任何事物都可能发生故障,我们的目标并非完全避免故障——这几乎是不可能的——而是去理解可能出现的故障类型,以及在故障发生时如何正确应对。
这个道理和与人相处很像。你的伴侣完全不生气?这几乎不可能。关键是要清楚TA通常在哪些点上容易生气,以及做什么可以让TA消气。小摩擦可能一顿火锅就能解决,而大的矛盾或许就需要一个包了。
今天我们要聊的“数据库”,就是一个需要精心维护的“伙伴”。好的,第一步,我们需要了解它可能会遇到哪些“故障”。
不过在此之前,我们先来回顾一下数据库执行一个操作的基本流程。举个例子:你在电商平台下单购买商品,后台需要执行一个下单事务,主要包含两个操作:
这个过程通常会按以下步骤执行:
- 开始新事务,分配事务ID。
- 执行操作1,写入日志到内存,并将更新的数据写入内存。
- 执行操作2,写入日志到内存,并将更新的数据写入内存。
- 操作完成,将内存中的日志写入磁盘。
- 将内存中更新后的数据写入磁盘。
- 事务返回成功。
这就是一个完整的事务流程。你可能注意到,数据库操作会先更新数据到内存,这是为什么?这其实是程序运行时,内存与硬盘协作的基本机制(想深入了解可以阅读关于内存管理的文章)。由于内存的访问速度比硬盘快数十万倍,将数据调入内存可以极大提升访问效率。
另一个频繁出现的词是日志。为什么日志如此重要?这是因为数据库管理系统(DBMS)严格遵守一个核心原则:日志登记原则(Write-Ahead Logging, WAL)。简单说,就是先写日志,后改数据库。
数据只是最终状态,而日志记录了数据变化的完整过程。先写日志能够确保操作流程被记录下来,即使数据本身因故障未能保存,后续也可以根据日志进行“重做”(Redo)。如果顺序反过来,先保存数据后写日志,一旦在写日志前发生故障,就会导致事务执行到一半却没有任何记录,数据库里就可能留下一堆无法解释的“脏数据”。
这好比领取物资:先登记再领取,确保每个人都有记录。如果你登记后因突发情况(比如晕倒)没能领取,事后也可以凭记录补发。如果先领取后登记,你领了东西却没登记上,就会导致库存数据对不上。

由此可见,在整个事务链路中,各个环节都可能发生故障。我们可以将其归纳为以下三大类:
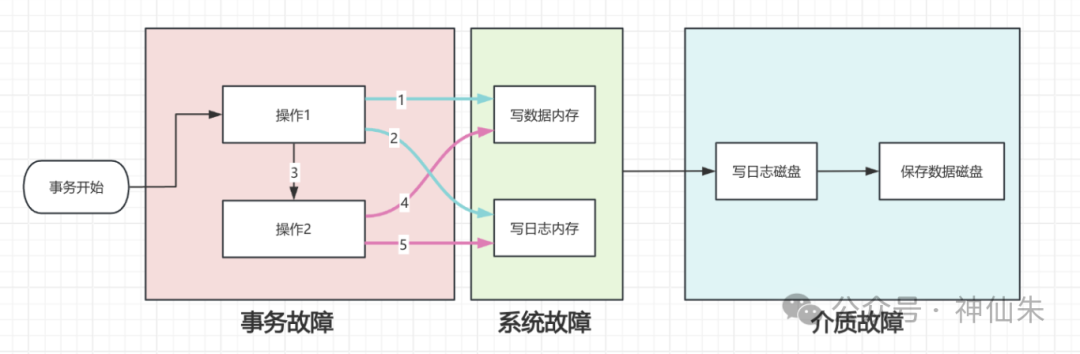
- 事务故障
- 系统故障
- 介质故障
事务故障
指的是事务尚未完成就意外终止的情况。原因主要有两种:
- 可预期的故障:通常由业务代码本身的Bug或逻辑错误引起,例如账户余额不足、违反数据完整性约束等。
- 不可预期的故障:主要指非人为的并发控制问题,例如DBMS检测到的死锁——两个事务互相等待对方释放锁资源,导致都无法继续执行。
从影响范围看,事务故障的严重性最低,通常只影响当前少数几个事务,其他用户和事务仍可正常运行。解决方法也相对直接:
- 对于可预期故障,一般在代码中使用
try-catch 进行捕获,然后执行 ROLLBACK 回滚事务。
- 对于不可预期的死锁,DBMS会选择一个“牺牲者”事务,强制将其回滚以释放锁资源,确保其他事务能够完成,之后可以重启那个被终止的事务。
系统故障
指操作系统故障或DBMS自身故障导致数据库停止运行的情况。其影响范围较大,会波及当前所有正在处理的事务,属于中等严重性故障。
系统故障会导致驻留在内存中的所有数据丢失,包括正在处理的数据页。回顾事务流程,DBMS并非直接将数据写入磁盘,而是先更新内存中的数据并写入内存日志,待事务在内存中执行完毕,才进行写盘操作。因此,系统故障发生时,主要面临两种情况:
- 未完成的事务:事务执行到一半发生故障,尚未提交。
- 已提交但未写盘的事务:事务逻辑上已提交(客户端收到成功响应),但修改的数据仍在内存中,尚未持久化到磁盘。
针对这两种情况,DBMS在重启恢复时会利用日志建立两个队列:
- 重做队列 (REDO):针对“已提交但未写盘的事务”。通过正向扫描日志,找到这些事务记录的更新后的新值,并重新执行一遍,将数据写入数据库。
- 撤销队列 (UNDO):针对“未完成的事务”。通过反向扫描日志,找到这些事务已执行的操作所记录的更新前的旧值,并依此回滚操作,将数据恢复到事务开始前的状态。
简单理解:重做是“历史重演”,所以正向;撤销是“时光倒流”,就像按 Ctrl+Z,所以反向。
讲到这里,你可能会有疑问:
- “未完成的事务,既然没有写盘,为什么要撤销?”
- “已提交,但日志没写盘或写到一半就故障,这该撤销还是重做?”

第一个问题:“未完成的事务,说明没有写盘,为什么要撤销?”
按照标准流程,事务似乎是在写日志到磁盘之后,才更新数据到磁盘。那么事务没完成,理应不会更新磁盘数据,何来撤销一说?
原因在于存在一个特殊机制:检查点 (Checkpoint) 机制。为了保障数据一致性并提升恢复效率,DBMS会定期将内存中已修改的脏数据页写回磁盘。这意味着,一个事务即使尚未完成,其部分修改也可能因为检查点而被提前写入了磁盘,从而“污染”了磁盘数据。一旦此后系统发生故障,自然需要根据日志撤销这些未完成的操作。当然,在数据页写盘之前,其对应的日志记录必然已先写入了磁盘(遵守WAL原则)。
此外,另一种情况是内存已满,操作系统不得不进行页面置换,也可能将包含未提交事务修改的数据页写回磁盘。
第二个问题:“已提交,但是日志没写盘,或者写到一半就故障,这要撤销还是重做?”
答案是:撤销。
事务提交成功的一个关键前提是:该事务的日志记录已经完全写入磁盘。注意,是“完全写入磁盘”。只有日志完全落盘后,DBMS才能确保即使之后发生故障,也能根据完整的日志进行重做。如果日志只写了一部分就发生故障,表明事务并未真正完成,因此需要撤销。如果日志完全没写,那就当作这个事务从未发生过。

这里的情况确实有些交织,需要仔细理解日志(记录操作)与数据(记录结果)在故障恢复中的不同角色。
介质故障
指存储数据的物理介质(如磁盘)发生损坏,例如硬盘磁头碰撞、消磁或遭遇自然灾害等。硬盘是相对脆弱的设备,其工作原理决定了它存在损坏的可能。
介质故障的解决办法相对单一但至关重要:备份。这就引出了我们今天另一个核心话题。
数据库备份策略详解
备份听起来简单,但要建立一个健全的备份体系,需要考虑很多方面:备份什么内容、如何备份、备份到哪里、何时备份等等。
首先,按照备份的数据量大小,可以分为三种类型:
- 全量备份 (Full Backup):简称全备,备份整个数据库的所有数据。
- 增量备份 (Incremental Backup):简称增备,备份自上一次备份(无论何种类型) 以来发生变化的部分数据。
- 差量备份 (Differential Backup):简称差备,备份自上一次全量备份以来发生变化的部分数据。
增备和差备容易混淆。看下面这个表格就一目了然了:
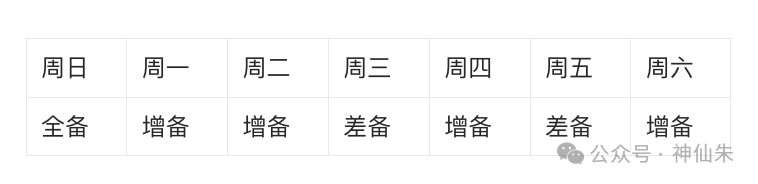
- 增备:只与最近一次备份做差异对比。例如,周二的增备,只会备份周二相对于周一的增备所产生的差异部分。
- 差备:始终与最近一次全备做差异对比。例如,周三的差备,会备份自周日全备以来,到周三为止的所有变化。
其次,按照备份时数据库的运行状态,可以分为两种:
- 冷备 (Cold Backup):在数据库关闭(脱机)时进行备份。方法最简单,直接复制物理数据文件即可,备份结果与数据库状态完全一致。但缺点是需要停止服务,对业务连续性影响大。
- 热备 (Hot Backup):在数据库正常运行(联机)时进行备份。可用性最高,无需停机,但会带来数据不一致的经典问题。
为什么热备会导致数据不一致?因为备份程序在拷贝数据文件的同时,用户还在对数据库进行读写。
举例来说:
- 备份从 10:00 开始,10:30 结束。
- 10:05 时,备份程序拷贝了账户A(此时余额1000元)。
- 10:10 时,一个事务完成了从A向B转账500元:A余额变为500,B余额变为500(原为0)。
- 10:15 时,备份程序拷贝了账户B(此时余额500元)。
结果:备份出来的数据副本中,账户A余额是1000,账户B余额是500。这凭空多出来的500元就是逻辑不一致的“脏数据”。
解决方法就是依赖日志文件。即使备份的数据快照不一致,但只要拥有备份开始点的完整数据以及截止到恢复点的事务日志,就可以通过“重放”日志来将数据库恢复到一致的正确状态。
实践中,这些备份类型通常会组合使用,例如:
- 周日凌晨进行冷全备:关闭服务,做一次完整的物理备份。
- 周一至周六白天进行热增备:在服务运行时,只备份当天新产生的日志和变化的数据块。
备份恢复流程
那么,如何利用这些备份进行恢复呢?举个例子:
假设我们有以下备份集:
- 周一:全备
- 周二:增备(周一后的变化)
- 周三:增备(周二后的变化)
在周四上午10点,磁盘损坏。恢复步骤必须严格按顺序进行:
- 恢复周一的全备。
- 在此基础上,恢复周二的增备。
- 再恢复周三的增备。
此时,数据库就恢复到了周三备份完成时的状态。但周三备份之后到周四10点故障之间,可能还有新的业务发生。因此,关键的一步是:应用周三备份之后产生的事务日志,将这段时间内的事务重新执行(Redo)一遍,最终将数据库恢复到故障前的最近一致状态(例如周四10点整)。
此外,在硬件层面,磁盘冗余阵列 (RAID) 技术也为数据保护提供了强大支持。它并非简单的1:1磁盘镜像,而是通过奇偶校验、条带化等技术,在多个磁盘之间实现数据冗余和性能提升,能够抵御单块甚至多块磁盘的故障。这虽然是存储层面的技术,但对于构建高可用的数据库系统至关重要。
总结
我们来回顾一下今天的内容:
- 故障处理:核心在于理解事务日志 (WAL) 和基于日志的恢复机制 (Redo/Undo)。无论是事务级的小故障,还是系统级的大故障,日志都是实现数据一致性的基石。
- 备份策略:需要根据业务对RTO(恢复时间目标)和RPO(恢复点目标)的要求,灵活组合使用全备、增备、差备、冷备、热备等多种策略,并设计完整的恢复演练流程。
理解这些底层机制,不仅能帮助我们在故障发生时从容应对,更是设计高可用、高可靠系统架构的计算机基础。希望这篇梳理对你有所帮助。如果你想与更多开发者交流这些技术心得,欢迎来云栈社区一起探讨。
 发表于 2026-3-16 06:02:53
|
查看: 157|
回复: 0
发表于 2026-3-16 06:02:53
|
查看: 157|
回复: 0
