一个交易员赚了300万美元,到底是因为他本人厉害,还是因为他坐的那个位置厉害?平台和个体能力孰轻孰重,这个经典的“椅子”与“人”的争论,如今在AI工程领域也找到了映射。
最近,AI工程师圈子里掀起了一场激烈的辩论。辩论的焦点是:驱动智能体(Agent)成功的关键,究竟是模型本身,还是包裹模型的工程框架?
一边是 Big Model 派,他们坚信模型的原始能力决定一切;另一边则是 Big Harness 派,他们认为巧妙设计的工程框架才是解锁模型潜力的钥匙。latent space 近日对两派的观点进行了梳理,这场辩论或许正指向AI应用开发的未来方向。
Big Model 派的观点:框架应如蝉翼,模型才是核心
Big Model 派的观点非常鲜明:框架(Harness)越薄越好,最好只是模型能力的一个简单出口。
Claude Code 的创始人 Boris Cherny 的表述相当直接:“我们的秘诀都在模型里,框架只是最薄的那层包装。我们写得不能再简单了,这就是最精简的东西。” 他们的开发哲学是围绕模型构建,甚至不惜每隔几周就重写一次框架代码,但核心目标始终不变——让模型发挥最大能力,减少框架带来的任何束缚。
OpenAI 的 Noam Brown 则从推理模型发展的角度给出了更激进的看法。他认为,随着推理模型的成熟,那些复杂的脚手架将变得多余。“你直接把问题给推理模型,它自己就能搞定。那些脚手架最终都会被更强大的模型替代。”
数据似乎也在支持这一派别。来自 METR(机器学习技术研究评估)的测试显示,像 Claude Code 和 Codex 这样的专用框架,在任务时间范围的测量上,其表现并未显著超越他们默认使用的基础脚手架。
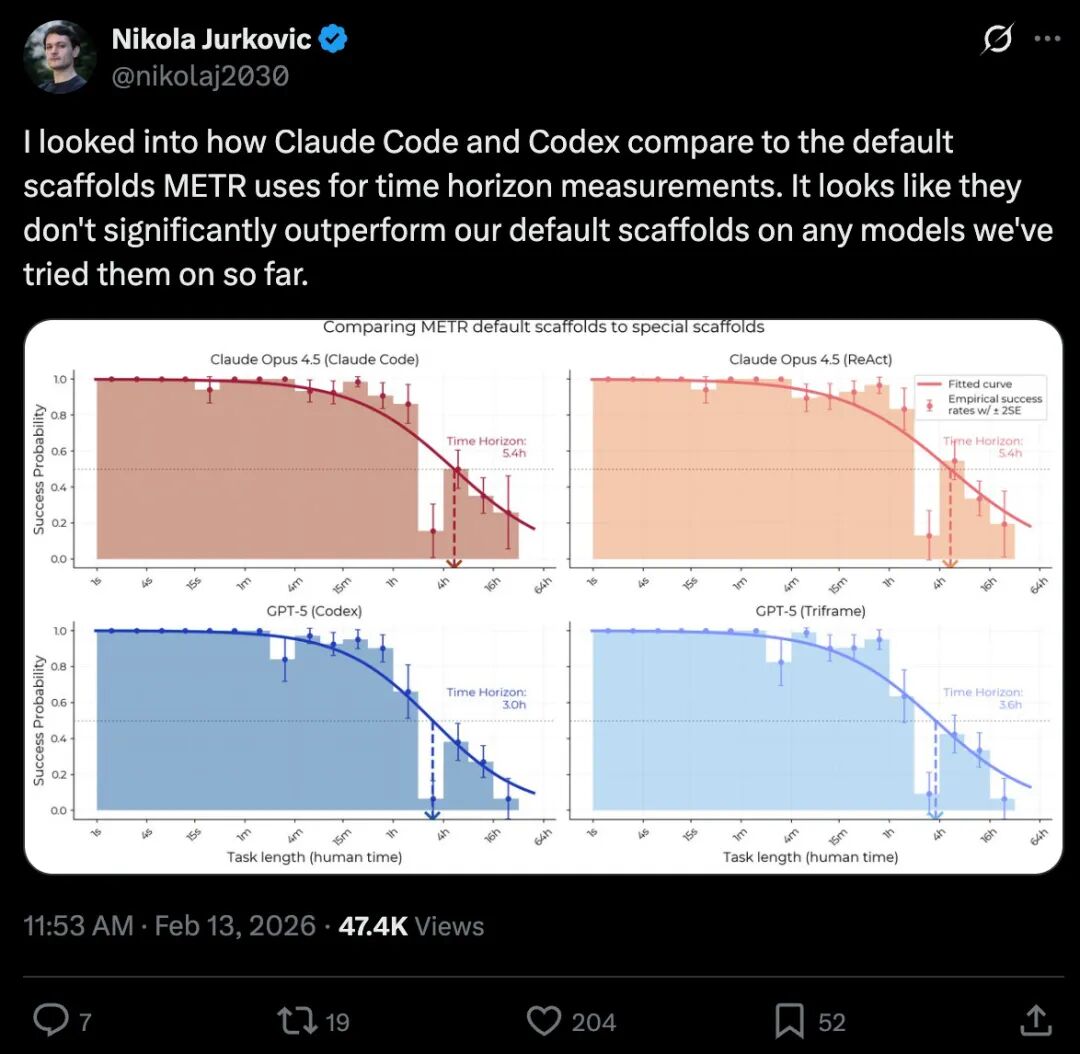
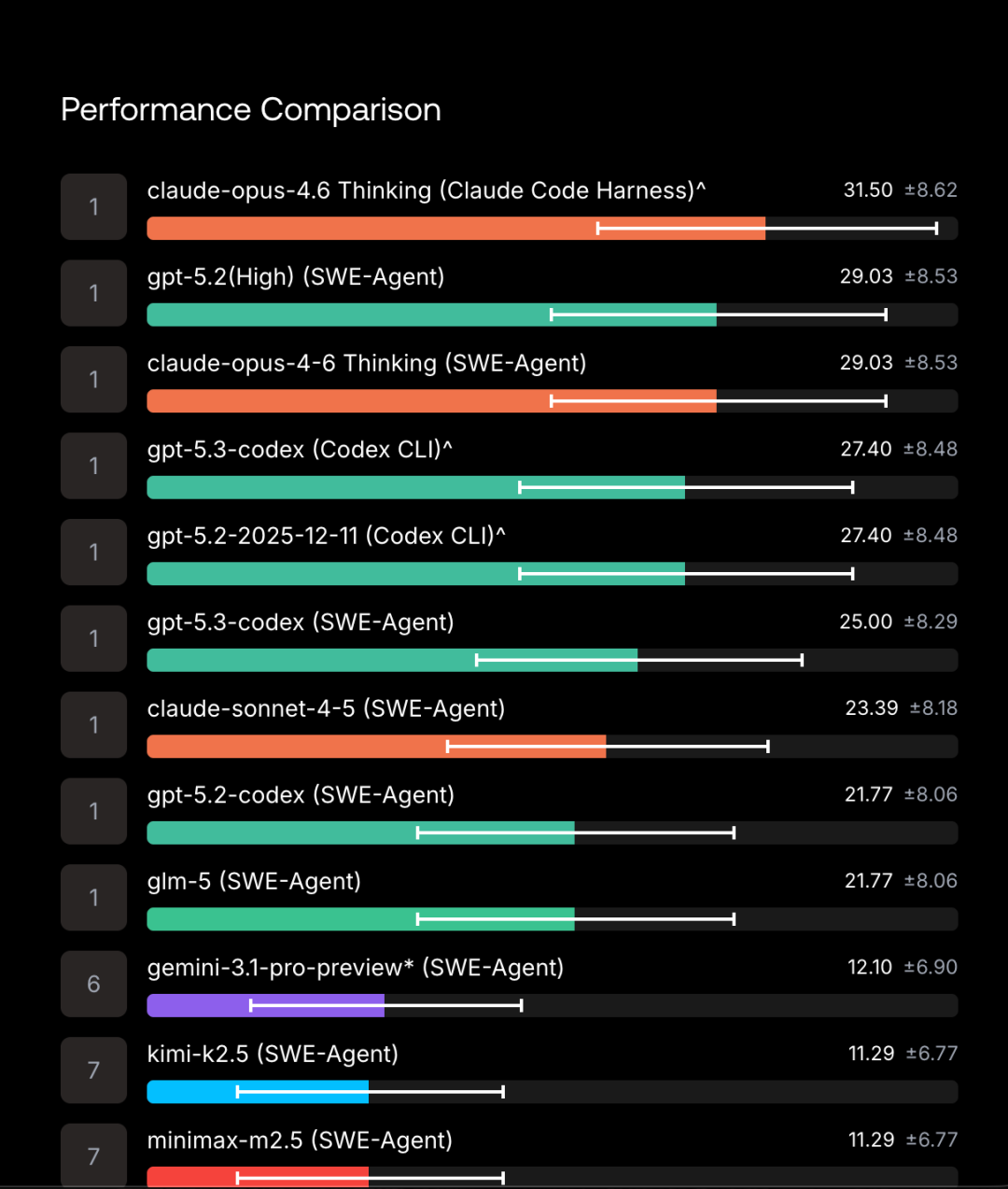
Scale AI 的 SWE-Atlas 基准测试也提供了有趣的发现:对于 Claude Opus 4.6 模型,使用 Claude Code 框架比使用通用的 SWE-Agent 框架平均高出2.5分;但对于 GPT-5.2 模型,情况却正好相反。整体来看,在统计误差范围内,为特定模型选择专用框架带来的提升可能并不显著。
Big Harness 派的反击:框架即产品,工程化是关键
Big Harness 派则提出了完全不同的视角。他们认为,框架本身就是产品的核心价值所在。一个设计精良的框架,决定了模型能力能被多大程度地、多可靠地释放。
从技术实现上看,每个生产级的智能体(Agent)都遵循一个核心循环,这个循环本身并不复杂:
while (模型返回工具调用):
执行工具 → 捕获结果 → 添加到上下文 → 再次调用模型
无论是 Claude Code、Cursor 的 Agent,还是 Manus 的架构,本质上都在这个循环内运作。那么,差异在哪?差异在于如何设计这个循环中的每一步:如何构建上下文(Context)、如何选择和管理工具(Tools)、如何定义停止条件、如何进行错误处理和状态管理。
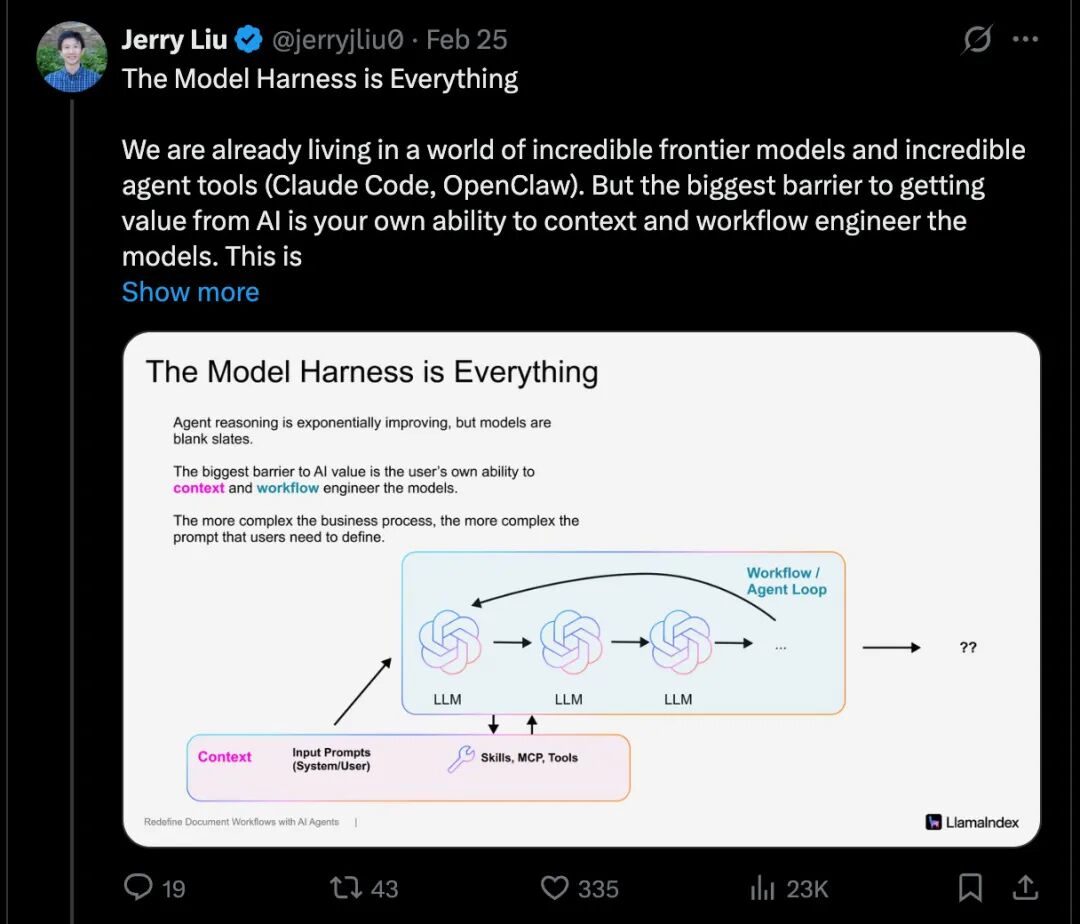
LlamaIndex 创始人 Jerry Liu 的观点更加犀利,他直言:“模型框架就是一切(The Model Harness is Everything)。从 AI 获取价值最大的障碍,就是你自己对模型进行上下文和工作流工程的能力。业务逻辑越复杂,这一点就越重要。”
更有说服力的证据来自实践。有开发者分享,仅通过一个下午对框架的优化,就让15个不同的大语言模型在编码任务上的能力都获得了显著提升——模型本身没有任何改变,变的只是调用它们的方式和流程。
当然,我们也要看到立场的差异:卖框架的自然会说框架重要,卖模型的则必然强调模型的核心地位。AI行业内部也一直有关于“复合AI系统”的讨论,试图告诉你两者都不可或缺。
但趋势似乎正在发生变化。随着 Agent Labs 等机构在理论上的探索得到市场验证(例如 Cursor 的高估值),业界不得不承认 “Harness Engineering” 确实创造着巨大价值。这一点甚至体现在了专业教育领域,AIE Europe 已经开设了 全球首个 Harness Engineering 专题课程。
小结:好马需配好鞍,但马也在进化
这场辩论虽然将观点推向了两个极端,但它清晰地揭示了一个核心矛盾。最终的答案很可能并非二选一,而是动态平衡。
从长远趋势看,大语言模型本身的能力无疑在持续增强。一些针对初级模型的、非常细节和刻板的框架设计(就像一步步教小学生做算术题),在面对越来越强大的“大学生”级别的模型时,自然会显得冗余和低效,逐渐消亡。
这不禁让人联想到工业革命以来的管理变革。过去,对于流水线上的工人,标准化、计时打卡等精细化管控能显著提升效率。但当面对知识型、创意型工作时,同样的强管控手段往往会适得其反。字节跳动提出的“Context, not Control”(提供上下文,而非控制)管理理念,正是这种适应性进化的体现。
对于 人工智能 的开发与应用也是如此。我们需要根据模型能力的进化阶段以及具体任务场景的差异,灵活调整“框架”的复杂度和侧重点。为强大的模型配备一个轻盈而智能的“鞍”,在提供必要引导的同时给予其足够的自主空间,或许才是最有意义的工程实践方向。
这场关于 Big Model 与 Big Harness 的讨论,不仅关乎技术选型,更关乎我们对 AI 能力本质的理解。如果你对这类深入的技术辩论和行业趋势分析感兴趣,欢迎到 云栈社区 的 智能 & 数据 & 云 板块继续交流探讨。
 发表于 2026-3-14 07:57:11
|
查看: 150|
回复: 0
发表于 2026-3-14 07:57:11
|
查看: 150|
回复: 0
