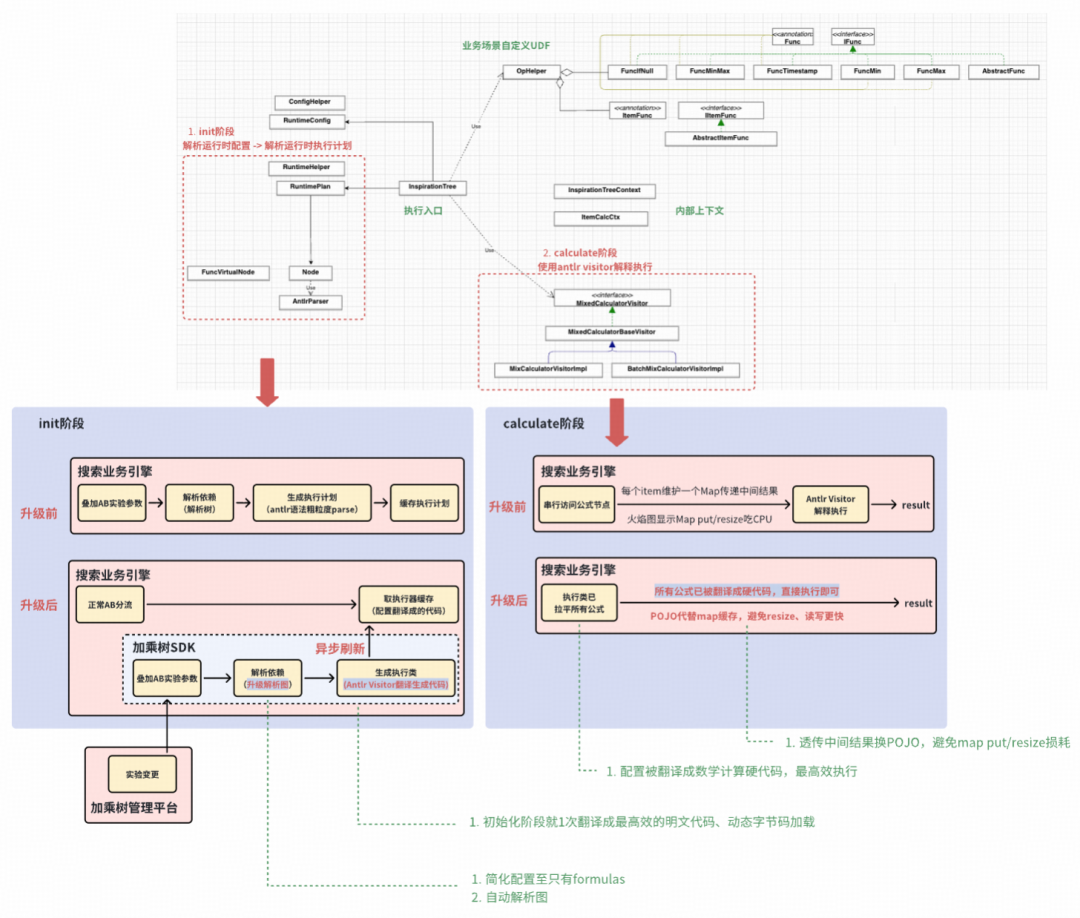
- Antlr翻译 & Javassist加载,直接“公式翻译成可执行代码”:包括多行公式的依赖关系、数学计算及UDF调用在内的所有逻辑,都被直接“拉平”翻译成硬编码。硬编码的执行效率最高,避免了通过Map缓存中间结果、递归调用栈等带来的性能损耗。
- 多行公式传递中间结果,Map换POJO:在旧版本中,每个物品需要维护自己的缓存Map来传递中间结果,高并发下的Map put/resize操作造成了明显的CPU消耗和Young GC压力。在3.0中,我们改为在初始化时决策并缓存POJO对象,避免了Map的resize,并且读写效率更高。
- 核心Javassist管理类借鉴Dubbo写法:Dubbo的ClassGenerator在内存管理方面考虑得非常完善。本次我们借鉴了其设计思路,将动态生成代码的逻辑收拢到唯一的管理单例类中。
性能收益
晚高峰时段的模块平响、CPU火焰图消耗和内存分配火焰图消耗均得到了显著降低。
典型踩坑
- 字节码加载不容忍语法糖:动态生成的字节码必须严格遵循JVM规范,平时在源码中习惯手写的Java语法糖是不被允许的。例如,
Float a = (float) b; 在源码中合法,但如果 b 是 Double 类型,该语句涉及拆箱、窄化转换、装箱等多个步骤,而在字节码层面需要显式插入 doubleValue() → (float) cast → Float.valueOf() 等指令。若直接按表面类型生成字节码,将会触发 VerifyError。
- OOM在多处需要关注:Javassist使用不当容易引发OOM。Javassist在生成和操作字节码时,因其内部的缓存机制,需要开发者主动管理资源释放。每次解析字节码生成的CtClass必须及时释放,否则高频生成字节码极易触发OOM。在这一点上,加乘树参照了Dubbo的ClassGenerator写法,将类的创建与销毁内聚在同一个管理类中,做到即用即释放。

动态生成的ClassLoader、Class、Instance要能正常被GC回收:Instance能被GC,ClassLoader和Class呢?答案是肯定的,只有从ClassLoader -> Class -> Instance全链路的对象都GC Root不可达时,这一整串对象才能被回收。因此,使用Spring的常驻ClassLoader来加载动态生成的类是不可行的,必须使用即用即弃的自定义ClassLoader,并注意避免全链路中出现不必要的强引用。
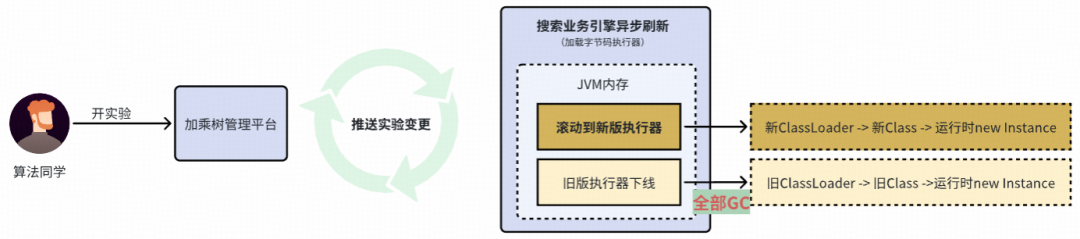
我们通过实际测试验证了动态生成的类确实能够被JVM正常垃圾回收。
多重护航:防止非法Java字节码引发线上问题
- ASM + Javassist双重检验:翻译生成的代码,经由Javassist生成字节码后,除了Javassist
.toClass() 方法自身的检验外,我们还让字节码通过了ASM的字节码静态校验器(该校验器会运行类似JVM的类型推断验证,确保每条指令执行前后,局部变量表和操作数栈的状态是类型安全的)。
- 沙箱加载:我们将加乘树管理平台封装成了一个沙箱环境。算法工程师在调试公式时点击“校验”按钮,平台会使用同一套SDK模拟线上全套加载流程:“AST强校验 -> DAG强校验 -> 真实翻译代码 -> Javassist & ASM 双校验 -> 反射调用构造器创建实例”。只有这一整套流程全部无误后,配置才会被推送到线上。
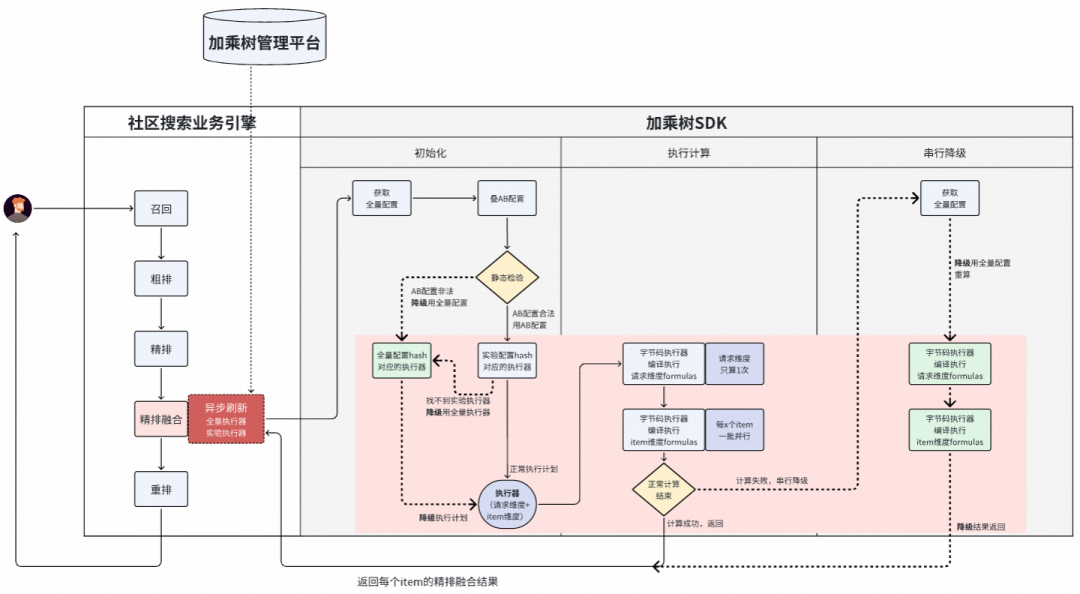
- 线上异步加载,任何问题自动降级:“可执行代码(执行器)初始化”过程实现了读写分离,新配置上线采用异步刷新机制。即使刷新过程出错,也只会导致线上流量过来时找不到对应的新执行器,此时系统会自动降级使用全量配置的执行器(并发出告警),而不会影响线上服务的效果。
- 可回退解释执行:加乘树2.0和1.0的解释执行能力十分稳定,只是性能略差。3.0版本保留了一键回退至解释执行模式的能力,作为终极保障。
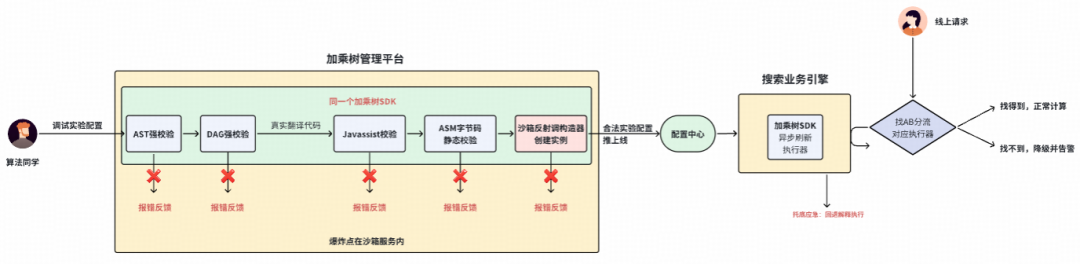
加乘树管理平台:一站式配置、调试与实验平台
- 面向算法同学:打造了一套一站式的“辅助配置 -> 校验 -> 实时调试 -> 开实验 -> 变更管控”使用体验,告别繁琐的配置流程,操作体感更丝滑。
- 面向系统稳定:如上文所述,加乘树管理平台将自己封装成了一个沙箱,将所有潜在风险都拦截在沙箱内部。
稳扎稳打:从1.0到3.0的演进
加乘树1.0的目标是支持配置公式、框架直接计算公式,支持UDF,采用解释执行。加乘树2.0进行了少量性能优化,并将其抽象成通用SDK。加乘树3.0则升级为编译执行,对外部使用者而言,配置更加简化,只需要配置公式,框架会自动解析依赖生成DAG。
加乘树1.0和2.0都采用解释执行,即通过ANTLR Visitor遍历AST进行“数学/逻辑/if判断”运算。加乘树3.0升级为编译执行,在解析多行公式形成DAG、以及用ANTLR解析每行公式AST的同时,直接将其翻译成Java执行代码,再利用字节码技术将执行代码加载进JVM直接运行。同时,加乘树3.0也保留了降级至解释执行的能力。
加乘树1.0
- 解决的问题:落地了“即配即用”公式框架,解决了手写硬代码迭代效率低、以及代码腐化导致线上生效逻辑不清晰的问题。
- 存在的缺陷:消耗线程和CPU资源较多。
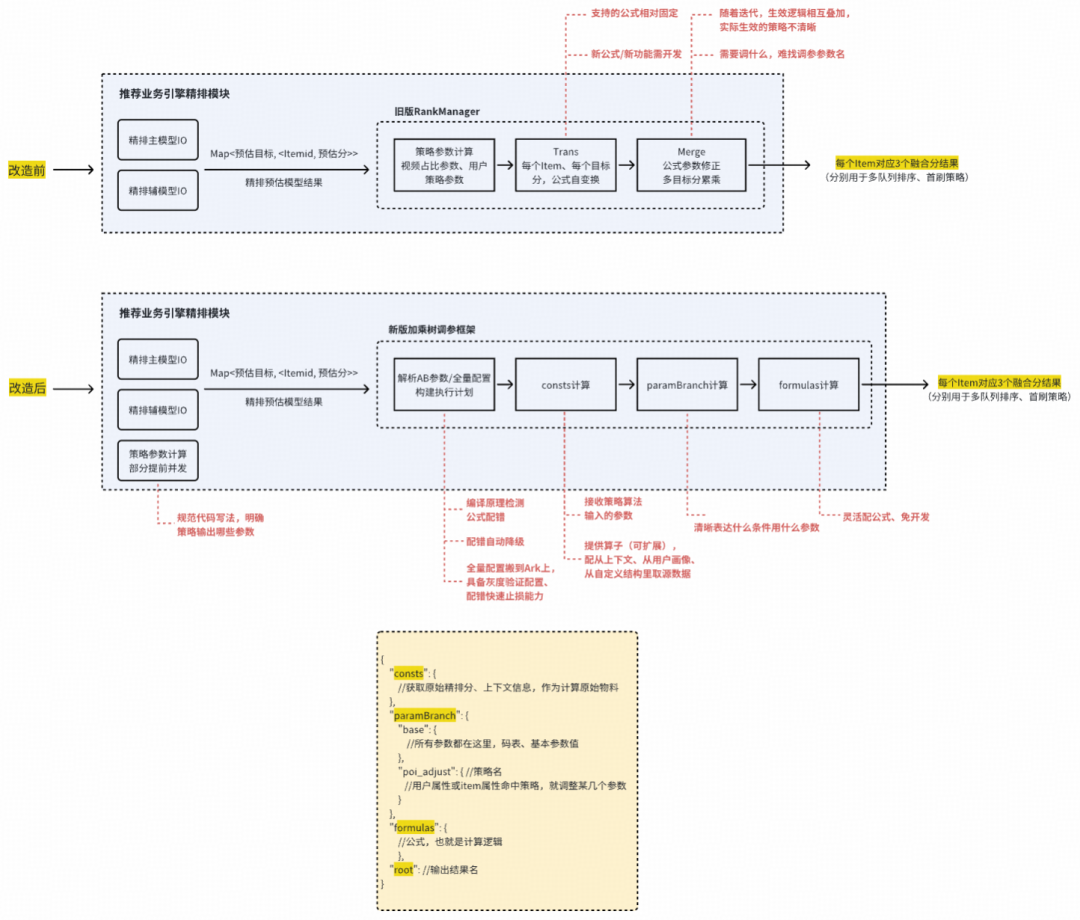
加乘树1.0于2025年1月在社区推荐外流精排场景落地,其配置方法(使用外观)和降级机制在后续迭代中保持稳定:
- 配置方法:1)“全量配置+叠加实验改动”的配置机制;2)配置结构分为consts(输入物料)、paramBranch(条件分支替换参数)、formulas(公式)、root(融合结果字段名)。
- 降级机制:1)初始化阶段即检测公式配错、漏配等问题,一旦检出就自动降级使用全量配置,并发出告警;2)针对少量运行时才能发现的问题,采用串行重算、降级计算全量配置的方式托底。
当时是从手写硬代码做公式融合,且无DIFF对比能力迁移而来,它解决了以下两个迭代痛点:
- 迭代效率:除调参可配外,调整公式形态、生效条件等都需要开发介入并上线。
- 逻辑黑盒:Boost、融合公式迭代复杂后,线上生效逻辑变得不透明,难以分析调参方向。
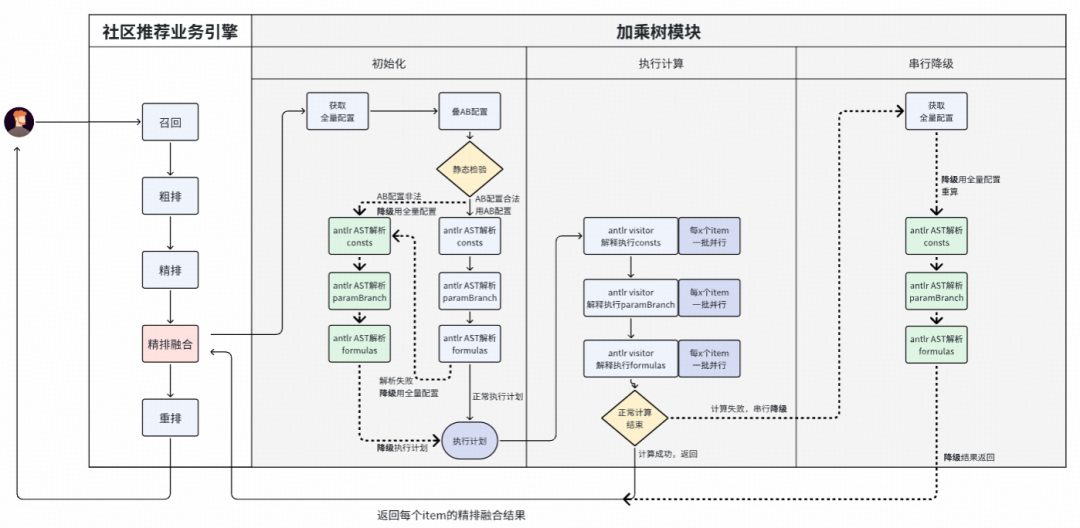
加乘树1.0的实现要点
纯物品维度计算(请求维度的公式也会在每个物品上重复计算)。计算流程为consts -> paramBranch -> formulas串行执行。使用ANTLR解析单行公式为AST,框架递归解析树依赖,最后通过ANTLR Visitor解释执行。
为什么选用ANTLR?
- DSL语法校验:我们需要一种配置设计,能够尽可能简洁地表征模型融合公式(支持逻辑判断/复杂数学变换/UDF)——一种接近Java语法和数学公式的DSL(当时对标了业界同类产品的配置外观)。我们需要准确校验DSL配置的正确性,并正确解析它。在ANTLR、手写逆波兰表达式解析器、Flex&Bison等方案中,我们选择了ANTLR来校验和解析DSL(因其基于AST的校验原理可靠,且Java生态上手难度低)。
- ANTLR Visitor解释执行:基于AST解析进行计算是一种可靠的计算逻辑。我们需要一个稳定可靠的计算引擎,因为一旦算法同学大规模使用,会出现大量千变万化的公式组合——依赖AST进行解析和计算提供了这种可靠性。
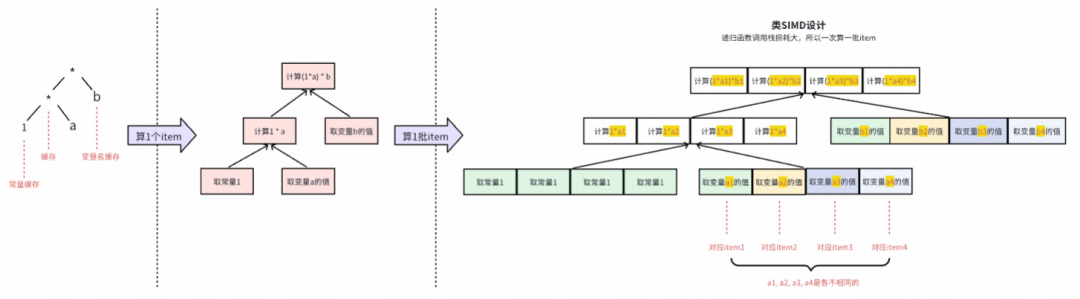
- 类SIMD设计使性能可接受:ANTLR解析AST本身比较耗时,必须做到一次解析、多次复用,不能在物品维度重复解析。通常,使用ANTLR Visitor做线上实时计算,性能是不可接受的。我们采用了一种类SIMD的代码写法,使得落地性能达到可接受范围——这种类SIMD的设计,让一次ANTLR Visitor计算一批物品。最终落地的性能,并未因为ANTLR Visitor而拖累太多,甚至比旧版手写硬代码的融合公式性能还要好。
加乘树2.0
- 解决的问题:抽象成通用SDK;执行计划能自动识别请求维度公式,方便序融合等逻辑编写UDF。
- 存在的缺陷:受限于解释执行的模式,仍然比较消耗线程资源。
加乘树2.0于2025年9月在社区搜索场景落地。主要优化点如下:
- 使用体验:配置的JSON结构得到简化,只需要配置递归的一组公式即可(移除了consts、paramBranch层级)。
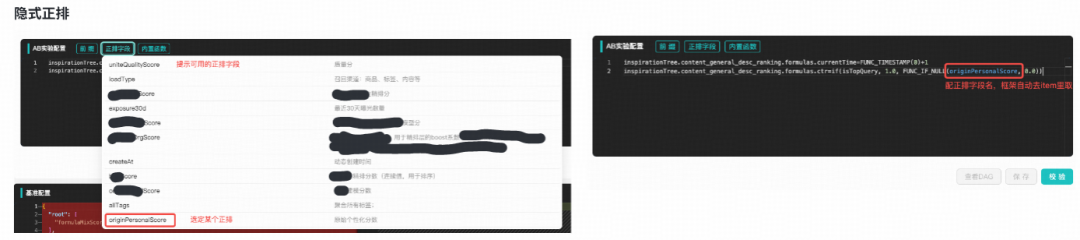
if() 条件的配置写法得到简化:旧版编译器设计简单,将“逻辑表达式”与“数学表达式”分别放在两个编译器里,使用者不允许在if里嵌套函数;加乘树2.0合并了编译器,允许在 if() 里嵌套函数调用。支持“隐式物品正排”特性。
* **性能**:框架能自动识别请求维度的公式,并保证全局只计算一次。执行计划加入缓存,砍掉了“每次请求都重新构建执行计划”的开销,降低了平响时间。
* **横向扩展**:Java版加乘树被抽象为独立的SDK,方便其他场景直接引用集成。
加乘树3.0
- 解决的问题:升级为编译执行,性能得到大幅提升。
加乘树3.0于2026年1月在社区搜索场景落地。正如前面“核心攻坚”模块所述,在高并发、计算量大的情况下,加乘树2.0暴露出消耗CPU和线程资源的弱点(尽管类SIMD设计让性能可接受,但ANTLR Visitor的计算方式仍有升级空间)。
加乘树3.0替换了执行引擎。我们通过观察性能火焰图发现,“按照公式逻辑直接手写的Java代码”执行效率最高,但迭代效率最低。加乘树为了追求“即配即用”的迭代效率,却在性能上做出了牺牲。为了平衡“即配即用”的迭代效率与“极致性能”,我们采取了“将配置公式直接翻译成可执行代码,用字节码技术加载到JVM中直接计算”的策略,这使得加乘树从解释执行升级为编译执行。
还能更好
- 多语言 & 模块化:加乘树目前拥有Java版,同时引擎同学也创新实现了高性能的C++版本。它支持多种业务场景及模块(如粗排、精排),可灵活接入Java业务引擎或C++高性能引擎。我们欢迎其他业务场景和技术模块接入使用。
- 稳定性 & 产品化:未来将重点打磨“加乘树管理平台沙箱拦截 -> 线上容错降级 -> 失败监控告警发现 -> 解释执行托底”这一链条的有效性,并定期进行降级演练和算法效果验证。增强“加乘树管理平台”的DIFF对比能力,扩展展示“调试DAG”、“对比动态生成的代码”等功能,打通实时Debug平台,实现“展开DAG查看计算的中间结果”。
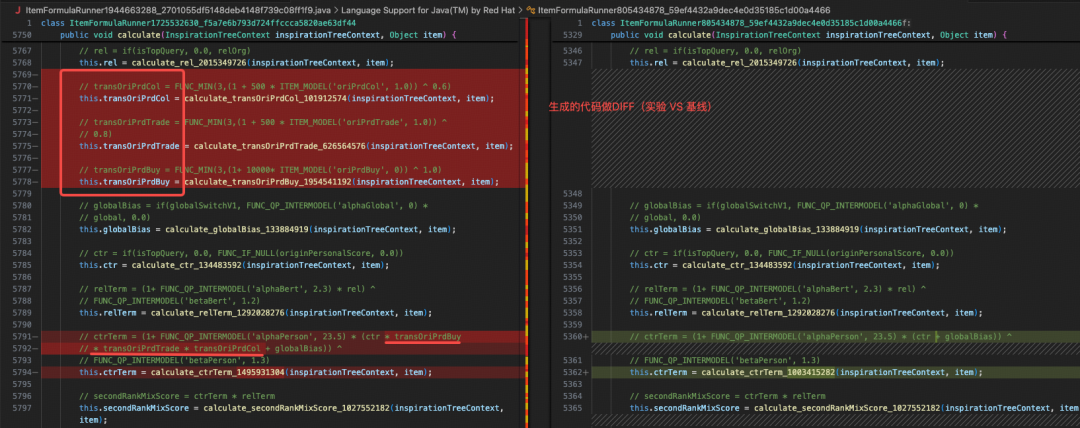
- 打通模型调用自动化:未来计划在加乘树框架内打通精排模型调用流程,对精排模型的调用也进行高度抽象,做到“一配即用、一配即可加入公式融合”,进一步提升算法工程的全链路效率。
如果你对构建此类高性能、高可用的分布式系统架构有更多兴趣或想法,欢迎在技术社区进行深入交流与探讨。
 发表于 2026-3-5 05:19:49
|
查看: 240|
回复: 0
发表于 2026-3-5 05:19:49
|
查看: 240|
回复: 0
