Token,正在成为AI时代的水和电。谁能在有限的算力下挤压出更高的Token效率,谁就能在这场激烈的技术竞赛中占据更持久的优势。这或许可以解释,为何今年英伟达GTC大会的关注点,正悄然从“谁拥有更多GPU”转向“谁能更聪明地使用GPU”。

刚刚在GTC大会上发表演讲的月之暗面(Moonshot AI)创始人杨植麟,其演讲的一个重要主题正是Token效率。这很可能也是他受邀登上这一顶级舞台的原因之一。
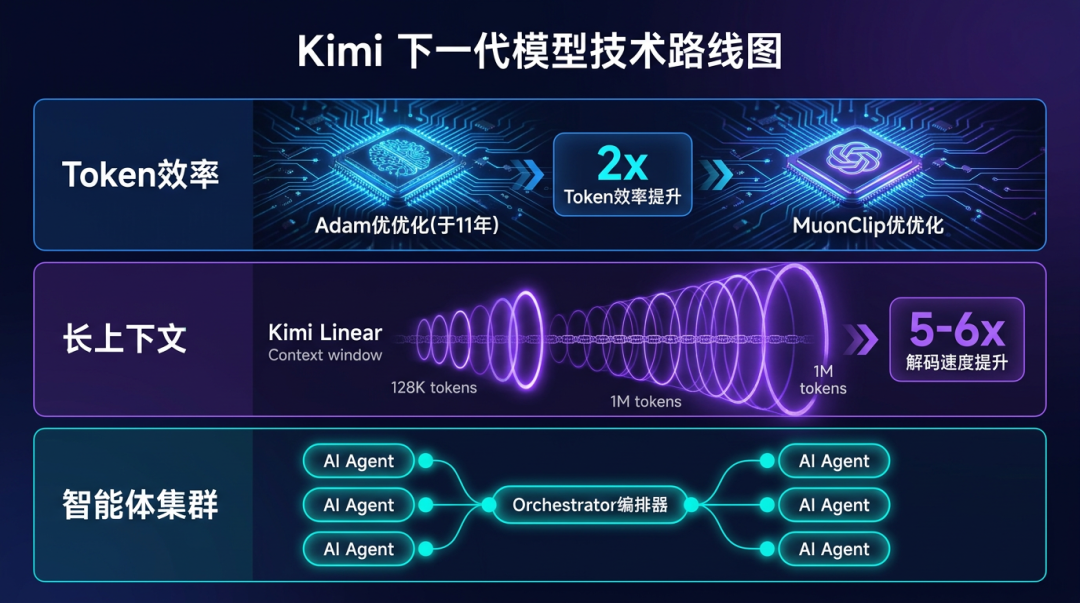
杨植麟的演讲主题《How We Scaled Kimi K2.5》首次完整披露了Kimi下一代模型的技术路线图。他将Kimi的进化逻辑凝练为三个核心维度:
- Token效率:以MuonClip优化器替代已服役11年的Adam,实现Token效率翻倍。
- 长上下文:基于Kimi Linear架构,在128K至1M的上下文窗口内,解码速度提升5-6倍。
- 智能体集群:引入Orchestrator编排器,协调多个AI Agent并行协作。
然而,真正引起业界广泛关注的,是他在演讲中提及的第三项底层创新:Attention Residuals(注意力残差)。

就在GTC召开前两天,Kimi团队正式发布了这项研究的技术报告。马斯克在转发这篇论文时毫不吝啬地称赞道:“Impressive work from Kimi”。
前特斯拉AI总监、OpenAI创始成员之一的Andrej Karpathy在研读后也半开玩笑地评论道:我们是不是对“注意力机制就是一切”这句话理解得还不够透彻?
一篇看似“只”改动了残差连接(Residual Connection)的论文,为何能引发如此高的关注?这要从残差连接本身说起。

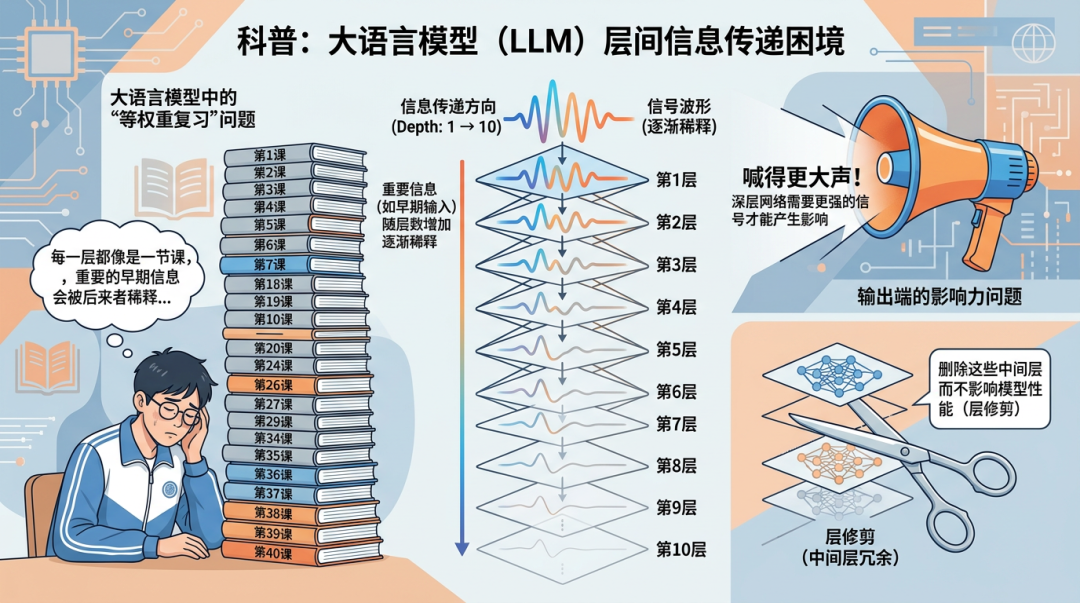
残差连接,这个由ResNet在2015年提出的概念,其核心操作简单得惊人:每一层的输出,等于上一层的输入(即“残差流”)加上本层计算产生的结果。正是这个简单的加法操作,使得训练成百上千层的深度神经网络成为可能,也为后来Transformer架构的稳定训练奠定了基础。
但问题也随之而来:这个加法的权重恒定为1。
这意味着,在信息从第一层流向最后一层的过程中,每一层的贡献都被等权重复制并累加。这好比一个学生上了40门课,期末复习时却不分重点地将所有课堂笔记等量堆叠在一起看。
其结果就是:
- 早期输入的重要信息,在传递到深层网络时已被严重稀释。
- 深层网络若想对最终输出产生显著影响,其“计算声音”必须比前面所有层加起来还要“响亮”。
- 甚至有研究表明,许多大模型中相当一部分中间层可以被直接“修剪”掉,而模型性能几乎不受影响。
这个沿用近十年的设计,并非完美,只是“足够好用”让人们失去了深入追问的动力。
业界并非没有尝试改进。例如,DeepSeek在去年底提出的mHC(流形约束超连接)架构,其核心思路是让残差连接的权重从固定值变为可学习的参数,让模型自己学会如何混合各层信号。
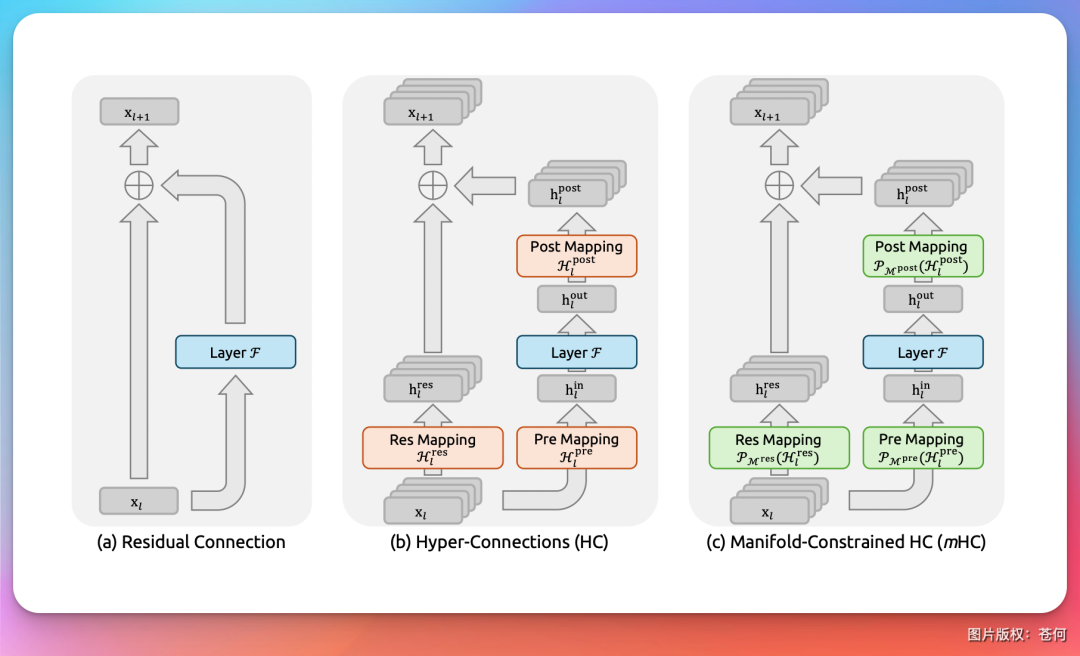
这个方向是正确的,但仍存在一个根本性局限:这些学习到的权重在训练完成后就被固定下来。 无论输入什么内容,模型各层之间信号的混合方式都是一成不变的。更重要的是,信息一旦被混合进累积的“状态”中,就无法再被单独检索和审视。
Kimi团队的Attention Residuals则提出了一个更根本的解决方案,其灵感来源于一个精妙的类比。
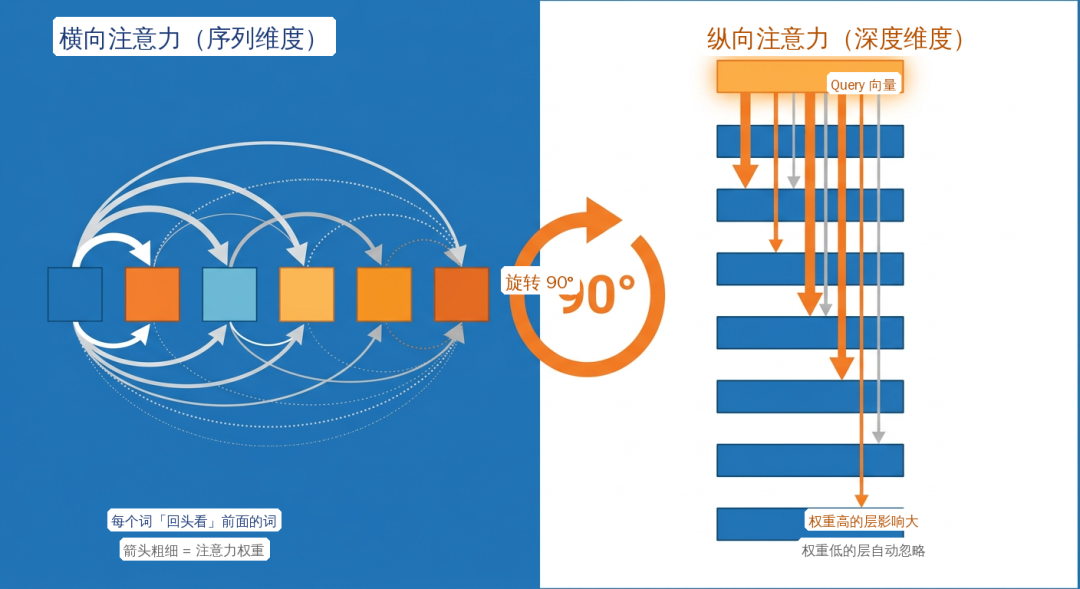
标准的Transformer在处理一个序列时,其注意力机制是“横向”工作的:序列中的每个词(Token)都可以“回头看”前面所有的词,并根据语义相关性动态分配注意力权重。
Kimi团队思考:为什么这种动态的、内容感知的注意力机制,不能应用在网络的“纵向”,即深度维度上呢?
于是,他们提出了将注意力机制“旋转90度”的构想——从序列维度转向层与层之间的深度维度。
具体而言,在Attention Residuals架构下,每一层(或每一组层)都配备了一个可学习的查询向量(Query)。这个Query会对所有前序层(或前序模块)的输出(作为Key和Value)做注意力计算。这样,模型就能根据当前处理的内容,动态决定哪些深层或浅层的特征更为重要,并给予相应的权重,无关紧要的层则会被自动忽略。
回到学生的比喻:现在他拥有了一套智能复习系统。面对每道具体的题目(即不同的模型输入),系统会实时分析并动态地从40门课的笔记中,筛选出与当前题目最相关的几份重点进行复习。
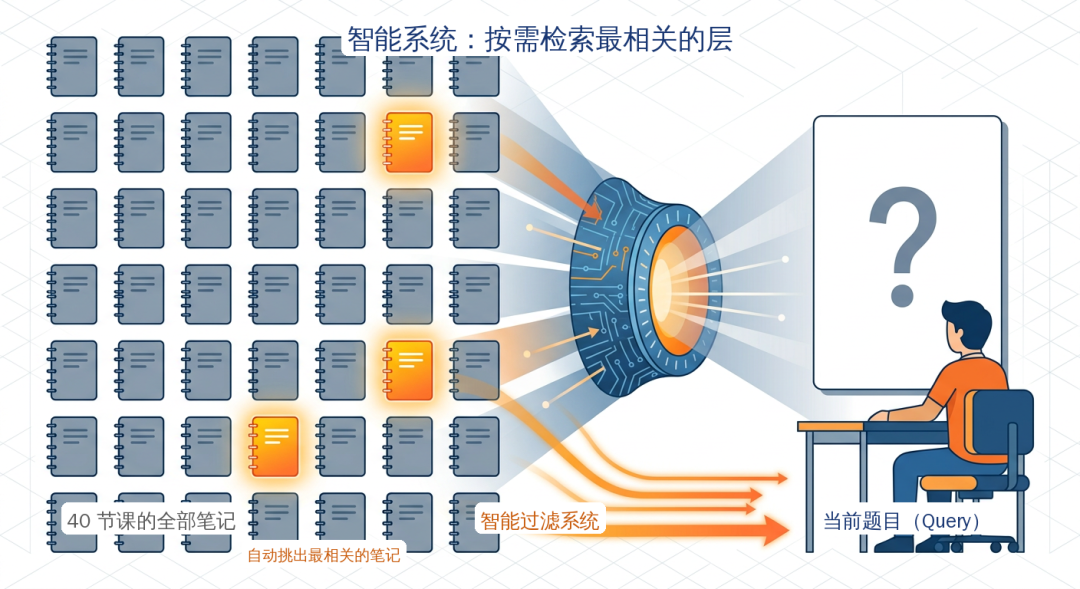
最关键的区别在于,这种层间的注意力权重是完全动态、输入相关的,而非训练后固定不变的。
效果:近乎免费的性能提升,等效于节省20-25%算力
在工程实现上,为了平衡效果与开销,Kimi团队采用了“块注意力残差”设计:将整个模型划分为约8个块(Block),块内部使用传统残差连接以保证效率,块与块之间则应用动态的注意力残差连接。最终,这项改进带来的额外推理延迟不到2%,代价几乎可以忽略不计。
在Kimi自家的48B总参数(3B激活参数)的Kimi Linear模型上进行验证,Attention Residuals带来了显著的性能提升:
- GPQA-Diamond(科学推理):+7.5分
- MATH(数学):+3.6分
- HumanEval(代码生成):+3.1分
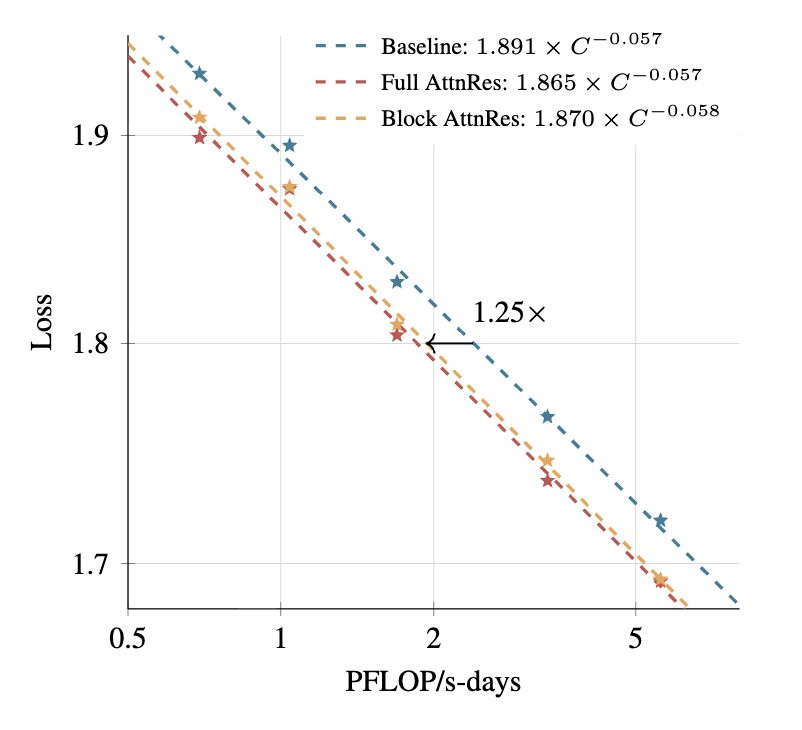
根据论文中的缩放定律分析,在相同计算预算下,采用Attention Residuals的模型性能更优。反之,要达到相同的性能水平,所需的训练预算减少了约20%。这相当于不增加任何硬件和数据投入,仅通过优化模型内部的信息流动结构,就“白赚”了25%的算力效果。
结语:大模型竞争进入“拆地基”深水区
近年来,大模型的竞争往往被简化为参数规模、数据量和计算卡数量的比拼。然而,从本届GTC传递出的信号来看,风向正在转变。
黄仁勋比任何人都清楚,单纯依赖暴力堆砌算力的时代正在触及天花板。他需要在舞台上展示的,是那些能够“更聪明地运用算力”的创新者。
杨植麟在GTC上展示的MuonClip优化器、Kimi Linear架构以及Attention Residuals,无一不在回答同一个核心命题:如何用更少的资源,训练出能力更强的模型。
Adam优化器用了11年,注意力机制成为主流已8年,残差连接更是基石般的存在了10年。这些底层组件并非不可撼动,只是大多数人默认为“无需改动”。
当整个行业仍在思考如何获取更多算力时,真正的突破或许正来自于思考如何让每一单位算力产生的每一个Token都更具价值。这正是像Kimi这样的团队,通过深入开源实战与基础研究,试图向世界展示的方向。
从DeepSeek到Kimi,中国大模型团队的技术创新正触及越来越深的层次:从训练方法和工程技巧,到核心网络架构设计,直至最底层的神经网络信号传递机制。
“大力出奇迹”的叙事已经持续了太久。下一阶段的竞争,无疑将属于那些敢于质疑并动手改造“地基”的人。对于广大开发者和研究者而言,关注这些智能 & 数据 & 云领域最前沿的突破,是保持技术敏锐度的关键。更多深入的技术讨论与资源分享,欢迎访问云栈社区进行交流。
 发表于 2026-3-20 09:32:04
|
查看: 114|
回复: 0
发表于 2026-3-20 09:32:04
|
查看: 114|
回复: 0
