当你的个人博客系统突然走红,每天面临百万级读请求时,单纯依靠一台数据库服务器很快就会达到性能瓶颈。你会发现,绝大部分压力其实来自“读”操作,而宝贵的数据库资源却被这些请求耗尽,导致那仅占1%的“写”请求也无法顺利完成。
初期,一个典型的Web应用数据流非常简单直接:

随着流量激增,单机数据库会迅速暴露出多个瓶颈:
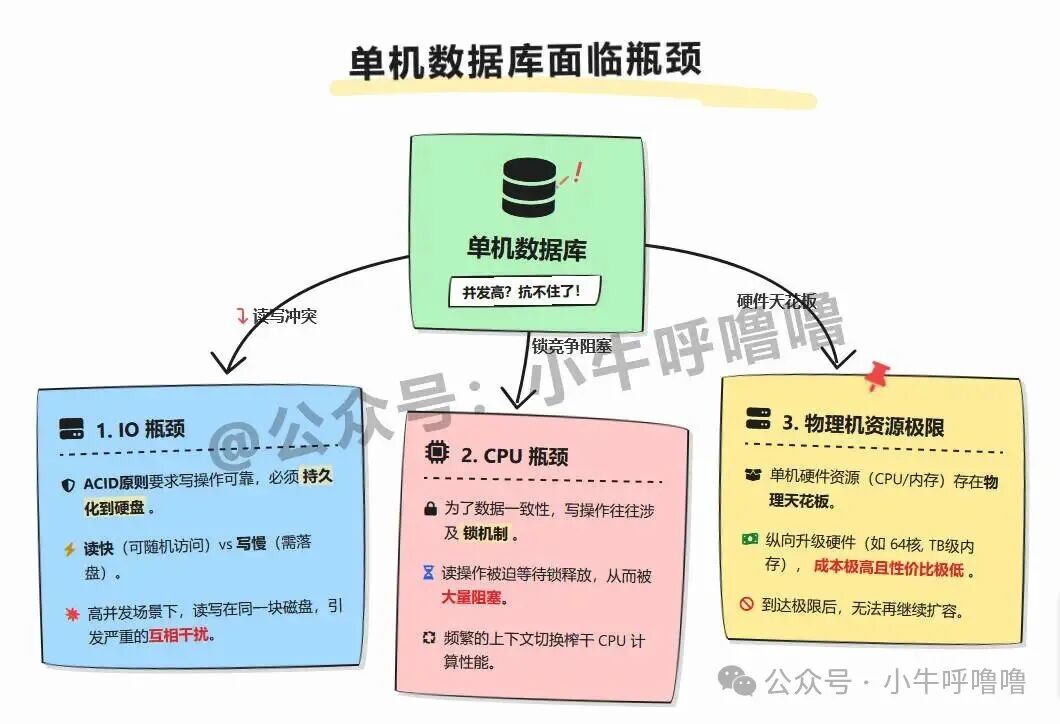
首先是IO瓶颈。数据库的ACID原则要求写操作必须可靠持久化到硬盘,导致读快(可随机访问)而写慢。在高并发场景下,读写操作集中在同一块磁盘,会产生严重的相互干扰。
其次是CPU瓶颈。为保证数据一致性,写操作常涉及锁机制,导致读操作被阻塞等待,频繁的上下文切换会大量消耗CPU计算资源。
最后是物理资源极限。单台服务器的硬件资源(CPU、内存)存在物理天花板,纵向升级硬件不仅成本极高,而且性价比会随着规格提升而急剧下降。
此时,仅仅进行加索引、SQL优化或加缓存可能仍无法应对持续增长的流量,数据库最终会成为整个系统的最大瓶颈。一个根本性的解决方案是引入水平扩展,而针对“读多写少”的场景,最经典的架构就是读写分离。
什么是读写分离?
读写分离是一种数据库架构优化技术,其核心思想是将对数据库的“读”和“写”操作分离,交由不同的服务器组处理。通常采用“一主多从”的架构:
- 配置一个 Master主库,专门负责处理“写”操作(
INSERT, UPDATE, DELETE)。
- 配置一个或多个 Slave从库,专门负责处理“读”操作(
SELECT)。从库实时地从主库同步数据,从而确保数据副本的可用性。
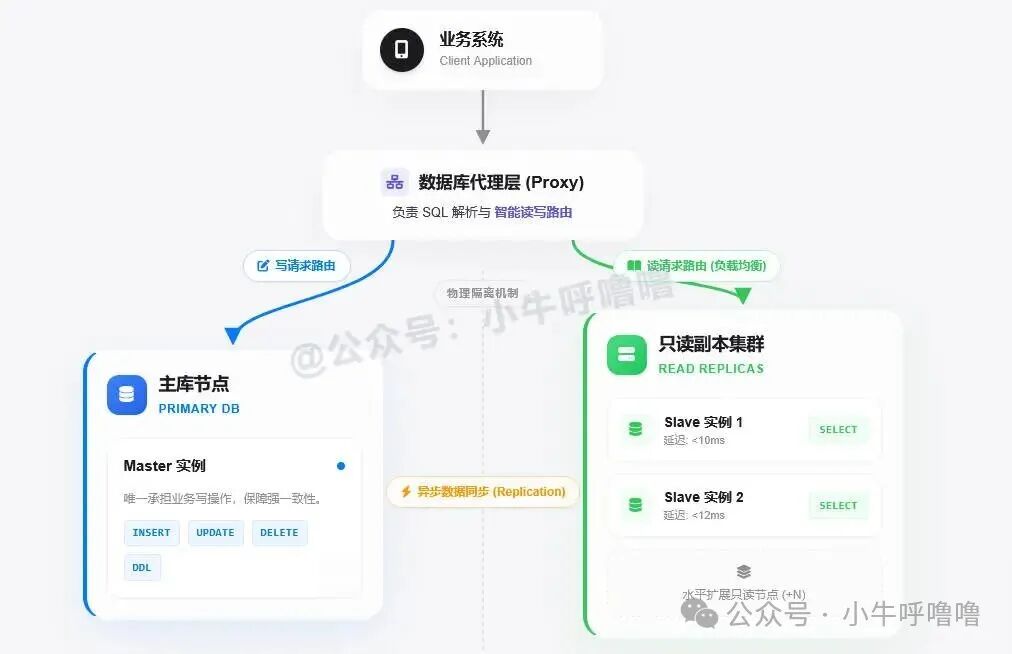
这种架构带来了多重好处:
- 负载均衡:将巨大的读压力分散到多个从库上,显著降低单台服务器的负载。
- 职责分离:主库专注于写操作,保证数据的一致性和可用性;从库专注于读操作,提供高并发的读取能力,这也是 System Design 中常见的解耦思想。
- 高可用性:当主库出现故障时,可以迅速将一个从库提升为新的主库,从而减少服务中断时间。
如何让从库的数据和主库保持一致?
实现读写分离的关键在于数据同步,这依赖于 主从复制(业界现多称 领导者-跟随者复制 Leader-Follower Replication)技术。它是构建高并发、高可用系统架构的基石,无论是 MySQL、Redis、Kafka 还是 MongoDB,底层都离不开它。
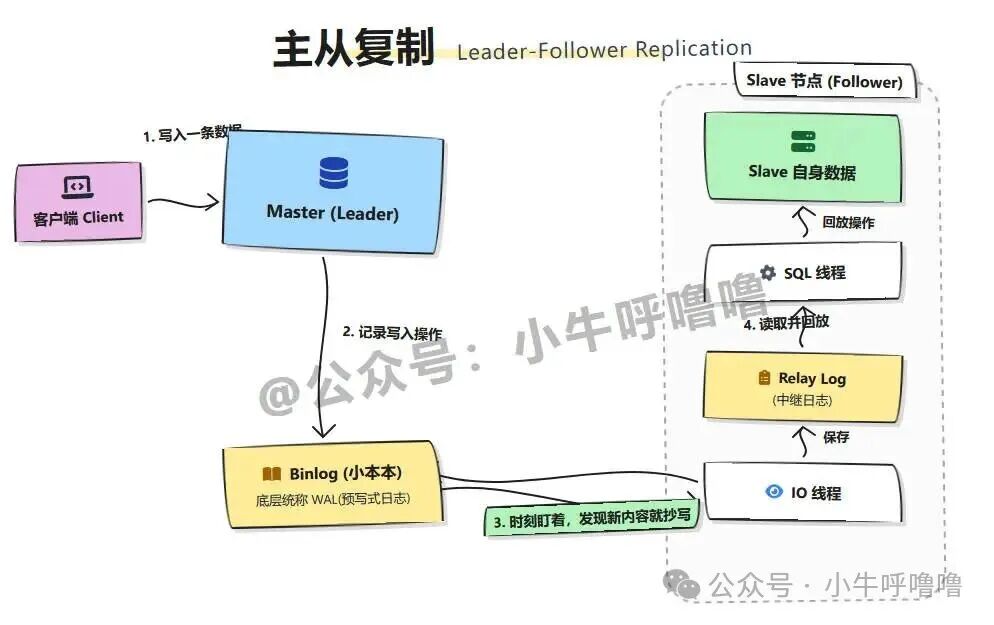
以MySQL的Binlog为例,其同步流程如下:
- 客户端向 Master 写入一条数据。
- Master 将这次写入操作记录到 Binlog(在Redis中类似AOF,底层统称为 WAL预写式日志)。
- Slave 的 IO线程 连接到Master,持续监控Binlog的变化。一旦发现新内容,就将其拷贝并保存到本地的 中继日志 Relay Log 中。
- Slave 的 SQL线程 读取Relay Log,并在自身数据库上回放这些写操作。
通过这一机制,Slave的数据得以与Master保持一致。随后,所有查询请求被引流到Slave集群,Master的压力便得到极大缓解。
如何实现读写分离?
在应用层实现读写分离,一种较为简单清晰的方式是利用Spring AOP和动态数据源,在代码层面进行路由分配。以下是一个基于 Java Spring Boot + MySQL 的示例。
假设已搭建好MySQL主从环境(主库: localhost:3306,从库: localhost:3307)。我们使用 AbstractRoutingDataSource 实现动态数据源切换。
首先,在 pom.xml 中添加必要依赖:
<!-- Spring Boot Starter Data JPA -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- MySQL Driver -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.3.0</version>
</dependency>
配置 application.yml,定义主从数据源:
spring:
datasource:
master: # 主库配置
url: jdbc:mysql://localhost:3306/testdb?useSSL=false
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
slave: # 从库配置(可多个)
url: jdbc:mysql://localhost:3307/testdb?useSSL=false
username: root
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
创建动态数据源类 DynamicDataSource.java:
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class DynamicDataSource extends AbstractRoutingDataSource { // 继承AbstractRoutingDataSource,实现动态切换
@Override
protected Object determineCurrentLookupKey() { // 重写方法,决定当前使用哪个数据源
// 从ThreadLocal中获取当前上下文:读还是写
return DataSourceContextHolder.getDataSourceType(); // 如果是"master"返回主库,否则从库
}
}
创建线程上下文持有器 DataSourceContextHolder.java:
public class DataSourceContextHolder { // 线程安全的上下文持有器,用于存储当前数据源类型
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>(); // 使用ThreadLocal,确保每个线程独立
public static void setDataSourceType(String dataSourceType) { // 设置数据源类型(master或slave)
contextHolder.set(dataSourceType);
}
public static String getDataSourceType() {
return contextHolder.get();
}
public static void clearDataSourceType() { // 清除上下文,防止内存泄漏
contextHolder.remove();
}
}
创建AOP切面 DataSourceAspect.java,通过注解自动切换数据源:
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class DataSourceAspect {
@Before("@annotation(ReadOnly)") // 前置通知:方法有@ReadOnly注解时,切换到从库
public void setSlave() {
DataSourceContextHolder.setDataSourceType("slave"); // 设置为slave,从库读
}
@Before("execution(* com.example.service.*.*(..)) && !@annotation(ReadOnly)") // 前置通知:服务层方法无@ReadOnly时,用主库
public void setMaster() {
DataSourceContextHolder.setDataSourceType("master"); // 设置为master,主库写
}
@After("@annotation(ReadOnly) || execution(* com.example.service.*.*(..))") // 后置通知:执行后清除上下文
public void clear() {
DataSourceContextHolder.clearDataSourceType(); // 清除ThreadLocal
}
}
定义用于标记读操作的自定义注解 ReadOnly.java:
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME) // 运行时可见
public @interface ReadOnly { // 定义读操作注解
// 无内容,仅标记读方法
}
配置数据源Bean DataSourceConfig.java:
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master") // 绑定主库配置
public DataSource masterDataSource() {
return new com.zaxxer.hikari.HikariDataSource();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave") // 绑定从库配置
public DataSource slaveDataSource() {
return new com.zaxxer.hikari.HikariDataSource();
}
@Bean
public DynamicDataSource dynamicDataSource(@Qualifier("masterDataSource") DataSource master,
@Qualifier("slaveDataSource") DataSource slave) {
DynamicDataSource ds = new DynamicDataSource();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put("master", master); // 添加主库
targetDataSources.put("slave", slave); // 添加从库
ds.setTargetDataSources(targetDataSources); // 设置目标数据源
ds.setDefaultTargetDataSource(master); // 默认主库
return ds;
}
@Bean
public DataSourceTransactionManager transactionManager(DynamicDataSource ds) {
return new DataSourceTransactionManager(ds); // 绑定动态数据源的事务
}
}
在Service层使用示例:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void saveUser(User user) { // 写操作,无@ReadOnly,用主库
userRepository.save(user); // 保存用户
}
@ReadOnly // 读操作,注解切换到从库
public List<User> getAllUsers() {
return userRepository.findAll(); // 查询所有用户
}
}
应用启动后,所有写方法将自动路由至主库,而带有 @ReadOnly 注解的读方法则会路由至从库。需要注意的是,MySQL侧需要预先配置好主从复制(主库开启Binlog,从库执行 CHANGE MASTER TO ... 命令进行同步)。通过水平扩展从库,系统的读性能可以获得数倍提升。
除了上述在应用层编码实现的方式,业界还有更成熟的方案。例如,引入 ShardingSphere-JDBC,它以JAR包形式集成,通过配置文件定义规则即可自动完成SQL解析和路由,对业务代码侵入性极低。另一种是中间件代理方案,如Mycat、ProxySQL或云厂商提供的数据库代理服务。它们在应用与数据库之间独立部署一层代理,应用像连接单机数据库一样连接代理,由代理负责SQL解析和转发,实现了对应用的完全透明。
主从延迟及其挑战
读写分离结合主从复制并非银弹,它会引入一个经典问题:主从延迟。由于数据从主库同步到从库需要时间,用户执行写操作后若立刻去从库读取,可能会因为同步尚未完成而读取到旧数据,这就是 Read-after-Write 一致性问题。
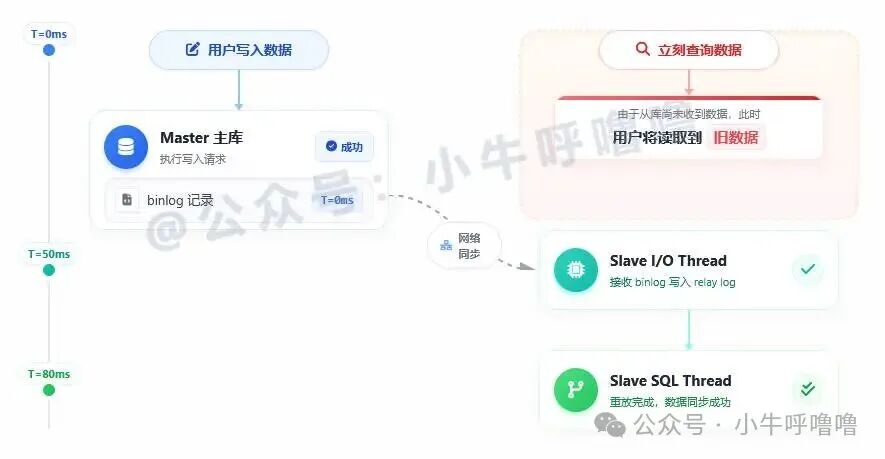
导致主从延迟的原因主要有以下几点:
- 网络延迟:主库与从库之间的物理距离导致的数据传输耗时。同机房通常
< 1ms,跨地域则可能 > 100ms。
- 从库负载过高:从库不仅承担数据同步任务,还可能处理大量读请求。如果从库上运行了未经优化的慢SQL,其资源可能被耗尽,导致同步速度跟不上主库Binlog的生成速度。
- 单线程复制瓶颈:在MySQL 5.6之前,Slave只有一个SQL线程串行回放Relay Log,严重制约了同步吞吐量。MySQL 5.7+引入了多线程并行复制才有效解决了此问题。
- 大事务:执行时间过长的事务(例如一次性更新上百万行数据)在主库完成后,在从库重放同样需要大量时间,会造成显著的延迟。在生产环境中应尽量避免大事务,可考虑将大批量操作拆分为多个小批次执行。
主从同步延迟的处理策略
面对主从延迟,可以根据业务场景选择不同的应对策略:
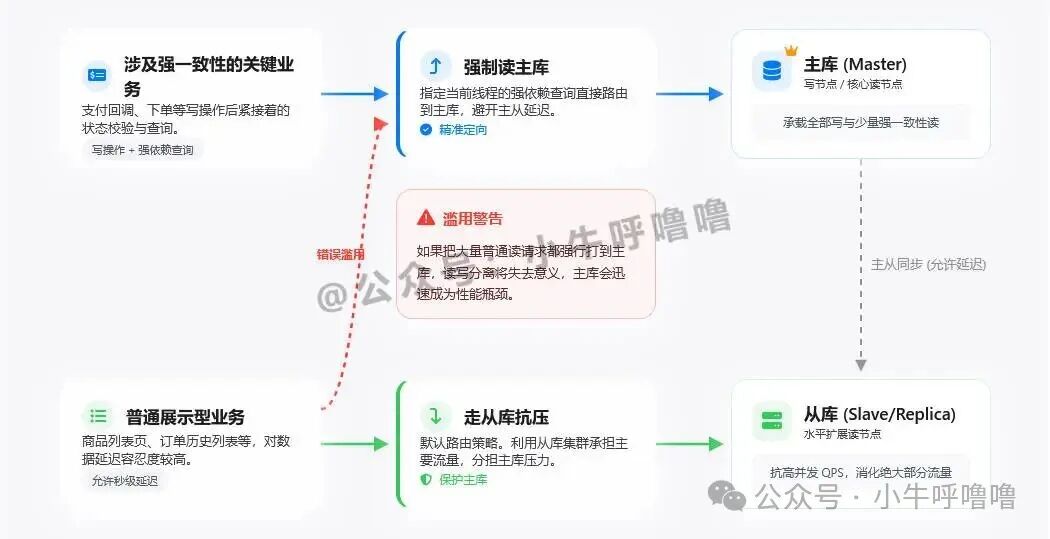
-
关键业务强制读主库
对于涉及强一致性的核心业务(如支付成功后的状态查询、下单后的订单详情展示),可以在写操作后,将紧接着的强依赖查询强制路由到主库。此策略仅用于关键路径,如果滥用,将大量普通读请求也打到主库,会使读写分离失去意义,主库很快成为新的性能瓶颈。
-
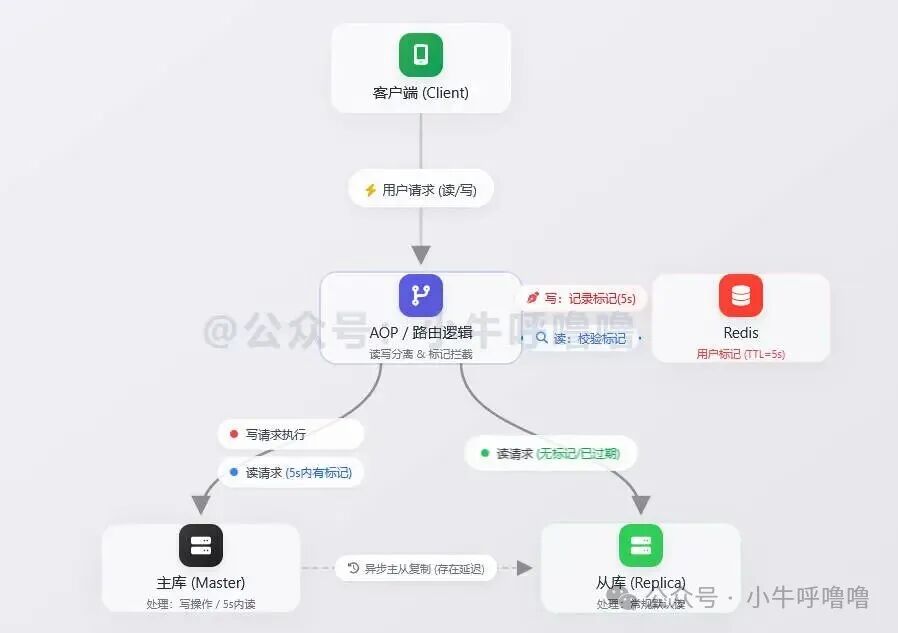
写后读延迟补偿(Redis标记法)
这是一种更精细的控制方案。绝大部分读请求默认走从库。当用户发生写操作时,在Redis中为该用户设置一个短期有效的标记(例如TTL为5秒)。在接下来的5秒内,该用户的所有读请求都通过AOP或路由逻辑强制路由到主库。5秒后标记过期,其读请求恢复至从库。这种方法在确保关键数据新鲜度的同时,最大限度地保护了主库。
-
使用MySQL半同步复制
默认的MySQL主从复制是异步的:主库提交事务后立即向客户端返回成功,不关心从库是否已同步。这存在数据丢失风险(主库宕机时)。
半同步复制要求主库在提交事务后,必须等待至少一个从库成功接收Binlog并写入其Relay Log后,才能向客户端返回成功。
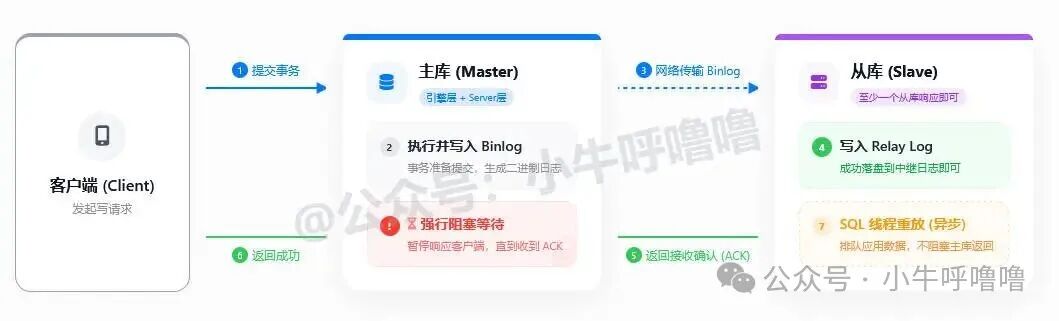
半同步复制主要目标是解决数据丢失问题,提升高可用性,而非彻底消除延迟。因为它只保证日志传输到了从库,不保证从库的SQL线程已应用日志。不过,由于增加了等待环节,它客观上缩短了主从之间的数据差距,但其代价是会轻微降低主库的写入性能。
掌握读写分离的原理、实现方式及其带来的挑战(如主从延迟),是构建高性能、高可用 后端架构 的必备知识。在实际项目中,需要根据业务的数据一致性要求、延迟容忍度和流量规模,灵活选择和组合上述策略。如果你想了解更多关于 Java 生态下的高性能实践,或与其他开发者交流此类架构经验,欢迎到 云栈社区 的相关板块参与讨论。
 发表于 2026-3-18 03:41:38
|
查看: 167|
回复: 0
发表于 2026-3-18 03:41:38
|
查看: 167|
回复: 0
