大多数人低估了昨天 Claude 开放 100 万上下文长度的更新。从 200K 到 1M,上下文长度提升的倍数,其实不是名义上的5倍,而是接近7倍、8倍甚至9倍。
为什么?因为原来的 200K 上下文里,有相当大一部分会被系统提示词、记忆文件、技能模块,以及预留的自动压缩缓冲区占据。所以你真正可使用的项目上下文长度可能只有 100K 出头。现在在 1M 的上下文里,项目可用的上下文长度直接跃升到了 900K 左右。
为了更直观地展示,我打开 Claude Code 的 /context 命令截了两张图。
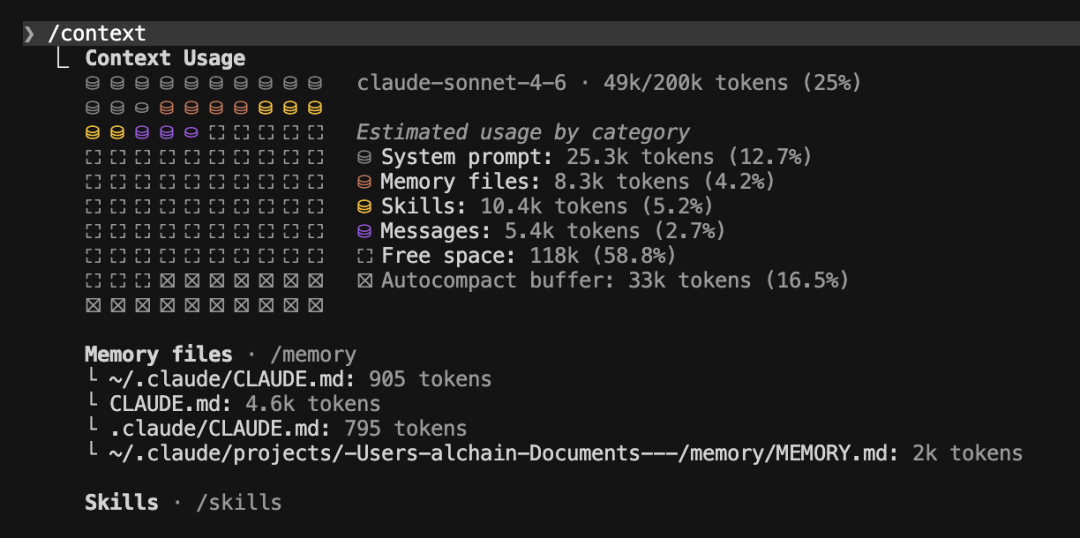
第一张是 Sonnet 4.6 模型(200K 上下文窗口)的情况,可以看到刚打开对话,上下文就已被占用 25%:
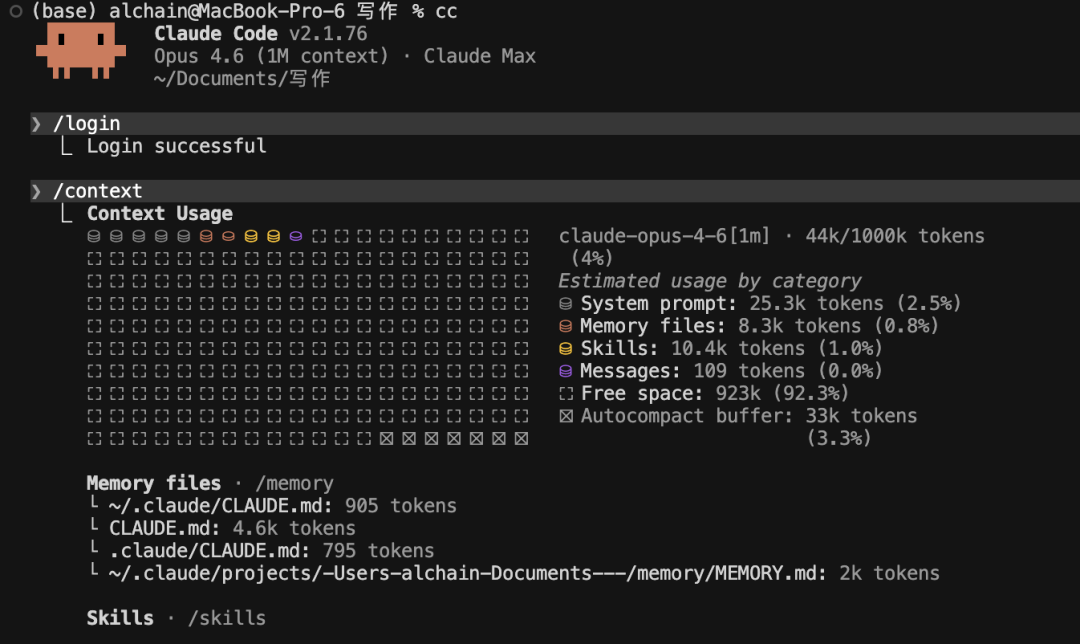
第二张是 Opus 4.6 模型(1M 上下文窗口),在保持相同技能配置的前提下,占用比例骤降至 4%:
我们可以重点关注 Free space(可用空间) 的对比:
- Sonnet 4.6(200K): free space 118k(58.8%)
- Opus 4.6(1M): free space 923k(92.3%)
做一个简单的计算:923 ÷ 118 ≈ 7.8 倍。这意味着,名义上窗口扩大了5倍,但实际可自由使用的空间却提升了接近8倍。对于技能配置更复杂、系统占用更高的用户来说,这个倍数会更加夸张——这也就是我为什么说这次更新等效于将可用上下文提升了6到10倍。
任何被 Compact(自动压缩) 机制折磨过的用户,都能深刻理解这个提升意味着什么。当对话太长触发压缩时,过程并不总是顺畅的,有时会直接失败,导致对话卡死。你不得不重新开始,手动粘贴上下文,每次操作都伴随着信息损耗。然后,模型可能会在你以为已经解决的地方,再次犯下相同的错误。
上下文不是容量,是模型的“草稿纸”
物理学家费曼有一个著名的准则:如果你无法将一个概念用简单的语言、去掉所有专业符号解释清楚,那你就没有真正理解它。上下文限制束缚的,绝不仅仅是你能“装入”多少内容。
想象一下,你正在解一道复杂的数学题,进行到一半时,有人拿走了你的草稿纸。你变笨了吗?并没有。但你能解出那道题吗?恐怕也不能了。
问题出在草稿纸,而不在你的大脑。对于大语言模型而言,其上下文就是它的草稿纸。记忆不只是存储,更是推理的原材料。要推导出一个结论,前提和中间的步骤必须被记在某个地方,模型才能一步步推进。如果每推进一步就忘记一步,即使计算能力再强,也无法完成复杂的逻辑链。上下文窗口定义了模型的有效记忆范围,超出这个范围的信息,模型就只能依靠猜测。
因此,模型犯的很多错误,根源可能不是不够聪明,而是“看不见”:
- 代码开发:一个 Bug 的根源可能是在三个文件之前引入的某个变量定义。一旦这个定义超出了当前上下文,模型就“看不见”它,只能基于不完整的信息进行猜测。
- 长文写作:当文章写到后半部分,前面提出的某个核心论点可能已滚动出上下文窗口。这时,模型可能会无意间复述已表达过的内容,或者导致前后逻辑出现细微的矛盾。这些往往在修改稿件时才发现,为时已晚。
- 多轮深度对话:在第3轮对话中设定的约束条件,可能到了第30轮就从模型的“记忆”中消失了。它给出的建议会越来越偏离轨道,你感觉不对,却说不出具体原因,只觉得“它好像没在听”。
上下文窗口越小,这类因信息残缺导致的问题就越多,模型的整体表现也就越不稳定。
数据证实:上下文越长,Claude 的优势越明显
数据也清晰地印证了这一点。Anthropic 使用 MRCR v2(8-needle)基准进行了一轮长上下文检索测试,任务是在超长文本中同时定位多个隐藏的关键信息。
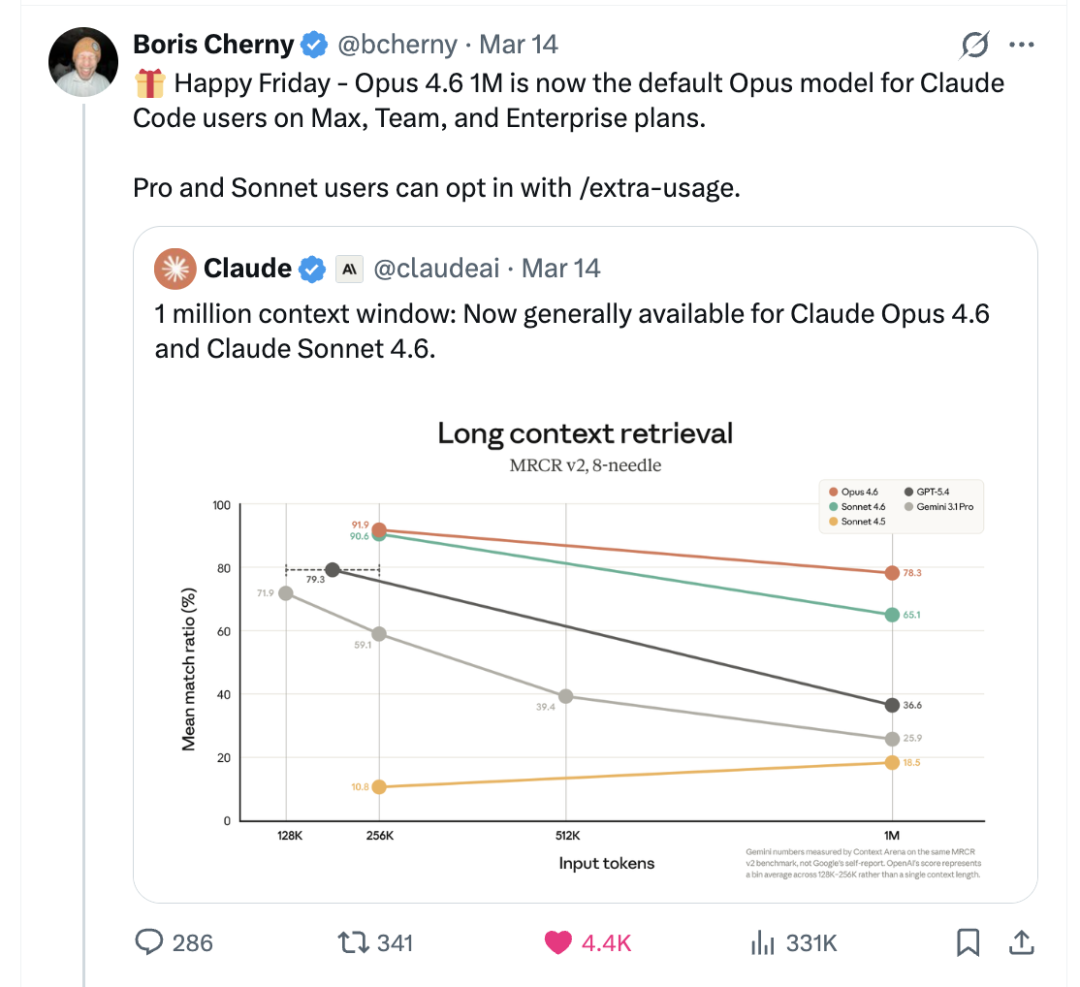
我们将关键数据整理如下表:
| 模型 |
256K上下文表现 |
1M上下文表现 |
| Claude Opus 4.6 |
91.9% |
78.3% |
| Claude Sonnet 4.6 |
90.6% |
65.1% |
| GPT-4.4 |
79.3%† |
36.6% |
| Gemini 3.1 Pro |
59.1% |
25.9% |
† GPT-4.4 的 256K 数据为 128K–256K 区间均值
一个明显的趋势是:上下文越长,模型之间的差距被拉得越大。在 256K 长度下,顶级模型的表现还算接近;但当长度拉到 1M 时,GPT-4.4 的匹配率掉到 36.6%,Gemini 3.1 Pro 更是降至 25.9%,而 Claude Opus 4.6 仍保持在 78.3%。这并非说明 Claude 在短上下文里绝对更强,而是在极限长度下,其他模型的表现衰减更剧烈,而 Claude 保持了更好的韧性。
Claude Code 的产品经理 Boris Cherny 也在推特上确认:Opus 4.6 1M 版本现在已成为 Claude Code 中 Max、Team、Enterprise 套餐的默认模型,用户无需更改任何设置。Pro 版和 Sonnet 用户则可以通过输入 /extra-usage 命令手动开启这一能力。
Anthropic 还引用了一个客户案例:在启用 1M 上下文后,其工作流中的自动压缩事件减少了 15%。这与我个人的使用感受相符。据我估算,对于那些需要长期迭代的复杂项目而言,上下文的大幅拓展所带来的效率提升和价值,至少等同于模型本身的能力提升了 10%-20%。
API 定价同步调整:长上下文不再有溢价
另一个关键利好是 API 定价策略的调整。现在,无论你提交 900K token 的请求还是 9K token 的请求,都按同样的单价计费:
| 服务商 |
长上下文收费策略 |
| Anthropic Claude |
✓ 无溢价,与短上下文单价相同 |
| OpenAI GPT-4.4 |
输入超过 272K 部分收取 2倍单价,输出部分收取 1.5倍单价 |
当 OpenAI 仍在收取“长度税”时,Anthropic 已经取消了这项溢价。这标志着,超长上下文正逐渐成为顶级模型的标配能力。从理论上讲,处理长上下文本身也确实是模型应具备的基础能力,而不该被视作一项“高级功能”。
对于 Claude Code Max 用户(每月 100 美元档位)来说更简单,1M 上下文能力直接包含在套餐内,无需额外参数,也无需支付更多费用。
本次更新中的其他亮点
除了核心的上下文扩展,本次更新还包含另外两个实用改进:
- 文件上传上限提升:图片/PDF 的同时上传数量上限从 100 个增加至 600 个。以前处理大量 PDF 时需要手动分批上传,现在可以一次性全部喂给模型。对于需要整理大量截图和参考资料的文章写作等工作流,这一步的提升直接省去了好几个操作步骤。
- Adaptive Thinking 转正:“自适应思考”功能结束测试,转为正式版。模型会自行判断何时需要“深度慢想”,何时可以直接回答,用户无需再手动配置推理深度。这减少了一层不必要的决策,让交互更加流畅。
写在最后:Context,Not Control.
AI 工具的进步通常有两种路径:一是让模型本身变得更聪明;二是将模型已有的能力更充分、更稳定地释放出来。Claude 1M 上下文窗口的全面开放,显然属于后者。但对于长期项目、复杂开发任务,以及那些曾被自动压缩机制搞崩过心态的用户而言,这次更新的实际影响,丝毫不亚于一次显著的模型能力升级。
费曼曾说过,背下一个公式,与能够从头推导出这个公式,是两件重量完全不同的事。同样地,直接给模型喂食答案,与为模型提供足以推导出答案的全部信息,也是两种截然不同的路径。后者更难实现,但得出的结果往往更可靠、更经得起推敲。
上下文窗口的大小,直接决定了你能为模型提供多少用于推导的“原材料”。在过去窗口有限的时期,我们不得不做减法——忍痛剪掉那些“可能有用但实在放不下”的信息。每次裁剪,都是一场赌博,赌这段被舍弃的信息不重要。赌赢了,你毫无感知;赌输了,模型就会在某个你视线之外的角落,犯下一个让你摸不着头脑的错误。
现在,情况终于改变了。你可以更加“肆无忌惮”地向模型投喂任何你认为它完成工作所必须知道的信息。这种“提供充分语境,而非施加精细控制”的理念,不仅在 Netflix、字节跳动等公司的管理中行之有效,在大模型的使用范式上也正变得越来越重要。
如果你对这类 AI 技术在实际开发与创作中的应用和趋势感兴趣,欢迎来 云栈社区 交流讨论,这里聚集了许多关注前沿技术的开发者。
 发表于 2026-3-16 02:56:28
|
查看: 223|
回复: 0
发表于 2026-3-16 02:56:28
|
查看: 223|
回复: 0
