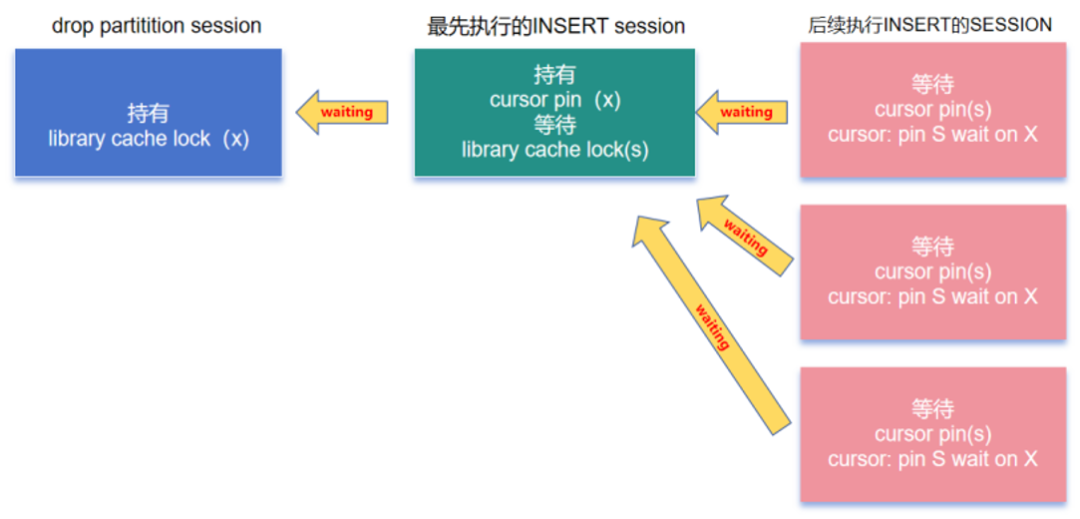
某银行客户核心系统数据库大量使用RANGE+LIST的二级分区表,一级分区按DATE列,每天一个分区,二级分区LIST子分区(每个一级分区下有528个子分区),需要按保留周期每天清理之前的分区(一级分区)。在drop分区期间,会导致该表上的INSERT等交易SQL产生阻塞,进而导致交易超时。
主要阻塞链为 [INSERT](cursor: pin S wait on X)->[INSERT](library cache lock)->[ALTER TABLE](ON CPU)。
问题的根本原因在于分区数量过多,导致DDL维护慢、library cache加载慢、SQL解析慢。
解决思路如下:
- 减少分区数(业务侧已从52831降低至5289=4752,无法继续减少)。
- 缩短
drop partition的时间(当前在20秒以上),核心在于缩短排他模式持有library cache lock的时间。
这就需要我们深入分析drop partition操作的时间消耗主要在哪些阶段,以及在什么阶段会以排他模式持有library cache lock。
分析过程
通过分析ALTER TABLE执行期间的ASH裸数据,可以判断耗时原因。
col SQL_OPNAME for a20
select t.inst_id,t.SAMPLE_TIME,t.SESSION_ID,t.SQL_ID,t.SQL_OPNAME,t.EVENT,t.P1TEXT,t.P1,t.P2TEXT,t.P2,t.TIME_WAITED
from gv$active_session_history t
where SAMPLE_TIME between to_date('2025-05-08 04:20','yyyy-mm-dd hh24:mi') and to_date('2025-05-08 04:29','yyyy-mm-dd hh24:mi')
and SQL_OPNAME='ALTER TABLE'
ORDER BY SAMPLE_ID;
从等待事件可以看出,enq: CR - block range reuse ckpt、enq: RO - fast object reuse、reliable message占比较高。其中reliable message为IPC消息交互,暂时忽略。我们主要关注enq: CR - block range reuse ckpt和enq: RO - fast object reuse这两个与检查点相关的等待事件。
SQL> select name,eq_name,req_reason,req_description from v$event_name a,v$enqueue_statistics b
where name in ('enq: RO - fast object reuse','enq: CR - block range reuse ckpt') and a.event# = b.event#;
NAME EQ_NAME REQ_REASON REQ_DESCRIPTION
------------------------------ ------------------------------ ------------------------------ --------------------------------------------------
enq: RO - fast object reuse Multiple Object Reuse fast object reuse Coordinates fast object reuse
enq: CR - block range reuse ck Reuse Block Range block range reuse ckpt Coordinates fast block range reuse ckpt
pt
这里的enq: CR - block range reuse可能容易误解,从名字上看,容易把CR理解成一致性读(CR)块,实际上这里的CR指的是Reuse Block Range。
SQL> col TYPE for a5
SQL> select TYPE,name from v$lock_type where type='CR';
TYPE NAME
----- ------------------------------
CR Reuse Block Range
可能导致等待检查点慢的可能原因包括:
- DBWR写入慢
- IO写入慢
- 系统繁忙
- BUFFER CACHE大,脏块多
- BUFFER CACHE如果过大(如该客户的库BUFFER CACHE 500G以上),扫描脏块过程可能变慢。
- 多实例(RAC)环境,需要等待多个实例上的脏块落盘。
验证DROP PARTITION过程中需要等待检查点(脏块落盘)
1. 创建测试表
SQL> create table test.tpart(id number,c varchar2(100))
partition by range(id)
(partition part_1 values less than(100),
partition part_2 values less than(200),
partition part_3 values less than(300));
SQL> insert into test.tpart select rownum,rownum from dual connect by rownum<300;
299 rows created.
SQL> commit;
Commit complete.
2. 使用gdb暂停DBWR进程
[root@db1 trace]# ps -ef |grep dbw
oracle 2328 1 0 13:32 ? 00:00:00 ora_dbw0_test
root 2814 2449 0 14:41 pts/3 00:00:00 grep dbw
[root@db1 trace]# gdb -p 2328
3. 执行DROP PARTITION会进入等待
SQL> alter table test.tpart drop partition part_1;
等待....
通过查询会话状态,可以看到ALTER TABLE语句正在等待enq: RO - fast object reuse事件,这表明进程确实在等待检查点完成。
FAST OBJECT REUSE / BLOCK RANGE REUSE CKPT 是否仅涉及被DROP的SEGMENT落盘?
1. 创建测试表
SQL> create table test.tobj1 as select * from dba_objects;
Table created.
SQL> create table test.tobj2 as select * from dba_objects;
Table created.
SQL> @o test.tobj2
owner object_name object_type status OID D_OID CREATED LAST_DDL_TIME
------------------------- ------------------------------ -------------------- --------- ---------- ---------- ------------------- -------------------
TEST TOBJ2 TABLE VALID 87363 87363 2025-09-10 14:02:13 2025-09-10 14:02:13
2. 统计脏块数量
SELECT
COUNT(*) AS dirty_count,max(HSCN_BAS),max(tch),max(HSUB_SCN),min(LRBA_BNO),sum(decode(OBJ,87363,1,0))
FROM
X$BH
WHERE
DBABLK != 0
AND /*DIRTY*/ decode(bitand(flag,1), 0, 'N', 'Y')='Y' and LRBA_BNO>0
AND OBJ >0;
DIRTY_COUNT MAX(HSCN_BAS) MAX(TCH) MAX(HSUB_SCN) MIN(LRBA_BNO) SUM(DECODE(OBJ,87363,1,0))
----------- ------------- ---------- ------------- ------------- --------------------------
2190 968226 13 1 2 28
3. 先更新其他表制造脏块,再更新要DROP的表
SQL> update test.tobj1 set object_id=object_id where rownum<100000;
86260 rows updated.
SQL> commit;
Commit complete.
SQL> update test.tobj2 set object_id=object_id where rownum<100;
99 rows updated.
SQL> commit;
Commit complete.
SELECT
COUNT(*) AS dirty_count,max(HSCN_BAS),max(tch),max(HSUB_SCN),min(LRBA_BNO),sum(decode(OBJ,87363,1,0))
FROM
X$BH
WHERE
DBABLK != 0
AND /*DIRTY*/ decode(bitand(flag,1), 0, 'N', 'Y')='Y' and LRBA_BNO>0
AND OBJ >0;
DIRTY_COUNT MAX(HSCN_BAS) MAX(TCH) MAX(HSUB_SCN) MIN(LRBA_BNO) SUM(DECODE(OBJ,87363,1,0))
----------- ------------- ---------- ------------- ------------- --------------------------
4717 968294 13 1 2 30
此时,BUFFER CACHE中总的脏块从2190增长到4717,而TOBJ2对象的脏块有30个。
4. 执行DROP TABLE
SQL> drop table test.tobj2 purge;
Table dropped.
5. 再次统计脏块
DIRTY_COUNT MAX(HSCN_BAS) MAX(TCH) MAX(HSUB_SCN) MIN(LRBA_BNO) SUM(DECODE(OBJ,87363,1,0))
----------- ------------- ---------- ------------- ------------- --------------------------
4692 968336 23 1 2 0
可以看到,总的脏块还剩4692,而TOBJ2对象的脏块已为0。这说明DROP操作并非等待所有脏块落盘,而是仅等待被删除对象相关的脏块落盘。
二级分区表,DROP一级分区时,等待一次检查点还是多次?
为了深入理解内部流程,我们进行以下步骤:
- 创建一个二级分区表,每个一级分区下有500个二级分区。
- 开启10046 Level 12跟踪。
- 执行DROP一级分区。
- 关闭10046跟踪。
- 分析生成的trace文件。
主要流程如下:
-
将需要DROP的所有segment(表、分区、索引等)设置为临时段。
核心操作是更新seg$系统表,将type#字段修改为3(TEMPORARY)。
update seg$ set type#=3 ... where ts#=:1 and file#=:2 and block#=:3
-- type#=3 = TEMPORARY
-- type# number not null, /* segment type (see KTS.H): */
-- /* 1 = UNDO, 2 = SAVE UNDO, 3 = TEMPORARY, 4 = CACHE, 5 = DATA, 6 = INDEX */
-- /* 7 = SORT 8 = LOB 9 = Space Header 10 = System Managed Undo */
-
遍历每个segment,发起fast object reuse和block range reuse ckpt检查点,并等待enq: RO - fast object reuse和enq: CR - block range reuse ckpt事件。这两个等待事件在trace中是交替出现的,意味着每个(或每批)segment的清理都可能触发独立的检查点等待。
-
最后,从seg$表中删除对应的segment记录。
delete from seg$ where ts#=:1 and file#=:2 and block#=:3
(以下为创建测试二级分区表的DDL,供参考)
CREATE TABLE test.SALES_DATA (
sale_id NUMBER,
sale_date DATE,
region_code VARCHAR2(10),
product_id NUMBER,
amount NUMBER
)
PARTITION BY RANGE (sale_date)
SUBPARTITION BY LIST (region_code)
SUBPARTITION TEMPLATE (
... -- 此处省略了500个子分区定义
)
(
PARTITION p_20250101 VALUES LESS THAN (TO_DATE('2025-01-02', 'YYYY-MM-DD')),
PARTITION p_20250102 VALUES LESS THAN (TO_DATE('2025-01-03', 'YYYY-MM-DD'))
);
耗时分析
综合以上分析,DROP PARTITION操作耗时主要来自两方面:
- 递归SQL执行耗时:从10046 trace文件可以看到,DROP一个包含大量子分区的一级分区时,涉及数据字典操作的递归SQL执行次数可能高达数万次,这部分的总耗时较长。
-
等待检查点的耗时:仅考虑单实例情况。对于520个分区(假设每个一级分区有500个子分区,加上对应的本地索引段),如果只是段头(Segment Header)是脏块,那么至少会产生 520 * 4 = 2080 个脏块需要写入。
假设写一个脏块平均耗时5毫秒,那么仅等待脏块落盘的时间就可能达到 2080 * 5 / 1000 ≈ 10.4 秒。在RAC多节点环境下,或当BUFFER CACHE非常大、扫描脏块效率低时,这个时间可能会更长。此外,磁盘IO性能、系统负载等因素也会直接影响检查点完成速度,这些都是数据库运维中需要持续关注和性能优化的关键点。
结论:对于拥有大量子分区的分区表,DROP PARTITION操作耗时的核心瓶颈之一,在于需要为每个(或每批)被删除的segment等待其专属的脏块检查点完成。分区数量越多,这个等待过程被重复的次数就越多,总耗时也线性增长。
 发表于 2025-12-9 05:33:31
|
查看: 182|
回复: 0
发表于 2025-12-9 05:33:31
|
查看: 182|
回复: 0
