如果说过去七年是 Transformer 的黄金时代,那么从2026年开始,空气中已经隐隐飘着“范式更替”的味道。不久前,Sam Altman 在斯坦福的一场访谈中抛出了一个重磅判断:Transformer的寿命快到头了,下一代架构已经在路上。
奥特曼在最新访谈中直言,我们所追求的 AGI 可能只是一次“热身”。真正的革命正在酝酿——下一代架构突破已经在路上。现有的高阶大模型已经具备足够的认知力,它们不只是工具,而是人类智力的杠杆,正在亲手推开另一个技术范式的大门。
这场革命的核心,正是由 Albert Gu 和 Tri Dao 在 2023 年底提出的全新架构:Mamba。它彻底绕开了注意力机制,改用状态空间模型(SSM)来处理序列。简单来说,Transformer 读一句话要让每个词和其他所有词“对视”一遍,而 Mamba 只维护一个固定大小的记忆状态,线性时间就能完成,推理吞吐量直接快上五倍。
到了 2026 年初,Mamba 已经进化到第三代—— Mamba‑3。
为什么Mamba‑3是当下最值得关注的架构突破?
Transformer 的成功毋庸置疑,它撑起了 GPT、Claude、Gemini 等一系列划时代模型。但它也有一个无法回避的致命弱点—— 算力黑洞。序列长度翻十倍,计算量直接翻一百倍,KV Cache 随着上下文线性膨胀,推理成本高到让大模型部署变成“富人游戏”。当模型越来越大、上下文越来越长、推理越来越频繁,Transformer 的结构性瓶颈已经成为整个行业的天花板。
于是,另一条路线悄然崛起:线性模型(SSM / State Space Models)。 它们不依赖全局注意力,而是通过固定大小的状态向量来处理序列,理论上能做到 线性复杂度+常数内存。
从 S4 到Mamba‑1,再到 2024 年的 Mamba‑2,这条路线一路狂飙,甚至被 NVIDIA、微软、AI21 等巨头大规模采用。
但线性模型也有自己的短板:它们的表达能力不如 Transformer,尤其在状态跟踪、复杂动态建模上表现乏力;它们的离散化方法粗糙,理论基础薄弱;它们的推理阶段虽然复杂度低,但在 GPU 上却是典型的 memory‑bound,算力利用率极低。
就在这种“希望与瓶颈并存”的关键节点, Mamba‑3出现了!
这不是一次常规的版本升级,而是一场彻底的架构重构。 它的核心理念只有一句话: Inference‑First(推理优先)。
不是为了训练更快,而是为了推理更强;不是为了模型更大,而是为了模型更聪明;不是为了延续旧范式,而是为了打开新范式的大门。
Mamba‑3 的三大创新——指数‑梯形离散化、复数状态空间模型、MIMO推理结构,分别对应线性模型的三大痛点:精度、能力、效率。
研究团队由当今 SSM 领域最强的组合构成:
- CMU(Carnegie Mellon University):SSM 理论源头,Albert Gu、Zico Kolter 坐镇。
- Princeton University:工程实现与大规模实验。
- Together AI(Tri Dao):FlashAttention 发明者,GPU kernel 优化大师。
- Cartesia AI:SSM 商业化落地团队。
这支队伍几乎囊括了整个 SSM 体系的核心人物,是名副其实的“原班人马 + 工程铁军”。
从 S4 到 Mamba‑1,再到Mamba‑2,SSM 的发展史本身就是一条不断逼近 Transformer 的曲线。而 Mamba‑3 的出现,则让这条曲线第一次出现了明显的“超越拐点”。
Transformer 的故事已经讲了太久,但它的成功与局限,恰恰构成了 Mamba‑3 崛起的背景。
Transformer 的最大优势,是它的 全局注意力机制。 每个 token 都能与其他所有 token 交互,这让模型具备了极强的表达能力,尤其在语言建模、推理、代码生成等任务上表现惊艳。
但这种“全局对视”也带来了巨大的代价:计算复杂度O(n²),序列越长越难受;KV Cache线性增长,推理时内存压力爆炸;长上下文成本高昂,让大模型的推理变成奢侈品。
当上下文从 4K → 128K → 1M,Transformer 的结构性矛盾被无限放大。 这不是工程优化能解决的问题,而是架构本身的限制。
于是,另一条路线开始被重新审视:状态空间模型(SSM)。
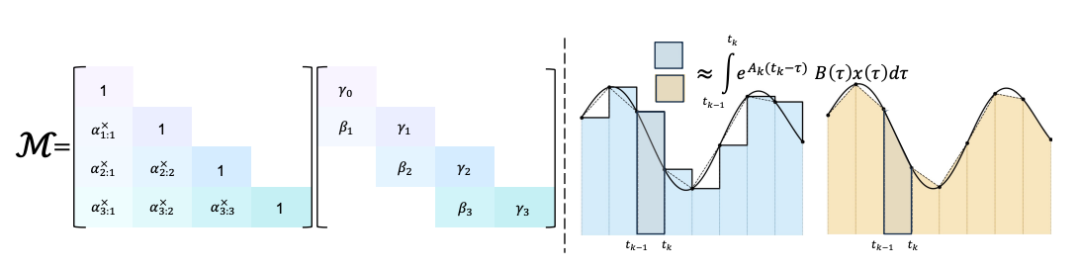
图:左:指数梯形规则诱导的结构化掩模是衰减和双频卷积掩模的乘积。右图:Euler(保持端点)与梯形(平均端点)积分近似。
SSM 的核心思想非常简单: 不让所有 token 互相“对视”,而是维护一个固定大小的“状态向量”,随着序列推进不断更新。 这意味着计算复杂度线性、内存占用常数级、天然适合长序列。
从 S4 到 S5,SSM 在学术界逐渐成熟。从 Mamba‑1 到 Mamba‑2,它开始进入工业界,成为 Transformer 的重要替代方案。
Mamba‑1 解决了训练效率问题, Mamba‑2 进一步优化了推理速度; 但它们仍然存在三个关键缺陷:
- 离散化方法粗糙,表达能力有限。
- 无法处理复杂的状态跟踪任务。
- 推理阶段算力利用率极低(memory‑bound)。
这三点限制了线性模型的上限,也让它们始终无法真正撼动 Transformer 的统治地位。
Mamba‑3 的设计哲学正是在这种背景下诞生的。它不是为了让模型训练更快,而是为了让模型推理更强;不是为了让模型更大,而是为了让模型更聪明。 Inference‑First(推理优先)是 Mamba‑3 的灵魂。
它的目标非常明确:在保持线性复杂度的前提下, 同时提升模型的表达能力、状态跟踪能力与推理硬件效率。这也是为什么 Mamba‑3 被视为“后Transformer 时代”的重要候选架构。
核心创新一:指数‑梯形离散化(Exponential‑Trapezoidal)
如果把 Mamba‑1/2 比作一台“能跑但不够精密”的线性引擎,那么 Mamba‑3 做的第一件事,就是把这台引擎的燃油系统彻底换掉。过去的 Mamba‑1/2 使用的是最简单的 Euler 离散化,这种方法的优点是快,但缺点也非常明显:它只有一阶精度,误差会随着序列长度不断累积,像滚雪球一样越滚越大。
在长序列任务里,这种误差累积会直接限制模型对局部结构的表达能力。你可以把它想象成模型每走一步都会“踩偏一点点”,走得越远,偏差越大。
Mamba‑2 的状态更新公式非常简单,核心形式是:
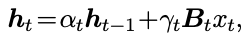
h_t = α_t h_{t-1} + γ_t B_t x_t
其中
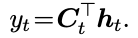
y_t = C_t^T h_t.
这看起来还不错,但本质上仍然是一阶近似。
Mamba‑3 的作者显然对这种“粗糙的近似”不满意,于是他们回到连续时间的状态空间模型,从数学原理重新推导离散化方法。连续 SSM 的基本形式是:
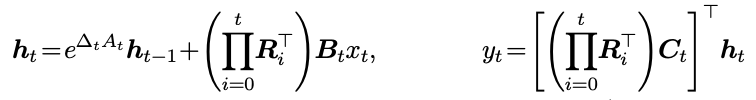
h_t = e^{Δ_t A_t} h_{t-1} + (∏_{i=0}^t R_i^⊤) B_t x_t, y_t = [(∏_{i=0}^t R_i^⊤) C_t]^⊤ h_t
关键突破点在于:Mamba‑3 不再只看区间右端点,而是同时看左右两个端点的加权平均,这就是所谓的“指数‑梯形离散化”。它的本质,是把输入项的积分从一阶精度提升到二阶精度。
最终得到的离散化形式是:
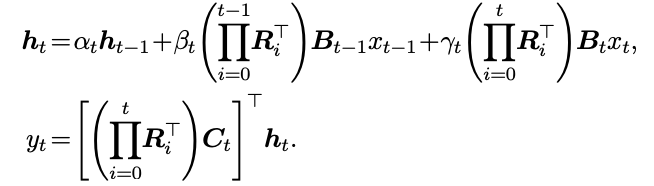
h_t = α_t h_{t-1} + β_t (Π_{i=0}^{t-1} R_i^T) B_{t-1} x_{t-1} + γ_t (Π_{i=0}^t R_i^T) B_t x_t, y_t = [ (Π_{i=0}^t R_i^T) C_t ]^T h_t.
这是一个核心数学公式,也是 Mamba‑3 的关键升级点。
它的意义非常深远:模型不再只看当前 token,而是同时看当前和上一个 token 的组合。Mamba‑3 的状态更新天然带有一个“隐式宽度 2 的卷积”,让它在捕捉局部结构时更加精确、更加稳定。
这项升级带来的效果是立竿见影的。 Mamba‑3 不再需要额外的短卷积层,语言建模质量显著提升,长序列任务中的误差累积也大幅减少。对于一个线性模型来说,这几乎是一次“底层数学级别”的能力增强。
核心创新二:复数状态空间模型(Complex SSM)
如果说指数‑梯形离散化是“精度升级”,那么复数 SSM 则是“能力升级”。
线性模型一直有一个致命弱点:它们的状态转移矩阵通常是实数、非负、对角的。这意味着它们只能表达“衰减”或“累积”,却无法表达“旋转”或“周期性”。
而很多状态跟踪任务——比如 parity(奇偶性)、括号匹配、计数器——本质上都需要一种“旋转式”的状态更新。但 Mamba‑2 的实数对角矩阵根本做不到这一点,于是它在这些任务上表现得几乎和随机猜测一样。
Mamba‑3 的作者做了一件非常聪明的事:他们引入了复数状态空间模型。复数 SSM 的连续形式允许状态在复平面上旋转,而不是只能衰减或累积。离散化后,它等价于一个由 2×2 旋转矩阵组成的块对角矩阵。
更妙的是,研究团队证明复数 SSM 等价于对 B、C 做数据依赖的 RoPE(旋转位置编码)。也就是说,Mamba‑3 不需要真正使用复数,只需要用 RoPE trick 就能实现复数动态。
这项创新带来的能力提升是质变级别的。Mamba‑3 在所有状态跟踪任务上几乎满分,而 Mamba‑2 则完全失败。这意味着线性模型第一次在“能力维度”上实现了真正的突破。
如果说前两个创新解决的是“模型能力”,那么 MIMO 则是解决“硬件效率”的终极武器。
线性模型的推理虽然是 O(n),但在 GPU 上却是典型的 memory‑bound, 算力闲着,显存带宽却被打满。
研究给出的数字非常直观:SSM 推理算强度:2.5 ops/byte,H100 的理论算强度:295 ops/byte。这意味着 GPU 的绝大部分算力都被浪费了。
MIMO的设计思想
Mamba‑3 的作者提出了一个非常工程化的解决方案:把 SISO(单输入单输出)扩展为 MIMO(多输入多输出)。
原本的状态更新是一个外积:B_t x_t^⊤,而 MIMO 把它变成了一个矩阵乘法:B_t X_t^⊤。
这件事带来了两个巨大好处:算强度提升 4×,GPU 的 Tensor Core 能真正被吃满。更关键的是延迟几乎不变。因为推理仍然是 memory‑bound,算力变多不会拖慢速度。
带来的能力提升
MIMO 的效果非常显著:推理效率显著提升,模型质量进一步提升(尤其是 MIMO 版本的 Mamba‑3),更适合 agentic workflows、并行推理、长上下文任务。
这让 Mamba‑3 不仅是一个“更强的模型”,更是一个“更适合部署的模型”。
Mamba‑3的整体架构设计
如果说 Mamba‑3 的三大数学创新是“发动机重做”,那么它的整体架构,就是把这台新引擎装进一辆真正能跑的车里。研究在工程层面做了大量细致的打磨,让 Mamba‑3 不只是一个理论上更强的模型,而是一个可以大规模训练、部署、落地的工业级架构。
Llama风格的Block结构更现代、更稳定、更易扩展
Mamba‑3 的整体结构,直接采用了 Llama 系列的经典布局:Mamba‑3 Block与SwiGLU前馈层交替堆叠,采用Pre‑Norm结构。
这意味着它不再像 Mamba‑1/2 那样需要额外的短卷积层来弥补表达能力。 因为指数‑梯形离散化本身就已经在状态更新中引入了“隐式卷积”,短卷积层自然就可以被移除。
这让 Mamba‑3 的 Block 更加简洁,也更接近 Transformer 的工业标准结构,方便与现有训练框架兼容。
BCNorm:线性模型的QKNorm时刻
Transformer 世界里有一个非常重要的技巧:QKNorm。 它能稳定注意力分布,提升大模型训练的稳定性。
Mamba‑3 借鉴了这一点,在 B、C 投影后加入了 RMSNorm,称为 BCNorm。
它的作用非常直接:稳定训练、减少梯度爆炸、提升大模型性能、让 Mamba‑3 不再需要 Mamba‑2 中的“post‑gate RMSNorm”补丁。
在纯 Mamba‑3 模型中,BCNorm 足以保证稳定性; 在混合模型(SSM + Attention)中,BCNorm 甚至是长上下文能力的关键。
B/C Bias让线性模型更像卷积神经网络
研究团队还有一个非常有意思的设计: 在 B、C 投影后加入 可学习的通道偏置(bias)。
这看似微不足道,但在 SSM 里却非常关键。因为 B、C 是状态输入与输出的核心参数,加入 bias 相当于让模型具备了“数据无关的卷积能力”。 这让 Mamba‑3 在表达局部模式时更加灵活,也让它在没有短卷积层的情况下依然能捕捉局部结构。这是一个典型的“工程小改动 → 能力大提升”的例子。
SISO与MIMO:公平对比vs性能巅峰
Mamba‑3 提供两种模式:
- SISO(Single‑Input Single‑Output):这是为了与 Mamba‑2、GDN、Transformer 做公平对比。它的结构与 Mamba‑2 类似,但使用了新的离散化与复数 SSM。
- MIMO(Multi‑Input Multi‑Output):这是 Mamba‑3 的“完全体”。 它把外积变成矩阵乘法,让 GPU 的 Tensor Core 真正吃满。
研究实验显示:SISO 已经比 Mamba‑2 强,MIMO 直接拉开一个档次。如果说 SISO 是“学术版”,MIMO 就是“工业版”。
实验结果:Mamba‑3的性能跃迁
Mamba‑3 的实验结果可以用一句话概括:在保持线性复杂度的前提下,全面超越所有线性模型,并在多个维度逼近甚至超越Transformer。
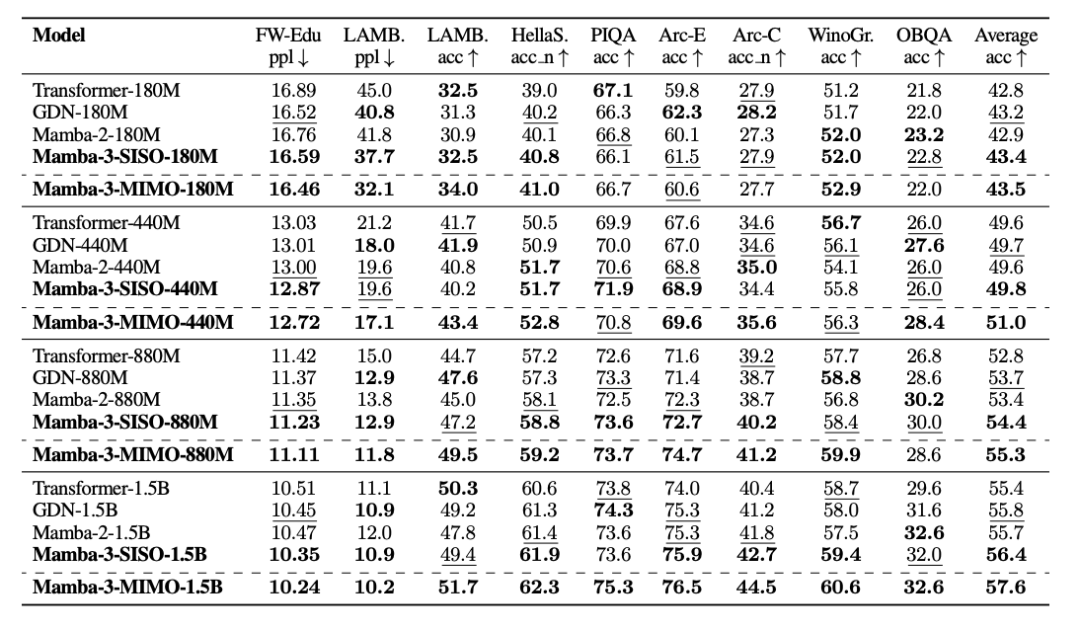
表1:使用100B FineWeb Edu令牌训练的模型的下游语言建模评估。最佳结果以粗体显示,次佳结果以下划线显示。Mamba-3 SISO在每个模型尺度上都优于Mamba-2和其他模型,MIMO进一步提高了建模能力。
语言建模(1.5B 参数):MIMO版本直接起飞
研究给出的结果非常直观:Mamba‑3 SISO:+0.6分(相对 GDN),Mamba‑3 MIMO:+1.8分(相对 GDN)。
这意味着 SISO 已经比 Mamba‑2、GDN更强,MIMO 直接把性能拉到 Transformer 同级甚至更高。在 1.5B 这种“小模型”规模下能做到这一点,非常不容易。
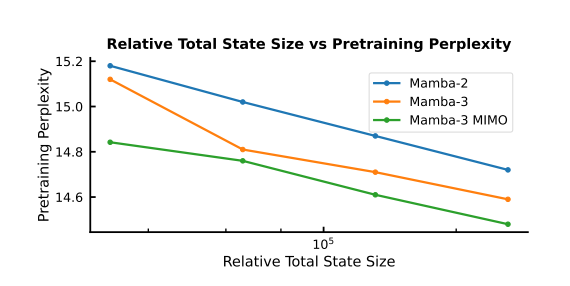
图2:状态大小与预训练困惑度的关系。与之前的循环单输入单输出模型相比,Mamba-3改进了帕累托前沿,MIMO进一步改变了前沿。
状态跟踪任务:复数 SSM 的碾压式胜利
研究团队展示了一个非常关键的实验:parity、括号匹配、计数器等任务。
结果几乎是“降维打击”:Mamba‑3(复数SSM)几乎满分,Mamba‑3(无复数)≈随机,Mamba‑2 ≈随机。
这说明复数 SSM 的引入不是“锦上添花”,而是“能力质变”。
推理效率:FLOPs ×4,延迟不变
MIMO 的效果非常惊人!推理 FLOPs 提升 4倍,延迟几乎与 Mamba‑2 相同,perplexity 更低。这意味着 Mamba‑3是目前最能吃满GPU的线性模型。
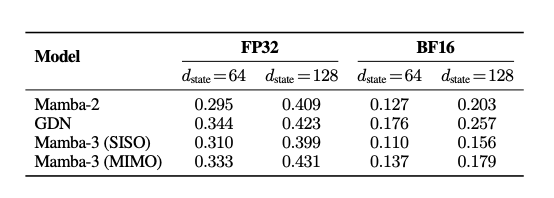
表2:不同模型、精度和状态大小下的内核延迟比较。在常用设置下,Mamba-3 SISO内核比参考Mamba-2和GDN内核快,MIMO几乎不产生额外成本。
检索任务(NIAH):线性模型的天然弱点被部分弥补
在固定状态大小的情况下,线性模型在检索任务上仍然弱于 Transformer。 但 Mamba‑3 在 OOD(长距离 needle)上表现更好,说明它的状态更新更稳定。研究还指出 混合模型(Mamba‑3 + Attention)效果最佳。这也暗示了未来架构的方向。
Mamba‑3的技术价值与产业意义
Mamba‑3 的意义远不止“性能更强”,它在多个维度都指向了下一代架构的趋势。
表达能力质的飞跃:Mamba‑3 让线性模型第一次在表达能力上实现大幅提升。复数 SSM 打开了新的能力空间,二阶离散化让状态更新更精确,隐式卷积让模型更像Transformer。这让 SSM 不再只是“高效但弱”,而是“高效且强”。
硬件效率的革命:MIMO 的出现,让线性模型第一次真正吃满 GPU,推理成本下降,并行推理更高效,更适合 agentic AI、长上下文、工具链调用。这对未来的 AI 应用至关重要。
下一代架构的雏形:Mamba‑3 指向了一个非常明确的趋势:动态状态、线性复杂度、高算强度推理、混合架构(SSM + Attention)。这可能就是下一代 AGI 模型的基础。
产业落地的加速器:Mamba‑3 的出现意味着推理成本下降 → AI 应用规模扩大、状态跟踪增强 → 更智能的 agent、硬件效率提升 → 更快商业落地。它不仅是一个学术成果,更是一个产业信号。
Mamba‑3 不是终点,而是 SSM 路线的重大进化。 它展示了“后Transformer”架构的雏形,也让我们第一次看到线性模型真正具备挑战 Transformer 的可能性。
未来的模型可能是 SSM + Attention + 可微分程序 + 外部记忆。而 Mamba‑3,就是迈向这一未来的关键一步。
如果说 Transformer 开启了大模型时代,那么 Mamba‑3 可能正在开启“后 Transformer 时代”的序幕。

参考资料:
https://openreview.net/forum?id=HwCvaJOiCj&utm_source
本文技术观点由专业社区 云栈社区 编辑梳理,旨在为开发者提供深度、前沿的架构解析。技术演进日新月异,保持学习与讨论是应对变化的最好方式。
 发表于 2026-3-19 03:16:32
|
查看: 238|
回复: 0
发表于 2026-3-19 03:16:32
|
查看: 238|
回复: 0
