
昨天,斯坦福大学博士生、Thinking Machines Lab 的研究者 Zitong Yang 完成了他名为「持续自我改进式 AI」的博士论文答辩。答辩完成后,他很快公布了完整的视频和幻灯片,系统性地展示了对未来AI进化路径的前沿探索。
针对当前大模型普遍存在的三大瓶颈——训练后权重固化、高质量人类数据即将枯竭、新算法发现高度依赖人工——他的研究提出了清晰的解决思路。
答辩的核心内容主要围绕三个方向展开:
首先是「合成持续训练」范式。研究团队利用名为“实体图”的合成数据生成技术,使模型在预训练后仍能持续学习小众领域的知识,同时避免灾难性遗忘。
其次是「预训练能力的自我提升」。通过“合成引导预训练”技术,让模型自主挖掘海量文档间的潜在结构与关联,从而优化自身预训练效果,并显著降低事实性错误。
最后是「迈向 AI 设计 AI」的展望。通过构建包含代码库和价值函数的独立研究环境,并引入演化搜索机制,让模型能够自主提出算法创意、编写代码并执行实验。
Zitong Yang 在总结中引用了一个深刻的类比:正如爱因斯坦创立的场方程预言了连他本人最初都难以接受的宇宙膨胀一样,人类基于算法过程创造的智能体,完全有可能进化出超越创造者自身智能水平的形态。
此次答辩委员会阵容强大,包括了斯坦福大学的 Percy Liang、Emmanuel Candès、Tatsunori Hashimoto 等知名教授,以及近期从 Meta 加入 OpenAI 的研究员庞若鸣。该研究也获得了业内多位重量级人物的关注,包括前 OpenAI CTO Mira Murati 和 PyTorch 联合创始人 Soumith Chintala 等。

以下是对 Zitong Yang 答辩核心内容的梳理。

何为“持续自我改进式 AI”?
在演讲伊始,Zitong Yang 首先尝试定义他想要构建的系统:
一个持续自我改进的AI系统,是指一旦被创造出来,就能自主且持续地进行自我改进,并且其改进效果要优于人类创造者对它的改进。

为了使定义更精确且可操作,他将讨论范围限定在满足两个假设的AI系统内:
- 参数化:系统基于一个或多个神经网络,其知识编码在一组明确定义的参数权重中。
- 预训练:系统经历了一个资源密集型的预训练阶段:
ai_system = learning_algorithm(training_signal),其中训练信号涵盖了大部分人类知识。

在这两个前提下,一个真正的持续自我改进的AI系统应满足三个特性(P1-P3):

(P1) 持续知识获取:在初始预训练后,系统能持续将新知识吸收进其参数权重,而不会灾难性遗忘已有能力。
(P2) 自我改进的预训练能力:系统能生成自己的训练信号,并且从这些自生成信号中学习所带来的改进,超越从人类生成信号中学习的改进。
(P3) AI设计的AI:系统能自主设计使用何种学习算法来从训练信号中学习。
这三个特性直指当前AI系统背后的“人类创造者”所面临的三个根本局限。
为何需要这样的AI?
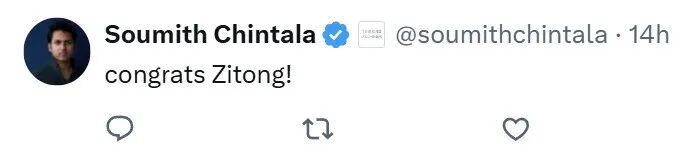
局限一:人类创造后,权重即静止
在与当前大模型的对话中,随着轮次增加,我们需要进行“上下文压缩”。这个过程是有损的,模型无法完美记忆过往对话。而人类记忆则不同,通过睡眠等机制可以转化和保留信息。这揭示了当前AI缺乏持续学习与记忆能力的短板。
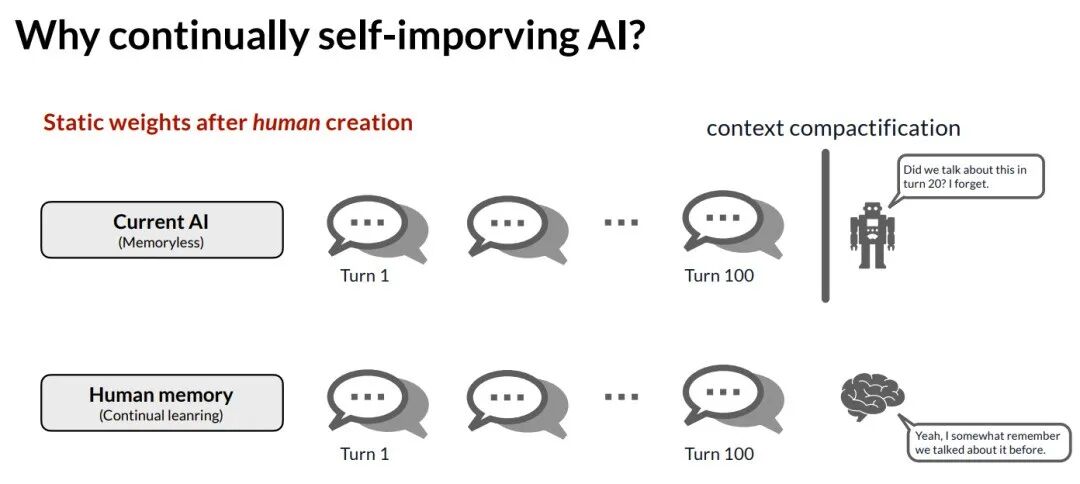
局限二:有限人类数据下的扩展瓶颈
根据 Scaling Law 和 Epoch AI 的预测,前沿大模型训练所用的数据量正迅速逼近互联网上可用文本数据的总量。尽管私有数据被不断吸纳,但人类产生的数据本质上是有限的,这将成为模型持续扩展的天花板。
局限三:受限于人类所能发现的算法
新算法的诞生依赖“提出想法 -> 实验验证 -> 产出成果”的人力密集型循环。我们发现的算法只是所有可能算法中的一小部分。让AI自动化这一科研过程,是突破此局限的关键。
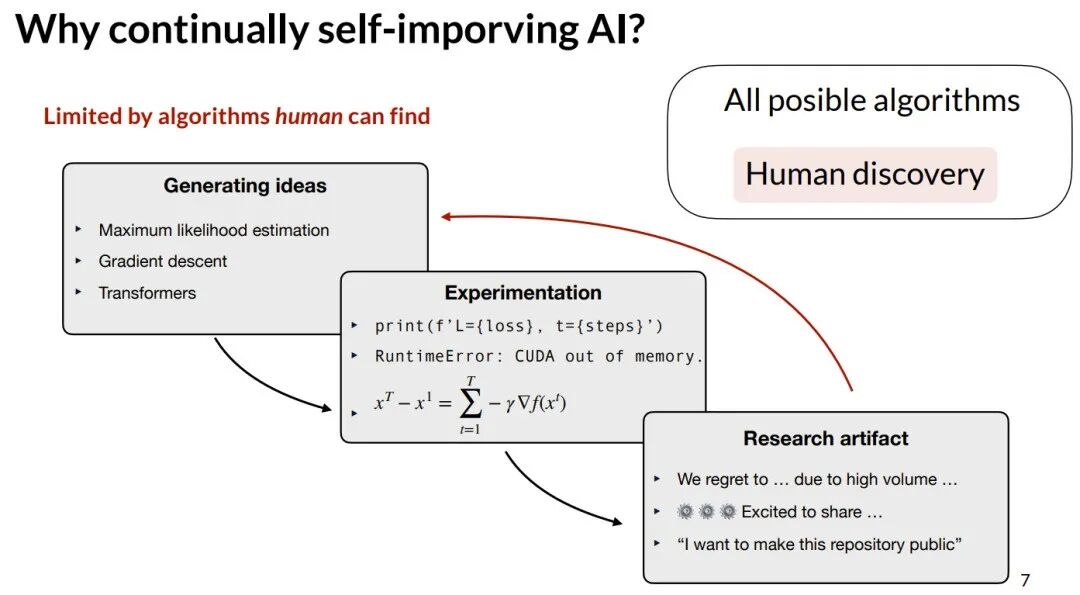
接下来,Zitong Yang 的演讲就从应对这三个局限的三个方面展开。

第一篇章:持续知识获取——合成持续训练
这一部分的研究旨在实现特性 P1:让模型在“出厂”后仍能持续吸收新知识。
他首先感谢了众多合作者,这项工作是团队智慧的结晶。

为了实现持续学习,他们提出了“合成持续训练”范式。其目标是将来自某个小众领域(仅有少量源文档)的知识教给模型。

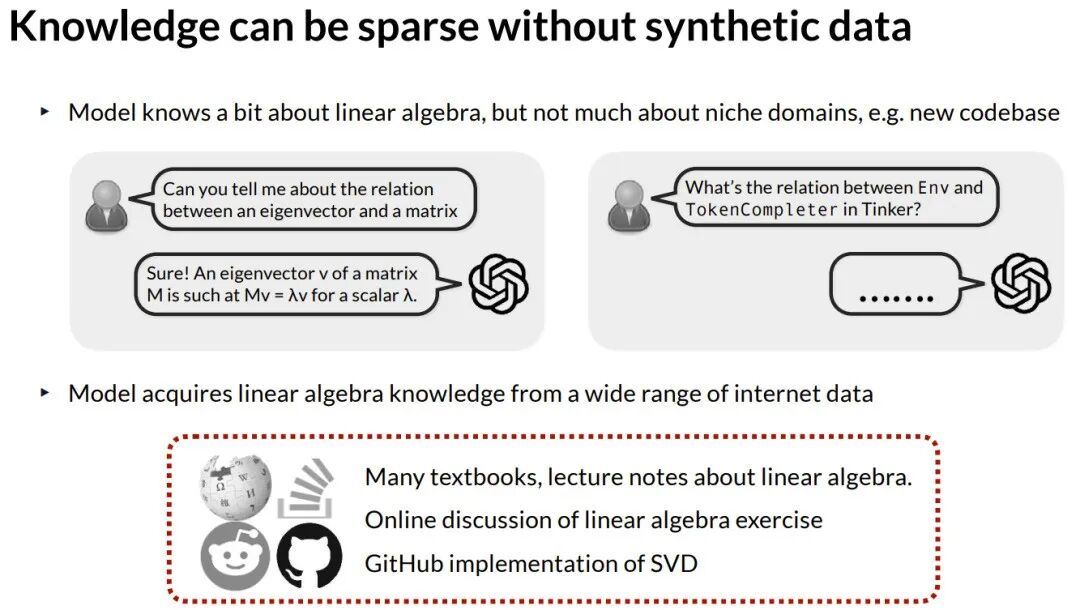
为什么要用合成数据?核心洞察是:没有合成数据,知识可能是稀疏的。模型对线性代数等常见主题有深刻理解,因为互联网上有海量相关教材、讨论和代码。但对于一个全新的小众代码库,模型可能一无所知,因为缺乏多样化的数据表征。
为了严谨验证,实验需要两样东西:
- 一组模型未知的小众领域源文档。
- 一个测试模型对此领域知识掌握程度的任务。
他们选择了 QuALITY 数据集。它包含265本专业书籍(约180万词元),模型本不知其内容,并配有高质量的多选题问答任务。

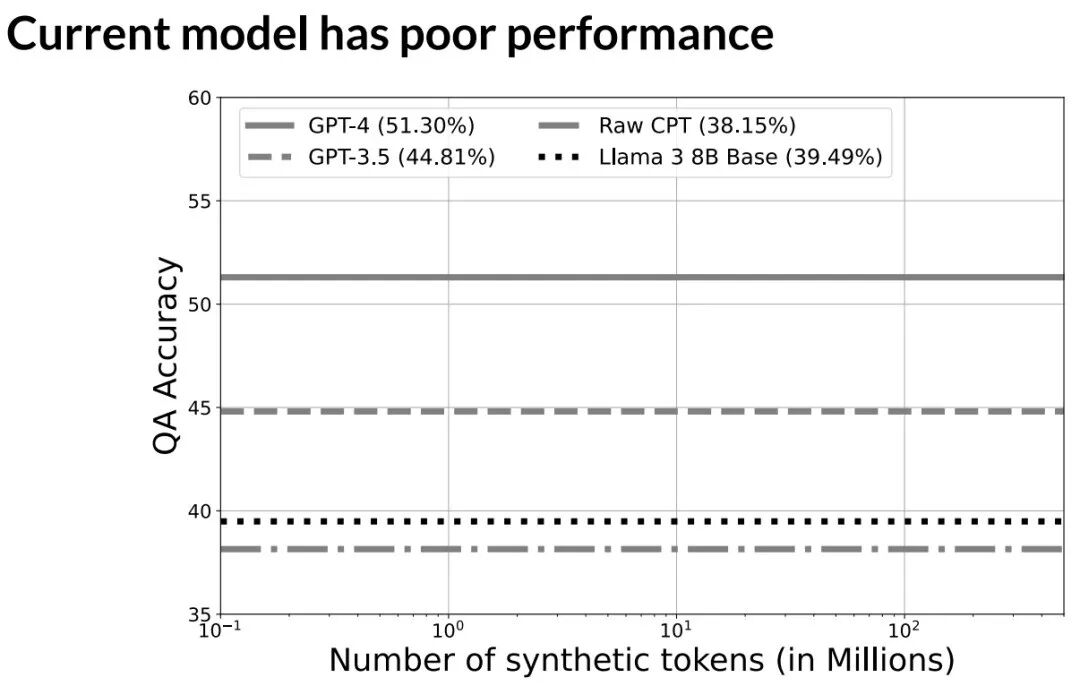
实验设置即:以这些书籍为源文档,让模型进行闭卷问答。

在基线测试中,Llama 3 8B 基础模型准确率仅39%,直接在原始文档上持续预训练(Raw CPT)效果反而下降。GPT-3.5和GPT-4的准确率分别在44%和51%左右,说明任务具有挑战性。
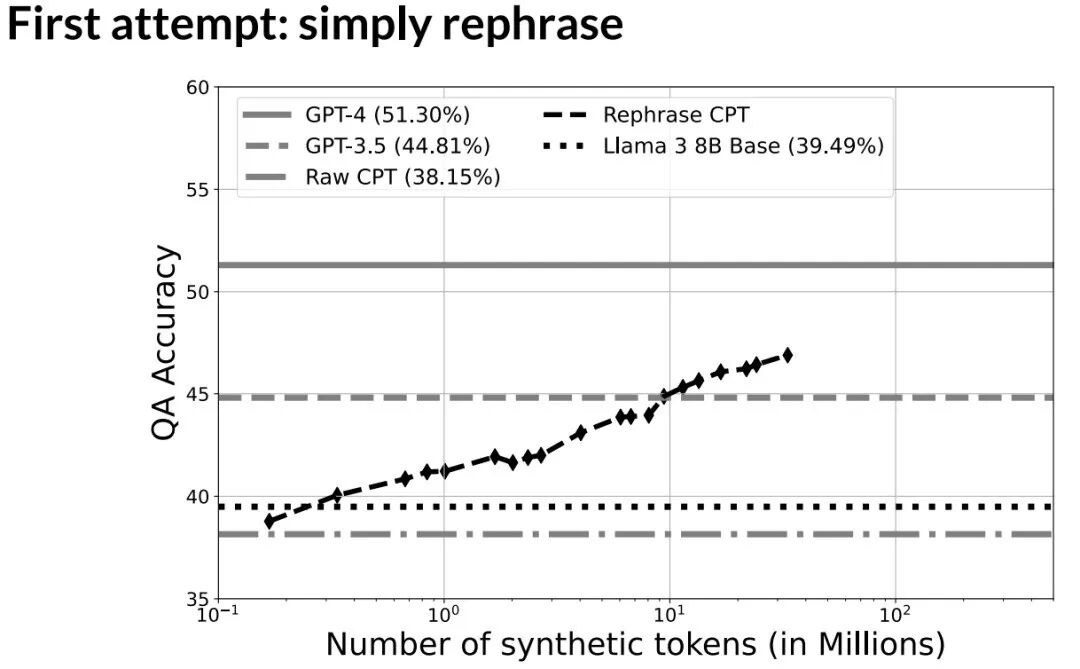
关键突破:从“简单重写”到“实体图生成”
首轮尝试是让模型“简单重写”文档。虽然准确率随合成数据量增加而提升,但斜率平缓,上限不高。问题在于这种方法缺乏数据多样性。
为此,他们提出了“实体图合成数据生成”方法。

该方法分为两步:
- 实体提取:从源文档中提取核心实体列表。
- 关系分析:随机选取实体子集,提示语言模型描述这些实体在原文背景下的关系,从而生成多样化的叙述文本。
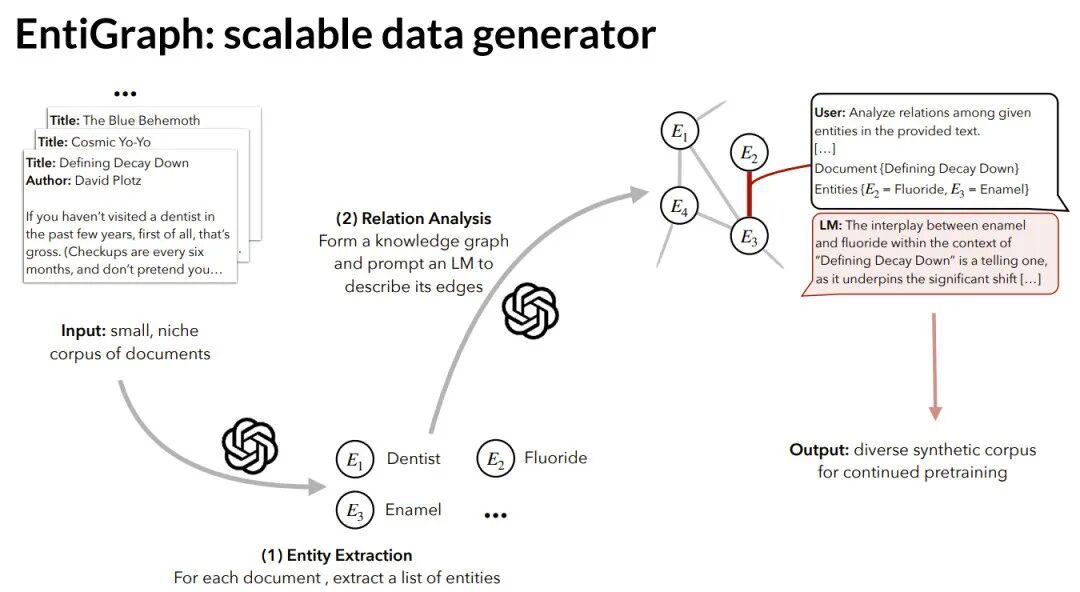
EntiGraph 方法带来了显著的性能提升。随着合成数据量增加,模型在闭卷问答上的准确率持续快速上升,最终超越了GPT-4的基线水平。
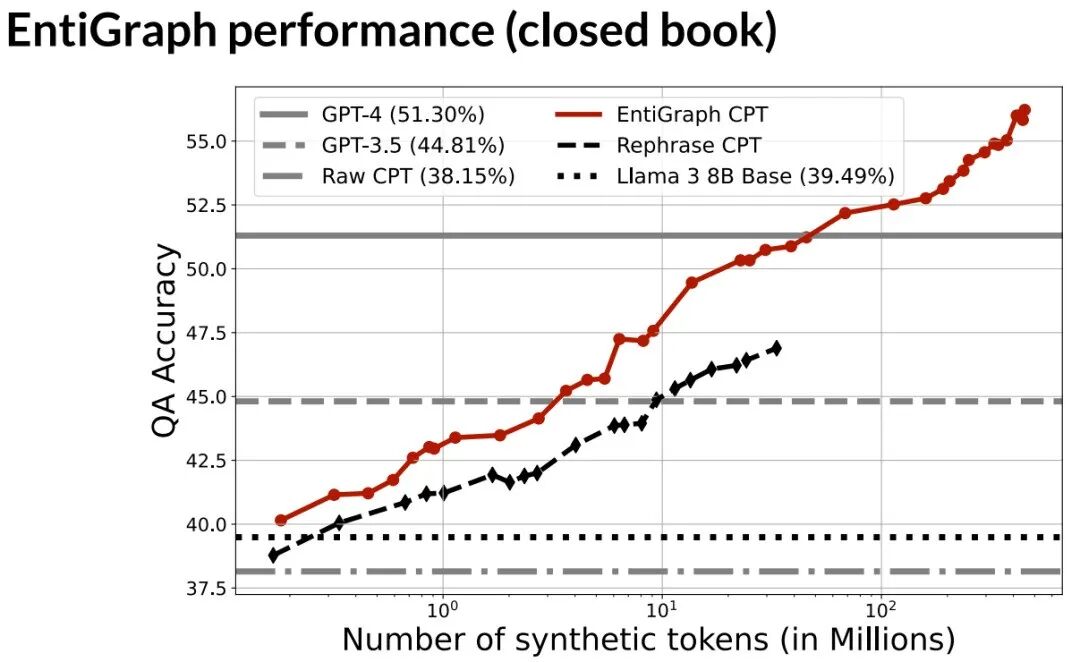
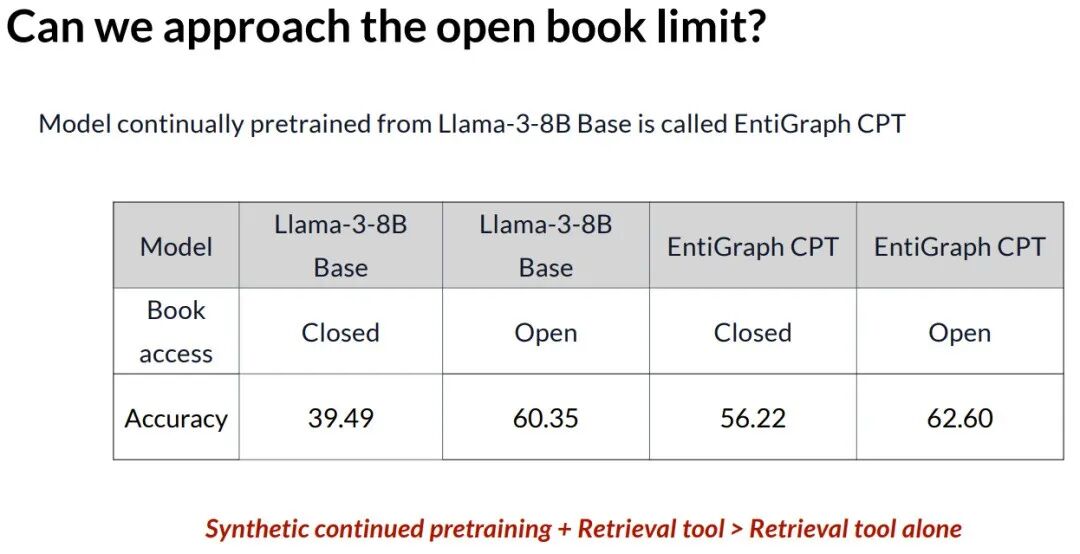
结合检索,逼近理论上限
研究还探索了开卷(提供原文检索)场景。结果表明,合成持续训练与检索工具的结合能带来最佳效果,性能超越仅使用检索工具。这为将来定制化领域模型提供了一种有效范式:综合利用合成数据训练和工具调用。
第二篇章:预训练能力的自我提升
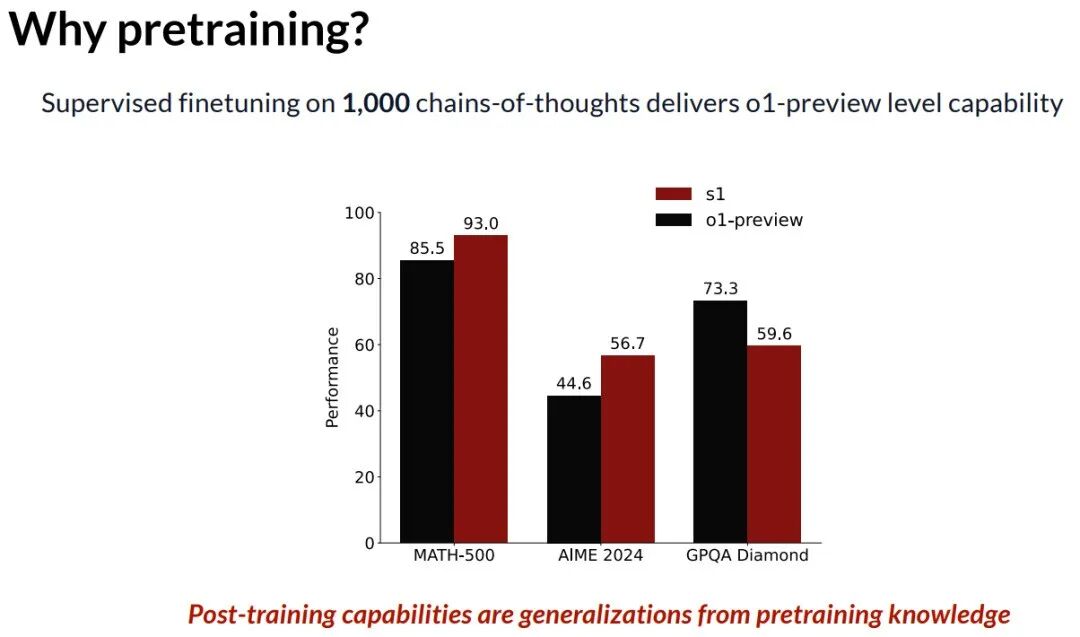
这部分研究瞄准特性 P2:让模型自我改进其核心的预训练能力。为什么预训练如此重要?Zitong Yang 以 o1 和 s1 模型为例指出,许多强大的后训练能力(如推理)本质上是预训练知识的泛化。因此,真正的自我改进必须发生在预训练层面。
那么,预训练中的“知识”究竟从何而来?他通过一个思想实验说明:如果训练数据是完全随机的 token 序列,模型将学不到任何东西。自然语言文本之所以可学习,是因为 token 间存在丰富的统计相关性或可压缩的结构性模式。

当前预训练范式一个未被充分利用的相关性来源是文档间的关联,例如《哈利·波特》书籍与其电影剧本、学术论文与其代码实现之间,都存在着深刻联系。
合成引导预训练
为了利用这种关联并实现真正的自我提升(而非知识蒸馏),他们设计了“合成引导预训练”三步法:
- 用固定数据从头预训练一个模型。
- 将该模型微调为一个合成数据生成器。
- 用“真实数据 + 合成数据”重新预训练一个新模型,观察性能提升。

具体技术细节包括:
- 最近邻配对:使用嵌入模型,在文档向量空间中寻找语义相近的文档对。
- 合成器微调:以相近文档对为训练样本,微调模型,使其能根据一篇文档生成相关文档。
- 规模化合成:使用温度=1的采样,基于所有真实文档大规模生成多样化的合成语料。
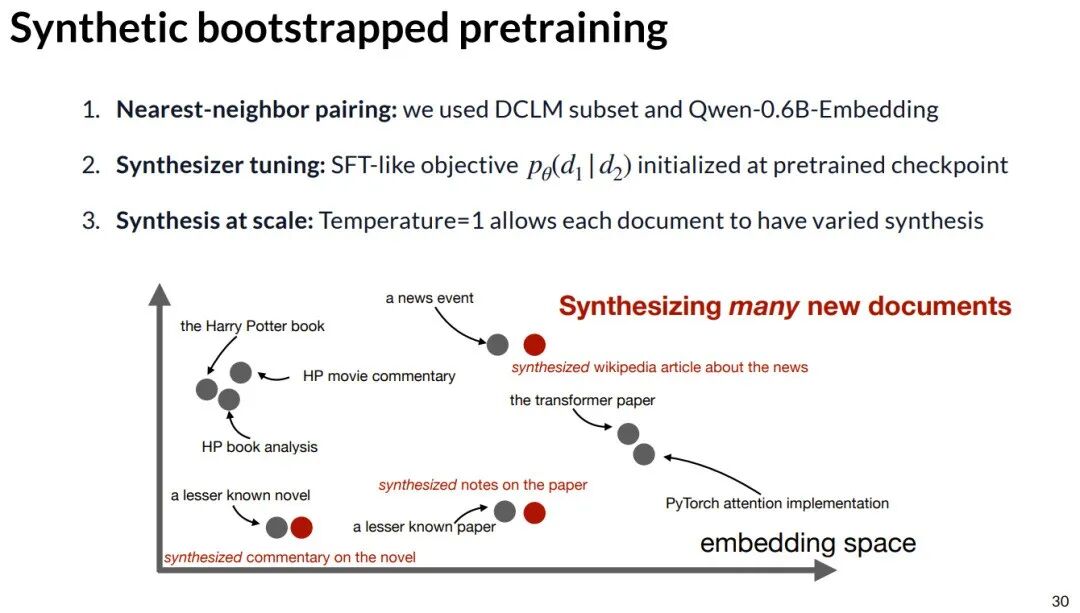
生成的合成数据并非简单复述,而是能进行联想和拓展,例如从讨论咖啡馆的文档,衍生出对意式咖啡机的探讨。

实验与结果
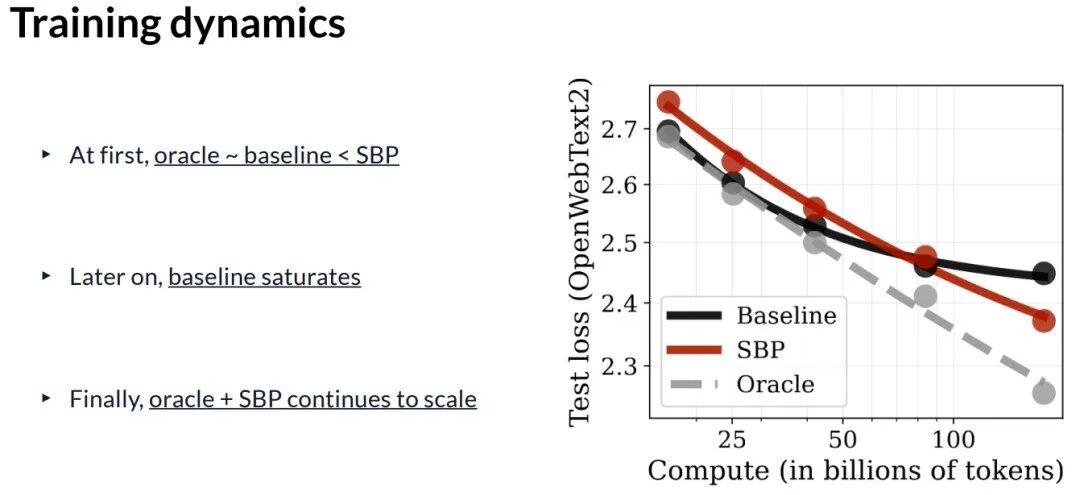
在严格控制计算量的对比实验中:
- 基线:重复使用固定真实数据。
- SBP:使用等量真实数据,但将其替换为等量的合成数据。
- 预言机:使用无限的真实数据(理想上限)。

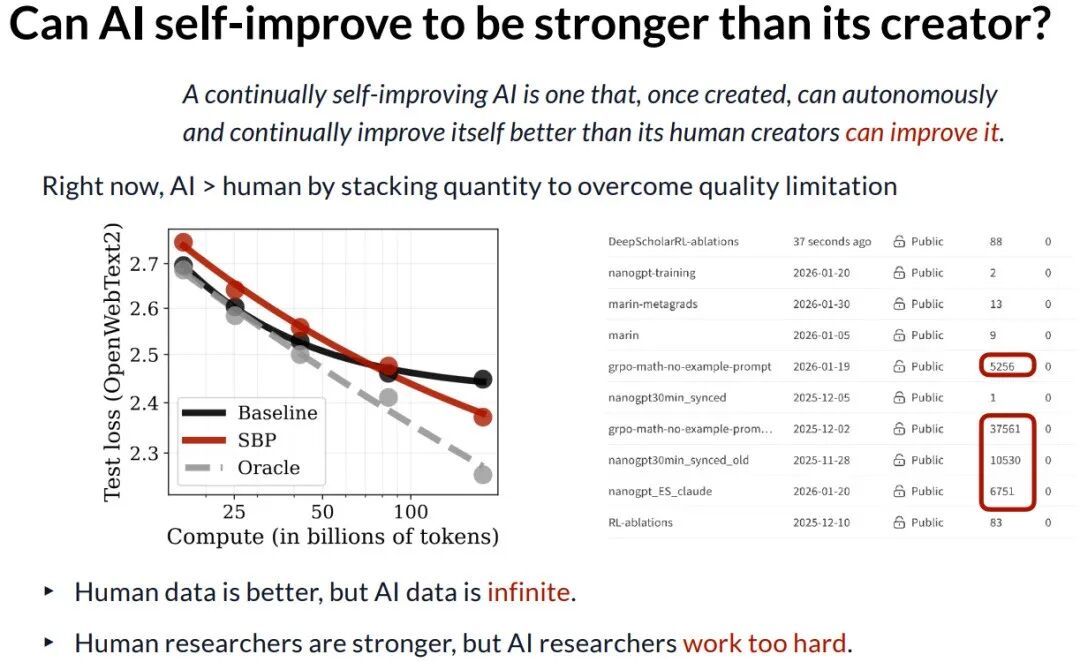
训练动态显示,基线方法很快因数据重复而性能饱和,而 SBP 方法则能跟随预言机的趋势持续提升。
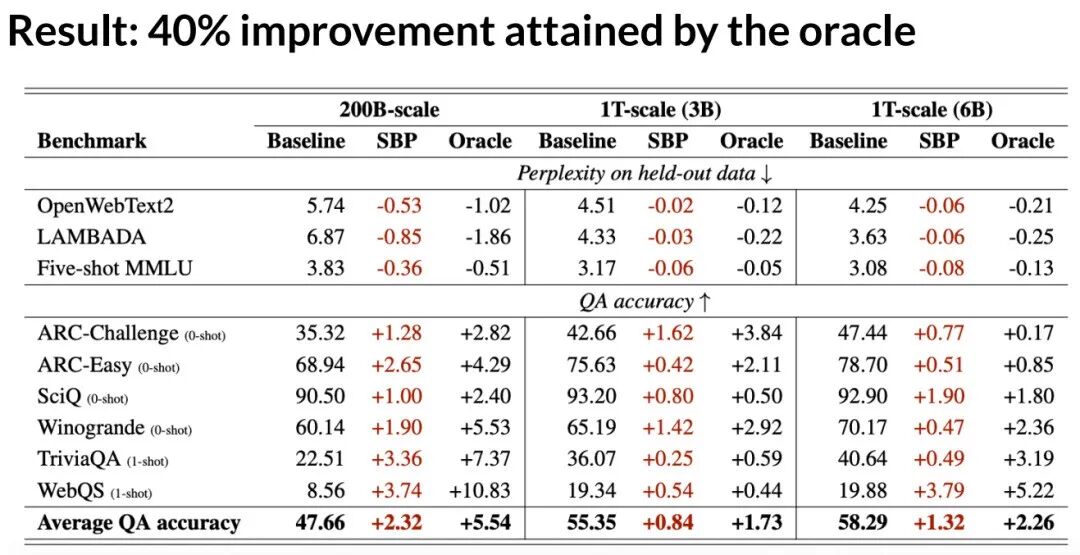
定量结果验证了 SBP 的有效性,在不同模型规模和训练计算量下,它都能带来一致的性能提升。更重要的是,随着用于生成合成数据的“母模型”规模增大,合成数据的质量(如事实准确性)显著提高。这表明更强的AI能生成更优质的训练数据,形成良性循环。
第三篇章:迈向 AI 设计 AI
最后一部分探索特性 P3:让AI自主设计学习算法。这实质上是让AI替代人类进行AI研究。
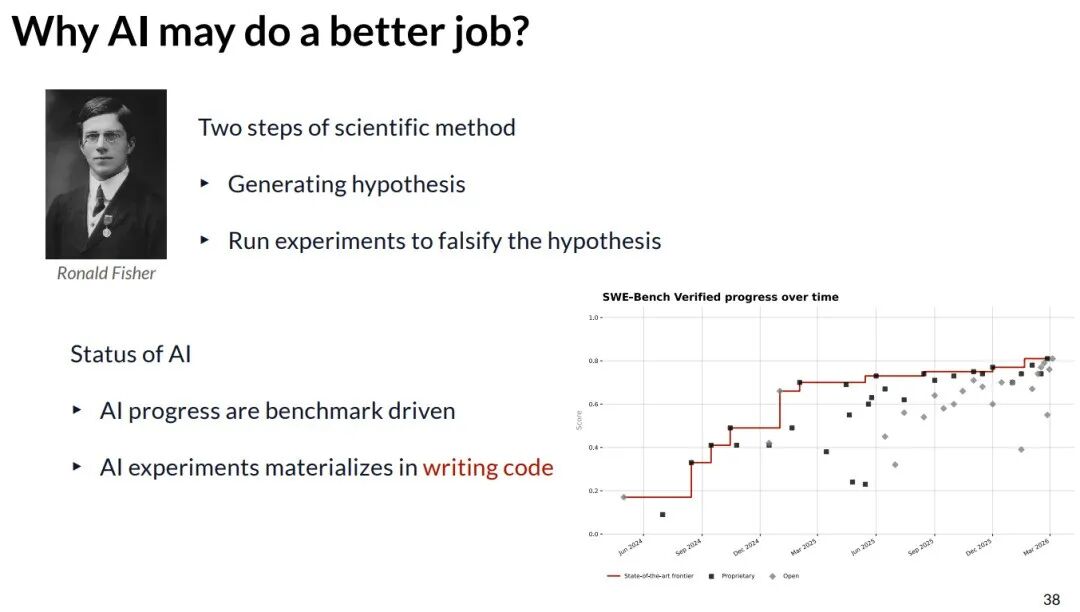
为什么AI可能更擅长做研究?科学方法论的两大支柱是“提出假设”和“实验验证”。AI生成假设如同生成文本,而AI实验则直接体现为编写和运行代码——这正是计算机的天然优势。
研究环境抽象
为了实现自动化研究,他们抽象出一个“研究环境”,它包含两个核心部分:
- 上下文:描述任务(如代码库)。
- 价值函数:评估一个想法(如代码补丁)的好坏。
class ResearchEnv:
@abstract
def context(self):
# passed into LM
# describing the task
pass
@abstract
def value(self, idea: str):
# goodness of the idea
# benchmark perf for AI
pass
class AIResearchEnv(ResearchEnv):
codebase: str
resource: str
sandbox_factory: Callable
def context(self):
return self.codebase
def value(self, code_diff: str):
sandbox = sandbox_factory(resource)
sandbox.exec(f"patch -p {code_diff}")
_ = sandbox.exec("bash run.sh")
std_out = sandbox.exec("bash eval.sh")
return std_out
他们构建了两种具体环境:一个是 nanoGPT 预训练任务(优化损失下降时间),另一个是 GRPO 数学推理后训练任务(优化准确率)。

自动化AI研究员系统
基于此,他们设计了自动化AI研究员系统,其工作流程如下:
想法 -> 研究员.构思器(环境.上下文)
代码差异 -> 研究员.执行器(环境.上下文, 想法)
结果.追加((想法, 环境.价值(代码差异)))
研究员.学习(结果)
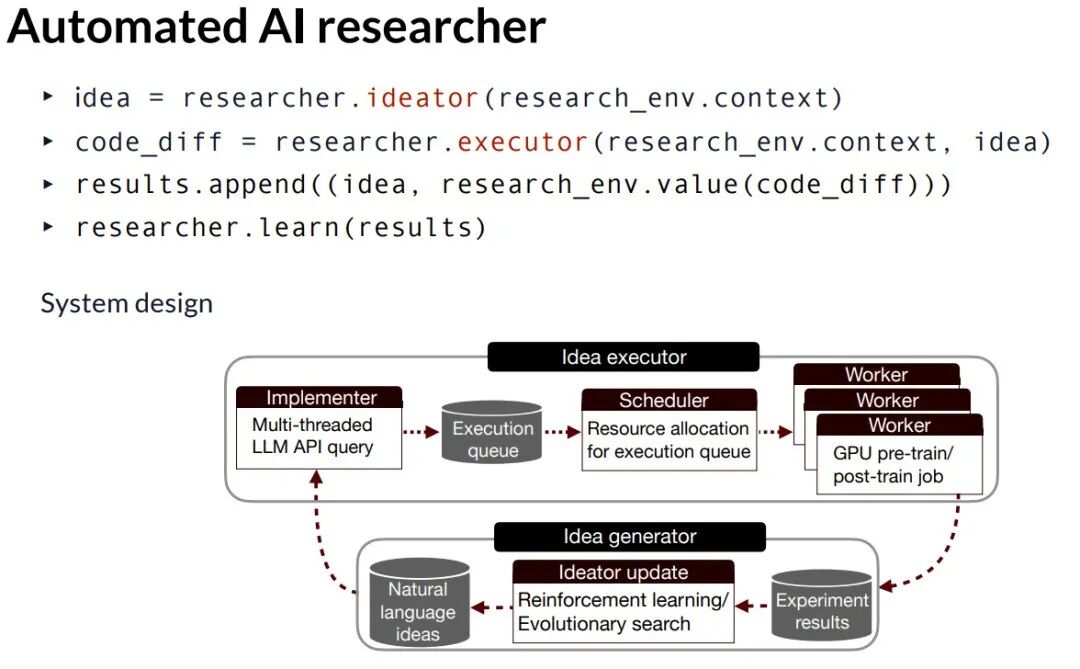
其中,“学习”过程被实现为一个迭代的测试时搜索。系统维护一个过往想法库,并策略性地结合(Exploit)优秀想法或探索(Explore)全新想法。

实验结果与启示
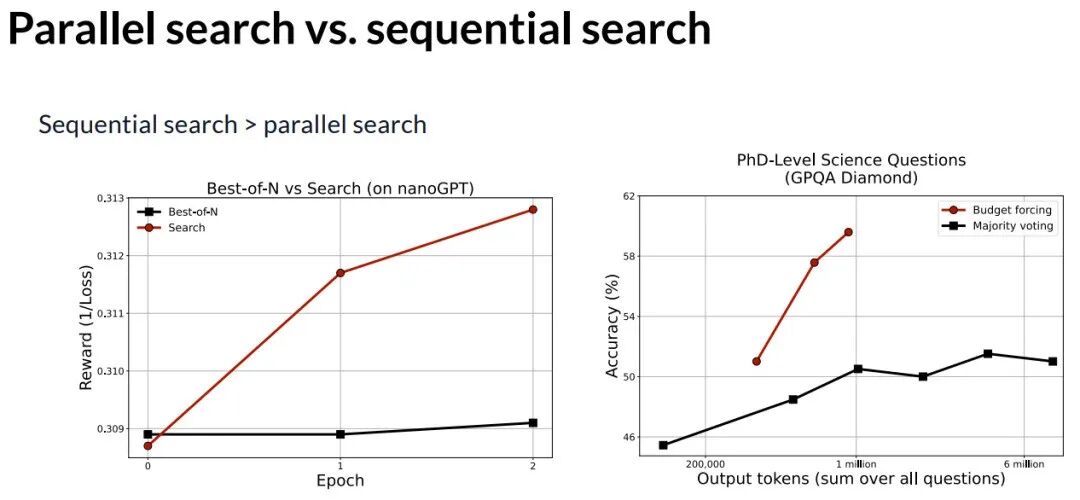
在数学推理后训练任务上,自动化搜索将准确率从48%提升至69.4%,达到了与该任务相关课程(CS336)排行榜上顶尖人类选手相当的水平。在预训练任务上也有改进,但尚未超越人类最佳记录。
一个有趣的发现是:串行搜索优于并行搜索。这与在推理任务中观察到的“预算强制”技术优于“多数投票”的现象类似,暗示了串行、迭代的思考过程比并行采样更有价值。
系统能够产生具有洞察力的想法。例如,它提出了“数学工作记忆模拟”的概念,通过维护一个存储数学事实和中间结果的缓冲区来辅助复杂推理,该想法实现了10%的性能提升。

结语:超越创造者的必然性
回顾最初的定义:持续自我改进的AI应能比人类创造者更好地改进自身。目前的证据显示,AI的优势在于以数量克服质量限制——人类数据质量更高,但AI能生成无限数据;人类研究员构思能力更强,但AI研究员可以不知疲倦地尝试数以万计的想法。
那么,AI能否实现真正意义上的、质变性的超越?Zitong Yang 借用物理学史上的一个经典案例给出了充满哲学意味的肯定回答。
爱因斯坦创立了广义相对论场方程,该方程预言了宇宙膨胀。然而,受当时“静态宇宙”主流观念影响,爱因斯坦人为添加了一个“宇宙常数”以使方程符合静态预期。后来哈勃观测证实了宇宙膨胀,且符合原始方程。爱因斯坦称引入常数为“一生最大错误”。

这个案例表明:一个理论(或算法系统)一旦被创造,就拥有了自己的“生命”,可以演化出超越创造者当时认知的结论。同理,人类通过算法过程创造的AI,也完全有潜力进化到比人类更智能的阶段。
“我们创造的东西,没有理由一定不能超越我们。” Zitong Yang 总结道。那种认为AI无法超越人类的“子集逻辑”(人类能力集包含AI能力集)忽视了算法创造过程的涌现特性。因此,问题或许不该是“AI能否超越人类”,而是我们如何引导这一必然的进程。
这项研究在 云栈社区 的「人工智能」和「智能 & 数据 & 云」板块引发了广泛讨论,为研究者们提供了关于合成数据驱动进化和自动化AI研究的前沿视角。
 发表于 2026-3-9 02:34:11
|
查看: 161|
回复: 0
发表于 2026-3-9 02:34:11
|
查看: 161|
回复: 0
