
金融市场是现代经济的核心引擎,驱动着海量的股票趋势建模与投资组合策略研究。然而,金融股票预测本身却面临着复杂依赖和非平稳动态的巨大挑战。以往的预测方法主要分为单变量时间序列(UTS)和多变量时间序列(MTS)两种范式:前者往往忽略了跨特征和跨股票的相互影响,而后者又只能同时捕捉其中一种关系。近年来兴起的3D多变量时间序列(3D-MTS)方法虽然理论上能处理更复杂的关系,但在实践中也存在信息丢失的问题。
为此,本文深入探讨一个名为 FinD³ 的前沿模型。它通过结合双立方状态空间模型(DCSSM)和动态演化超图注意力(EHA),旨在更精准地建模金融3D-MTS数据中的复杂时空依赖关系。实验证明,FinD³在真实的股市数据集上,其量化交易表现达到了当前最优水平。
简介
在金融分析领域,精确的预测模型是投资决策和风险管理的基石。现有的股票预测方法大致可归纳为三类:单变量时间序列(UTS)、多变量时间序列(MTS),以及更具表达力的3D多变量时间序列(3D-MTS)。
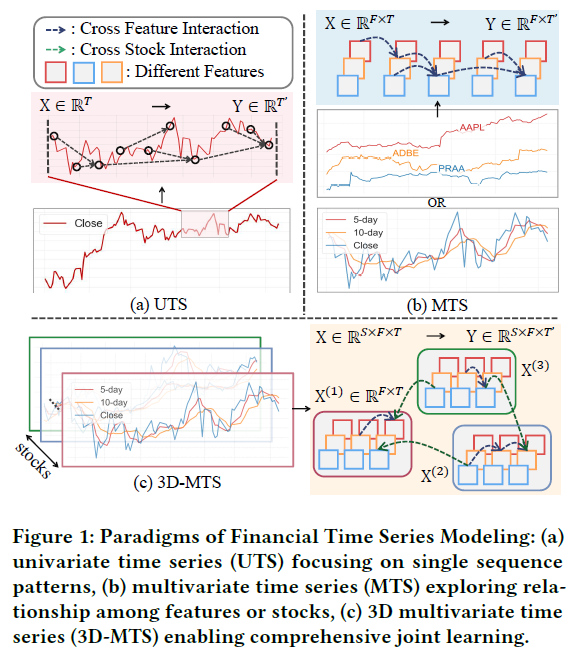
3D-MTS能够同时捕捉多只股票、多个特征之间的复杂交互,这对投资组合优化至关重要。然而,它在金融场景下的研究尚不充分,主要面临两大挑战:
- 信息利用不充分:现有研究多聚焦于简单的UTS或MTS,在处理3D-MTS时往往进行简化,导致大量跨维度依赖信息丢失。
- 动态关系建模难:金融市场是非线性动态系统,股票间的关系会随宏观经济和政策变化而演变。部分模型构建的静态图无法反映这种动态性;而另一些采用完全可学习的动态图,又可能忽略领域先验知识,导致收敛不稳定或产生极端模式。
为了应对这些挑战,我们提出了 FinD³ 框架。该框架的核心创新在于:
- 双立方状态空间模型(DCSSM):专门设计用于高效捕捉3D-MTS中跨股票和跨特征的复杂依赖,解决了高计算成本和交互建模难题。
- 演化超图注意力模块(EHA):通过分层结构和超图注意力生成卷积(HAGC)层,动态适应超图结构,既能融入先验领域知识,又能精准刻画市场关系的动态演变。
实验结果表明,FinD³在两个真实股市数据集上的交易表现达到了最先进的水平。
FinD³ 框架详解
预备知识
- 定义1:3D多变量时间序列(3D-MTS):定义为 $X=[X^{(1)}, X^{(2)}, ..., X^{(S)}] \in \mathbb{R}^{S \times F \times T}$,其中 $S$ 是股票集合的大小,$F$ 是特征数量,$T$ 是历史时间步长。每只股票 $i$ 的 $X^{(i)} \in \mathbb{R}^{F \times T}$ 表示其过去 $T$ 步的多元时间序列。我们的目标是捕捉3D-MTS中的复杂模式。
- 定义2:先验超图:基于金融领域知识构建的先验超图 $G^0 = (\mathcal{S}, \mathcal{E}^0, W^0)$。其中 $\mathcal{S}$ 是节点集(代表股票),$\mathcal{E}^0$ 是先验超边集(每条超边连接一个股票子集,代表某种共同关系或语义语境),$W^0$ 初始化为单位矩阵,关联矩阵 $M^0$ 是稀疏的二进制矩阵。
- 问题定义:给定3D-MTS输入 $X$ 和先验超图 $G^0$,目标是学习一个预测函数 $F_\theta(X, G^0)$ 来预测未来 $T'$ 个时间步的 $Y$,并基于预测表现选择前 $K$ 只股票以最大化投资回报。
框架概览
FinD³ 是一个端到端的框架,主要由两个关键组件构成:Dual Cubic State Space Model (DCSSM) 和 Evolving Hypergraph Attention (EHA)。
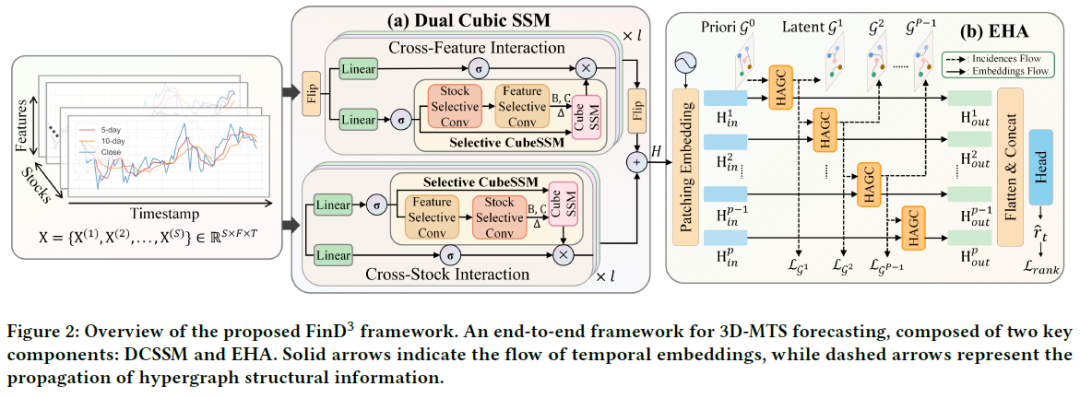
- DCSSM:负责从金融3D-MTS中提取复杂的时空依赖。它首先引入核心的 Selective CubeSSM,然后构建并行的跨股票分支和跨特征分支,分别捕捉股票间的相互影响模式和特征的全局共享模式。两个分支的输出最终融合成统一的嵌入 $H$,作为下游图神经网络的输入。
- EHA:借助领域先验知识来捕捉股市的动态特性。它将嵌入 $H$ 划分为多个时间块,并基于先验超图 $G^0$,通过多层的 超图注意力生成卷积(HAGC) 来迭代地生成和细化每一阶段的超图拓扑 $G^p$ 和节点嵌入 $H_{out}^p$。最后,将所有阶段的输出嵌入拼接,通过一个MLP生成最终的预测 $\hat{Y} \in \mathbb{R}^{S \times F \times T'}$。
双立方状态空间模型 (DCSSM)
DCSSM 是为提取3D-MTS数据中的复杂关系而设计的。经典的状态空间模型(SSM)不适用于3D数据,因此我们引入了 Selective CubeSSM 和双分支架构。
Selective CubeSSM
经典SSM将一个序列建模为一个线性时不变(LTI)动力系统:
$$h_t = A h_{t-1} + B x_t$$
$$z_t = C h_t \tag{1}$$
为了将SSM应用于3D-MTS(形状为 $S \times F \times L$),我们提出了一种3D参数化策略,采用两步选择性卷积设计(特征选择卷积 FConv 和股票选择卷积 SConv),以实现特征和股票维度的灵活参数化。
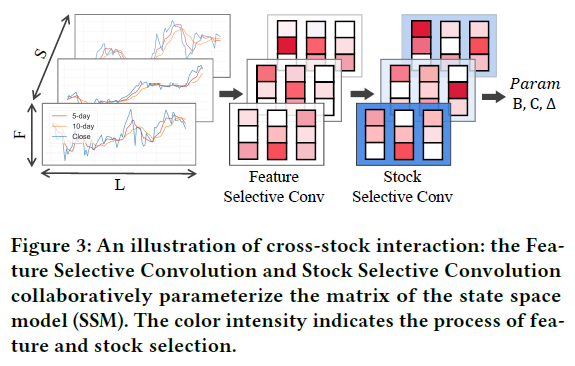
参数化函数定义为:
$$f_\delta(x) = \text{SConv}_\delta(\text{FConv}_\delta(\text{Linear}(x))) \quad \delta \in \{B, C, \Delta\}, \tag{2}$$
使用零阶保持(ZOH)方法对连续时间SSM进行离散化:
$$\bar{A} = e^{\Delta A} \quad \bar{B} = (\Delta A)^{-1}(e^{\Delta A} - I) \Delta B, \tag{3}$$
离散化后的状态转移方程为:
$$h_t = \bar{A} h_{t-1} + \bar{B} x_t \quad z_t = C h_t. \tag{4}$$
Selective CubeSSM的算法伪代码如下,其计算复杂度约为 $O(BSFLN)$,相比自注意力机制的 $O(BSFL^2)$ 更适合处理长序列。
Algorithm 1 Selective CubeSSM
Input: X ∈ ℝ^(B×S×F×L)
Output: Z ∈ ℝ^(B×S×F×L)
1: Initialize learnable parameter A ∈ ℝ^(N×F), N: state dimension
2: B ← f_B(X) ∈ ℝ^(B×S×F×L)
3: C ← f_C(X) ∈ ℝ^(B×S×F×L)
4: Δ ← Linear(f_Δ(X)) ∈ ℝ^(B×S×N×L)
5: Discretize A̅ ← exp(ΔA) ∈ ℝ^(B×S×N×L×F)
6: Discretize B̅ ← (ΔA)^(-1)(exp(ΔA) - I)(ΔB) ∈ ℝ^(B×S×N×L×F)
7: Initialize hidden state h_0 ∈ ℝ^(B×S×N×F)
8: for t = 1 to L do
9: Extract x_t, the t-th time slice of X
10: Extract A_t and B̅_t, the t-th slices of A̅ and B̅
11: Extract C_t, the t-th slice of C
12: Compute hidden state: h_t = A̅_t h_{t-1} + B̅_t x_t
13: Compute output: z_t = C_t h_t
14: end for
15: Concatenate outputs {z_t}_{t=1}^L along time dimension to form Z
交叉股票分支
该分支专注于捕捉不同股票间时间模式的相互影响。
$$X^{stock} = \text{MLP}(X) \in \mathbb{R}^{S \times F \times L}, \tag{5}$$
$$B = f_B(X^{stock}) \quad C = f_C(X^{stock}) \quad \Delta = \text{Linear}(f_\Delta(X^{stock})), \tag{6}$$
通过Selective CubeSSM得到输出
$Z^{stock}$,并与原始输入交互:
$$O^{stock} = \text{MLP}(X^{stock}) \odot \text{MLP}(Z^{stock}). \tag{7}$$
交叉特征分支
该分支通过建模单个特征如何受到不同股票集体行为的共同影响,来捕捉跨特征依赖关系。
$$X^{feature} = \text{MLP}(\text{Flips}(X)) \in \mathbb{R}^{F \times S \times L}, \tag{8}$$
$$B = f_B(X^{feature}) \quad C = f_C(X^{feature}) \quad \Delta = \text{Linear}(f_\Delta(X^{feature})), \tag{9}$$
类似地,得到输出并交互:
$$O^{feature} = \text{MLP}(X^{feature}) \odot \text{MLP}(Z^{feature}). \tag{10}$$
分支融合
最后,通过元素相加融合两个分支的输出,并进行适当的维度转换:
$$H = (O^{stock} + \text{Flip}(O^{feature})) \in \mathbb{R}^{S \times F \times L}. \tag{11}$$
这个统一的嵌入
$H$ 将作为下游EHA模块的输入。
演化超图注意力 (EHA)
EHA模块是一个多阶段的分层架构。它利用先验超图融入领域知识,引导模型的合理初始状态,防止过拟合,同时超图拓扑会在各个阶段迭代细化。
首先,将DCSSM的输出 $H$ 加上位置嵌入 $W_{pos}$ 后,分割成 $P$ 个非重叠的时间块:
$$H_{in}^p = \text{Patching}(H + W_{pos}), \tag{12}$$
其中
$p \in [1, P]$ 表示阶段索引。
超图注意力生成卷积 (HAGC)
超图拓扑定义了节点间的交互方式。在第 $p$ 阶段,HAGC层以前一阶段的超图结构($G^{p-1}$ 及其关联矩阵 $M^{p-1}$、权重矩阵 $W^{p-1}$)和当前时间块嵌入 $H_{in}^p$ 作为输入。
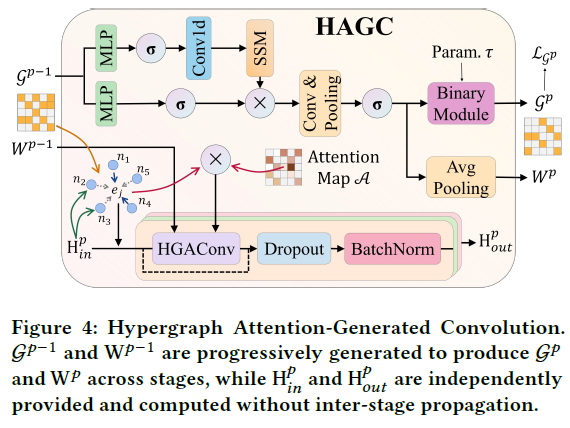
超图拓扑生成:利用SSM来提取金融市场的潜在动态结构模式。将前一阶段的二进制关联矩阵 $M^{p-1}$ 转换为潜在的连续值信息矩阵 $\tilde{M}^p$。
$$\tilde{M}^p = \text{MLP}(M^{p-1}) \odot \text{MLP}(\text{Conv1d}(\text{SSM}(M^{p-1}))), \tag{13}$$
对于 $\tilde{M}^p$ 中的每一列(对应一条超边 $e_i$),使用SSM进行处理:
$$h_i = \bar{A} h_{i-1} + \bar{B} e_i \quad z_i = C h_i \quad e_i \in \mathcal{E}^{p-1}, \tag{14}$$
根据 $\tilde{M}^p$ 计算下一阶段超边的权重 $W^p$,通过计算每列关联值的平均值来确定超边的重要性:
$$W^p = \text{diag}(\text{AVG}_{v \in \mathcal{S}}(\tilde{M}^p)) \in \mathbb{R}^{|\mathcal{E}^p| \times |\mathcal{E}^p|}, \tag{15}$$
生成二进制的复杂关联矩阵 $M^p$:对 $\tilde{M}^p$ 应用可学习的Gumbel-Softmax函数进行二值化。前向传播时使用 argmax 进行硬二值化,反向传播时采用连续的Gumbel-Softmax松弛。
$$M_j^p = \begin{cases} \arg\max_j (l_j + g_j) & \text{(forward)} \\ \exp((l_j+g_j)/\tau) / \sum_k \exp((l_k+g_k)/\tau) & \text{(backward)} \end{cases}, \tag{16}$$
其中
$l$ 是logits,
$g$ 是Gumbel噪声,
$\tau$ 是温度参数。
超图注意力卷积:为了细化节点与超边间的交互,我们使用一个注意力加权矩阵 $A_{att}^{p-1}$ 来替代原始的关联矩阵 $M_{p-1}$。注意力分数 $\alpha_{i,j}$ 量化了节点 $i$ 对超边 $j$ 的重要性。
$$\alpha_{i,j} = \frac{\exp(\text{LeakyReLU}(\mathbf{a}^T [\mathbf{W}_Q x_i || \mathbf{W}_K e_j]))}{\sum_{k \in \mathcal{N}_i} \exp(\text{LeakyReLU}(\mathbf{a}^T [\mathbf{W}_Q x_i || \mathbf{W}_K e_k]))} \tag{17}$$
在第 $l$ 层超图注意力卷积中,使用 $H$ 个头进行卷积操作以更新节点特征:
$$X^{(l+1)} = \|_{h=1}^{H} \sigma(D_v^{-1/2} \mathcal{A}_{att}^{(p-1)} W^{(p-1)} D_e^{-1} {\mathcal{A}_{att}^{(p-1)}}^T D_v^{-1/2} X^{(l)} \Theta), \tag{18}$$
层与层之间穿插批量归一化(BatchNorm)和 Dropout 层。阶段
$p$ 的HAGC模块最终输出更新后的节点嵌入
$H_{out}^p$。
最终预测与正则化
经过 $P$ 个阶段的迭代后,将所有阶段的输出嵌入沿时间维度拼接,并输入到一个预测MLP头中,生成未来 $T'$ 步的预测:
$$\hat{Y} = \text{MLP} (\|_{p=1}^{P} H_{out}^p). \tag{19}$$
为了鼓励超边内的节点特征相似,并促进超图结构的稀疏性,我们设计了一个超图拉普拉斯正则化损失项 $\mathcal{L}_G$:
$$\mathcal{L}_G = \frac{1}{P-1} \sum_{p=1}^{P-1} \log(1 + \text{tr}({H_{out}^p}^T L_{sym}^p H_{out}^p)), \tag{20}$$
其中
$L_{sym}^p = I_N - D_v^{-1/2} M^p D_e^{-1} {M^p}^T D_v^{-1/2}$ 是未加权的超图对称拉普拉斯矩阵,强调拓扑结构本身的重要性。
损失函数
模型的训练通过一个组合损失函数来引导:
- 回归损失:确保预测值接近真实值。
$$\mathcal{L}_{reg} = \frac{1}{S} \sum_{i=1}^{S} |\hat{Y}^{(i)} - Y^{(i)}|^2 \tag{21}$$
- 排序损失:对于投资决策,预测收益的相对排名比绝对值更重要。计算股票 $i$ 的预测收益率 $\hat{r}_t^{(i)} = (\hat{p}_t^{(i)} - p_{t-1}^{(i)}) / p_{t-1}^{(i)}$,并应用成对排序损失:
$$\mathcal{L}_{rank} = \sum_{i=1}^{S} \sum_{j=1}^{S} \phi((r_t^{(i)} - r_t^{(j)})(\hat{r}_t^{(i)} - \hat{r}_t^{(j)})), \tag{22}$$
其中 $\phi(x) = \log(1+\exp(-x))$。
- 完整的端到端损失:
$$\mathcal{L} = \mathcal{L}_{reg} + \alpha \mathcal{L}_{rank} + \lambda \mathcal{L}_G. \tag{23}$$
超参数 $\alpha$ 和 $\lambda$ 用于平衡各项损失的重要性。
实验与分析
实验设置
- 数据集:使用2013年至2017年纳斯达克(NASDAQ)和纽约证券交易所(NYSE)的真实股票数据进行评估。纳斯达克数据集包含1026只股票,纽交所包含1737只。基于5日、10日、20日、30日移动平均线及收盘价构建特征,并进行了标准化。先验超边基于DTW距离近邻、行业分类、所有权关系三种关系构建。
| Market |
Stocks(Nodes) |
Train Period |
Validation Period |
Test Period |
Priori Hyperedges |
| NASDAQ |
1026 |
2013/01 - 2015/12 (756) |
2016/01 - 2016/12 (252) |
2017/01 - 2017/12 (237) |
2212 |
| NYSE |
1737 |
2013/01 - 2015/12 (756) |
2016/01 - 2016/12 (252) |
2017/01 - 2017/12 (237) |
6423 |
- 实现细节:使用PyTorch 2.3.0在NVIDIA A800 GPU上实现。使用Adam优化器,固定随机种子以确保可复现性。关键模块参数如下:
- DCSSM:编码器2层,嵌入维度24,卷积核大小3。
- Selective CubeSSM:状态维度16,扩展因子2,SiLU激活。
- EHA:补丁长度8,超图注意力卷积2层、4头、隐藏单元48,SSM状态维度16。
- 评估指标:通过模拟每日买入持有交易策略来评估。在每个时间步 $t$,按预测收益率 $\hat{r}_t$ 降序选择前 $K$ 只股票构建投资组合,在 $t+1$ 步卖出。使用夏普比率(SR) 和投资回报率(IRR) 作为主要评估指标。
整体表现
下表对比了FinD³与各类基线方法在NASDAQ和NYSE数据集上的表现。
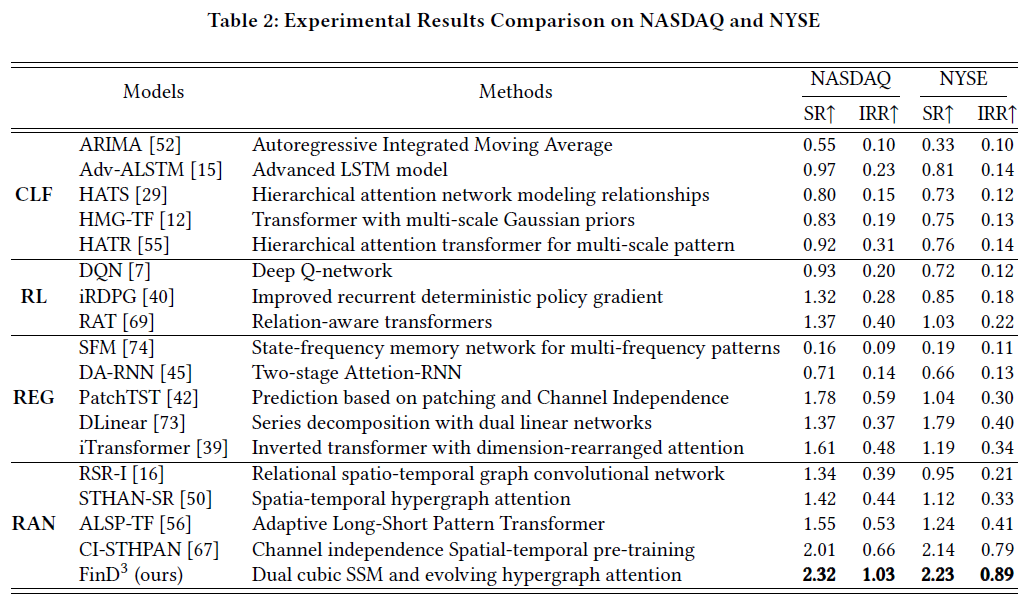
实验结果表明:
- FinD³在两个交易所的SR和IRR指标上均取得了最佳表现,证明了其能够有效捕捉3D-MTS中潜在的时间模式与动态关系依赖。
- 与经典统计方法(CLF)相比提升显著,凸显了线性假设在复杂金融市场中的局限性。
- 相较于其他先进的深度学习方法(如PatchTST、iTransformer)和关系感知模型(如CI-STHPAN),FinD³通过结合先验知识的动态超图建模,表现出了更强的适应性和稳定性。
消融分析
为了验证各个组件的有效性,我们进行了系统的消融实验。
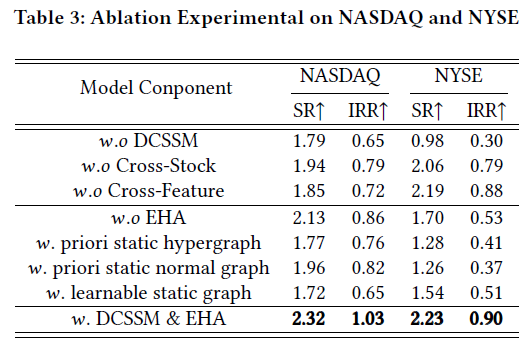
关键发现:
- DCSSM至关重要:移除整个DCSSM模块(
w.o DCSSM)会导致性能大幅下降,说明其对于捕捉3D-MTS时空模式是不可或缺的,且双分支的协同效果最佳。
- EHA模块贡献显著:移除EHA模块(
w.o EHA)同样会影响性能,尤其是在NYSE数据集上,这表明建模股票间的高阶动态交互非常重要。
- 动态演化优于静态图:使用先验静态超图(
w. priori static hypergraph)或普通静态图(w. priori static normal graph)的效果均不如完整的动态演化版本(w. DCSSM & EHA),说明了结合初始化先验与动态建模的必要性。
- 可学习静态图效果有限:完全从数据中学习静态图结构(
w. learnable static graph)的性能也不稳定,进一步印证了融入领域先验知识对引导模型学习、防止过拟合的重要性。
盈利能力与风险分析
我们进一步分析了模型的累积收益和风险调整后收益。
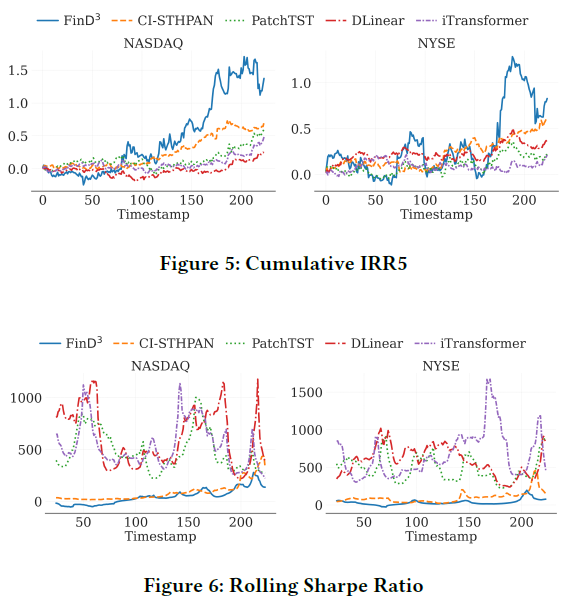
- 图5:累计IRR:展示了随着时间推移,各模型投资组合的累计内部收益率。FinD³的累计回报曲线始终高于其他基线,表明其总体盈利能力更强。
- 图6:滚动夏普比率:展示了30天滚动窗口下的夏普比率变化,用于评估短期绩效的稳定性。FinD³的夏普比率轨迹更加平稳且维持在较高水平,说明其在追求高回报的同时,能更好地控制风险。
这些结果得益于DCSSM与EHA的协同设计,使得模型能够同时追踪市场动态变化和股票间的结构性依赖,从而实现更可持续和可靠的预测。
参数敏感性分析
我们对关键超参数进行了敏感性分析。
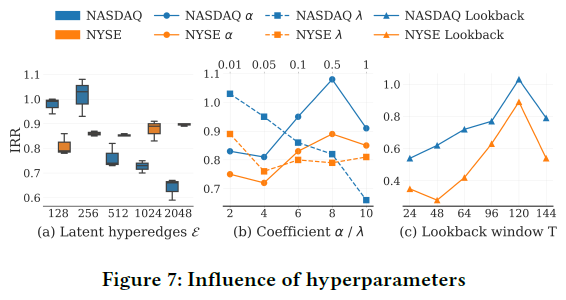
- (a) 潜在超边数 $\epsilon$:不同数据集的最优值不同(NASDAQ ~256, NYSE ~2048),反映了不同市场的内在复杂度差异。
- (b) 损失系数 $\alpha / \lambda$:模型对正则化系数表现稳定,最佳值为 $\alpha=8, \lambda=0.01$,显示出一定的鲁棒性。
- (c) 回溯窗口 $T$:性能随着回溯窗口 $T$ 增大而提升,在 $T=120$ 附近达到最佳,过长则略有下降,证明了FinD³在捕捉长期依赖方面的优势。
效率分析
最后,我们比较了不同模型的推理时间(单位:秒)。
| Model |
NASDAQ |
NYSE |
| PatchTST* |
159.84 |
256.87 |
| DLinear* |
36.81 |
94.60 |
| iTransformer* |
138.20 |
226.87 |
| CI-STHPAN |
78.44 |
126.35 |
| Ours |
14.89 |
21.42 |
FinD³在所有对比方法中推理速度最快,比次优的CI-STHPAN快五倍以上。这得益于其针对股票和特征维度保持线性复杂度的设计,并支持沿股票轴的并行计算,而许多基线模型需要顺序推理,处理3D-MTS数据更慢。
总结
本文提出了用于股票市场预测的FinD³模型,它创新性地融合了双立方状态空间模块(DCSSM) 与演化超图注意力模块(EHA),以全面捕获3D-MTS数据中复杂的时空表征。在两个真实金融数据集上的实验表明,FinD³在投资回报和风险调整后表现上均超越了现有基线方法,并且具有更高的推理效率与稳定性。
未来工作可以围绕以下几个方向展开:增强超图演化机制的适应性,融入新闻情绪、宏观经济指标等多源市场信息,以及探索该框架在金融领域之外的其他3D-MTS应用场景(如交通流量预测、多传感器监测等)中的适用性。对于希望深入研究 状态空间模型 和 图神经网络 在复杂预测任务中应用的朋友,可以在 云栈社区 找到更多相关的技术讨论与资源。
 发表于 2026-3-12 05:56:31
|
查看: 205|
回复: 0
发表于 2026-3-12 05:56:31
|
查看: 205|
回复: 0
