有段时间没写 SemiAnalysis 的报告了,之前的文章中我们就提到过一个观点:关于 AI 泡沫,其实有三个卡点:电力、内存和台积电的 CoWoS 产能。但从 SemiAnalysis 的最新报告来看,CoWoS 产能虽然紧张,但不是死结,前端晶圆产能才是更致命的问题。
这篇文章就来看看 SemiAnalysis 最新的分析:TSMC: King of Wafer Supply。

Anthropic 一个月赚了 60 亿美元,但他们想要更多
先说个数字:Anthropic 在今年 2 月,仅仅一个月时间,就新增了 60 亿美元的年度经常性收入。这是什么概念?主要靠的是他们的 Claude Code 这个 AI 编程工具。
“如果 Anthropic 有更多算力,他们本可以赚得更多。”
这不是客套话。现在整个行业都在疯狂找 GPU,连两代之前的 Hopper 显卡,按需租用价格还在涨。我们团队前段时间想找点小规模集群测试,问了一圈云服务商,全都锁死了,一台都租不到。
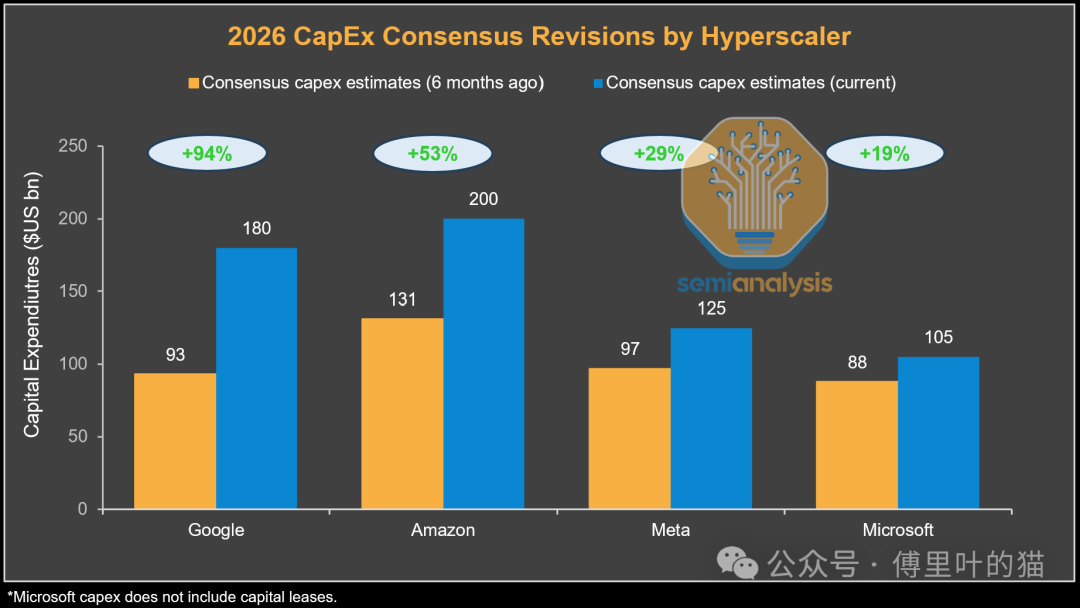
你看这些科技巨头的资本开支,都在往上飙。但他们自己都说,不是不想花更多钱,是根本买不到芯片。这背后是云计算基础设施军备竞赛的直接体现。
台积电的 3nm 产能,成了香饽饽
问题出在哪?核心就是台积电的 3nm 制程产能跟不上了。
今年是个特殊的年份,几乎所有主流 AI 芯片都在往 3nm 转。NVIDIA 的 Rubin、AMD 的 MI350X、Google 的 TPU v7、AWS 的 Trainium3、Meta 的 MTIA……全都盯上了台积电的 N3 产能。
这不是巧合。3nm 是目前最先进的量产制程之一,性能和能效都有明显提升。但问题是,台积电的产能规划明显没跟上这波AI算力需求。
说到 N3,其实在 AI 芯片大规模转向之前,这个产能主要是给消费电子用的。苹果的 iPhone 芯片、高通的骁龙 8 Elite 系列、联发科的天玑系列手机芯片,还有英特尔的 Lunar Lake 和 Arrow Lake 处理器,都在用 N3。
但 2026 年开始,游戏规则变了。AI 加速器开始大规模占领 N3 产线。
虽然史上最大规模的 AI 基础设施建设从 2022 年底就开始了,但台积电的资本开支直到 2025 年才超过历史峰值。这中间有两年多的时间差,产能扩张严重滞后。
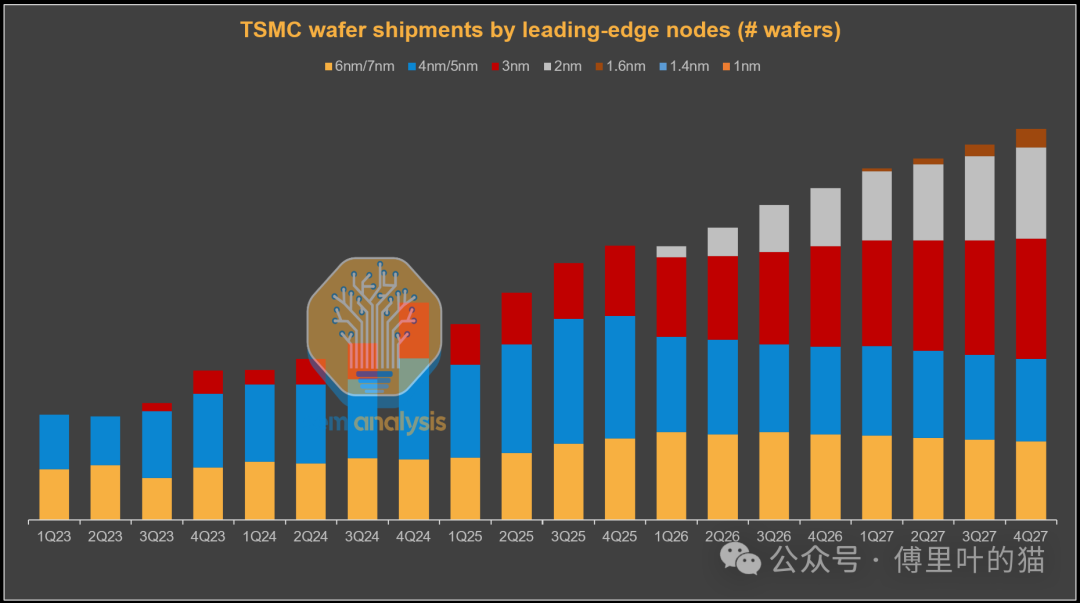
具体来看各家的转换路线:NVIDIA 从 Blackwell 的 4NP 制程跳到 Rubin 的 3NP,AMD 在 MI350X 上已经用上了 N3,MI400 的 AID 和 MID 芯片继续用 N3(只有 XCD 部分用 N2)。Google 的 TPU v7 全面转向 N3E,而且今年 TPU 的出货量会有巨大增长。AWS 的 Trainium3 用的是 N3P。
不只是加速器芯片本身,连带的其他组件也在抢 N3 产能。比如 VR 机架里用的 Vera CPU 用的是 N3P,NVLink 6 交换芯片也是,还有 Tomahawk 6 和 Spectrum 6 这些网络芯片。Rubin 每个 GPU 配 1.6T 的横向扩展网络,这带动了 3nm 工艺的 200G 光学 DSP 芯片的需求。
结果就是,今年 AI 相关的芯片需求会占掉台积电近 60% 的 3nm 产能,到明年这个数字会飙到 86%。手机芯片、PC 处理器,基本要被挤出去了。
苹果、高通、联发科这些传统大客户估计也很头疼。他们要么延长产品周期,要么直接跳到下一代制程,反正 3nm 是抢不过 AI 芯片厂商的。
台积电成了“造王者”
这种局面下,台积电实际上掌握了生杀大权。谁能拿到更多产能,谁就能出更多货,谁就能在 AI 军备竞赛中占优势。
为什么 AI 客户能优先拿到产能?原因很简单:
第一,AI 芯片 die 面积大、封装复杂,单价高得多。台积电当然愿意优先服务高价值客户。
第二,AI 需求有长期可见性。这些大厂都签了多年的算力采购合同,需求稳定。反观手机市场,早就饱和了,增长空间有限。
第三,也是最关键的——AI 客户真的愿意为算力付任何代价。
SemiAnalysis 还提到一个有意思的情况:如果手机需求下滑,释放出来的 N3 产能能做什么?假设把 2026 年 5% 的手机芯片 N3 晶圆(大约 22,000 片晶圆)转给 AI 加速器,可以多生产约 10 万片 Rubin GPU,或者 30 万片 TPU v7。如果是更极端的情况,转移 25% 的手机芯片产能(约 109,000 片晶圆),就能多造 70 万片 Rubin GPU 或 150 万片 TPU v7。
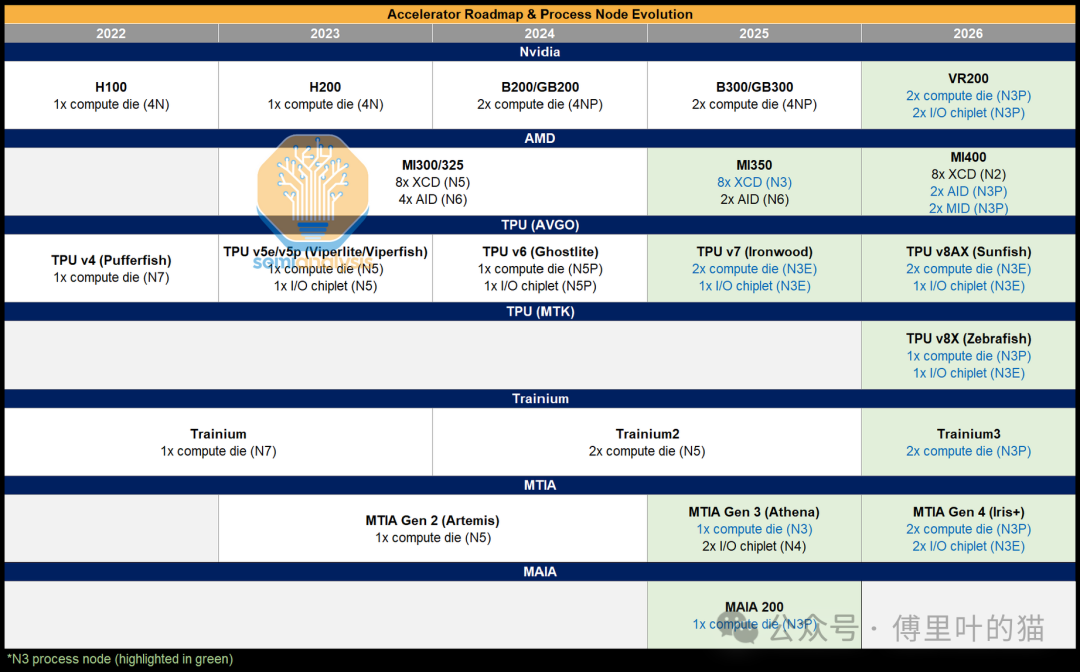
当然,有逻辑芯片还不够,你还得有内存和先进封装产能配套。但这个数字至少说明,消费电子市场的任何波动,都会直接影响 AI 芯片的供应。这也凸显了台积电在全球半导体产业链中的决定性地位。
内存也在告急,而且情况可能更糟
光有逻辑芯片还不够,AI 加速器还需要大量高带宽内存(HBM)。这又是另一个瓶颈。
HBM 的问题在于,它太“费”晶圆了。生产同样容量的内存,HBM 消耗的晶圆产能是普通 DDR 内存的 3 到 4 倍。随着行业从 HBM3E 转向 HBM4,这个差距可能会扩大到 4 倍,到 HBM4E 时代会更大。
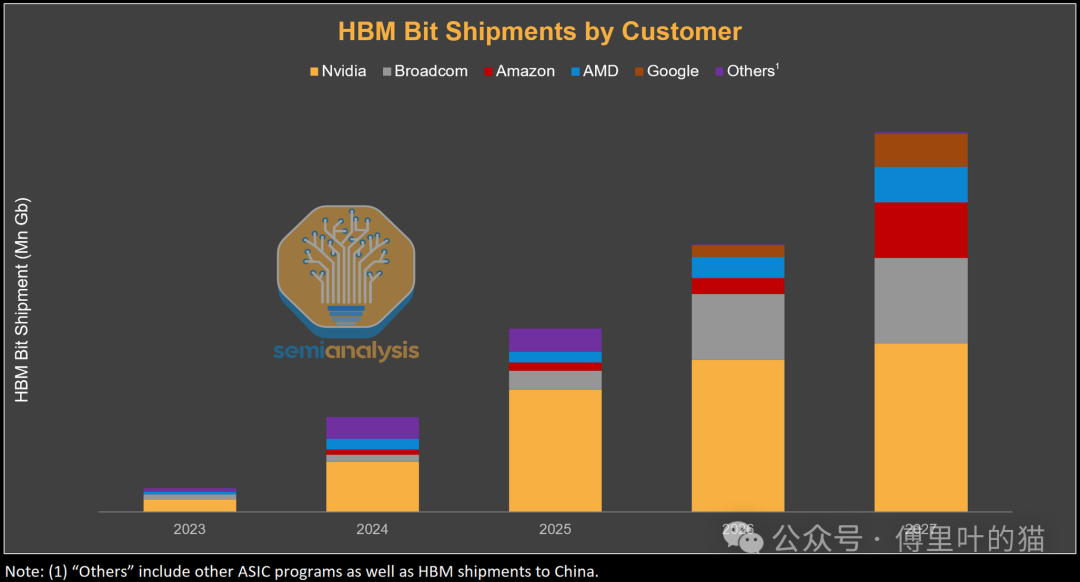
而且每一代 AI 芯片的 HBM 容量都在猛增。NVIDIA 从 Blackwell 到 Blackwell Ultra 再到 Rubin,HBM 容量增加 50%,到 Rubin Ultra 再翻 4 倍。其他厂商也在跟进:Google 的 TPU v8AX 和 AWS 的 Trainium3 都从上一代的 8-Hi 堆栈升级到 12-Hi,AMD 从 MI350 到 MI400 内存容量也增加了 50%。
HBM 位出货量的增长,主要不是因为设备数量增加,而是单个设备的内存容量在暴涨。
除了 HBM,服务器用的普通 DDR 内存需求也在增长。NVIDIA 下一代平台的系统内存会大幅增加,VR NVL72 机架每个 Vera CPU 配 1,536 GB DDR,是之前 Grace CPU 的 3 倍(之前是 512 GB)。
同时,整个云计算和企业服务器市场正在进入一个多年的更新换代周期,老旧的服务器需要替换。AI 工作负载,特别是数据暂存、编排和强化学习,也在推动 CPU 需求增长,CPU 和 GPU 的配比正在逐渐提高。
所以服务器 DRAM 的需求会持续走高,足以抵消手机、PC 和消费电子产品需求的疲软。
更麻烦的是,现在出现了一个微妙的价格倒挂现象。
以前 HBM 利润率高,内存厂商有动力扩产 HBM。但今年 DDR 价格涨得太猛,利润率已经快追上 HBM 了。这意味着内存厂商没那么大动力把产能从 DDR 转向 HBM。
如果 AI 客户想要更多 HBM,就得出更高的价格。明年的 HBM 价格谈判,估计会很激烈。
SemiAnalysis 还提到一个有意思的假设:如果消费电子需求暴跌 50%(比如手机销量腰斩),释放出来的 DRAM 产能大约是 55,390 百万 Gb,相当于 2026 年总 DRAM 需求的 14%。即使是 25% 的削减,也能释放约 27,690 百万 Gb,占总需求的 7%,几乎是今年 HBM 需求的 80%。
这不是没可能。内存价格涨上去,手机成本就上去,消费者需求就会下降。SemiAnalysis 已经看到迹象:智能手机需求预计会出现低两位数的同比下滑。随着手机需求走弱,相关的晶圆需求会被削减,从而释放出更多产能给 AI 加速器用。
这就是所谓的“位重新分配”——从消费应用转向服务器和 HBM。某种程度上,这是一种“市场自动调节”,只不过代价是消费电子行业要让路。
CoWoS 封装:紧张但不再是最大瓶颈
说到 AI 芯片生产,很多人可能还记得前两年 CoWoS 先进封装产能紧张的新闻。CoWoS 是台积电的 2.5D 封装技术,AI 加速器芯片都需要用它来把逻辑芯片和 HBM 封装在一起。
现在 CoWoS 虽然还是紧张,但已经不是最大的瓶颈了。原因很简单:台积电在规划 CoWoS 产能时,已经把 N3 前端晶圆的限制考虑进去了。如果没有前端晶圆供应支撑,过度投资 CoWoS 产能也没意义。
而且 CoWoS 还有其他选择。台积电之前就把部分 CoWoS 订单外包给日月光(ASE/SPIL)和 Amkor 这些封测厂。比如 NVIDIA 要给中国市场供应 H200 时,就找 Amkor 做封装。英特尔的 EMIB 2.5D 封装方案也是个选项,Trainium 和 TPU 都在不同程度上采用了这个技术。
所以封装虽然紧,但不是死结。真正的死结在前端晶圆产能。
台积电在拼命扩产,但还是不够
面对这种需求爆炸,台积电当然不会坐以待毙。他们正在全力扩张 N3 产能,想方设法从现有产线里榨出每一片晶圆。
但问题是,晶圆厂扩产不是一蹴而就的事。一条新产线从规划到投产,至少要两到三年。设备采购、工艺调试、良率爬坡,每一步都需要时间。
更关键的是,台积电显然低估了 AI 需求的增长速度。虽然 ChatGPT 发布后的 AI 基础设施建设从 2022 年底就开始了,但台积电的资本开支直到 2025 年才超过历史峰值。这意味着他们在 2023 年和 2024 年的投资力度不够,导致现在产能跟不上。
今年台积电会打破去年的资本开支纪录,因为他们终于意识到客户需求远远超出了他们的产能。但这些投资要转化成实际产能,还得等到 2027 年甚至更晚。
瓶颈转移:从电力到硅片
过去两年,大家讨论 AI 基础设施,焦点都在数据中心建设和电力供应上。怎么拉电网、怎么搞冷却、怎么快速建机房,这些都是热门话题。
但现在情况变了。
SemiAnalysis 指出,数据中心和电力供应的扩张速度,实际上已经超过了 AI 算力的增长速度。换句话说,我们现在有足够的电力和机房空间,但没有足够的芯片来填满它们。
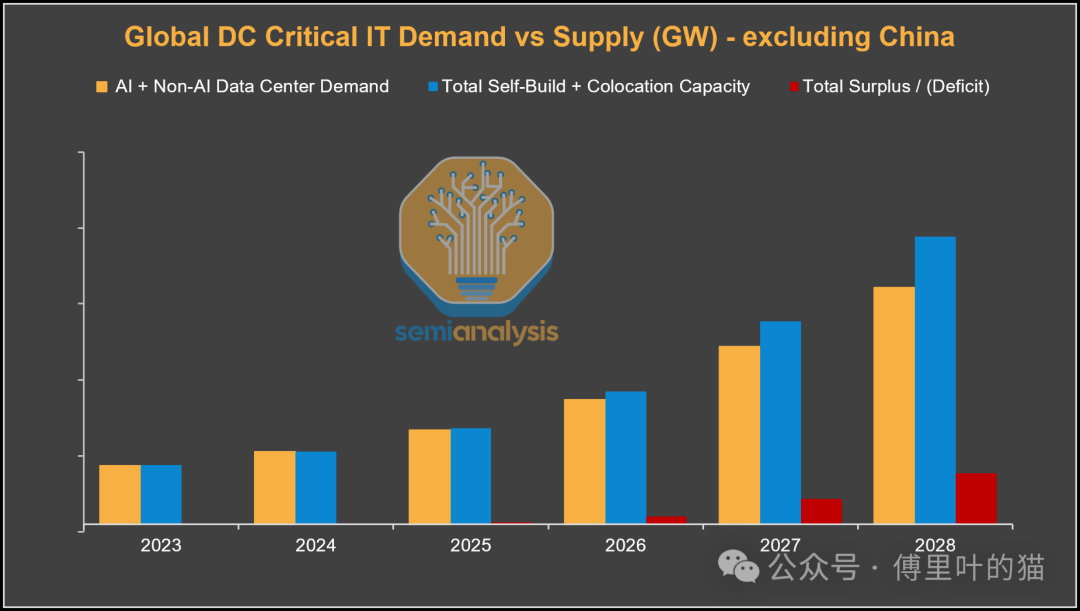
这是个结构性的转变。建数据中心、拉电网,虽然也不容易,但相对来说还是可控的。各种创新方案层出不穷,比如现场燃气发电。
但建晶圆厂?那完全是另一个量级的难度。一座先进制程晶圆厂,投资动辄上百亿美元,建设周期三到五年,还需要极其复杂的供应链配合。这不是短期内能解决的问题。
所以现在的局面就是:有电没芯片。
这个转变其实挺讽刺的。过去几年,整个行业都在想办法解决电力和数据中心问题,各种创新方案层出不穷。现场燃气发电、液冷技术、模块化数据中心……大家做得很成功。
但晶圆厂建设的速度,完全跟不上数据中心建设的速度。结果就是,我们现在有大把的机房空间和充足的电力供应,却没有足够的芯片来填满这些机架。
SemiAnalysis 的结论很明确:扩建数据中心和电力设施虽然也有难度,但相对来说是可以用人类智慧和工程能力解决的。但建晶圆厂?那是完全不同量级的挑战。投资规模、技术难度、供应链复杂度,都不是短期内能突破的。
NVIDIA:供应链战争的最大赢家
在这场供应链争夺战中,NVIDIA 显然是准备最充分的。
黄仁勋这两年频繁往亚洲跑,外界都以为他是去逛夜市、吃小吃。但 SemiAnalysis 揭示了另一面:2025 年他去韩国,主要目的是锁定内存供应。
NVIDIA 提前布局,锁定了大部分逻辑晶圆、内存和其他关键组件的供应。他们甚至帮客户争取到更便宜的 DRAM 价格,减轻客户的采购压力。这种供应链掌控能力,是 NVIDIA 最大的护城河。
Jensen 的韩国之行不是去吃烤肉那么简单。他是在为 NVIDIA 未来几年的内存供应做战略布局。这种前瞻性的供应链管理,让 NVIDIA 在这场硅片争夺战中占据了绝对优势。
现在业内关于“GPU vs 定制 ASIC”的争论很热。Anthropic 大量使用 Google 的 TPU 和 AWS 的 Trainium,很多人觉得定制芯片会是未来趋势。技术上看,定制 ASIC 在特定工作负载上确实可能更高效。
但 SemiAnalysis 的结论很直白:在算力稀缺的时代,谁能拿到最多硅片,谁就能部署最多算力。 技术路线的优劣,反而变成了次要因素。
这就是现实。AI 实验室现在的心态是:管它是 GPU 还是 ASIC,只要能用,先拿到手再说。算力供应不足的情况下,有货就是王道。NVIDIA 恰好在供应链控制上做得最好,所以他们会是最大的受益者。
今年的 AI 芯片格局会怎样?
基于 SemiAnalysis 的数据,我们可以看到一些有意思的趋势。
今年 N3 加速器晶圆需求会全年持续攀升。主要推动力是 NVIDIA 从 Blackwell(4NP)向 Rubin(3NP)的转换。不过 Blackwell 今年的出货量还是会高于 Rubin,因为平台和供应链更成熟。
Google 和 Broadcom 的 TPU 其实抢跑了,他们比 NVIDIA 和 Amazon 更早用上 N3。TPU v7 在 2025 年就开始生产了,今年出货量会大幅增长。这既有 Google 内部需求,也有外部客户的需求——Anthropic 就是大客户之一。同时,下一代 TPU v8 的各个变体也会开始生产,继续用 N3 节点。
AWS 的 Trainium3 是另一个重要变量。它从 2026 年初开始投片,下半年会有大规模产出。这是基于 N3P 的芯片,会占用相当一部分产能。
所以今年的 N3 产能分配,基本就是 NVIDIA、Google、AWS 这三家在主导,AMD 和 Meta 的份额相对小一些。
这对我们意味着什么?
SemiAnalysis 传递的信息很清晰:AI 产业已经进入“硅片短缺时代”,而且这个状态至少会持续到 2027 年。
对于 AI 公司来说,供应链管理能力变得和技术能力一样重要。你的模型再先进,没有算力来训练和部署,也只是纸上谈兵。这也解释了为什么 Anthropic 虽然技术很强,但在算力获取上还是要依赖 Google 和 AWS 的 ASIC。他们没有 NVIDIA 那样的供应链掌控力。
对于云服务商来说,这是个巨大的机会。AWS、Google、Azure 这些有自研芯片能力的厂商,可以通过直接跟台积电合作来获取产能。这也是为什么他们都在大力投资自研 ASIC 的原因——不只是为了性能优化,更是为了在供应链上获得更多话语权。
对于消费者来说,影响会更直接。手机、PC 的更新换代可能会放缓,或者价格会上涨。因为产能都被 AI 抢走了。SemiAnalysis 已经预测智能手机需求会出现低两位数的同比下滑,部分原因就是内存价格上涨推高了手机成本。
苹果、三星这些手机厂商可能会面临两难选择:要么接受更高的芯片成本,要么延长产品周期。iPhone 的年度更新传统,可能会受到挑战。
对于投资者来说,这份 SemiAnalysis 基本点明了几个方向:
- 关注供应链控制能力强的公司。在这个阶段,能拿到货比技术创新更重要。NVIDIA 显然是最大受益者。
- 关注内存厂商。三星、SK 海力士、美光这些 HBM 供应商,在未来几年会有很强的定价权。2027 年的 HBM 价格谈判,可能会出现大幅涨价。
- 关注台积电的竞争对手。虽然台积电现在一家独大,但这种极度紧张的供应状况,会给三星、英特尔这些追赶者创造机会。如果他们能在先进制程上缩小差距,就能分到一杯羹。
- 警惕消费电子板块。手机、PC 这些传统消费电子,在产能争夺中处于劣势。除非是苹果这种有超强议价能力的厂商,否则中小厂商会很难受。
一些更深层的思考
第一,AI 的发展速度已经超出了硬件供应链的承受能力。这不是说供应链做得不好,而是 AI 需求的增长太疯狂了。Anthropic 一个月增加 60 亿美元 ARR,这种增长速度在人类商业史上都是罕见的。
第二,硅片短缺可能会改变 AI 竞争的格局。以前大家比的是算法、模型架构、训练技巧。现在,谁能拿到更多芯片,谁就能训练更大的模型,部署更多的服务。这某种程度上是在“用钱砸”,但钱还不够,你还得有供应链关系。
第三,台积电的地位变得更加关键。他们现在不只是一个代工厂,而是 AI 产业的“造王者”。他们的产能分配决策,直接影响着 NVIDIA、Google、AMD、AWS 这些巨头的竞争力。这种权力集中,长期来看可能不是好事。
第四,消费电子和 AI 的资源争夺会越来越激烈。SemiAnalysis 提到的“位重新分配”,本质上是一场零和博弈。AI 多用一片晶圆,手机就少一片。这会带来一系列连锁反应:手机涨价 → 消费者需求下降 → 释放更多产能给 AI → AI 算力增加 → AI 应用更普及 → AI 需求进一步增长。这是个正反馈循环。
我们总觉得 AI 发展是软件和算法的竞赛,但到头来,还是要回到最基础的硬件制造能力上。台积电的一条产线,可能比任何一个大模型都更能决定 AI 产业的走向。
Jensen 说过一句话:“加速计算的时代已经到来。”但现在看来,更准确的说法可能是:“加速计算的时代已经到来,但硅片还没准备好。”
这或许就是所谓的“基础设施决定上层建筑”吧。在这场 AI 革命中,最终的赢家可能不是算法最好的公司,而是供应链控制最强的公司。对整个科技行业和开发者生态而言,理解这场供应链战争背后的逻辑,将比以往任何时候都更加重要。
 发表于 2026-3-15 12:52:30
|
查看: 189|
回复: 0
发表于 2026-3-15 12:52:30
|
查看: 189|
回复: 0
