Transformer架构自2017年诞生以来,几乎统治了所有生成式AI模型。但其计算量随序列长度呈二次方增长的特性,使其在推理时面临严峻的“内存墙”挑战,昂贵的GPU算力常常在等待数据搬运中空转。
为了从根本上解决这个问题,一系列线性注意力模型应运而生,其中Mamba系列因其高效的状态空间模型(SSM)设计而备受瞩目。近日,其新一代模型 Mamba-3 正式发布,论文题为《Mamba-3: Improved Sequence Modeling using State Space Principles》。

与上一代相比,Mamba-3不再单纯追求训练速度,而是彻底转向“推理优先”的设计哲学,旨在让GPU的每一秒都在高效计算。它通过三项核心创新,分别解决了数学近似误差、模型表达能力瓶颈和硬件利用率三大问题。
理解Mamba的核心:状态空间模型(SSM)
在深入Mamba-3之前,需要先理解其基础。Mamba是一种状态空间模型,其核心思想是使用一个固定大小的状态向量来压缩和记忆历史信息,而非像Transformer那样需要回顾整个历史上下文。
一个连续时间的标准SSM可以表示为:

其中,h(t)是状态,x(t)是输入,y(t)是输出,A(t), B(t), C(t)是随时间变化的参数矩阵。
要将此模型应用于离散的数字数据,必须进行离散化。Mamba-1/2采用了一种简化的离散化方案:hₜ = e^{ΔₜAₜ} hₜ₋₁ + Δₜ Bₜ xₜ。这个方案虽然简单,但存在三个主要问题:缺乏严格的理论依据、仅有一阶精度导致误差较大,以及实数矩阵无法表示旋转等复杂动态,限制了模型解决逻辑问题的能力。
Mamba-3的三大改进,正是针对这些痛点而来。
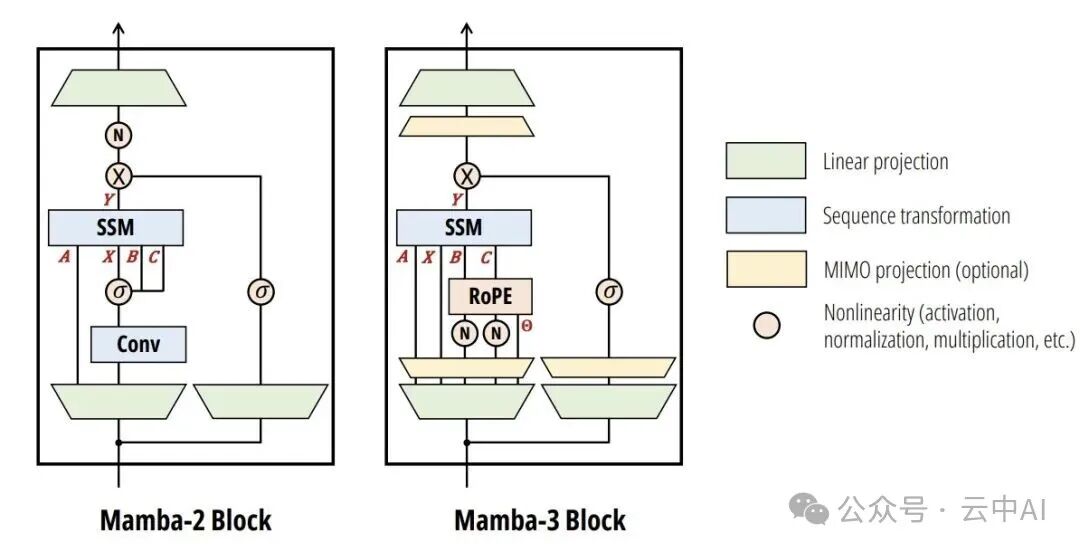
第一项改进:指数梯形离散化
这是对Mamba-1/2离散化方法的彻底重构,旨在提升精度并引入隐式卷积能力。
从连续系统到高阶离散化
从连续系统公式出发,状态的更新由两部分组成:旧状态的衰减,以及整个时间区间内输入影响的积分。
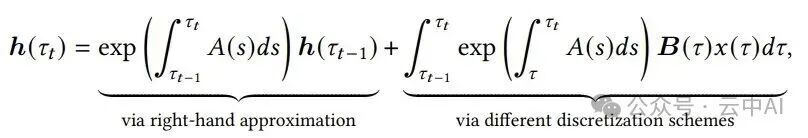
Mamba-1/2采用的“指数欧拉法”将区间内的A(s)近似为常数Aₜ,并用右端点Bₜ xₜ来近似整个积分项。这是一阶方法,局部截断误差为O(Δₜ²)。
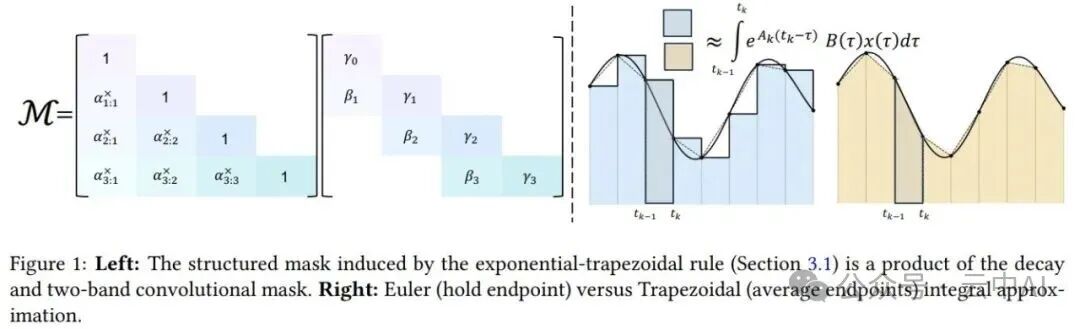
Mamba-3升级为广义梯形法则。它在同样假设A(s)为常数的前提下,对积分项采用了更精确的近似:使用两个端点Bₜ₋₁ xₜ₋₁和Bₜ xₜ的加权平均,并引入一个数据依赖的加权系数λₜ,让模型自主学习更依赖哪一个端点。
其离散化后的递归公式为:
hₜ = αₜ hₜ₋₁ + βₜ Bₜ₋₁ xₜ₋₁ + γₜ Bₜ xₜ
其中,αₜ = e^{ΔₜAₜ}, βₜ = (1-λₜ)Δₜ αₜ, γₜ = λₜ Δₜ。

技术优势
- 二阶精度:当
λₜ接近1/2时,该方法的局部截断误差为O(Δₜ³),精度显著高于Mamba-2。
- 隐式卷积:公式中的
βₜ Bₜ₋₁ xₜ₋₁项,将上一时刻的输入也纳入计算,相当于在递归内部实现了一个宽度为2的卷积操作。这使得Mamba-3可以省去传统Mamba块外部额外的短卷积层。
- 训练/推理两便:该递归公式可以展开为并行计算的矩阵形式,即一个半可分矩阵与一个双带状矩阵的乘积。这意味着在训练时可以使用高效的矩阵乘法进行并行计算,而在推理时则切换回节省内存的递归模式,实现了“训练像Transformer一样快,推理像RNN一样省”的目标。

第二项改进:复值状态空间
此项改进旨在突破线性模型在状态跟踪任务上的局限性,例如奇偶校验或带括号的算术运算。
实数模型的局限性
以奇偶校验任务为例,模型需要跟踪输入中“1”的个数是奇数还是偶数。一个理想的解决方案是使用一个二维状态,每遇到一个“1”就旋转180度(乘以-1)。然而,实数乘法只能表示缩放,无法表示旋转。旋转需要复数特征值。
Mamba-3的复数解决方案
Mamba-3将状态从实数域扩展到复数域,其连续时间系统方程如下:
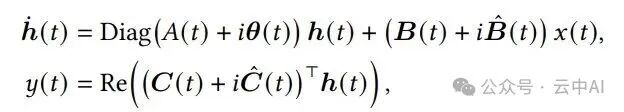
经过与第一项改进相同的指数梯形法离散化后,这个复值系统可以等价地转换为一个实数系统,但状态维度翻倍。关键在于,其状态转移矩阵变成了块对角旋转矩阵的乘积:
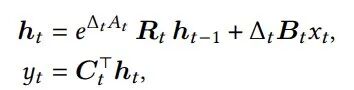
其中,Rₜ是由Δₜθₜ决定的2×2旋转矩阵([[cosθ, -sinθ], [sinθ, cosθ]])组成的块对角矩阵。
转换后的输入、输出矩阵B_t和C_t也相应变为实部和虚部的组合:
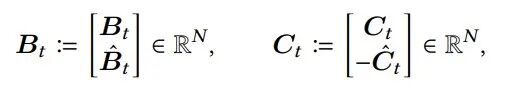
等价于数据依赖的RoPE
更巧妙的是,这些旋转操作可以被“吸收”到输入和输出的投影矩阵中。论文证明,上述系统等价于以下形式:
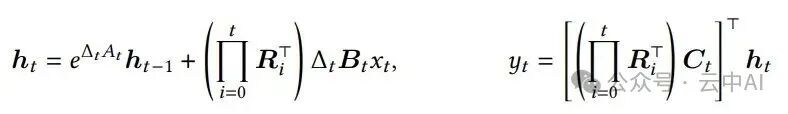
可以看到,旋转矩阵全部转移到了B和C矩阵上。这实质上是一种数据依赖的旋转位置编码(RoPE)。与传统Transformer中固定的旋转角度不同,Mamba-3的旋转角度θₜ是从当前输入数据中学出来的,使模型能动态决定状态如何旋转。
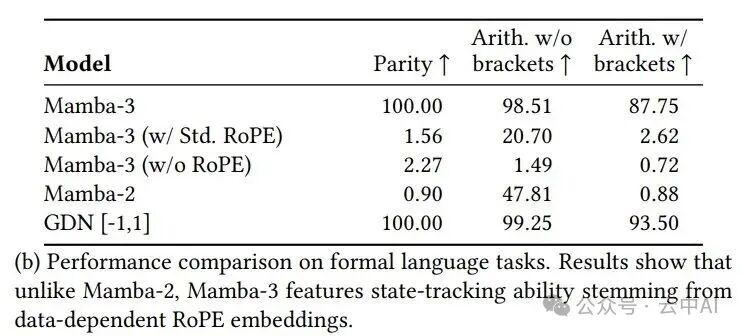
实验证明,正是这项改进让Mamba-3能够完美解决奇偶校验等状态跟踪任务,而Mamba-2在此类任务上几乎无效。
第三项改进:多输入多输出(MIMO)
这项改进直指推理阶段的硬件利用率瓶颈,旨在让GPU“忙起来”。
推理瓶颈:内存墙
在自回归推理过程中,尤其是在生成阶段,每一步的计算量很小,主要开销在于将参数和状态数据从显存搬运到计算单元。此时,GPU的算力利用率极低,处于“内存受限”状态。
Mamba-2的核心递归操作是一个向量外积:Bₜ xₜᵀ。这个操作的算术强度(计算量/内存访问量)很低,远低于现代GPU(如H100)的理论峰值,导致大量时间浪费在数据搬运上。
MIMO的设计思路
Mamba-3提出:既然计算单元闲着,不如让它同时处理更多信息。
它将输入xₜ从标量或向量扩展为矩阵(维度P×R),将参数Bₜ也相应扩展(维度N×R)。这样,原来的外积Bₜ xₜᵀ就变成了矩阵乘法Bₜ xₜᵀ,产生一个N×P的矩阵。

计算量从O(NP)增加到O(NPR),而内存访问量的增长相对较少。当R=4时,算术强度得到有效提升,让GPU在每一步能进行更多有效计算,从而提高了硬件利用率。
高效的训练实现
朴素的MIMO实现会使训练复杂度暴增R²倍。论文采用了一种巧妙的分块算法,将序列分块处理,块内并行、块间递归。通过精细设计块大小,可以将总训练复杂度控制在O(TRN²)级别,仅比SISO版本增加R倍,而非R²倍。
性能评估
语言建模能力
在1.5B参数规模下,使用100B FineWeb-Edu tokens进行训练,Mamba-3 MIMO (R=4) 在多个常识推理基准测试上的平均准确率达到57.6%,显著优于同规模的Transformer(55.4%)、Mamba-2(55.7%)和Gated DeltaNet(55.8%)。
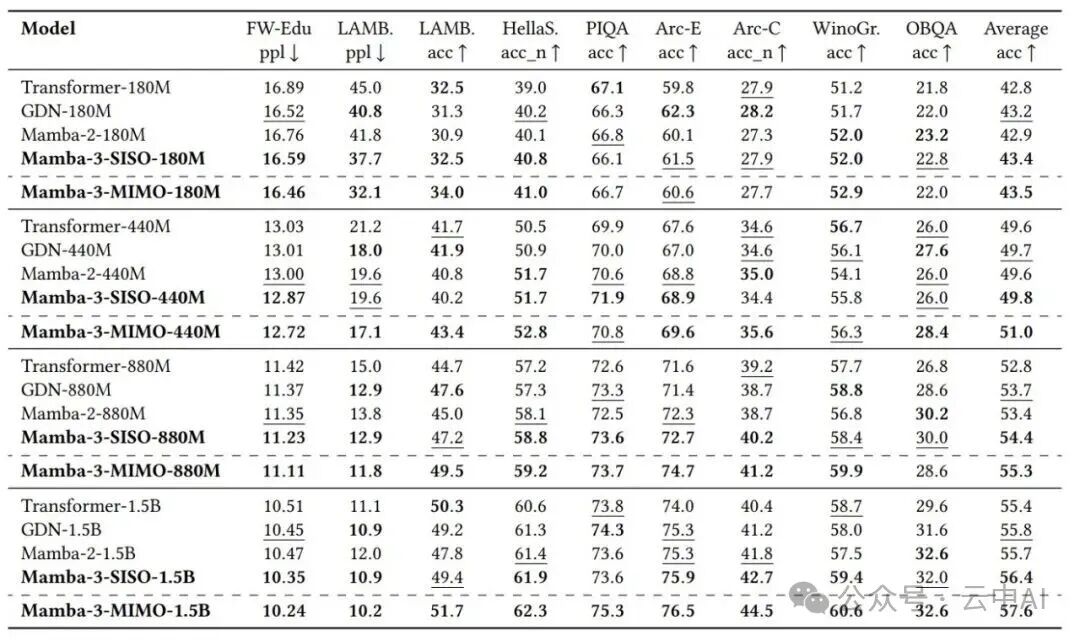
更重要的是效率对比:Mamba-3仅使用64维状态就能达到Mamba-2使用128维状态时的语言建模困惑度水平。这意味着在达到相同模型质量时,Mamba-3的推理速度可以快一倍。
状态跟踪能力
在形式语言任务测试中,Mamba-3的优势更为明显:
- 在奇偶校验任务上,准确率达100%,而Mamba-2不足1%。
- 在带括号的算术运算任务上,Mamba-3达到87.75%,Mamba-2仅为0.88%。
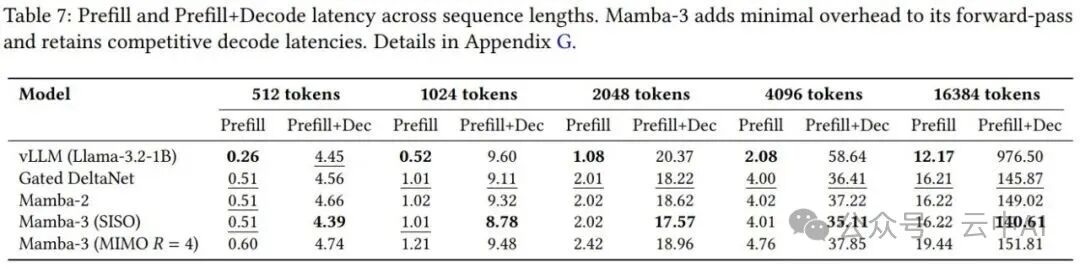
推理速度
在实际延迟测试中:
- Mamba-3 SISO变体比Mamba-2更快。
- Mamba-3 MIMO (
R=4) 变体虽然单步延迟略有增加,但换来了显著的模型质量提升。
- 在长序列(16384 tokens)场景下,Mamba-3 SISO的总延迟为140ms左右,而经过vLLM高度优化的Transformer延迟高达976ms,前者优势巨大。
总结
Mamba-3的三项核心创新,每一刀都切中了当前序列建模的关键痛点:
- 指数梯形离散化:提升了模型的理论精度和数值稳定性,并在递归中内嵌了卷积能力,简化了架构。
- 复值状态空间:通过引入数据依赖的旋转机制,赋予了线性模型强大的状态跟踪和逻辑推理能力。
- 多输入多输出(MIMO):优化了核心操作的算术强度,有效提升了GPU在推理时的利用率。
这些改进共同使得Mamba-3不仅在多项任务性能上超越同规模Transformer,更在长序列推理效率上展现出压倒性优势。它证明了固定大小的状态记忆与高效的线性模型,同样可以具备强大的表达能力。
随着代码的开源和论文的发布,Mamba-3为挑战Transformer的统治地位提供了又一个强有力的候选者。对于关注推理效率和模型性能的开发者与研究者而言,深入理解其设计原理将大有裨益。
 发表于 2026-3-20 14:01:40
|
查看: 171|
回复: 0
发表于 2026-3-20 14:01:40
|
查看: 171|
回复: 0
