三月中旬,全球光通信行业的年度盛会 OFC 2026(光纤通信会议)在洛杉矶落下帷幕。这场盛会的重要性不言而喻,它正在清晰地展现一场由AI算力需求驱动的、深刻的光互连技术变革。
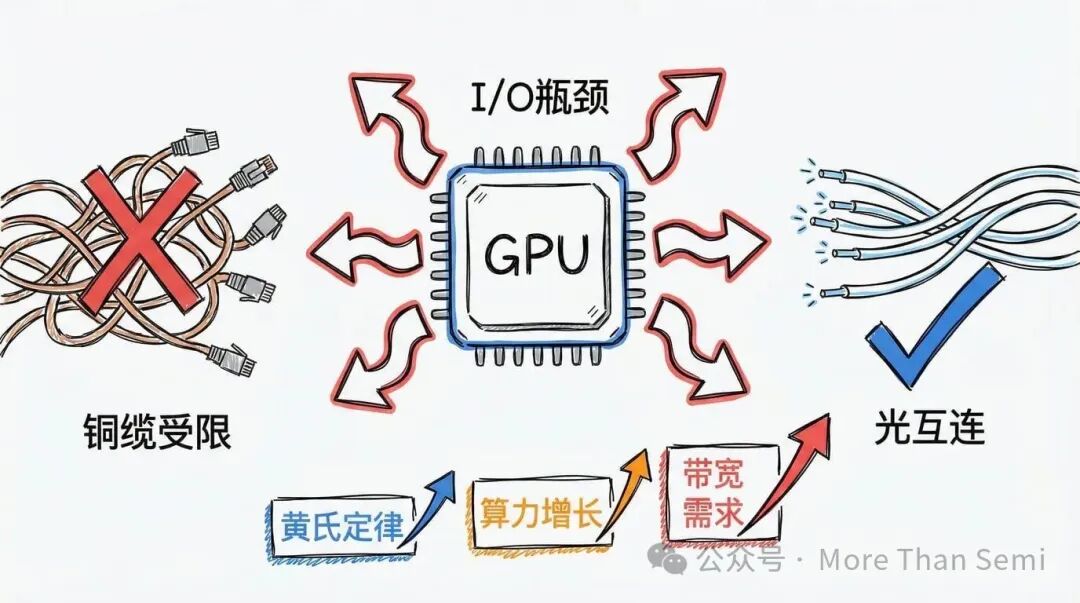
随着生成式AI模型参数量的爆炸式增长,数据中心面临的主要瓶颈已经悄然转移:从晶体管的纯粹算力,转向了芯片与芯片之间、机架与机架之间的互连带宽与延迟。英伟达CEO黄仁勋提出的“黄氏定律”也揭示了这一矛盾:计算能力可以通过先进制程和3D封装持续提升,但芯片间的I/O(输入/输出)速度却难以跟上,形成了阻碍性能增长的“I/O墙”。
这个问题究竟有多严重?传统的铜缆互连在速率达到200Gb/s量级时,其物理特性(如损耗、串扰)已成为硬性限制。在某些高密度场景下,甚至在单个服务器机架内部,铜缆都难以保证稳定传输。这迫使整个行业做出结构性的转变:光学器件必须前所未有地靠近计算核心与交换芯片,以从根本上减少信号损耗、降低功耗、突破距离限制。
光互连技术的三个演进阶段
数据中心的光互连技术正沿着一条清晰的路径演进,大致可分为三个阶段,每一阶段都在着力解决前一阶段的痛点。
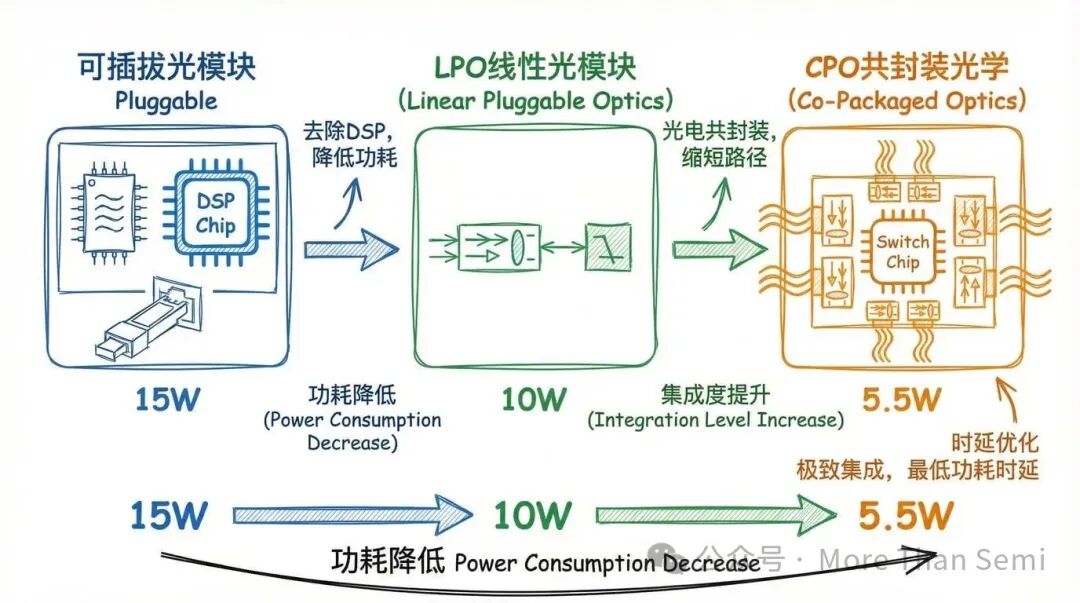
第一阶段:可插拔光模块(Pluggable Optics)
这是当前绝对的主流方案。可插拔光模块像一个独立的“黑盒子”,内部集成了DSP(数字信号处理器)来负责复杂的信号调理与补偿,优点是互操作性好,即插即用。但代价是更高的功耗和热密度——相当于每个模块都自带一个“小电脑”,自然会更耗电、更发热。
第二阶段:LPO(线性可插拔光模块)
LPO的核心思想是“做减法”,它移除了功耗大户DSP,转而依赖交换机或网卡侧的高质量SerDes(串行器/解串器)和线性驱动电路来直接处理信号,从而显著降低功耗和延迟。但这种方案对信道质量要求极为苛刻,需要更纯净的PCB设计、更严格的信号完整性预算,因此通常只能在可控的、同质化的部署环境(如单一厂商的AI集群)中使用。
第三阶段:CPO(共封装光学)
CPO代表了更激进的集成路线,它将光学引擎(如调制器、探测器)直接放置在交换芯片的封装基板附近,甚至共用同一个封装,通常由外置的激光器提供光源。根据Broadcom公布的数据,CPO方案在800G端口上的功耗可低至5.5W,而同等规格的可插拔模块则需要约15W,端口级功耗降低近3倍。
然而,CPO的大规模商用仍面临现实挑战。黄仁勋曾表示,虽然英伟达计划在2026年的网络交换芯片中引入光学技术,但将其更广泛地应用(尤其是更靠近GPU的位置)可能要到2028年之后。原因在于对可靠性、可维护性的顾虑,以及铜缆在短距离内已被验证的稳定性优势。
供应链的价值转移与激光器瓶颈
随着技术从“可插拔”走向“共封装”,整个产业链的价值重心也在发生迁移。
在可插拔时代,供应链角色清晰:光引擎、激光器、DSP、封装测试等环节分工明确。价值主要沉淀在光模块厂商和核心芯片供应商手中。
到了LPO时代,由于DSP被移除,价值开始向高质量的SerDes设计、信道工程和系统级协同设计转移。系统厂商需要建立更严格的互操作性标准。
进入CPO时代,封装、测试、激光器供应和光学组装成为了新的战略制高点。“电”与“光”的边界被模糊,协同设计与大规模测试成为关键卡点。
值得注意的是,硅光子技术的势头正在整个生态中加速。例如,意法半导体(STMicroelectronics)与AWS合作开发用于数据中心光模块的光子芯片,这标志着主流半导体巨头正深度切入光子学领域。
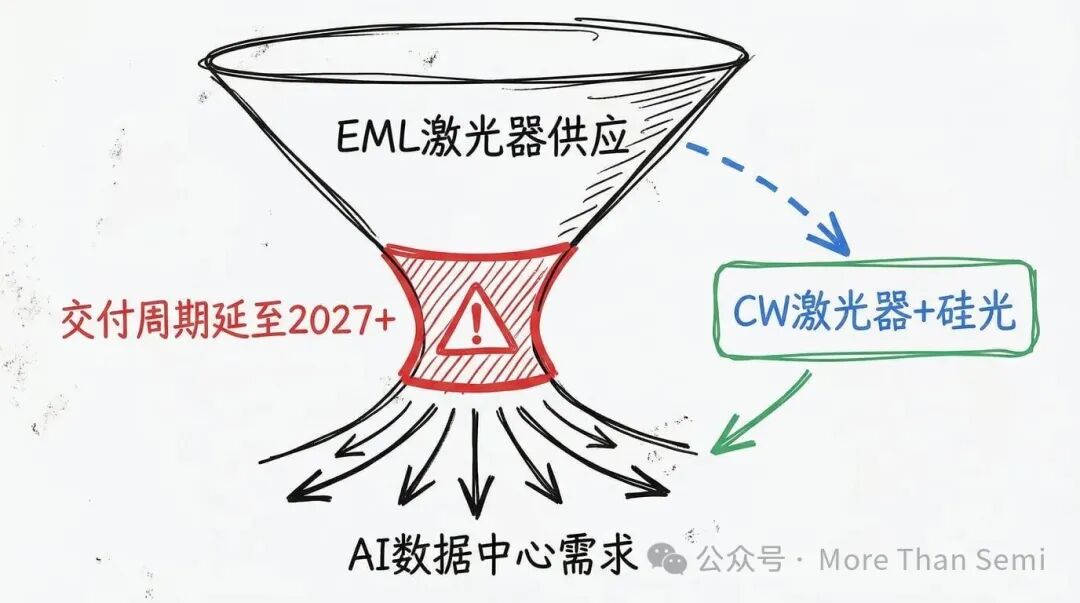
激光器供应:一个结构性的瓶颈
高端光模块(如800G/1.6T)及多数CPO方案,仍严重依赖EML(电吸收调制激光器)。EML将激光与调制功能集成,在超高速率下能提供优异的传输距离和信号完整性。
但问题在于:EML制造难度极高,全球供应商屈指可数。AI数据中心需求的井喷导致了严重的供应瓶颈。英伟达已锁定了关键EML供应商的大部分产能,交付周期被拉长至2027年以后,造成全球性短缺。Lumentum也承认EML供需持续失衡。
这种短缺正迫使超大规模数据中心和模块商加速寻找替代方案,特别是 外部连续波(CW)激光器 + 硅光子调制器 的组合,以期拓宽供应商来源。
为什么CPO推动“大功率CW激光器”成为焦点?
许多CPO架构采用外部激光器为多个共封装光引擎提供光源。由于需要克服光纤耦合、分路等带来的光功率损耗,行业正在推动CW激光器向数百毫瓦量级的高功率发展。
- Lumentum展示了高功率CW 1310nm DFB激光器,在50°C下封装模块的光纤输出功率达580mW。
- Coherent(相干)已提供样品,在55°C下输出超400mW的低噪声CW激光器,用于CPO/硅光子应用。
产能扩张与可靠性挑战
为缓解瓶颈并降低成本,行业正在向6英寸磷化铟(InP)晶圆制造迁移。Coherent宣布其6英寸InP平台可使每片晶圆的芯片数量增加约4倍,芯片成本降低超60%。高速EML、光电探测器和高功率CW激光器都正在该平台上进行认证。
然而,产能扩张仍受限于外延片供应、后段封装及测试老化等环节。TrendForce指出,CW激光器的生产也面临设备交付周期和劳动密集型可靠性测试的限制,未来可能面临自身的产能紧缩。
可靠性始终是光系统的生命线,尤其是在AI集群维护窗口极短的情况下。根据OCP全球峰会2025的信息,基于锗的光电二极管(Ge PD)被认为是光子系统中最脆弱的组件之一,对静电放电异常敏感。
CPO在改善可靠性的同时也引入了新挑战。它移除了现场可更换的模块,转向更早的晶圆级测试筛选,并可能简化热管理。但同时也带来了封装级的热机械应力、高密度下的光学连接可靠性等新问题。Broadcom与Meta公开的测试数据显示,CPO在累计100万个400G等效端口-小时中未出现单链路故障,光学功耗降低约65%。
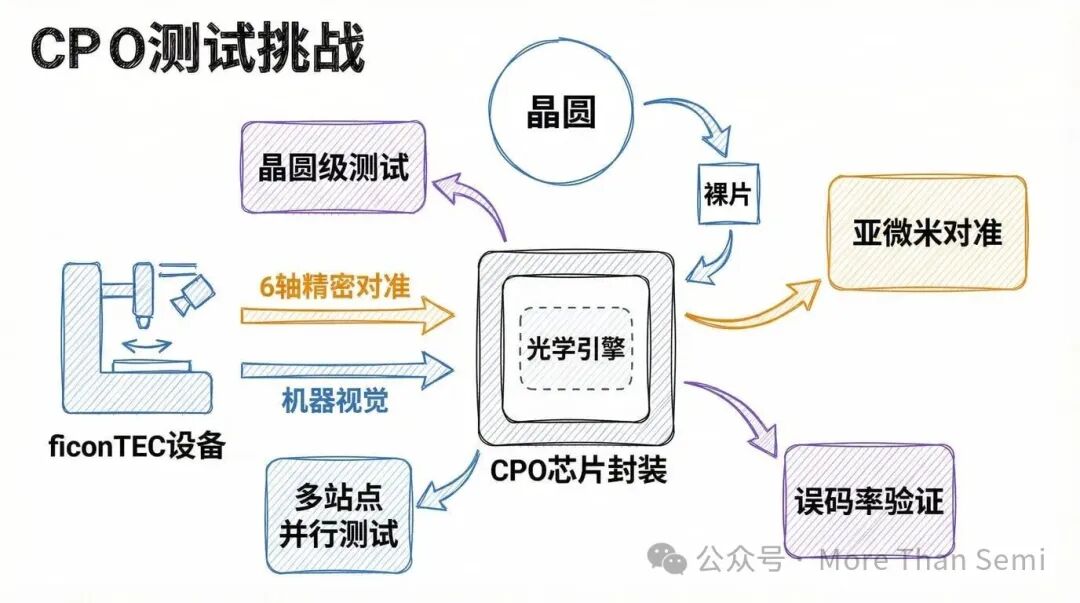
CPO测试:决定良率与成本的关键
共封装光学(CPO)将光引擎置于不可现场更换的位置,这使得测试、筛选和过程控制成为决定良率、可靠性及最终每比特成本的首要因素。
在可插拔时代,坏掉的模块可以轻松替换。但在CPO时代:
- 一个有缺陷的光学引擎可能导致整个昂贵封装件报废。
- 缺陷筛查必须提前到晶圆或芯片级,并且要全面(电、光、射频一体化测试)。
- 生产过程必须高度并行化(多站点测试),以防测试成本失控。
ficonTEC的领先优势
ficonTEC是该领域的核心玩家,其平台直击上述痛点:
- DLT-D1多站点芯片级测试仪:专为3D CPO光引擎设计,旨在将测试从实验室推向量产。它集成直流参数至全速率射频测试、底部光学主动对准与顶部电学探测,支持自动化物料处理和最多三个并行测试头,以降低单器件测试成本。
- 晶圆级电光测试单元:用于300mm晶圆的双面/单面探测,在一侧进行高速电学测试,另一侧进行六轴精密光学对准,填补“晶圆到芯片”的测试空白。
更重要的信号是,半导体测试巨头Teradyne宣布推出用于硅光子的大批量双面晶圆探针台,并与ficonTEC合作——这明确是由CPO需求驱动。这意味着CPO测试正在融入成熟的半导体ATE(自动测试设备)生态系统,而非停留在定制化实验阶段。
ficonTEC的核心优势在于机器视觉、六自由度精密对准与软件/AI优化。在光子学中,对准即良率。机器视觉辅助的对准降低了耦合损耗变异,在相同光功率下实现更优的误码率余量。早期端到端验证避免了后期昂贵报废,多站点并行测试则攻克了光子制造中最大的隐藏成本——测试时间。
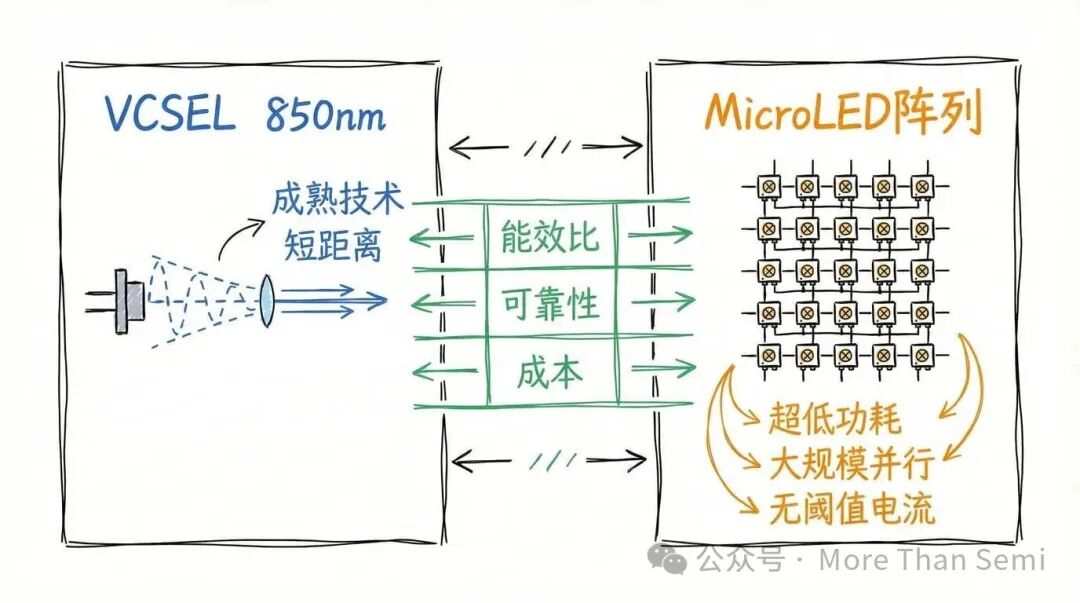
短距互连:VCSEL与MicroLED的角逐
VCSEL:成熟的短距离主力
850nm VCSEL(垂直腔面发射激光器)配合多模光纤,依然是短距离数据通信互连的主导方案,拥有成熟的产业链、出色的成本效益和合理的功耗。Broadcom的组件产品线也明确将850nm VCSEL定位用于高性能短距网络。
现实情况是,模块的差异化更多体现在SerDes质量、封装和热/信号完整性工程上,而非VCSEL本身。VCSEL技术成熟,这也意味着其成本曲线稳定,在无革命性替代方案出现前,地位难以撼动。
MicroLED:超短距离的潜力新星
MicroLED互连的吸引力在于,LED无需激光阈值电流,可通过大规模并行通道扩展带宽,有望在系统级实现更低的能耗。这与未来追求极致能效的AI和神经网络训练集群需求高度契合。
- 微软的MOSAIC方案:提出了“宽而慢”的设计哲学,即使用数百个低速MicroLED通道(如每个2Gb/s)而非几个超高速通道来构建高带宽链路(如20x20阵列实现800Gb/s)。论文报告称,相比铜缆,其架构功耗降低高达68%,传输距离提升约10倍。
- Avicena的LightBundle:该平台将MicroLED阵列与光电探测器(PD)阵列通过混合键合集成到CMOS芯片上。宣称其I/O密度超过1Tb/s/mm,传输距离大于10米,互连能效低于1pJ/bit。Avicena正与台积电合作优化硅基PD阵列。在SC25超算大会上,其演示链路在每通道4Gb/s、无前向纠错(FEC)的情况下,原始误码率达1×10⁻¹²,每个LED能耗约80fJ/bit。
MicroLED vs. VCSEL:拐点何在?
- VCSEL在成熟度、批量制造和已知可靠性上当前占优。
- MicroLED在通过无阈值电流和高度并行性实现超低能耗/比特方面潜力巨大。
关键风险在于:MicroLED互连的成功不仅取决于LED本身,更取决于阵列均匀性、键合良率、接收器灵敏度以及封装耦合——这再次印证了前面的观点,一旦光学器件进入封装/板级,测试与组装工具就具有了战略意义。2025年9月,Credo Technology收购了MicroLED光互连公司Hyperlume,正是为了布局这一新兴市场。
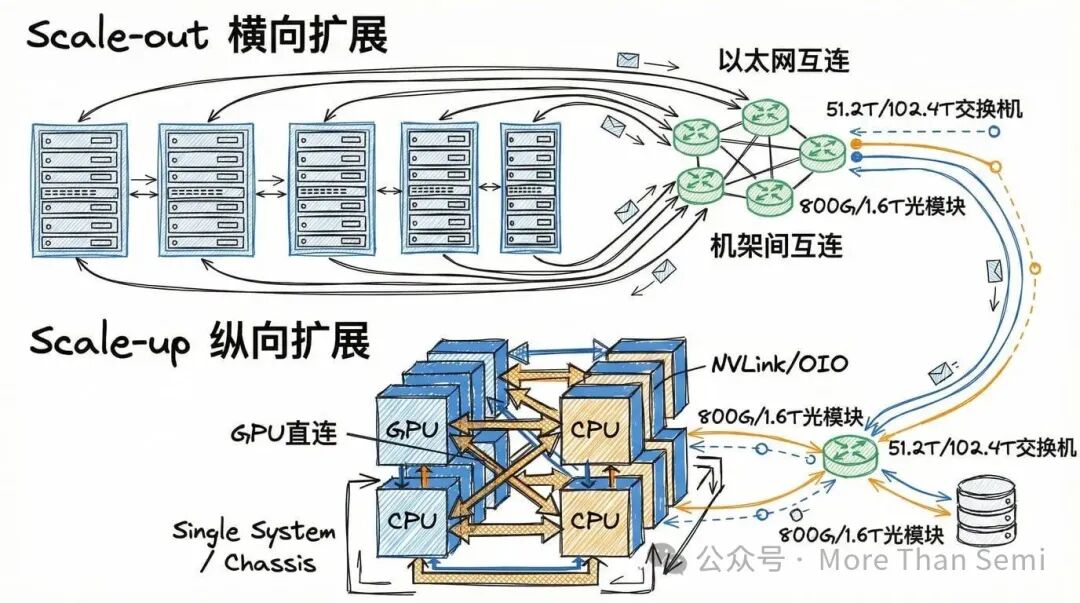
系统架构:Scale-out与Scale-up的需求分化
在横向扩展(Scale-out) 网络市场(机架间互连),英伟达、Broadcom、Marvell、思科等厂商正竞相推进51.2T到102.4T级的交换芯片与系统,以满足不断扩大的AI集群规模需求。例如,思科已发布其面向AI后端网络的Silicon One G300(102.4Tbps)芯片。
在纵向扩展(Scale-up) 领域(GPU间/节点内高带宽互连),行业则积极探索OIO/CPO式光学链路,以突破NVLink等铜缆互连在功耗和距离上的限制。Ayar Labs、Marvell、Lightmatter、英特尔等公司是该方向的活跃者,旨在将光互连推进至封装内部。
未来趋势:LPO/CPO/OIO路线图展望
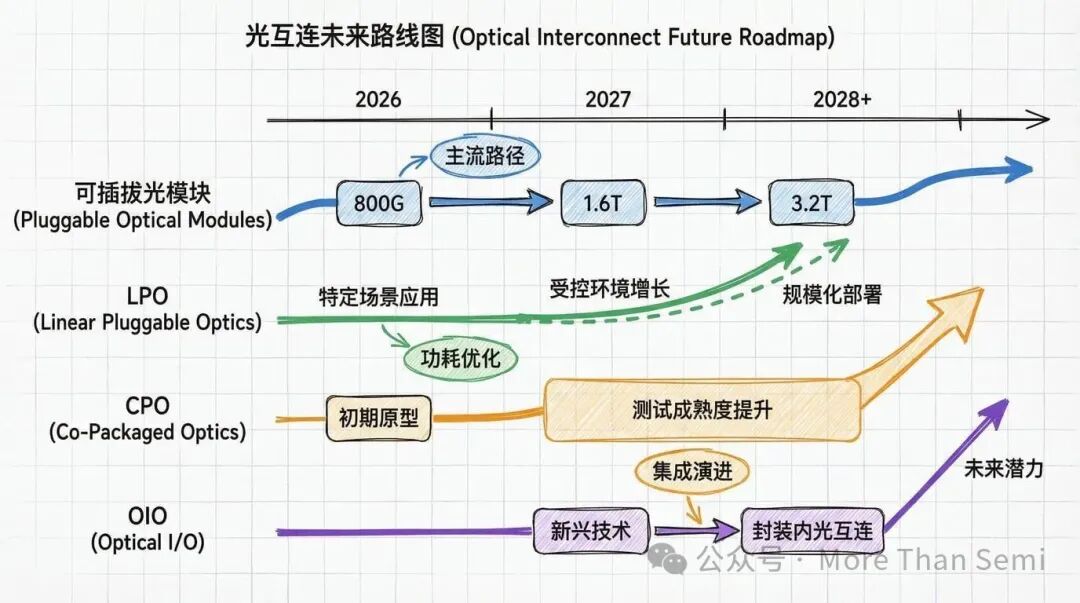
LPO:未来数年仍是重要市场
线性可插拔光学(LPO)通过去DSP化降低功耗和延迟,其发展往往与交换芯片SerDes世代同步(如200G/通道SerDes支撑1.6T光模块)。由于保留了可插拔的维护便利性,在许多对可维护性和供应链灵活性要求极高的超大规模数据中心中,它仍将是重要选择。
CPO:规模应用取决于测试与生态成熟度
CPO的大规模生产时间严重依赖于测试吞吐量和KGD(已知良品芯片)的供应。Broadcom的数据(800G端口功耗5.5W vs 可插拔15W)清晰地展示了其吸引力。预计在2026至2028年间,CPO将率先在交换机等对功耗密度敏感且外形可控的设备中应用,随后随着测试生态和可靠性数据完善而逐步扩展。
OIO:面向封装内互联与解耦架构
以Ayar Labs为代表的OIO(光学I/O)技术定位为“封装内”光学互连,旨在将高速光链路直接带到芯片边缘,实现与传输距离无关的带宽扩展。其TeraPHY光学I/O小芯片支持UCIe标准接口,宣称带宽可达8Tbps。OIO与内存解耦、大规模GPU池化等架构天然契合,但其采用取决于热管理、波长稳定性、封装集成及高通量测试等问题的解决。
写在最后
AI时代对算力互联的极致需求,正以前所未有的速度推动光技术向数据中心堆栈的更深层渗透。展望未来,几条技术路径将并行发展:
- 可插拔光模块凭借其可维护性和生态成熟度,在400G/800G乃至1.6T阶段仍是主流载体。
- LPO作为可插拔模块的“降功耗”优化路径,将在特定可控场景中持续增长。
- CPO则随着交换带宽向102.4T迈进和电气互连瓶颈凸显而吸引力倍增,其爬坡速度取决于测试能力与运维模式的接受度。
- OIO代表着更远期的、封装级的光互连愿景,与Chiplet、UCIe等先进封装生态深度绑定。
从产业链视角看,有几点趋势尤为关键:激光器供应链正在向6英寸InP平台重组以缓解瓶颈;测试设备(如ficonTEC)在CPO时代价值凸显;硅光子与III-V族材料的异构集成是技术主线;MicroLED作为超短距互连的颠覆者已获产业资本布局。
对于构建和关注AI基础设施的开发者与架构师而言,光互连已不再是一个边缘或纯硬件的话题,而是直接决定下一代AI系统性能上限与运营经济性的核心要素。OFC 2026所揭示的技术方向,很可能就是未来几年数据中心网络/系统架构演进的主旋律。想要持续追踪这类软硬件结合的前沿技术动态,不妨多关注像云栈社区这样的专业技术交流平台,那里汇聚了许多深入一线的实践讨论与资源分享。
 发表于 2026-3-12 07:51:53
|
查看: 320|
回复: 0
发表于 2026-3-12 07:51:53
|
查看: 320|
回复: 0
