有段时间,我电脑浏览器的常驻标签页大概是这样的:
Flightradar24、NASA FIRMS、BBS、CNN冲突数据库、某个监控宏观经济指标的网站,还有一个专门追踪辐射数据的页面。
每天早上打开电脑,第一件事不是写代码,而是挨个刷新这些标签页,看看有没有什么“异常”出现。
我知道这听起来很荒谬,但我就是停不下来。某种程度上,这已经成了一种习惯,或者说,是某种焦虑的外化表达。总觉得如果不了解点世界正在发生的变化,等会儿和同事吃午饭时聊起来,自己都搭不上话,别提多尴尬了。不知道你是否也有类似的感受。
直到有一天,我在 GitHub 上看到了一个名叫 Crucix 的开源项目。
作者在项目介绍里写的一段话,几乎就是我内心独白的翻版:
“I built this because I was constantly checking multiple sources to understand what's happening globally — conflict events, satellite signals, macro indicators, flight activity, etc.”
好吧,原来不止我一个人有这种“怪癖”。而且行动力强的人,已经把困扰我很久的痛点给解决了。
先搞清楚,它到底是什么?
Crucix 的定位非常直接:一个自托管的个人情报终端。
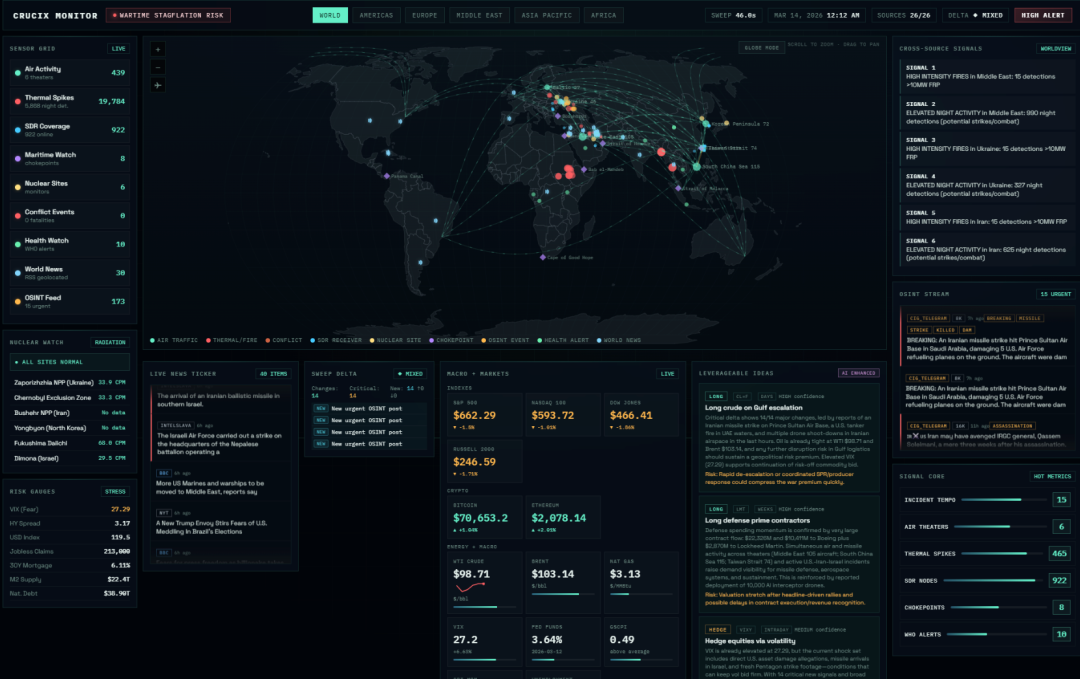
它不是新闻聚合器,不是 RSS 阅读器,也不是什么商业级的威胁情报平台。它更像一个不知疲倦的助手,每隔15分钟自动去26个数据源“巡逻”一遍,然后把关键的异常信号推送给你。
它完全运行在你的本地,基于 Node.js 构建,不需要云端服务器,也没有任何订阅费用。
数据主权在自己手里——这几个关键词放在一起,已经清晰地表明了作者的设计哲学。
它聚合了哪些数据源?
这是我最初最好奇的问题。翻看其文档,这些数据源大致可以分为几个层次:
地球物理层
- NASA FIRMS:卫星实时火点探测数据。
- 全球辐射监测站数据。
地缘政治层
- ACLED:武装冲突与暴力事件数据库,学术级别的冲突追踪工具。
- GDELT:全球事件、语言和音调数据库,每15分钟更新一次,覆盖全球新闻媒体。
运输追踪层
- 航班追踪(ADS-B 信号)。
- 海运数据(AIS)。
金融经济层
- FRED:美联储经济数据库,包含各种宏观经济指标。
- 实时金融市场数据。
OSINT 情报层
乍一看,这个组合似乎有点“散”。NASA 的卫星火点和股票市场数据放在一起,能有什么关系?
为什么要这样组合数据源?
这其实是一种 多模态信号交叉验证 的思路。
单个数据源提供的信号往往是孤立的、充满噪声的。但如果多个不同维度的信号同时指向同一个事件,其可信度和重要性就会指数级提升。
举个例子:
- 某地区突然出现大量卫星火点(FIRMS)。
- 同时该地区的冲突事件数量急剧上升(ACLED)。
- 周边区域的航班开始出现异常绕行(ADS-B)。
- 全球能源相关期货价格随之出现波动(市场数据)。
任何一个单一信号,你都很难判断其全局影响。但当这四种来自不同领域(环境、政治、交通、经济)的信号同时被触发时,你大概率已经捕捉到了一个“真实事件”的发生,其时效性远超过第二天的新闻报道。
Crucix 的核心目标,就是让你比传统新闻渠道更早地感知到世界正在发生什么。
技术架构是如何工作的?
简单来说,它是一个 定时拉取 + 本地聚合 + 规则触发通知 的系统。
其数据流可以概括如下:
外部数据源(26个API/Feed)
↓ (每15分钟轮询)
Crucix 数据采集层(Node.js)
↓
数据清洗与标准化
↓
本地存储(信号库)
↓
规则引擎(用户自定义触发条件)
↓ ↓
AI 分析层(可选) 直接推送
(LLM 信号解读)
↓
Telegram / Discord 等通知渠道
通知渠道可以灵活配置,Telegram 机器人可以轻松替换为飞书、企业微信等国内常见的办公机器人。这里有一个非常关键的设计决策值得注意:AI 分析层是可选的。
为什么将 AI 设计成可选模块?
如果强制将 LLM 分析插入每条数据处理流程,会带来两个直接问题:
- 成本激增:26个数据源,每15分钟轮询一次,每次可能产生数十条记录。如果每条都调用 LLM API,日积月累的成本会非常可观。
- 过度设计:并非所有信号都需要“解读”。很多信号(比如某地气温骤升)一目了然,真正需要的是聚合与报警,而非 AI 的“分析”。
将 AI 设计为“可选的增值模块”,而不是“必须的基础设施”,体现了作者清晰的架构分层思维。底层数据管道负责稳定、高效地获取和存储原始数据;上层 AI 模块则在需要时,对聚合后的复杂信号进行解读、总结或关联推测。这种职责分离的工程实践,相当克制且务实。
如何部署与运行?
项目基于 Node.js,部署流程相当标准。
第一步:克隆仓库
git clone https://github.com/calesthio/Crucix
cd Crucix
第二步:安装依赖
npm install
第三步:配置数据源
这一步需要花费一些时间。部分数据源(如 NASA FIRMS、FRED)需要申请免费的 API Key。对于个人使用而言,官方提供的免费额度通常完全足够。
第四步:配置通知渠道
在配置文件中填入你的 Telegram Bot Token 或 Discord Webhook URL。这样 Crucix 在检测到符合规则的信号时,就能自动推送给你。
第五步:启动服务
npm start
之后,它就会在后台安静运行,每15分钟自动扫描一轮预设的数据源,并在发现异常时向你发送通知。轮询周期可以根据自己的需求在配置中调整。
这类项目的真正价值是什么?
Crucix 不仅仅是一个“酷炫的工具”,它背后代表了一种值得深思的工程与信息处理思路:
信息的核心价值不在于数量,而在于其时效性以及跨领域交叉验证的能力。
如今大多数人获取信息的方式本质上是 被动 的:等待媒体报道、社交媒体推送,或者算法决定你今天“应该”看到什么。
而 Crucix 尝试构建的,是一条由你自己掌控的、主动 感知世界变化的信号管道。它不依赖任何云服务商的算法,数据在本地处理,通知推送到你的私有频道。这种对数据主权和信息主动权的追求,可能比“聚合26个数据源”这个功能本身更值得探讨。
当然,这套系统也并非没有“门槛”。最大的挑战在于 信号过滤。
26个数据源持续运行,会产生海量信息。如果没有精心配置的过滤规则,你的通知渠道很快就会被刷屏,导致信息过载。Crucix 将规则配置的主动权交给了用户,这既是其灵活性的体现,也意味着使用者需要对自己的需求有清晰的认知。
它更像一把功能强大的“锄头”,能帮你高效地挖掘信息矿藏;但具体要往哪里挖、挖多深,还得靠你自己来决定。关于更多类似的极客工具和思考,也欢迎到我们的开发者社区交流。
 发表于 2026-3-21 06:41:38
|
查看: 218|
回复: 0
发表于 2026-3-21 06:41:38
|
查看: 218|
回复: 0
