准确预测股票走势对于金融机构和市场参与者至关重要,但传统的分析方法往往存在局限。基本面分析虽然整合了新闻、网络关系等外部数据,却难以捕捉股票之间瞬息万变的互动模式,且预设的静态关系图在高度波动的市场中经常“失灵”。技术分析方法则各有短板:有的孤立看待个股,有的仅能建模两两配对关系,还有的依赖于固定的图结构,都无法灵活地反映市场行为的动态演变。
为了突破这些限制,韩国汉阳大学和首尔国立大学的研究团队提出了一种名为 DYCOR 的新框架。它旨在动态地捕捉股票间演变、复杂的潜在关系,从而显著提升预测准确性。实验表明,DYCOR 在多个关键指标上大幅优于现有基线方法。
现有方法的局限性
静态关系假设的不足
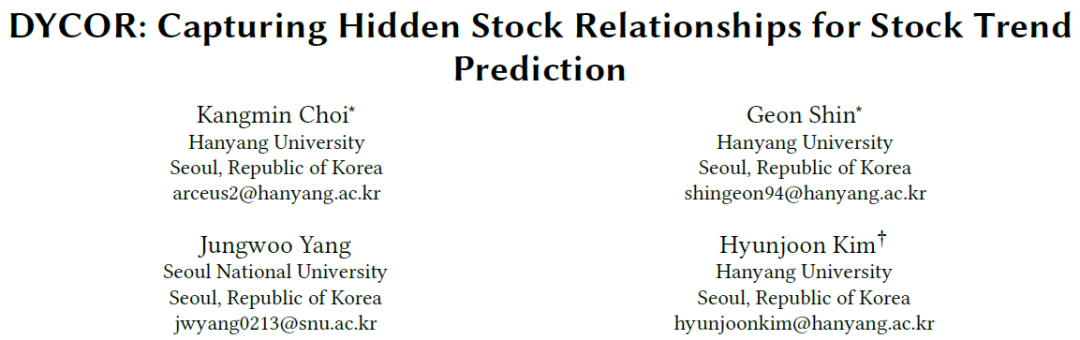
依赖预定义行业分类或固定关系图的方法,无法适应股票关联性的动态变化。下图清晰地展示了这一局限:在相同行业内,股票走势可能大相径庭(图a);而分属不同行业的股票,其价格却可能表现出高度的同步性(图b)。这说明静态的关系建模会遗漏大量重要的跨市场联动信号。
传统损失函数的缺陷
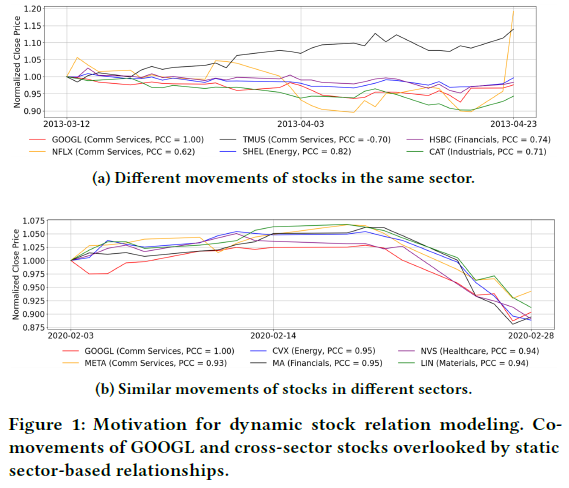
常用的均方误差(MSE)损失和成对排名损失也存在问题。如下图所示,MSE 可能通过预测接近零的值来最小化误差,而忽略了股票间的相对排名;排名损失则在预测与真实值的差异方向一致时,无法有效惩罚幅度上的不匹配,可能导致模型评估失真。
DYCOR 框架详解
DYCOR 的整体目标,是学习一个函数 $f_θ$,根据所有股票截至时间 $t$ 的历史特征矩阵 ${X_s}_{s∈S}$,来预测它们下一时间段的收益率 ${r_{s,t}}_{s∈S}$。其中,单只股票 $s$ 在 $t$ 时刻的收益率 $r_{s,t}$ 定义为:
$r_{s,t} = (c_{s,t} - c_{s,t-1}) / c_{s,t-1}$
$c_{s,t}$ 为其收盘价。
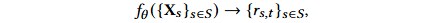
其核心架构包含五个阶段,如下图所示:
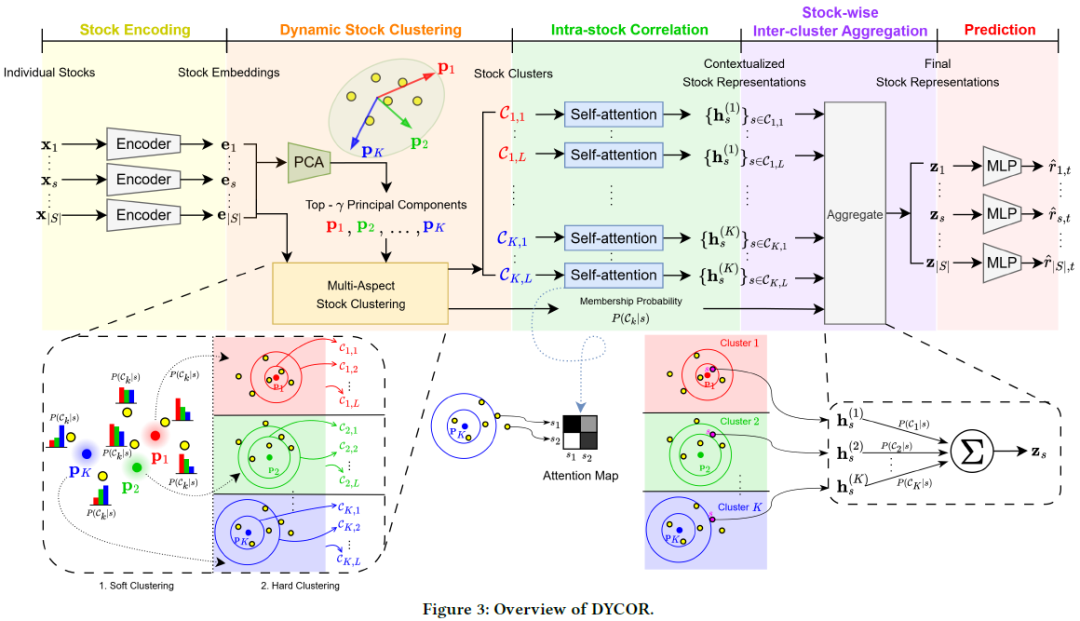
1. 股票编码
编码器将每只股票的特征矩阵 $X_s$ 转换为一个低维嵌入 $e_s$。这一过程通过三个步骤精炼特征:
- 趋势分解:将原始序列分解为趋势成分 $X_s^{tr}$ 和波动成分 $X_s^{fl}$,再进行线性投影。
X_s^tr = AvgPool1d(X_s), X_s^fl = X_s - X_s^tr
(1)
X'_s = (W_1 X_s^{tr} + b_1) + (W_2 X_s^{fl} + b_2)
(2)
- 时间混合:在特征的不同时间步之间交换信息,生成蕴含历史上下文的时间表示。
X̂_s = [x̂_s,t-T, x̂_s,t-T+1, ..., x̂_s,t-1] = TimeMixing(X'_s)
(3)
- 指标混合:在技术指标之间交换信息,最后通过MLP聚合,生成最终的股票嵌入 $e_s$。
IndicatorMixing(Ẋ_s) = Ẋ_s + W_4σ(W_3LayerNorm(Ẋ_s))
(5)
X̄_s^(j) = IndicatorMixing(TimeMixing(Conv1d_j(X_s')))
(6)
e_s = MLP([X_s^(T/2), X_s^(T)])
(7)
2. 动态股票聚类
为了捕捉超越传统行业分类的动态关联,DYCOR采用数据驱动的方式进行聚类。
- 潜在分段表示:对股票嵌入 ${e_s}$ 应用主成分分析(PCA),选取累积解释方差比超过阈值 $\gamma$ 的 top-K 主成分 ${p_k}$,每个主成分代表市场的一个潜在“方面”或“因子”。
$\frac{\sum_{i=1}^{K} \lambda_i}{\sum_{i=1}^{|S|} \lambda_i} \geq \gamma$
(8)
- 多角度聚类:
- 软聚类:计算每只股票属于每个潜在分段 $k$ 的成员概率 $P(C_k|s)$,使用带温度参数 $\tau$ 的softmax。
$P(C_k|s) = \frac{\exp(\text{sim}(e_s, p_k)/\tau)}{\sum_{k'=1}^{K} \exp(\text{sim}(e_s, p_{k'})/\tau)}$
(9)
- 硬聚类(子聚类):在每个分段 $k$ 内,根据成员概率将股票进一步划分为 $L$ 个子分段 $C_{k,l}$,以捕捉更细微的差异。
3. 股票内相关性建模
对于每个子分段 $C_{k,l}$ 内的股票,使用自注意力机制来建模它们之间的相互依赖关系,为每只股票生成一个上下文感知的表示 $h_s^{(k)}$。
Q = E_k,l W_Q, K = E_k,l W_K, V = E_k,l W_V
(10)
H_k,l = \text{softmax}(\frac{QK^T}{\sqrt{d}})V
(11)
4. 股票间跨簇聚合
一只股票(例如一家半导体公司)可能同时受到多个细分市场(如同行业、客户行业)的影响。此阶段将股票从各个角度(簇)得到的表示 $h_s^{(k)}$,按其成员概率 $P(C_k|s)$ 加权聚合,形成股票的最终综合表示 $z_s$。
$z_s = \sum_{k=1}^{K} P(C_k|s) \cdot h_s^{(k)}$
(12)
5. 预测与相关性感知训练
最终,通过一个简单的MLP从 $z_s$ 预测收益率 $\hat{r}_{s,t}$。
$\hat{r}_{s,t} = W_6 \cdot \sigma(\text{LayerNorm}(W_5 \cdot z_s + b_5)) + b_6$
(13)
DYCOR采用一种新颖的相关性感知损失进行训练,解决了传统MSE和排名损失的不足。总损失 $\mathcal{L}$ 是稳健的Huber回归损失 $\mathcal{L}_{reg}$ 和相关性损失 $\mathcal{L}_{corr}$ 的加权和:
$\mathcal{L} = (1 - \lambda_{corr}) \cdot \mathcal{L}_{reg} + \lambda_{corr} \cdot \mathcal{L}_{corr}$
(14)
其中,$\mathcal{L}_{corr} = 1 - \text{corr}({\hat{r}_{s,t}}_{s \in S}, {r_{s,t}}_{s \in S})$,旨在最大化预测值与真实值之间的皮尔逊相关系数(PCC)。PCC的计算考虑了全市场股票在当天的整体分布:
$\text{corr}({\hat{r}_{s,t}}_{s \in S}, {r_{s,t}}_{s \in S}) = \frac{\sum_{s \in S}(\hat{r}_{s,t} - \hat{\mu}_t)(r_{s,t} - \mu_t)}{\hat{\sigma}_t \cdot \sigma_t}$
(16)
这种方法迫使模型不仅关注预测的方向,还要关注其相对幅度与整个市场趋势的一致性。
实验评估
设置
- 数据集:使用 NASDAQ, NYSE 和 S&P 500 三个真实美股数据集进行评估。
- 评估指标:信息系数(IC)、Rank IC、ICIR、Rank ICIR、Recall@n、NDCG@n。
- 基线:对比了 LSTM, Transformer, TimeMixer 等通用序列模型,以及 RSR, DTML, STHAN-SR, StockMixer 等专门的股票预测模型。
主要结果
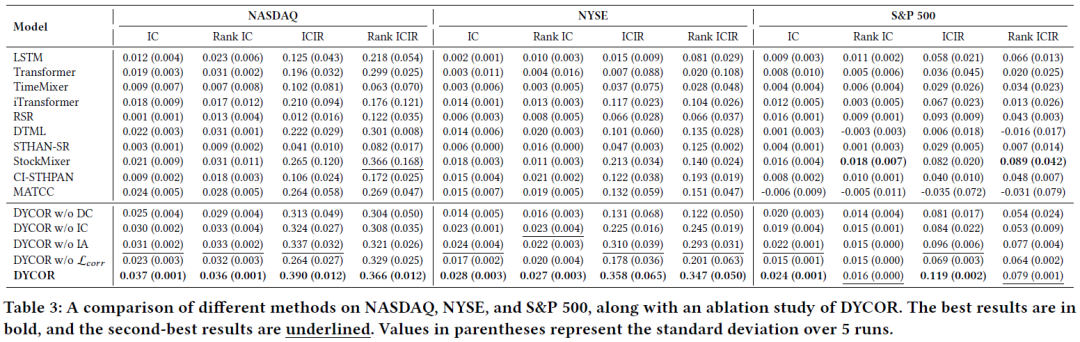
DYCOR在大多数指标上全面领先。如下表所示,在NASDAQ上,其IC比次优方法MATCC提升约54%,Rank IC比DTML提升16%;在NYSE上,IC和ICIR较StockMixer分别提升约56%和68%;在S&P 500上,IC和ICIR也表现最佳。
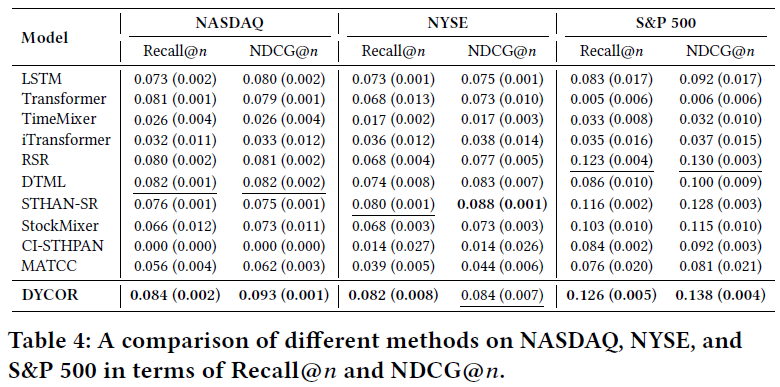
在基于排名的检索指标(Recall@n, NDCG@n)上,DYCOR同样展现出优势,尤其在识别顶部股票方面表现突出。
消融分析与讨论
- 组件重要性:移除动态聚类(w/o DC)导致性能大幅下降,尤其在股票数量多的NYSE上;移除相关性感知损失(w/o L_corr)也会造成持续的性能损失,证实了这些设计的有效性。
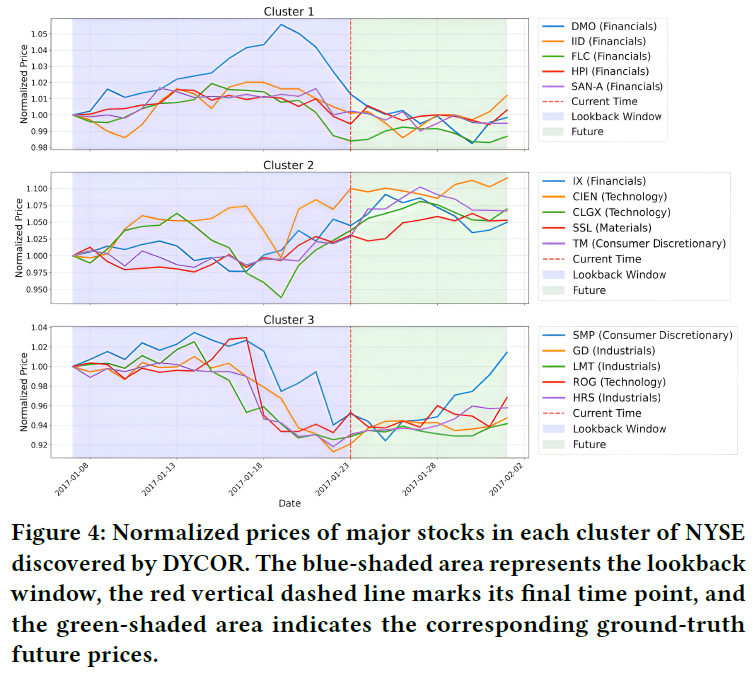
- 聚类效果可视化:下图展示了DYCOR在NYSE上发现的三个簇。可以看到,同一簇内的股票价格走势高度相似,而这些股票往往来自不同行业,证明了模型能够发现超越传统行业分类的隐藏关联(例如潜在的供应链或业务联系)。

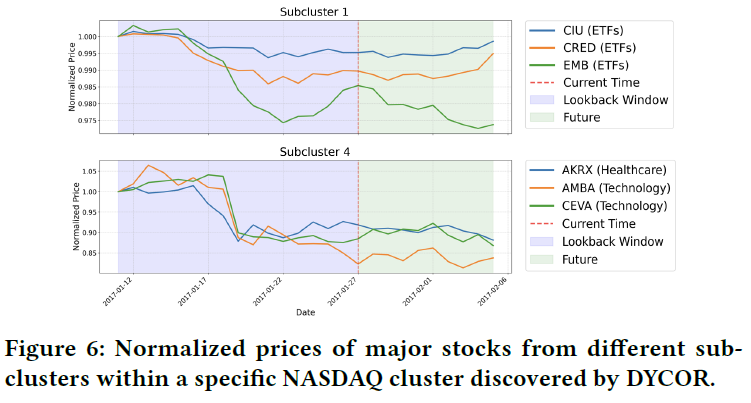
- 子聚类分析:同一主簇下的不同子聚类,能捕捉到股票间更精细的走势差异。
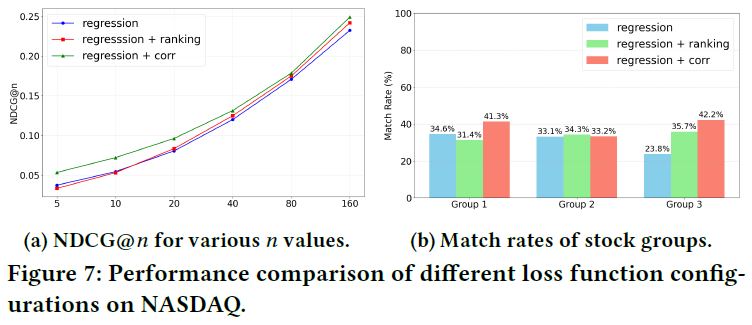
- 损失函数对比:实验表明,结合相关性感知损失的DYCOR,在NDCG指标上优于仅使用回归损失或“回归+排名”损失的变体,验证了新损失函数在捕捉股票回报相对幅度方面的优势。
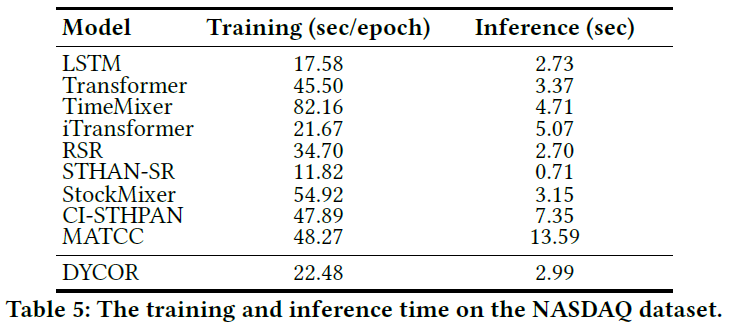
- 效率:DYCOR在训练和推理时间上都具有竞争力,其推理速度与LSTM等轻量模型相当,远快于一些复杂的图模型。
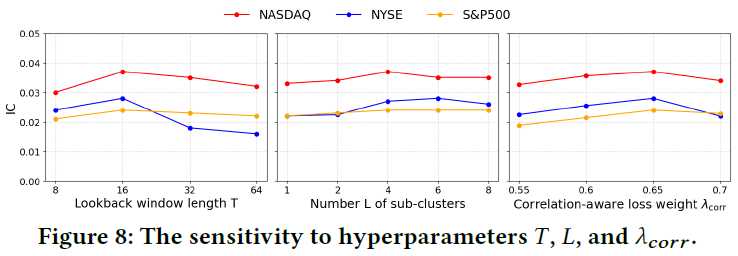
- 超参数敏感性:实验确定了关键超参数的经验最优值:回溯窗口 $T=16$,子簇数 $L$ 在 NASDAQ/S&P 500 上为4,在 NYSE 上为6,相关性损失权重 $\lambda_{corr}=0.65$。
总结
DYCOR框架通过动态股票聚类自适应地发现市场中的隐藏关联,并利用相关性感知损失确保预测与整体市场趋势在方向和幅度上保持一致,有效解决了现有股票趋势预测模型的两大痛点。在三个真实数据集上的大量实验证明了其卓越的性能和实用性。这项工作为 Data Science 和 Deep Learning 在金融预测领域的应用提供了一个强有力的新工具。未来研究方向可能包括扩展至多步预测以及在实盘交易环境中的进一步验证。
对这类结合前沿人工智能技术与金融分析的课题感兴趣?欢迎在云栈社区与其他开发者和研究者交流探讨。
 发表于 2026-3-6 02:49:27
|
查看: 243|
回复: 0
发表于 2026-3-6 02:49:27
|
查看: 243|
回复: 0
