
现代软件开发正面临一个深刻的认知困境:AI能轻松写出语法正确的代码,却难以理解这些代码在具体工程上下文中的真实含义。更深一层看,即便模型能力再强,如果缺乏结构化的工程约束与上下文支撑,智能体也难以稳定、可预期地完成真实的复杂工程任务。
当前主流的AI编程智能体,在项目级的语义理解上普遍存在短板:
- 感知范围狭窄:通常只围绕当前查询进行局部检索,缺乏对项目整体结构的上下文感知。
- 知识碎片化:返回的代码片段彼此孤立,难以还原它们在系统中的真实语义角色和关联。
- 高维上下文缺失:传统工具只能获取低维的代码细节数据,难以捕捉设计意图、历史决策等隐性的“为什么”知识。
这些局限导致AI智能体只能进行“逐点”的上下文检索,缺少对代码库的“立体”感知。业界逐渐形成的共识是,要让AI智能体真正可用,需要构建一套完整的 Harness Engineering 体系,这包括环境设计、意图规范、反馈循环、可观测性工具、架构约束、上下文工程等。而其中,工程知识底座(涵盖代码规范、架构约束、反馈循环与知识积累机制)起到了至关重要的支撑作用。只有当这套底座足够扎实,智能体才能从“偶尔可用”的玩具,走向“持续可靠”的生产力伙伴。
工程知识引擎:从“点”到“立体”的工程感知
为了解决上述难题,我们构建了 工程知识引擎——一套多维融合的代码认知系统。它通过整合代码文件、提交历史、RepoWiki、记忆卡片等多维数据源,为AI智能体赋予深度的上下文理解能力。
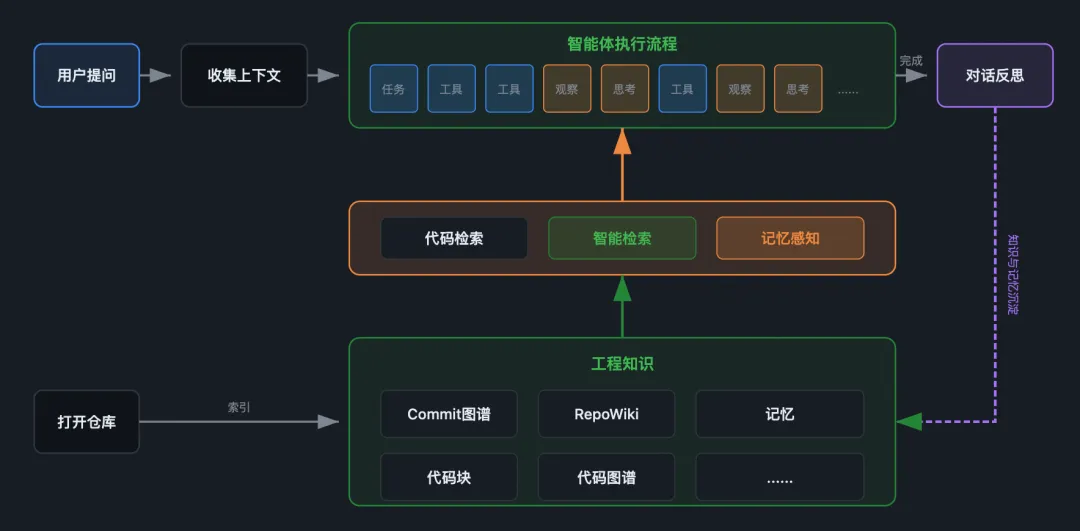
系统会自动构建工程知识引擎的数据层,主动分析并构建 Commit Graph、RepoWiki、Memory、Code Chunk、Code Graph 等多元索引,将原本离散的工程信息编织成立体的知识网络。智能体可以通过多个检索工具,从这个多维知识图谱中获取丰富的上下文支撑——不再只是孤立的代码片段,而是带有设计模式、关联关系和历史沿革的立体信息。
更重要的是,这套系统构建了完整的 知识正循环 机制。一方面,任务完成后,引擎会自动对对话过程进行分析与评估,从中提炼有价值的工程洞察,沉淀为持久化记忆;另一方面,当代码库发生 Git Commit 更新时,系统会实时捕获变更,自动分析增量代码的语义与影响,并将新知识同步沉淀到 RepoWiki 中,确保知识库与代码库始终保持同步演进。
这意味着,智能体使用得越多、代码迭代越频繁,知识积累就越丰富,理解能力也越强——从“被动检索”走向“主动学习”,实现工程知识的自我进化与持续增值。智能体的能力边界,在很大程度上由其运行的工程环境共同决定。
1. 向量检索:基础检索能力
向量检索构成了智能体感知代码世界的底层“触觉”。它使得自然语言查询能够直接映射到语义相关的代码实体,摒弃了传统 grep 式工具依赖关键词匹配的盲目试探。通过高效的索引调度策略,相比业界同类产品,我们的索引耗时平均减少5倍,95%的新开代码库仅需不到1分钟即可完成索引。
2. 代码图谱:从语法到语义的升维
代码图谱通过显式建模代码间的语义关系(如调用、引用、继承、实现等),极大地提升了智能体对代码库符号关系的认知。当智能体查询“如何实现用户登录验证”时,它不仅能获取到直接的登录逻辑代码片段,还能通过图谱关系智能地联想出鉴权逻辑、Token 服务、用户信息查询等完整的上下文链。这对于理解复杂的后端 & 架构至关重要。
3. Commit图谱:打通意图到代码的语义桥梁
智能体通过传统检索工具查询代码时,只能通过嵌入向量将自然语言与代码片段进行“黑盒”映射,无法覆盖高层次语义信号。而 Commit Message 天然具备高层次语义概括能力,架起了“做什么”(意图)与“怎么做”(实现)之间的桥梁。我们通过模型对低质量的 Commit Message 进行优化,构建了“Query → Commit Message(意图)→ 代码”的两阶段链路,有效弥合了高层需求与底层实现之间的语义鸿沟。
4. RepoWiki:高阶知识的沉淀池
代码图谱、Commit图谱和Chunk向量检索结合,起到了“由点及面”的效果。但智能体如果过度依赖局部上下文和通用代码模式,就会忽视项目特有的设计语言与架构约束,导致生成的代码虽然语法正确,却与项目风格和架构设计格格不入。RepoWiki 能够自动生成并维护项目的架构设计、功能模块说明、开发规范等高阶知识,形成一个能够跟随代码库持续演进的“活”知识库。你可以将其理解为项目专属的、不断更新的技术文档核心。
5. 记忆系统:持久化的个性化记忆能力
记忆系统赋予了AI智能体持久化记忆能力,帮助工程知识引擎加强对项目配置、开发规范、历史任务中的设计决策及变更文件的感知。记忆系统会基于每轮的对话消息进行分析挖掘,抽象出有价值的记忆卡片,并通过自动整理汰换、价值评估等机制实现记忆的自我演进。
6. Agentic Search:面向任务目标的自适应上下文编排引擎
如果说前述五大能力是工程知识引擎的“感官”与“记忆”,那么 Agentic Search 就是它的“认知中枢”——一个将多源异构知识进行动态调度、按需融合、自主推理的任务驱动型检索决策框架。
传统检索工具(如 grep_code 或单模态向量搜索)每次只会返回单一类型的检索结果,主智能体需要不断地自我迭代,调用多次传统工具来采集信息。这种方式在面对复杂工程任务时,极易检索出大量无关上下文,导致“上下文窗口腐化”。
Agentic Search 的核心价值在于 将检索本身升格为可规划、可反思、可迭代的子任务。它基于当前任务目标、已有上下文的置信度、各知识源的覆盖盲区与语义粒度,实时生成并执行最优的 多跳检索策略。
例如,面对这样一个请求:“请为订单服务新增幂等校验,兼容现有的 Redis 分布式锁机制,并避免与库存扣减优化逻辑冲突”,Agentic Search 会自动编排如下推理路径:
- 意图锚定:通过 Commit 图谱定位
inventory optimization 相关提交,提取其变更范围与设计约束。
- 语义对齐:调用代码图谱,识别
RedisDistributedLock 类的继承链、被调用方及关键方法签名,确保新逻辑与锁的生命周期兼容。
- 规范校验:查询 RepoWiki 中《订单服务幂等设计规范》章节,获取 idempotency key 生成规则与失败重试策略。
- 记忆增强:激活记忆系统,召回过往类似任务的经验(例如,采用基于 DB 唯一索引的方案,还是基于 Token UUID 的方案),主动规避已知的坑点。
效果评估
1. 效果演示
在相同的基础模型下,工程知识引擎的引入显著优化了任务检索阶段智能体的执行效率。相比传统“工具调用+自我迭代”的方案,其工具调用轮次与频次大幅降低,直接带动全局 Token 消耗下降约 21%。得益于引擎的高精度召回与上下文编排能力,系统表现出极强的逻辑鲁棒性,能够精准规避对非相关文件(如 cache.py)的误触改动,有效消除了代码生成的副作用。
2. 离线评估
在自研评测集 Qoder Agent Bench 上,启用工程知识引擎的实验组表现显著优于基线:
- 任务完成度得分提升 12%。
- 平均 token 消耗降低 14%。
- 相较于业界主流方案,代码检索的 F-Score 提升 21%。
- 启用 Agentic Search 后,相比于单一的语义检索,主模型的 token 消耗进一步降低 10.4%。
这表明,更丰富、更准确的多源上下文不仅提升了任务完成的准确性,也大幅减少了冗余推理与试错成本。Agentic Search 能在保持智能体最终效果的情况下,主动过滤无效信息,实现更高效的上下文利用。
3. 线上 A/B 测试
面向真实用户的 A/B 实验进一步验证了工程知识引擎的实用价值。在相同基础大模型下,启用该引擎的实验组,与仅使用 search_file、grep_code 等传统工具的对照组相比:
- 代码库检索(含向量检索、代码图谱、Commit图谱、RepoWiki):
- 代码保留率提升 1.9%,在 1000 个文件以上的大型代码库中,效果进一步提升至 2.2%。
- 针对复杂任务,模型所需的迭代轮次平均降低 7.1%。
- 记忆系统:
- 代码保留率提升 0.66%。
- 对话不满意率降低 27%。
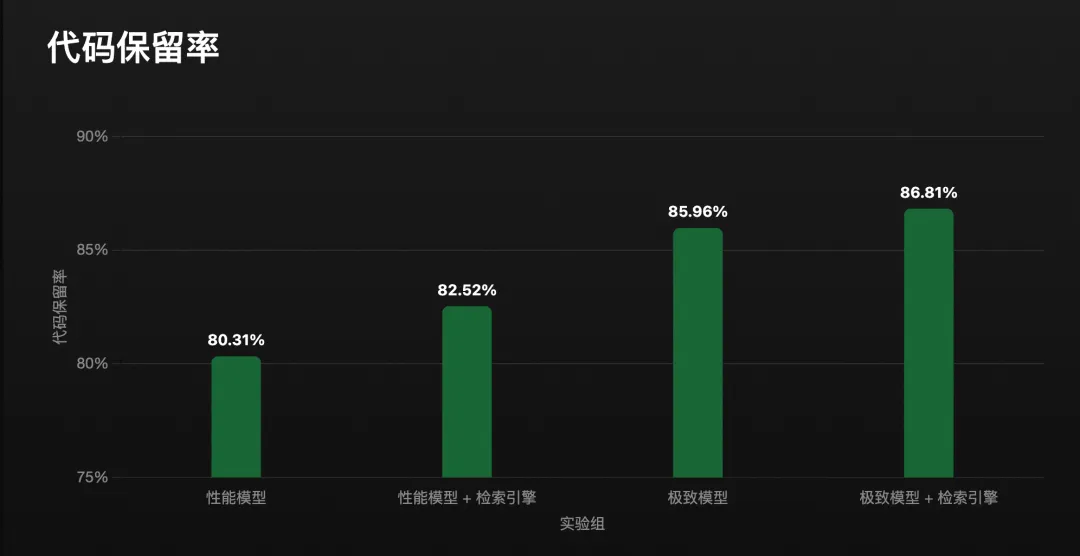
知识引擎赋能智能体,使其生成的代码更精准、更可靠且更符合用户的工程预期,从而显著提升了代码的“存活率”(保留率),并有效降低了用户的对话不满意率。
结论
工程知识引擎的出现,标志着 AI 编程正在从单纯的“代码生成器”向真正的“工程协作者”角色转变。但这一转变能走多远,根本上取决于我们为智能体构建了怎样的工程环境。
实践表明,智能体的质量上限,除了受模型本身的能力制约外,更关键的是由其所在工程底座的完善程度所决定。项目文档是否准确、架构约束是否可被机器理解与执行、知识库能否跟随代码同步演进——这些“基础设施”的质量,直接决定了智能体能否持续、稳定、可预期地完成真实且复杂的工程任务。
在这样的环境中,AI 不仅能看到代码的静态结构,还能理解其背后的意图、设计决策、技术限制以及演进历史。每一次智能体的“失误”,都应成为我们完善工程底座的契机;每一次知识的积累,都在缩小人机协作的认知鸿沟。
这不仅是一次技术上的进步,更是我们对软件工程方法论本身的重新审视:让工程环境足够好,智能体自然会足够好。 这,或许是推动未来软件开发效率实现质变最务实、也最根本的路径。对于希望深入探讨相关技术和架构实践的开发者,欢迎来到云栈社区交流分享。
 发表于 2026-3-20 12:55:40
|
查看: 119|
回复: 0
发表于 2026-3-20 12:55:40
|
查看: 119|
回复: 0
