在Redis中,有序集合(ZSet)的强大排序能力是其核心特性之一。你是否曾好奇,诸如ZADD、ZRANGE等命令是如何在O(logN)的时间复杂度内,高效处理海量数据排序与范围查询的?其背后的关键引擎,便是跳表(Skip List)。本文将深入Redis 6.2源码,为你一层层拆解跳表的设计原理、实现细节与优化技巧,揭开它成为高性能排序引擎的秘密。
一、跳表的基本原理:平衡树的高效替代者
跳表是一种概率型数据结构,它通过在有序链表上建立多级索引,实现了接近平衡二叉树的查询效率,同时又巧妙地避免了平衡树复杂的旋转操作。Redis中的跳表并非经典实现,它在支持重复元素、基于分值排序等方面做了大量优化。
与红黑树、AVL树等传统平衡树相比,跳表的最大优势在于实现简单和并发友好。它不需要复杂的旋转操作来维持平衡,而是通过随机算法来控制索引的层级分布。这种“以概率换平衡”的策略,在保证平均性能的同时,极大地降低了数据结构的实现和维护复杂度,非常适合像Redis这样追求高性能与代码简洁性的系统。
二、Redis跳表的数据结构定义
在Redis 6.2源码中,跳表的定义位于server.h文件。其核心由两个结构体组成:
typedef struct zskiplistNode {
sds ele; // 元素值
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度,记录两个节点之间的元素个数
} level[]; // 层级数组,柔性数组
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头节点和尾节点
unsigned long length; // 跳表中节点的数量
int level; // 当前跳表的最大层数
} zskiplist;
关键结构解析:
zskiplistNode:跳表的节点单元,包含元素值、分值、后退指针和一个柔性数组level[]。每个节点的层级是随机生成的。level 柔性数组:这是Redis跳表的一个内存优化技巧。level数组在节点创建时根据其随机层数动态分配,避免了固定大小指针数组可能造成的空间浪费。Redis使用幂次定律(P=0.25)生成层数,更高层级出现的概率呈指数下降。span 跨度字段:这是Redis跳表的核心优化之一。它记录了当前节点在某层索引上,到下一个索引节点之间跨越了多少个底层节点。ZRANK、ZREVRANK等命令能实现O(logN)的排名查询,正是通过累加路径上的span值实现的,避免了O(N)的遍历计数。backward 后退指针:每个节点都持有指向其前一个节点的指针,这使得跳表支持高效的反向遍历,为ZREVRANGE等命令提供了实现基础。
三、跳表的插入流程:从顶层到底层的精准定位
跳表的插入是其最核心的操作,代码实现在t_zset.c文件的zslInsert函数中。整个过程可以清晰地分为三个步骤:
1. 查找插入位置并记录路径
在插入新节点前,需要从最高层开始,逐层找到每一层中待插入位置的前驱节点,并记录下来。这一步同时也在计算新节点在每一层的“排名基数”。
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long rank[ZSKIPLIST_MAXLEVEL];
int i, level;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
// 记录当前层的排名
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 查找当前层的前驱节点
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0))) {
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
关键逻辑:
update数组:记录了新节点在每一层索引中的前驱节点,后续调整指针全靠它。rank数组:记录了update[i]节点在跳表中的排名(从0开始),用于精确计算新节点的span值。- 比较逻辑:先比较分值(
score),分值相同则再按元素值(ele)的字典序比较,这确保了ZSet支持同分不同值的有序存储。
- 查找路径:从顶层索引开始,利用索引快速跳过大量节点,逐步向下定位,这是跳表能达到O(logN)效率的关键。
2. 随机生成新节点的层级
节点的层级决定了它拥有多少级索引。Redis使用一个简单的随机算法来保证跳表的平衡性。
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
随机层级算法:
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
其中ZSKIPLIST_P的值为0.25,ZSKIPLIST_MAXLEVEL为64。这意味着:生成第2层的概率是1/4,生成第3层的概率是(1/4)^2,以此类推。这种幂次定律分布保证了索引层数的平衡,使查询效率稳定在O(logN)。
3. 创建新节点并调整指针与跨度
最后一步是创建节点实体,并将其“缝合”到跳表的各级索引链中,同时更新所有相关的span值。
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
// 计算新节点的跨度
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
// 更新那些新节点未到达的更高层的跨度
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 设置后退指针,维护双向链表
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
流程可视化:
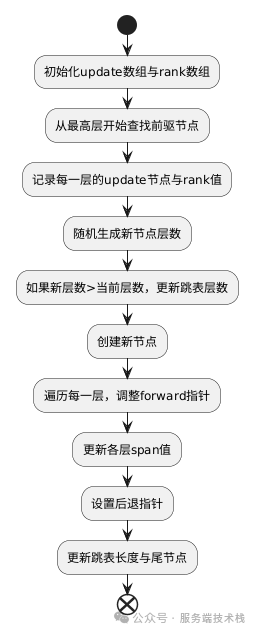
四、跳表的查找与删除流程
查找流程是插入流程的简化版,其核心函数zslFind逻辑与插入时查找update数组的过程几乎一致,都是从高层向底层逐级跳跃定位。
删除流程 (zslDelete) 则像是插入的逆操作:
- 同样先查找目标节点并记录
update路径。
- 调整各层前驱节点的
forward指针和span值,将目标节点从索引链中“摘除”。
- 更新相邻节点的后退指针(
backward)。
- 清理因删除节点而可能变空的顶层索引(
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL) zsl->level--;),优化内存使用。
五、Redis跳表的优化设计精粹
除了基本结构,Redis跳表的工业级优化更值得品味:
- 支持重复分值:通过
score和ele的联合比较,完美支持ZSet“分值可同,成员唯一”的核心语义。
span跨度字段:这是实现O(logN)排名查询(ZRANK)的灵魂,避免了遍历计数的性能瓶颈。- 动态层级调整:插入时可能增加层高,删除时会检测并降低空层,使得内存使用始终高效。
- 内存效率优化:使用C语言的柔性数组存放层级信息,让节点内存布局紧凑,减少内存碎片。
- 双向遍历支持:通过
backward指针,无需额外结构就能支持ZREVRANGE等逆序操作,时间复杂度仍是O(logN)。
六、跳表 vs. 平衡树:Redis的取舍之道
为什么Redis选择跳表而非更“经典”的红黑树来实现ZSet?下表对比揭示了关键原因:
| 特性 |
跳表 (Skip List) |
平衡树 (如红黑树) |
| 平均插入/查找复杂度 |
O(logN) |
O(logN) |
| 最坏情况复杂度 |
O(N) (概率极低) |
O(logN) |
| 实现复杂度 |
简单直观,无需旋转 |
复杂,需处理多种旋转情况 |
| 并发修改友好度 |
更优,修改通常只影响局部节点 |
较差,旋转操作可能影响全局平衡 |
| 范围查询效率 |
高效,找到起点后底层链表线性遍历即可 |
需要中序遍历,相对复杂 |
| 调试与维护难度 |
低,结构可视,逻辑清晰 |
高,旋转逻辑难以跟踪 |
Redis选择跳表的核心考量:
- 实现与维护成本:跳表代码量小,逻辑简单,bug风险低,符合Redis追求极致简洁与可靠性的哲学。
- 并发潜力:跳表的修改操作更局部化,为未来实现无锁(lock-free)或更细粒度的并发控制留下了更好的扩展性。
- 范围查询优势:ZSet的
ZRANGE、ZREVRANGEBYSCORE等范围操作非常频繁,跳表找到范围起点后,沿底层链表遍历即可,性能极高。
- 内存可控性:虽然平均指针数略多于平衡树,但跳表的内存占用是预期内且可计算的,没有平衡树那样的极端情况。
结语
跳表,这个诞生于1989年的数据结构,以其惊人的简洁性,在有序链表和平衡树之间找到了完美的性能平衡点。Redis将其吸纳并深度优化,使之成为支撑ZSet高性能排序的隐形引擎。通过本文对Redis 6.2源码的梳理,我们不仅看到了一个优秀数据结构的实现,更看到了工程设计中在性能、复杂度、可维护性之间的精妙权衡。
你是否在项目中使用过ZSet,又遇到过哪些有趣的性能问题或应用场景?欢迎在云栈社区与更多开发者一起交流探讨。
 发表于 2026-3-20 03:50:03
|
查看: 138|
回复: 0
发表于 2026-3-20 03:50:03
|
查看: 138|
回复: 0
