本文约4500字,建议阅读10分钟。法国南巴黎高等电信学院和巴黎萨克雷大学的研究团队,提出了融合集成学习与SHAP分析的机器学习框架,为HCC肝移植候选者的死亡风险评估提供了新解法。
肝癌因早期隐匿、进展迅猛等特点,素有“癌中之王”的称号。其中,肝细胞癌作为最常见的肝癌类型,占到原发性肝癌的70%-90%。对于许多HCC患者而言,肝移植是早期阶段重要的根治性手段。
然而,供体器官极度稀缺。更棘手的是,HCC肝移植候选者始终面临着肝功能衰竭与肿瘤进展的双重死亡威胁,两者相互交织,极大增加了等待期的死亡风险。因此,精准评估HCC肝移植候选者的等待期死亡风险,是优化移植名单优先级、公平分配稀缺供体,从而高效挽救患者生命的核心挑战。
此前,Child-Pugh、ALBI、MELD等传统评分已广泛应用,但在面对HCC患者的复杂情况时却显露出短板:它们要么侧重肝功能评估,要么仅聚焦肿瘤预测,无法兼顾双重风险。即便后续出现了HALT-HCC、Mehta Model等综合评分系统,也因受限于线性模型和静态测量,难以捕捉因素间的相互作用与疾病的动态变化,无法实现个体化的精准风险评估。
针对这一痛点,法国研究团队提出了融合集成学习与SHAP可解释性分析的机器学习框架。 该研究基于11,647例患者临床数据,对比了随机森林、XGBoost、LightGBM三种集成模型,并通过将SHAP值嵌入UMAP降维空间结合K-medoids进行监督聚类,明确了肝功能障碍和肿瘤进展是HCC患者死亡的两大核心风险。
这一研究填补了此前机器学习模型在精准评估HCC肝移植候选者双重风险方面的空白,实现了对候选者3个月等待期死亡率的精准预测与临床可解释性,为临床决策和风险分层提供了新工具。
相关成果以 “Explainable Mortality Prediction for Liver Transplant Candidates with Hepatocellular Carcinoma: A Supervised Clustering Approach” 为题,发表于 Health Data Science。
研究亮点:
- 首个通过机器学习模型深入分析HCC肝移植候选者等待名单死亡风险的综合性研究。
- 通过SHAP + UMAP + K-medoids实现了7个临床可解释的风险亚组分层,明确了双重风险的核心驱动因素。
- 基于SHAP筛选8个关键变量构建了全新风险评分ELM-HCC,预测精度显著优于传统评分。
- 首次将关键指标动态变量纳入风险评估,明确了其为HCC患者等待期死亡的关键预测指标。
论文地址:https://spj.science.org/doi/10.34133/hds.0295
数据集:大样本策略 + 动态变量引入
为减少混杂因素,研究采用了基于公共数据库的大样本策略。
具体来说,数据来自OPTN和UNOS的STAR文件,覆盖2002年2月27日至2023年9月30日期间登记的非多器官移植成年HCC患者。
研究以预测HCC患者肝移植3个月等待期的死亡率为目标。研究人群被分为两组:在等待名单上超过三个月的患者(“on waiting list”),以及3个月内在等待名单上死亡或因病情加重无法移植的患者(“waitlist mortality”)。最终,总队列包含11,647名患者(11,199名“on waiting list”,448名“waitlist mortality”),数据涵盖临床、实验室和疾病相关多维度变量。
在数据预处理阶段,为了捕捉患者健康状态的动态变化,研究团队计算了6个关键实验室变量的连续测量差值,包括血清钠、肌酐、白蛋白、胆红素、甲胎蛋白和国际标准化比值,使总特征数增加到31个(25个原始静态变量 + 6个新增动态变量)。
对于缺失值,数值变量(缺失率 < 7%)使用类别均值填补;分类变量(缺失率 < 0.1%)则直接删除了包含缺失值的观测记录。
模型架构:端到端一体化流程 + 多集成学习模型对比
为了使死亡率预测兼具高准确率和可解释性,研究团队构建了一个融合集成学习、SHAP分析、UMAP降维与K-Medoids监督聚类的端到端一体化流程。
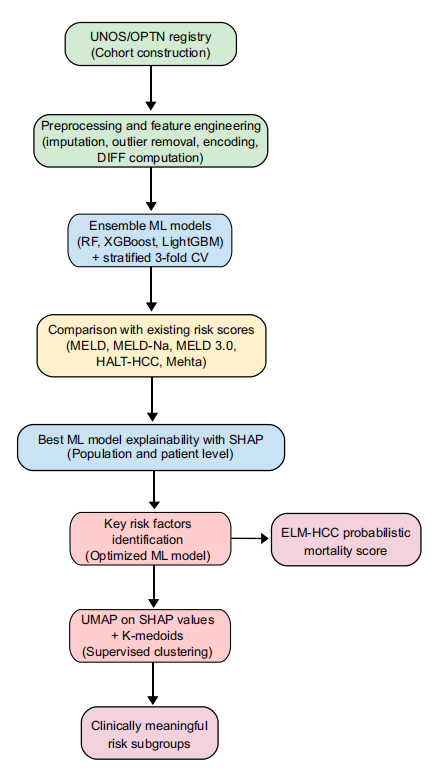
首先,核心模型采用对表格数据特别有效的集成树模型。 研究对比了随机森林、XGBoost和LightGBM三种模型。实验在两种场景下展开:仅使用25个原始静态变量;使用31个含动态变量的动静态结合变量。
其次,为了增强临床决策依据,将SHAP可解释性分析融入框架,用以识别关键风险因素并揭示模型预测逻辑。 全局解释通过计算SHAP值量化每个特征的贡献度;局部解释则通过SHAP图展示单个特征值对具体患者预测的影响。此环节还为后续聚类分析提供了更具解释性的SHAP值特征集。
最后,为实现精细化风险分层,流程中加入了UMAP降维与K-Medoids监督聚类方法。 首先将模型预测的SHAP值嵌入UMAP降维空间,然后采用K-Medoids算法进行聚类,以发现具有不同临床特征的潜在患者亚组。该方法被称为“监督聚类”,因为聚类基于SHAP值而非原始数据。
最优聚类数通过量化指标筛选,并结合SHAP分析进行临床验证,最终确定为7。
实验结果:8种传统评分作为对比 + 最优特征集训练新模型
风险评分表现对比
研究将所提框架与8种传统风险评估方法进行性能对比,包括ALBI、Child–Pugh、AFP、HALT-HCC、Mehta Model、MELD及其变体MELD-Na、MELD 3.0。
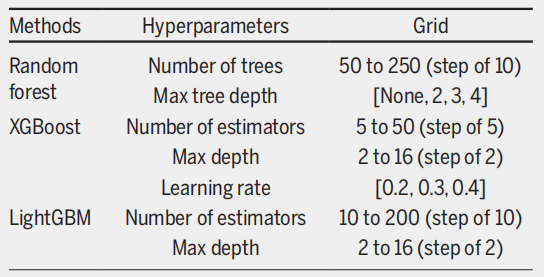
考虑到数据集存在严重类别不平衡,研究对多数类进行了下采样,生成30个平衡子集,并针对每个子集执行3折交叉验证。之后通过网格搜索确定三个集成模型的最优超参数。
结果显示,在传统评分系统中,Mehta Model表现最佳,AUROC达0.782,紧随其后的是HALT-HCC(AUROC 0.763)。 更重要的是,这两种模型的敏感性和特异性更为平衡。
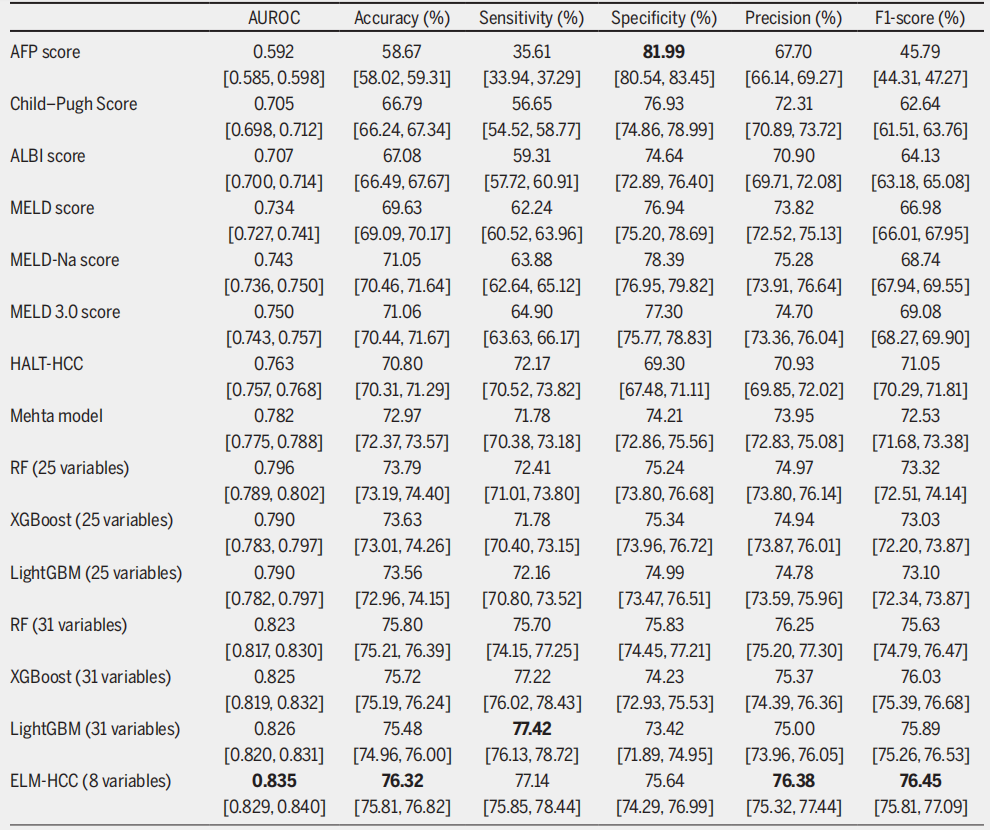
当使用集成学习框架时,仅在25个静态变量上训练,其准确率就已超过所有传统评分系统。其中随机森林表现最佳,AUROC为0.796。在引入包含动态变量的31个特征后,所有集成模型性能进一步提升。其中LightGBM的AUROC达到0.826,敏感性达到最高的77.42%,成为识别高危患者最有效的模型。
识别关键风险因素能力分析
在模型训练完成后,研究评估了仅使用最相关特征时的性能。研究团队针对性能最优的LightGBM模型,采用Gain importance和SHAP global importance两种方法筛选关键特征。
基于LightGBM模型,SHAP筛选出的前8个特征使模型性能达到最优,AUROC达0.835,不仅优于Gain importance筛选结果,还高于LightGBM在31个完整变量集上的表现(0.826),因此被选为最优特征集。
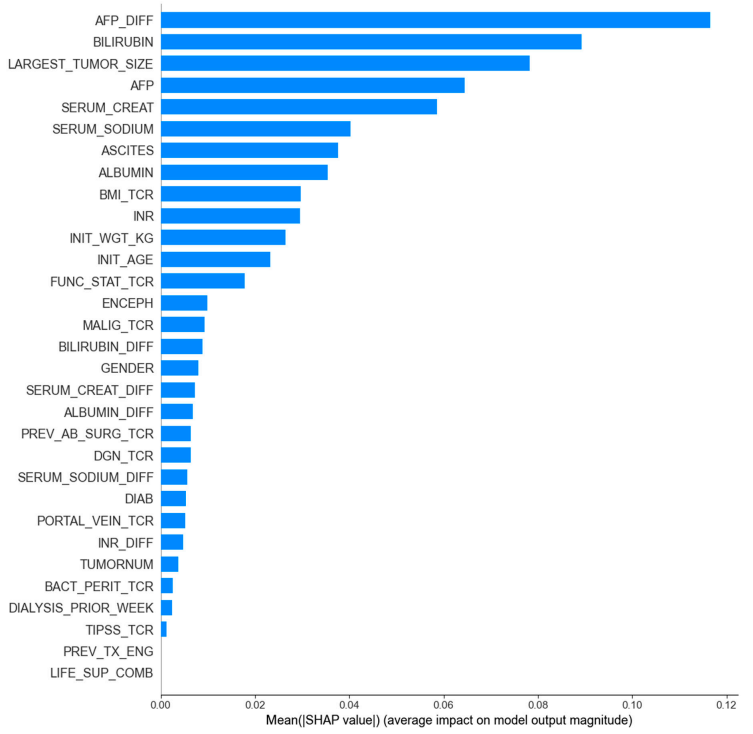
最终,研究基于这8个最优特征训练的LightGBM模型,构建了针对HCC患者的概率性死亡率评分,称为ELM-HCC。LightGBM在简化变量集上表现优于完整变量集,体现了这8个变量具备更强的预测影响力。 同时,关键特征中出现的AFP动态变化值也突出了纳入动态信息的重要性。
风险分层与亚组分析
研究基于SHAP值的监督聚类识别出7个具有不同临床特征和风险水平的患者亚组。下图B清晰地展示了从聚类1到聚类7,死亡概率逐渐增加的趋势。
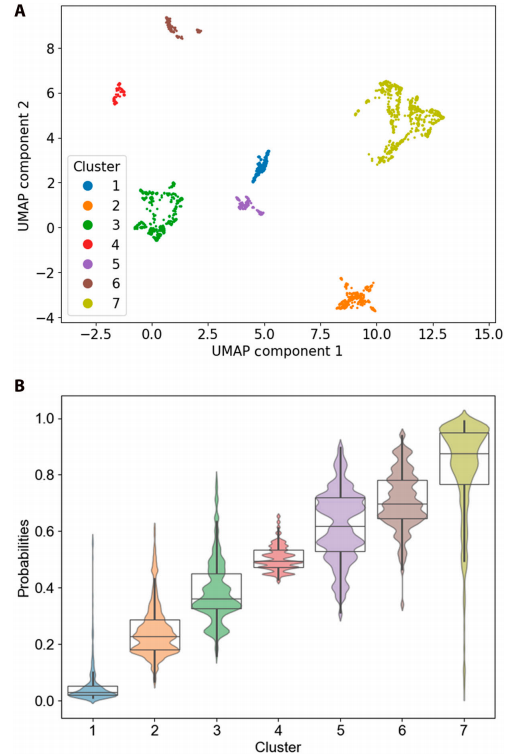
A为基于SHAP嵌入值的UMAP 2D可视化聚类;B为7个聚类的死亡概率箱型图和群体图。
基于Kruskal-Wallis检验的进一步分析揭示了不同聚类间变量的差异。如SHAP力图所示:从聚类1到聚类7,死亡风险概率呈递进式增长,代表性患者的死亡概率从0.03上升到0.98。这一趋势与箱型图观察到的排名一致,凸显了聚类方法的有效性。
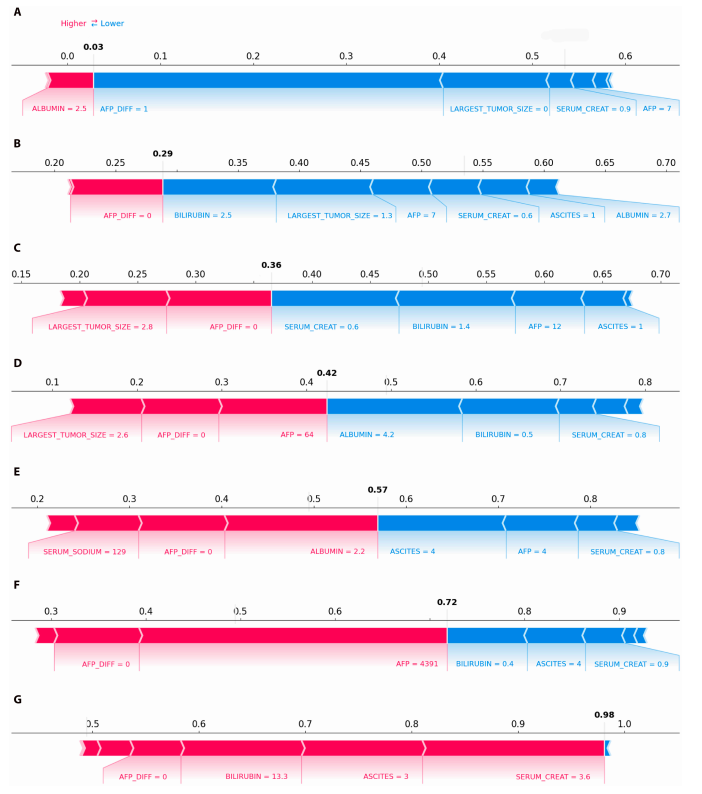
此外,亚组分析清晰地揭示了导致高死亡率风险的两个主要原因:严重的肝功能衰竭(以高胆红素、高肌酐和中度腹水为特征)和活跃的肿瘤进展(以高AFP水平为特征)。
总的来说,本研究提出的ELM-HCC框架在预测HCC肝移植候选者3个月等待期死亡风险方面,性能显著优于传统评分系统,同时通过监督聚类揭示了具有不同风险特征的患者亚组,为临床提供了更精准、更具解释性的风险评估工具。
革新肝移植候选者风险评估手段,综合性方法弥补研究空白
肝癌已成为全球性公共卫生难题,科学规划肝移植候选人名单至关重要。早在2002年,MELD评分已被用于优先级排序,但经过多次修订,其分配仍难以公平满足所有候选人。
而机器学习凭借对高维多模态数据的处理能力,已成为预测器官移植候选名单死亡风险的有力方案。
此前已有相关研究,例如麻省理工学院等机构的联合团队提出了基于最优分类树的死亡率优化预测模型OPOM。基于该模型分配肝脏,预计每年死亡人数比基于MELD可减少约418例。 该模型还优化了对HCC和非HCC患者的肝脏分配数量。
不过,OPOM基于HCC和非HCC混合队列,未针对性解决HCC患者面临的双重风险问题。而ELM-HCC无疑是对此空白的针对性填补。
本次研究不仅仅是对前人研究的精进,更是对当前研究空白的有效弥补。通过首次实现HCC肝移植候选者等待期死亡率的可解释性精准预测,为机器学习在器官移植风险评估领域的应用提供了新思路。
参考资料:
- https://spj.science.org/doi/10.34133/hds.0295
- https://www.sciencedirect.com/science/article/pii/S1600613522090335
编辑:文婧
本文由专业的技术内容平台整理发布。想了解更多前沿技术动态、数据科学与人工智能领域的深度解读与实践案例,欢迎访问云栈社区,与广大开发者一同交流学习。
 发表于 2026-3-20 13:51:15
|
查看: 88|
回复: 0
发表于 2026-3-20 13:51:15
|
查看: 88|
回复: 0
