传统数据治理严重依赖人工流程,不仅效率低下,也难以应对海量、动态的数据环境。如今,AI Agent(智能体)技术为数据治理带来了范式变革,它像一个不知疲倦的"超级数字员工",能够实现从感知、决策到执行的治理闭环自动化。本文将深入拆解数据治理Agent的四层核心架构,并提供一个从技术选型到业务落地的完整实战指南。
一、数据治理Agent的四层核心架构
一个完整的数据治理智能体本质上是"感知-决策-执行-学习"的闭环系统。
1. 感知层:数据的"感官系统"
这一层负责实时采集各类数据源的变化,为治理决策提供原始输入。
技术实现:
- 数据库日志捕获:使用Canal监听MySQL的Binlog,或Debezium抓取Oracle、PostgreSQL的变更流。
- API调用监控:通过OpenTelemetry等框架追踪微服务间的数据请求与响应。
- 用户行为审计:集成单点登录(SSO)、堡垒机日志,识别高危的数据访问与操作行为。
关键采集指标:
- 执行的SQL语句(涉及的表、字段、操作类型)
- 操作用户的身份、角色与权限信息
- 数据表与字段的上下游血缘关系
2. 决策层:数据的"智慧大脑"
基于感知层的信息,结合规则与AI模型进行推理,判断数据状态是否合规、质量问题是否需要修复。
技术实现:
- 规则引擎:使用Drools等工具处理明确的业务规则(例如:"身份证字段必须脱敏后才能查询")。
- 大模型推理:引入Qwen(通义千问)等大语言模型处理模糊、复杂的场景(例如:判断用户查询的"高净值客户"定义是否与企业标准一致)。
- RAG增强:从企业内部的数据字典、治理制度文档中检索相关信息,为大模型提供精准的领域知识,避免"幻觉",确保决策有据可依。
决策流程:
感知事件触发后,系统首先通过规则引擎进行快速过滤;对规则无法覆盖的复杂场景,则交由大模型结合RAG提供的背景知识进行推理,最终形成治理决策(如:通过、告警、阻断)。
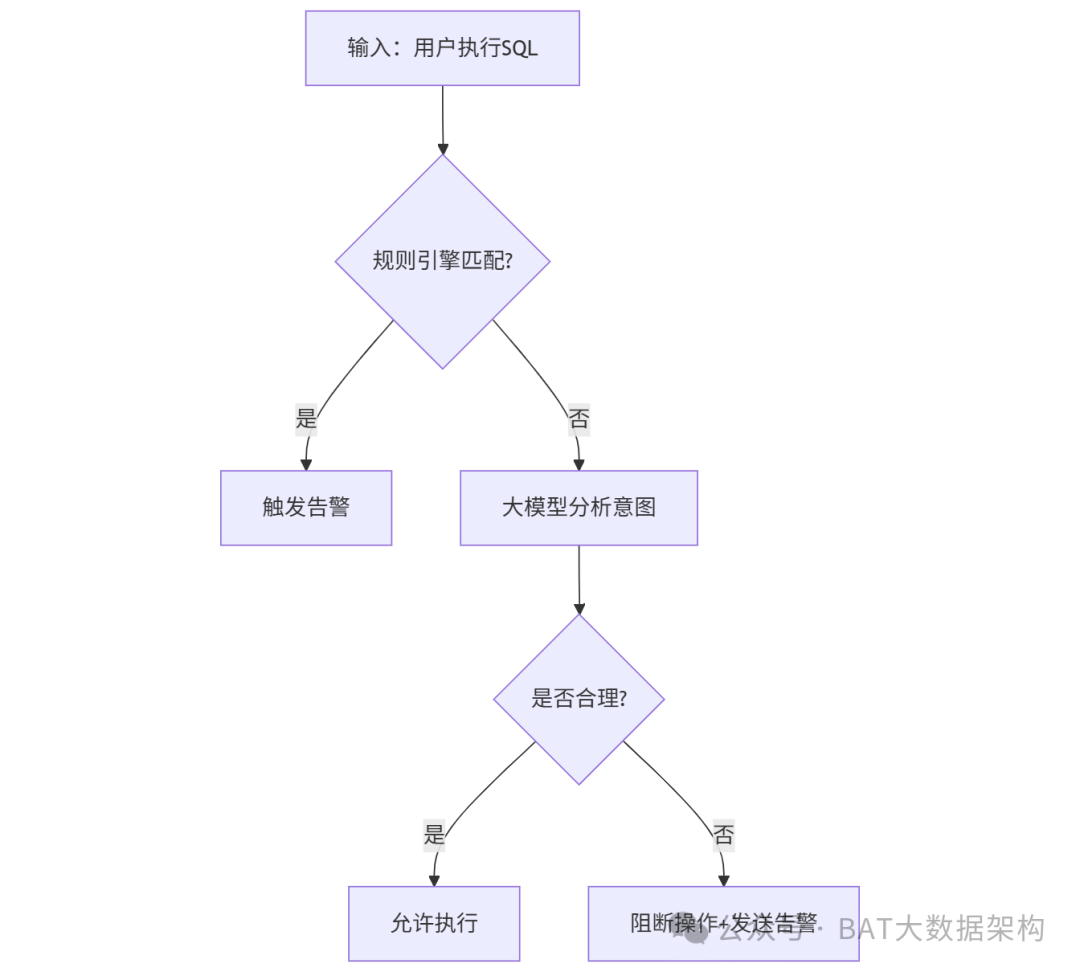
3. 执行层:数据的"手脚"
根据决策层的指令,自动执行相应的治理动作。
常见执行动作与工具:
| 动作 |
工具示例 |
| 发送告警通知 |
钉钉/企业微信群机器人、邮件 |
| 实时阻断违规操作 |
数据库防火墙(如设置拦截策略) |
| 调度任务修复数据质量 |
Airflow 调度SQL清洗脚本 |
| 更新元数据信息 |
调用 Apache Atlas 等元数据管理平台的API |
关键安全原则:
- 权限最小化:Agent服务账号仅拥有完成任务所需的最小权限(如只读日志、发送消息),严禁直接执行高危的删库、改表操作。
- 人类兜底:对于删除生产表等高风险操作,必须设置人工确认环节,由管理员审批后方可执行。
4. 学习层:数据的"经验记忆"
让Agent能够从历史治理事件中不断学习和优化,变得越来越"聪明"。
技术实现:
- 向量数据库存储:使用Milvus等向量数据库存储历史告警事件、修复记录及其上下文,便于相似案例检索。
- 闭环反馈机制:在发送的告警消息中嵌入"是否误报?"按钮,收集用户反馈,自动调整规则阈值或模型参数。
- 领域模型微调:利用LoRA等高效微调技术,基于企业内部的治理文档和案例对基座大模型进行微调,提升其对特定业务术语和规则的理解能力。
二、技术实现路径:从工具集成到智能体构建
1. 模型选型策略:大模型与小模型协同
核心决策用大模型:
对于需要理解复杂业务语境、进行推理判断的任务(如定义对齐、影响分析),选用GPT-4或同级别的国产大模型(如Qwen)。
简单任务用小模型:
对于模式匹配、特征提取(如识别身份证号格式)、向量检索等任务,使用BGE等轻量级小模型,可大幅降低推理成本(50%以上)。
实战组合案例:
- 敏感数据识别:小模型快速提取字段中的模式特征(如18位数字),大模型结合上下文判断其是否为需要保护的敏感身份证号。
- 数据质量告警:小模型监控表空值率是否超过阈值,大模型分析此表空值对下游报表的具体业务影响,生成有说服力的告警说明。
2. 工具调用:赋予Agent"动手能力"
让Agent不仅能"思考",还能"执行",需要通过工具调用框架连接各类系统。
核心工具链:
- LangChain:作为Agent的核心框架,用于集成数据库查询、API调用、文件读写等多种工具,定义工作流。
- Airflow:作为任务调度器,用于定时或触发式执行数据修复、质量检查等批处理任务。
- Drools:快速部署和迭代业务规则,实现对明确违规操作的实时拦截。
代码示例(LangChain调用工具):
from langchain.agents import initialize_agent, Tool
from langchain.llms import Qwen
# 定义Agent可用的工具
tools = [
Tool(
name="数据库查询",
func=query_database,
description="查询企业数据库表结构和内容"
),
Tool(
name="敏感数据检测",
func=check_sensitive_data,
description="识别身份证、手机号等敏感字段"
)
]
# 初始化Agent
agent = initialize_agent(
tools,
Qwen(temperature=0),
agent="zero-shot-react-description",
verbose=True
)
# 运行一个治理任务
result = agent.run("检查客户表中是否包含未经脱敏的敏感字段")
3. 治理知识增强:构建Agent的"业务知识库"
核心挑战:
如何让Agent理解企业内特有的业务术语和数据标准?
解决方案:
- 数据字典向量化:将Confluence、Excel中的数据字典文档通过RAG技术切片、嵌入,存入向量库,供Agent实时检索。
- 自动化血缘分析:解析ETL作业和SQL脚本,自动生成和维护数据资产间的依赖关系图谱。
- 量化质量评估:为数据资产定义空值率、重复率、时效性等质量指标,并设置自动评分与修复触发机制。
三、业务落地实战:从试点到规模化
1. 场景选择:从"小而美"的痛点切入
优先选择规则相对清晰、价值易于衡量的场景进行试点:
| 推荐场景 |
核心价值与优势 |
| 敏感数据外发拦截 |
合规刚性需求,规则明确,容易获得安全部门支持,可快速(如3周)上线验证价值。 |
| 核心报表数据质量监控 |
直接提升决策准确性,业务部门感知强,愿意为治理效果"买单"。 |
| 核心元数据变更通知 |
避免因上游表结构变更导致下游ETL任务或应用崩溃,深受运维和数据开发团队欢迎。 |
案例:
某商业银行从"开发环境敏感数据查询阻断"场景切入,首个部署月即成功拦截12次违规查询,潜在合规风险下降超过90%。
2. 团队协作:将Agent定位为"数字同事"
角色与职责:
- 数据治理委员会:定义核心治理规则与标准,审批Agent的高风险操作建议。
- IT与数据工程团队:负责Agent系统的部署、工具链维护与日常运维。
- 业务部门:提出具体的治理需求,在使用过程中对Agent的告警或建议进行反馈,标记误报。
关键运营动作:
- 定期复盘会:每周分析Agent的处理日志,协同优化规则,校准模型。
- 用户赋能:培训业务人员使用自然语言与Agent协作(例如,直接提问:"帮我查一下销售明细表的数据血缘")。
3. 安全与控制:为Agent设定"行动边界"
必须遵守的三大安全铁律:
- 权限最小化原则:Agent账号绝不授予直接修改生产环境核心数据表的权限。
- 操作可追溯原则:Agent所有的决策依据、执行动作必须完整记录到审计日志中,满足合规审计要求。
- 紧急熔断机制:系统必须提供管理员一键关停Agent所有自动化操作的能力,确保任何时候人类都能接管控制权。
四、三步搭建你的第一个数据治理Agent
步骤1:明确目标与范围
聚焦痛点:
选择一个高频、高业务痛感、且能形成处理闭环的场景作为MVP(最小可行产品),例如"生产数据库敏感信息访问实时告警"。
评估资源:
检查现有技术栈是否支持,例如数据库是否开启Binlog,是否有现成的监控告警通道(如钉钉)。
步骤2:快速搭建MVP
技术栈组合:
- 感知层:Canal监听MySQL Binlog
- 决策层:Drools(基础规则) + Qwen API(复杂判断)
- 执行层:钉钉机器人发送告警消息
成本估算:
- 工具成本:几乎为零(使用开源工具和现有通讯软件)
- 人力投入:1名后端开发(2周工作量) + 1名数据工程师(兼职提供业务规则)
步骤3:迭代优化与扩展
收集反馈:
在告警消息中设计便捷的反馈入口(如"误报"按钮),持续优化规则准确率。
扩展能力:
- 阶段1(监控告警):仅发现并通知问题
- 阶段2(自动修复):对已知的简单质量问题(如字段格式标准化)尝试自动修复
- 阶段3(主动建议):基于数据资产画像,主动提出治理建议(如"此表已180天未访问,建议归档")
结语:迈向人机共生的智能治理
数据治理Agent并非遥不可及的"黑科技",而是制度、技术与工具的高效融合。它的核心价值在于将数据治理从被动的"事后救火"转变为主动的"事前预防"和"事中控制",从而解放数据团队的人力,让其从繁琐的日常运维中抽身,更专注于数据战略与价值挖掘。
记住,成功的治理智能体,其智能化程度并非唯一标准,关键在于它能否切实地将治理工作从"成本中心"转化为"价值动力",实现可持续的"人机共生"。

 发表于 2025-12-8 01:40:09
|
查看: 242|
回复: 0
发表于 2025-12-8 01:40:09
|
查看: 242|
回复: 0
