现在一谈到大模型训练,大家第一反应就是算力不够,得堆更多更猛的核心。但说实话,当下 AI 加速器的性能瓶颈,早已不是计算单元本身,而是内存子系统和互联架构。它们正悄悄决定着一块芯片的真实战斗力。
1. 先理清谱系:AI加速器是如何一路演进过来的
AI 硬件的发展路径其实相当清晰,遵循着一条从“通用”迈向“专用”的轨迹。
最早大家都用 CPU 跑 AI。CPU 天生为灵活处理各种逻辑任务而生,但面对大模型所需的海量并行矩阵运算,它的架构就显得格格不入了,效率非常低。
紧接着 GPU 站上了舞台中央。GPU 本来是为图形渲染设计的,骨子里就带着几千个简单核心做大规模并行的基因,恰好踩中了 AI 训练的节拍。再加上 CUDA 这套极其成熟的软件生态加持,直到今天它依然是大模型训练场的绝对主力。
再往后,专用 AI 加速器开始群雄逐鹿:谷歌推出了 TPU,苹果、华为等厂商纷纷自研 NPU。它们的共同思路,就是把 AI 场景下最高频的矩阵乘法、卷积等运算直接固化到硅片里,死磕吞吐量和能效比。甚至出现了像 Cerebras 那样“丧心病狂”的方案——把一整块硅晶圆直接做成一颗芯片。

AI 加速器从通用 CPU 到专用晶圆级芯片的进化路线
发展到今天,业内通常将 AI 加速器归为五大流派:
- 通用 GPU:浮点吞吐能力猛,编程又灵活,训练、推理通吃,仍是当下市场的绝对主力。
- TPU 类定制 ASIC:专为张量运算优化,利用脉动阵列和低精度计算换取极高能效,多部署在云端数据中心。
- NPU:为端侧和移动设备量身打造,主打低功耗推理,你手机里的 AI 引擎基本都属此类。
- 定制化 ASIC:路线更极致的专用方案,涵盖存内计算芯片、可重配置数据流单元、晶圆级引擎等。
- FPGA:可重构是其灵魂,非常适合模型快速迭代,只是峰值吞吐量拼不过 ASIC 和 GPU。
从市场趋势来看,GPU 靠着完善的生态依然在训练市场占据统治地位,但 ASIC 和 NPU 在推理与端侧场景中的存在感正变得越来越强。尤其随着大模型体量急速膨胀,业界对更高内存带宽、更低延迟、更高能效的饥渴感,正倒逼着内存和互联架构飞速迭代。
2. 核心矛盾:那道越来越宽的“内存墙”
什么叫内存墙?
简单讲,就是处理器的算力增长速度,始终远远甩开内存带宽的增长速度。两者之间的鸿沟越来越大,数据困在存储器里根本来不及喂给计算单元。这样一来,计算核心再多,也只能干瞪眼,空转等待。这才是 AI 加速器目前最大的性能瓶颈。
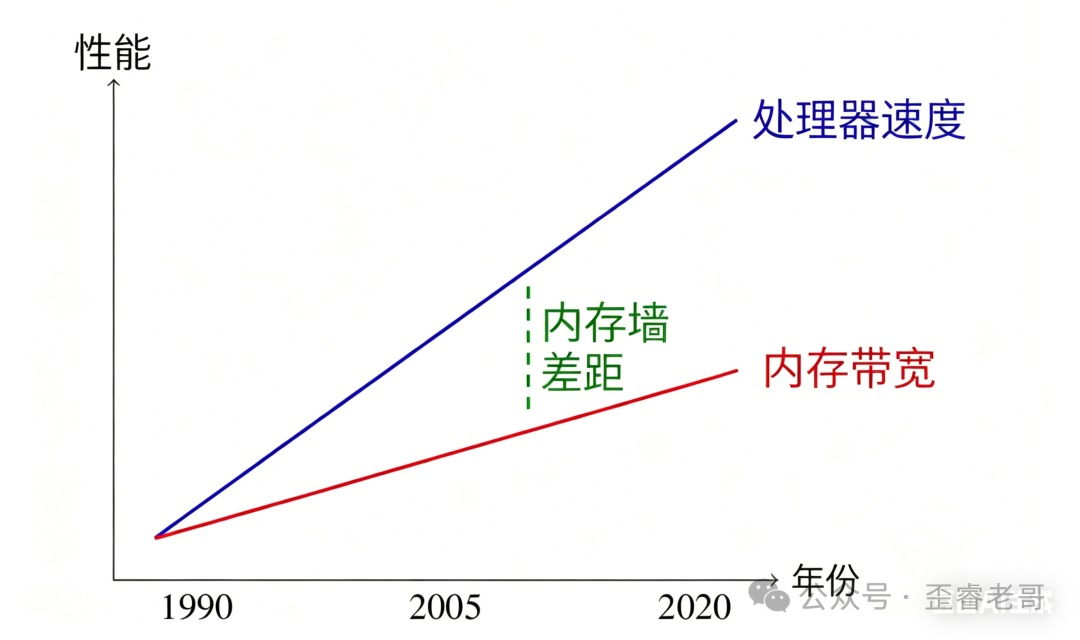
内存墙:处理器速度与内存带宽之间的鸿沟随时间持续拉大
为了填补这道要命的“内存墙”,如今的 AI 加速器在内存和互联上可谓绞尽脑汁,搞出了一系列创新:HBM、NoC、3D 堆叠、近存/存内计算,乃至多芯片互联(Chiplet)等等。我们来逐个拆解。
高带宽内存 HBM:已成 AI 加速器的标配
HBM 的本质,就是把内存颗粒垂直摞起来,利用硅通孔(TSV)技术将每一层紧密连接,再与计算芯片做贴身集成。
这种 3D 堆叠的方式,极大缩短了数据传输的物理路径,比起传统的 DDR、GDDR,不仅带宽高出一大截,功耗也更低。
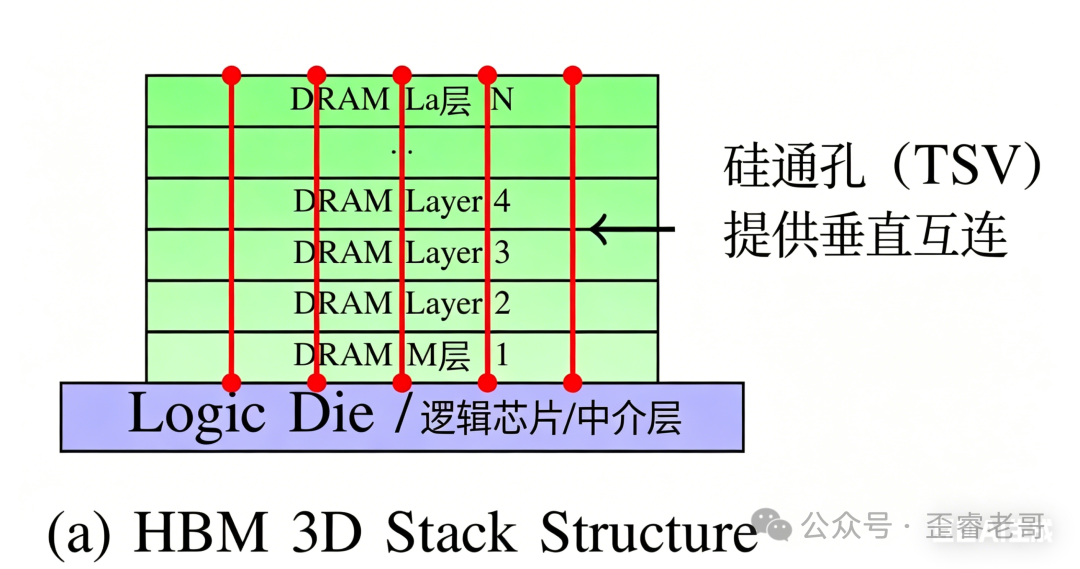
HBM 的 3D 堆叠结构:多层 DRAM 通过 TSV 与底层逻辑芯片相连
HBM 已经迭代了多代,参数跃升非常明显:

目前最新的 HBM3E 已实现单堆栈超过 1.2TB/s 的带宽,而 HBM4 更将接口位宽直接翻倍,能跑出 2TB/s 的单堆栈带宽,并已应用于最新一代的 AI 加速卡上。
当然,HBM 也并非完美无瑕:3D 堆叠密度太高导致散热困难,制造工艺极其复杂,成本自然也远高于传统内存。要用好 HBM,还需要 CoWoS、InFO 这类先进封装技术的默契配合,对供应链的要求相当严苛。
片上网络 NoC:千军万马如何统一调度
当前 AI 加速器动辄集成几十万甚至上百万个计算单元,这些核心之间如何高效通信?靠的就是片上网络 NoC。
主流的 NoC 拓扑结构包含几种:网状(Mesh)、环面(Torus)和分层(Hierarchical)结构,通常会搭配模块化的“拼砖”式设计,以便灵活地放大芯片规模。
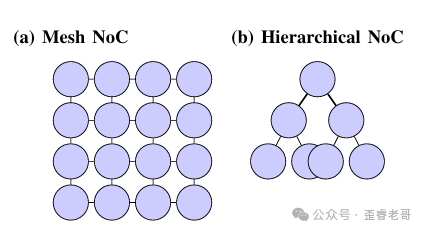
AI 加速器常用的两种 NoC 拓扑:左侧为 2D 网状,右侧为分层拓扑
网状拓扑配合模块化 tile 的好处是设计规整、易于扩展,还能实现精细化动态功耗管理:空闲的 tile 可直接断电,能省下不少功耗。
但缺点也很直接:芯片做大后,两个远端核心通信要跨越很多跳,延迟会随之飙升。而分层或混合拓扑正是为了解决这个痛点,通过优化局部通信、减少全局通信的频次来降低开销,当然,设计复杂度也会水涨船高。
值得一提的是,新兴的 Chiplet 架构已将 NoC 的概念外延到了芯片之间,利用 UCIe 这类开放标准,实现芯粒间的高带宽互联,这个我们后面再细聊。
3D 堆叠计算:从堆内存走向堆算力
3D 堆叠不仅能用在内存上,还能将多个计算芯片垂直集成,通过 TSV 实现超高密度的垂直互联,能提供超过 1TB/s 的互联带宽,远超传统方案。
目前主流的 3D 集成方案有三种:
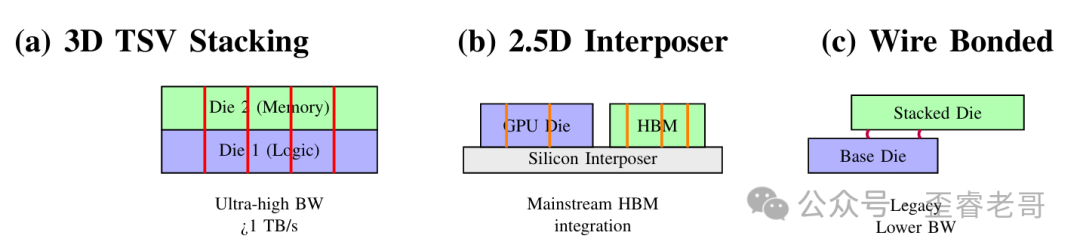
三种常见的 3D 集成方案对比:3D TSV 堆叠、2.5D 中介层、引线键合堆叠
- 3D TSV 堆叠:芯片直接面对面堆叠,用 TSV 垂直连接,带宽最高,但散热和良率问题也最棘手。
- 2.5D 硅中介层:将多颗芯片(比如 GPU 和 HBM)并排放置在硅中介层上,靠中介层内的高密度走线互联。这是目前 HBM 搭档 GPU 的绝对主流方案,NVIDIA 的 A100、H100 都是这么做的。
- 引线键合堆叠:芯片堆叠后利用导线连接,带宽低、延迟高,在先进 GPU 领域已基本被淘汰。
总的来看,3D 堆叠能带来更高的带宽和更紧凑的尺寸,但代价是设计更复杂、成本飙升、散热挑战巨大。行业正在积极探索微流道散热、背面供电等新技术来应对这些难题。
近存计算与存内计算:把算力搬到数据家门口
解决数据移动能耗问题,最直接的思路就是让计算去“找”数据,而不是让海量数据长途跋涉去“找”计算。这里分出了两条路径:近存计算(NMC)和存内计算(IMC)。
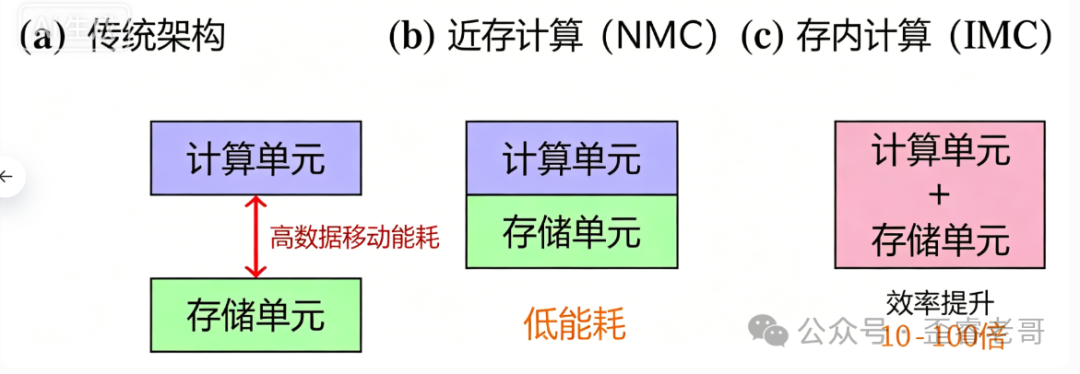
三种架构对比:从传统分离式,到近存计算,再到存内计算
近存计算就是把计算单元摆在内存旁边,例如在 HBM 的逻辑芯片里集成计算单元。这样能以较成熟的技术拿到高带宽、低延迟的好处,目前已有商用产品落地。
存内计算则更激进,直接在内存单元内部执行计算。比如利用 SRAM 或新型非易失性存储器,在原位完成矩阵向量乘法,能效比可达传统设计的 10 到 100 倍。但存内计算目前仍面临精度、扩展性以及与数字逻辑协同设计等多重挑战,距离大规模商用还有一段路要走。
多芯片互联:Chiplet 时代的高速公路
如今,将多个小芯片(Chiplet)集成在同一封装内已成为主流范式,封装内的互联技术自然成了胜负手。
目前几种主流方案包括:提供高密度布线的硅中介层,适用于 2.5D 集成;成本更优的再分布层(RDL)中介层,能保持不错的带宽和信号完整性;此外,还有 UCIe 这类开放标准,以及 NVLink、Infinity Fabric 等私有协议,它们的目标都是实现 Chiplet 之间的高速、低延迟通信。
眼下,RDL 中介层和 UCIe 等开放标准正日益升温,因为它们制造难度相对较低,生态支持好,能让更多公司参与到 Chiplet 方案的创新中来。
3. 全新分类框架:从内存和互联重新审视加速器
以往我们给 AI 加速器分类,习惯盯着计算架构(SIMD 还是脉动阵列)、应用场景(训练还是推理)或者芯片类型(GPU/TPU/NPU)。
但现在,内存和互联已经实质性地决定了 AI 加速器的最终性能。因此,一个全新的三维分类框架应运而生,它的三个坐标轴分别是:
- 内存架构:涵盖内存的层次、带宽以及与计算的距离,例如片外传统显存、HBM、近存、存内等。
- 互联拓扑:指片上和封装内网络的结构与可扩展性,如总线、网状、分层、Chiplet 互联、晶圆级互联等。
- 集成策略:描述计算与内存在物理上是如何结合的,比如单芯片、2.5D 中介层、3D 堆叠、晶圆级集成等。
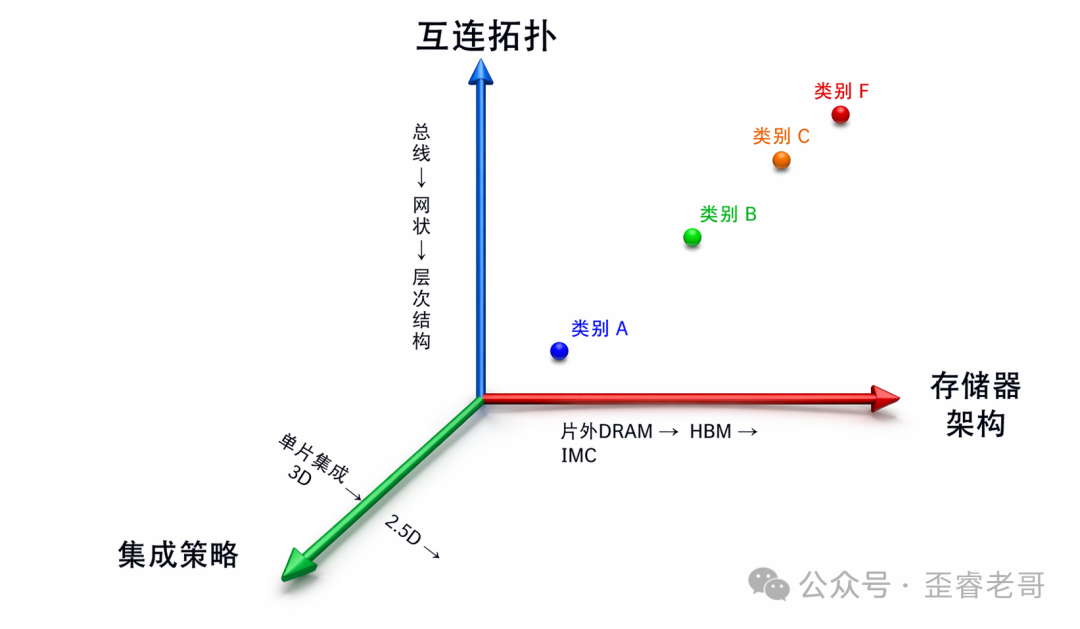
AI 加速器三维分类框架示意图
基于这个框架,我们可以将所有 AI 加速器清晰划分为六大类:
| 类别 |
内存架构 |
互联拓扑 |
集成策略 |
典型例子 |
| A 类 |
片外 DRAM(DDR/GDDR) |
总线 / PCIe |
单片 SoC |
早期 GPU |
| B 类 |
2.5D HBM(TSV) |
网状 NoC |
中介层集成 |
NVIDIA H100、AMD MI300 |
| C 类 |
3D 堆叠 HBM / 近存计算 |
分层 NoC |
3D TSV 堆叠 |
新一代近存加速芯片 |
| D 类 |
存内计算 |
Tile 分片 NoC |
单片 / Chiplet |
存内计算 AI 芯片 |
| E 类 |
Chiplet |
UCIe / 定制互联 |
多芯片封装 |
新一代 Chiplet AI 加速器 |
| F 类 |
晶圆级 SRAM / 近存 |
晶圆级网状 NoC |
晶圆级集成 |
Cerebras WSE |
不同类别的权衡取舍 (trade-off) 非常清晰:
- A 类受限于低带宽和差扩展性,内存读写已成为系统瓶颈。
- B 类是当下的主流,带宽高、能效好、扩展性也不俗,只是面积效率一般。
- C 类比 B 类带宽和能效更优,扩展性与之持平。
- D 类拥有极端高的局部带宽和最佳能效,但现阶段扩展性是个短板。
- E 类在带宽、能效、面积效率和扩展性上都表现均衡,尤其是扩展性最佳,代表了未来的演进方向。
- F 类的带宽高得离谱,扩展性不受制约,能效也很好,但面积效率极低,成本更是天文数字。
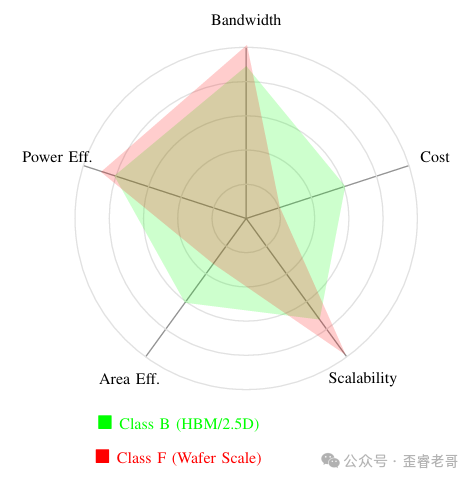
B 类 HBM GPU 与 F 类晶圆级加速器的多维 trade-off 对比
这个分类框架的核心价值在于,它将过去大家聚焦的计算核心放到次要位置,转而抓住当前 AI 加速器最底层的核心矛盾——内存与互联。无论是做学术研究还是产品规划,都能借此更清晰地对比不同设计,选准技术航向。
4. 极端案例:Cerebras 晶圆级引擎强在哪?
Cerebras 的 WSE 晶圆级引擎是 F 类的典型代表,它的设计思路与传统 GPU 大相径庭。
最新的 WSE-3 采用台积电 5nm 工艺,规格极其夸张:4 万亿晶体管、90 万个 AI 优化核心、44GB 片上 SRAM,内存带宽高达 21PB/s,FP16 峰值算力达 125PFLOPS,可原生支持高达 24 万亿参数的超大模型。
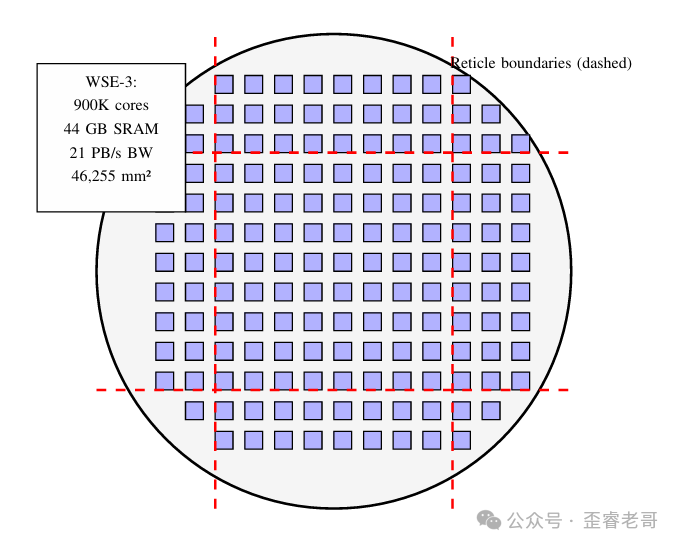
Cerebras WSE-3 晶圆级架构:整片晶圆即一个芯片,网状互联跨越所有光罩边界
它在内存和互联上的创新非常独到:
- 首先,在整个晶圆上构建了一张全覆盖的 2D 网状 NoC,将原本用于切割芯片的划片槽改造成了跨光罩的通信线路,实现了全晶圆所有核心的无缝互联,兼具低延迟和高带宽。
- 其次,采用计算与内存分离的架构。与传统 GPU 将计算与 HBM 紧耦合不同,WSE 将计算置于晶圆之上,而将内存放在外部的 MemoryX 模块中,使得内存容量可以独立扩展,非常适合承载巨型模型。
- 第三,通过层间流水线执行,即整个晶圆一次集中处理模型的一层,处理完毕再流向下一层。这最大化利用了数据局部性,显著减少了同步开销。
我们拿它与 H100、B200 做个参数对比,差异一目了然:
| 参数 |
WSE-3 |
H100 SXM |
B200 |
| 芯片面积 |
46,255 mm² |
814 mm² |
≈1,600 mm² |
| 计算单元 |
90 万 AI 核心 |
132 SM / 16,896 CUDA 核心 |
— |
| 片上内存 |
44 GB |
50 MB |
— |
| 内存带宽 |
21 PB/s |
3 TB/s |
8 TB/s |
| FP8 算力 |
250 PFLOPS |
64 PFLOPS |
216 PFLOPS |
| 系统功耗 |
23 kW |
700 W |
1,000 W |
| 系统价格 |
200~300 万美元 |
2.5~3 万美元 |
4~5 万美元 |
能够看到,WSE-3 的内存带宽比主流 GPU 高出好几个数量级,能处理超大模型而无需过度切分,效率极高。但它的短板同样突出:制造难度巨大,成本奇高,功耗惊人,注定了它只适用于极少数特定场景,难以普及。
5. 未来航向:AI加速器将驶向何方?
展望 2030 年,几个关键技术方向的发展节奏已十分清晰:
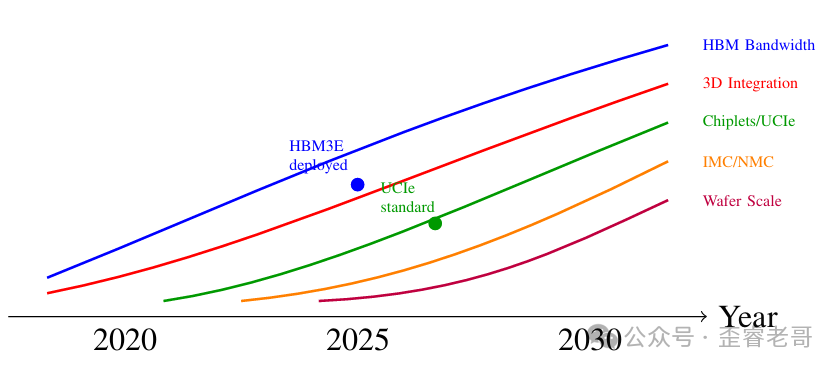
AI 加速器关键技术到 2030 年的进化趋势预测
第一,Chiplet 架构会加速普及。开放的 UCIe 标准已经成熟,它能实现多厂商异构集成,提高良率并增强供应链韧性,正逐步蚕食传统单芯片设计的固有地盘。
第二,先进封装将持续进化。RDL 中介层、混合键合、3D 堆叠等技术,会继续推高集成度、带宽和供电效率,同时成本也将逐步下探。
第三,近存与存内计算会获得更高关注度。数据移动的能耗瓶颈是产业顽疾,这类能从根本上缓解该问题的架构,天然适用于端侧低功耗场景,接下来渗透率会稳步提升。
第四,晶圆级和资源解耦架构将得到持续探索。Cerebras 已经蹚出了一条路,内存池化等资源池化技术也逐渐成熟,能为超大规模模型提供新的扩展思路。
最后,软件生态永远是决定性的一环。无论硬件创新多么惊艳,最终能否成功取决于有没有配套好用的软件栈、编译器、框架,能否将硬件优势淋漓尽致地发挥出来,并最大限度降低用户的使用门槛。
6. 总结
当下 AI 圈子都在死磕算力,比拼核心数量,但我们必须清醒认识到:内存和互联,才是今天 AI 加速器设计的核心战场。算力堆得再足,倘若数据“运”不出来,一切都是空中楼阁。
这个新的三维分类框架,将 AI 加速器的设计焦点从“计算中心论”转向“内存互联中心论”,恰与当前大模型越做越大的行业趋势严丝合缝。无论是研究者还是一线从业者,都能用这个框架更透彻地对比不同设计,做出更明智的技术抉择。
从 HBM 到 3D 堆叠,从 Chiplet 到晶圆级引擎,所有技术创新的本质,都在试图回答同一个问题:如何让数据更快、更省电地流向计算单元。未来 AI 硬件能走多远、能攀多高,很大程度上就看内存与互联技术能突破到什么程度。这就像一场接力赛,算力的双腿再强壮,也离不开内存与互联这双跑鞋。当业界都在为算力欢呼时,真正懂行的人早已将目光投向了那个更安静的战场。
本文参考资料: https://doi.org/10.36227/techrxiv.177102159.95058346/v1
 发表于 2026-4-25 09:39:03
|
查看: 199|
回复: 0
发表于 2026-4-25 09:39:03
|
查看: 199|
回复: 0
