前言
分页是后端开发中最常见的功能之一,但你是否想过我们为什么要分页?
- 从业务上看,即便系统有能力返回全部数据,用户也极少会翻看几十页之后的内容。
- 从技术上看,我们需要考虑数据获取的综合成本:服务端的磁盘I/O、内存消耗、网络带宽,以及请求方自身能否承受海量数据的传输与处理。
MySQL的分页基础语法:
select * from table limit 0, 20
那么,使用LIMIT进行分页,真的能有效降低上面提到的技术成本吗?当数据量变大,尤其是进行深度分页时,事情可能就没那么简单了。
环境准备:建表与数据初始化
为了清晰地演示问题,我们先创建一张测试表并初始化大量数据。
CREATE TABLE t1 (
id BIGINT NOT NULL AUTO_INCREMENT COMMENT '主键',
m_id BIGINT NOT NULL COMMENT '其他id',
`name` VARCHAR ( 255 ) COMMENT '用户名称',
identity_no VARCHAR ( 30 ) COMMENT '身份证号',
address VARCHAR ( 255 ) COMMENT '地址',
create_time TIMESTAMP NOT NULL COMMENT '添加时间',
modify_time TIMESTAMP NOT NULL COMMENT '修改时间',
PRIMARY KEY `id` ( `id` )
) ENGINE INNODB DEFAULT CHARSET = 'utf8' COMMENT '深分页测试表';
-- 先初始化一条数据
INSERT INTO t1
VALUES
( 1, 1, '这里是随机中英文的名字—1', '100000000000000000', '这里是随机中英文的地址—1', '2010-01-01 00:00:00', '2010-01-01 00:00:00' );
-- 通过递归插入快速生成大量数据
set @i=1;
insert into t1(m_id, name, identity_no, address, create_time, modify_time)
select @i:=@i+1 as m_id,
concat('这里是随机中英文的名字—',@i),
100000000000000000+@i,
concat('这里是随机中英文的地址—',@i),
date_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND),
date_add(date_add(create_time,interval +@i*cast(rand()*100 as signed) SECOND), interval + cast(rand()*1000000 as signed) SECOND)
from t1;
-- 注:该数据生成方法来源于网络
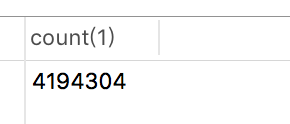
执行多次上述插入语句后,我们得到了一个拥有超过400万行数据的表。
场景分析与优化实践
场景一:无查询条件,无排序
首先,我们执行一个最简单的深分页查询,从第100万条开始取20条。
select id,m_id, name, identity_no, address, create_time, modify_time
from t1 limit 1000000, 20;
耗时:0.613 秒
然后,我们为主键id加上一个ORDER BY。
select id,m_id, name, identity_no, address, create_time, modify_time
from t1 order by id limit 1000000, 20;
耗时:0.417 秒
性能对比与原因分析
查看两者的执行计划:
- 无排序的执行计划显示为全表扫描 (
type: ALL)。

- 带主键排序的执行计划使用了主键索引 (
type: index),并且只读取了需要的前N条数据。

结论一:即使业务上没有明确的排序需求,也建议加上ORDER BY 主键。 这能保证结果稳定,并可能利用索引提升性能。
延伸思考:如果不指定ORDER BY,MySQL默认按什么顺序返回?通常被认为是主键顺序,但这涉及物理存储顺序与逻辑顺序的差异。在某些情况下(如删除后复用ID),顺序可能不一致。可以通过OPTIMIZE TABLE table_name命令来优化表的存储。
场景二:带排序,但排序字段无索引
现在,我们按create_time字段倒序排列,取第1万条开始的20条数据。
select id,m_id, name, identity_no, address, create_time, modify_time
from t1
order by create_time desc
limit 10000, 20;
耗时:2.015 秒
为了对比,我们创建表t2(直接从t1复制数据),并为create_time字段添加索引。
CREATE INDEX idx_create_time ON t2(create_time);
在t2上执行相同的查询:
select id,m_id, name, identity_no, address, create_time, modify_time
from t2
order by create_time desc
limit 10000, 20;
耗时:0.937 秒
性能对比与原因分析
执行计划差异明显:
- 无索引的表
t1进行了全表扫描,并在内存/磁盘上进行了文件排序 (Using filesort)。

- 有索引的表
t2直接通过索引树取得排序后的前N条数据,避免了全表扫描和filesort。

结论二:为常用的排序字段创建索引是优化分页性能的基础手段。
新的问题随之而来:
- 排序字段有索引就一定快吗?如果分页深度达到100万呢?
- 如果表中已有多个索引,不适合再添加新索引了怎么办?
场景三:排序字段有索引,但进行深度分页(100万开始)
在拥有索引的t2表上,执行深度分页查询。
select id,m_id, name, identity_no, address, create_time, modify_time
from t2
order by create_time desc
limit 1000000, 20;
耗时:18.350 秒 (性能急剧下降!)

原因分析: 执行计划显示,这次并没有走我们创建的idx_create_time索引,而是选择了全表扫描。这是因为MySQL的优化器发现,当需要扫描的数据行数超过总行数的一定比例(通常认为是30%左右,但并非绝对)时,它会认为走索引再回表取数据的成本高于直接全表扫描,因而放弃了索引。
场景四:强制使用索引
我们可以使用FORCE INDEX提示来强制MySQL使用我们指定的索引。
select id,m_id, name, identity_no, address, create_time, modify_time
from t2
force index(idx_create_time)
order by create_time desc
limit 1000000, 20;
耗时:15.197 秒
强制索引后的执行计划确实走了索引:

然而,性能提升并不明显。这是因为,即使走了索引,MySQL也需要沿着索引树定位到第100万条记录的位置,然后向后读取20条。这个过程需要遍历大量的索引节点,并进行20次回表操作来获取完整行数据,随机I/O开销巨大。
结论三:即使排序字段有索引,深度分页(如LIMIT 1000000, 20)的性能瓶颈依然存在,需要寻找更优方案。
方案五:使用游标式分页(last_*条件)
这种方法不依赖OFFSET,而是记录上一页最后一条记录的标识(如id和create_time),以此作为下一页的查询条件。
select id,m_id, name, identity_no, address, create_time, modify_time
from t2
where id > #{last_id} and create_time > #{last_create_time}
order by create_time desc
limit 20;
性能: 与正常的浅分页无异,非常高效。
局限性: 该方案受使用场景限制,无法支持跳页(如直接从第1页跳到第50页)或多排序字段复杂排序。它适用于无限滚动加载、只有“上一页/下一页”按钮的应用。
方案六:联表子查询(推荐方案)
这是解决深度分页问题的经典高效方案。其核心思想是将查询拆分为两步:子查询仅通过索引获取满足条件的主键ID,然后通过主键关联回原表获取这些ID对应的完整数据。
1. 优化有索引的表(t2)
将场景四中的强制索引查询改写为子查询形式:
-- 原慢查询
select id,m_id, name, identity_no, address, create_time, modify_time
from t2 force index(idx_create_time) order by create_time desc limit 1000000, 20;
-- 改为联表子查询
SELECT
id, m_id, NAME, identity_no, address, create_time, modify_time
FROM t2
JOIN ( SELECT id FROM t2 ORDER BY create_time desc LIMIT 1000000, 20 ) x USING ( id );
耗时:0.742 秒 (原查询15+秒)
2. 优化无索引的表(t1)
在没有create_time索引的t1表上尝试该方案:
SELECT
id, m_id, NAME, identity_no, address, create_time, modify_time
FROM t1
JOIN ( SELECT id FROM t1 ORDER BY create_time desc LIMIT 1000000, 20 ) x USING ( id );
耗时:2.866 秒 (原查询18+秒)
为何子查询如此高效?—— 执行计划深度解读
我们对比三种情况的执行计划:
- 直接查询(无强制索引):全表扫描 + 文件排序。

- 直接查询(强制索引):索引扫描 + 回表。

- 联表子查询:子查询部分
Using index,主查询部分通过主键关联。

关键区别在于 Using index。这表示子查询可以仅通过索引就获取到所需字段(这里只需要id),无需回表。对于无索引的表,虽然子查询也要做filesort,但它排序的数据量小得多(只有id和排序字段),极大地减少了临时文件I/O和内存消耗。
理解MySQL的排序策略:单路 vs 双路
当执行计划出现Using filesort时,MySQL有两种排序策略:
- 单路排序:一次性取出所有查询字段放入
sort_buffer,排序后直接返回。适用于查询字段总长度较小的情况。
- 双路排序:仅取出排序字段和行定位器(如主键
id)放入sort_buffer,排序后根据定位器回表取所需数据。
联表子查询本质上模拟了“双路排序”的优化思想。子查询只取id(和排序字段),这比直接查询取所有字段的数据量小了几个数量级,从而大幅减少了排序缓冲区的占用、临时文件的读写以及随之而来的I/O开销。这就是它性能卓越的根本原因。
补充优化:调整sort_buffer_size
适当增加sort_buffer_size系统变量,可以让更多的排序在内存中完成,减少磁盘临时文件的使用。虽然这通常作为辅助手段,但在特定场景下也能带来一定提升。
-- 查看当前配置
SHOW VARIABLES LIKE '%sort_buffer_size%';
-- 在会话或全局级别进行调整 (需根据服务器内存情况谨慎设置)
SET sort_buffer_size = 33554432; -- 例如设置为32M
总结与最佳实践
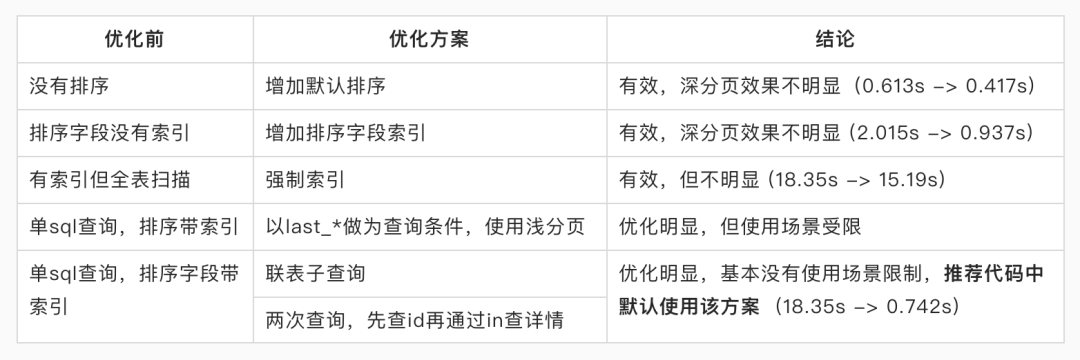
各方案效果对比
下表总结了不同场景下的优化方案及效果:
业务层建议
- 限制跳页深度:参考搜索引擎的做法,限制用户只能跳转到当前页前后的若干页(如前后10页),避免产生过深的
OFFSET。
- 推广游标分页:在无限滚动、瀑布流或仅支持“上/下一页”的场景中,优先使用
last_*游标分页方案。
技术层建议
- 规范SQL:即使业务无要求,分页查询也应加上
ORDER BY 主键,保证结果稳定并可预测。
- 索引是基石:为高频的排序字段和筛选条件创建合适的索引。
- 深度分页用子查询:当分页深度达到一定阈值时,应优先考虑使用联表子查询方案。这是兼顾性能与通用性的最佳选择。
- 辅助调优:可根据服务器配置,适当调整
sort_buffer_size等参数。
- 注意联合索引:使用联合索引时,应确保
ORDER BY和WHERE条件符合索引的最左前缀原则,避免索引失效。
通过以上分析与实践,我们可以看到,优化MySQL深分页问题需要从业务设计、SQL编写、索引规划多个层面综合考虑。其中最有效的联表子查询方案,通过减少不必要的数据访问和排序负担,从根本上提升了性能。希望这些在云栈社区分享的实战经验,能帮助你在面对海量数据分页时,写出更高效的SQL。
 发表于 2026-3-7 13:38:05
|
查看: 218|
回复: 0
发表于 2026-3-7 13:38:05
|
查看: 218|
回复: 0
