随着数字人直播、视频播客、实时互动等场景快速普及,行业正面临从“能生成”到“能长期稳定生成”的关键跨越。但在真实线上应用中,一旦视频生成拉长到分钟甚至小时级,画面稳定性与一致性往往会明显下降——身份漂移、细节丢失、画面闪烁,以及实时推理成本随时长攀升等问题尤为突出。
那么,如何让数字人视频在流式实时推理下做到小时级甚至无限长度,同时保持身份一致、细节稳定、口型精准?Soul AI Lab(Soul App AI团队)提出的SoulX-LiveAct给出了新思路。该方案通过 Neighbor Forcing(同扩散步对齐的自回归条件传播) 与 ConvKV Memory(KV 记忆压缩) 两大核心技术,让AR diffusion模型从“能流式”走向了“可真正长时稳定地实时流式”。

论文信息
01 模型架构
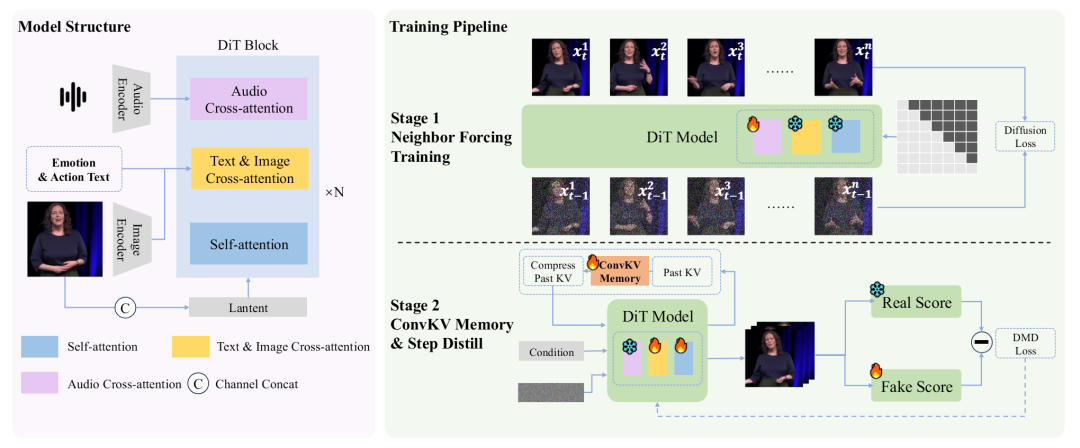
SoulX-LiveAct旨在解决小时级实时数字人动画的流式生成难题。其整体采用AR Diffusion(自回归扩散) 范式,并围绕“长时一致 + 恒定显存”构建了两条核心机制:Neighbor Forcing 与 ConvKV Memory。
- AR Diffusion 主干:模型按chunk/帧块进行自回归生成。在每个chunk内部采用扩散模型来生成细节,而chunk之间则通过条件上下文来传递运动与身份信息,从而形成一个完整的流式推理闭环。
- Neighbor Forcing(邻近强制):这是确保长时一致性的关键。在自回归链上,模型不传播“处于不同扩散步”的状态,而是专门传播同扩散步
t 下的相邻帧的潜在表示(latent)作为条件。这样做使得上下文与当前预测处于同一噪声语义空间中,显著降低了训练和推理过程中因分布不一致导致的漂移。
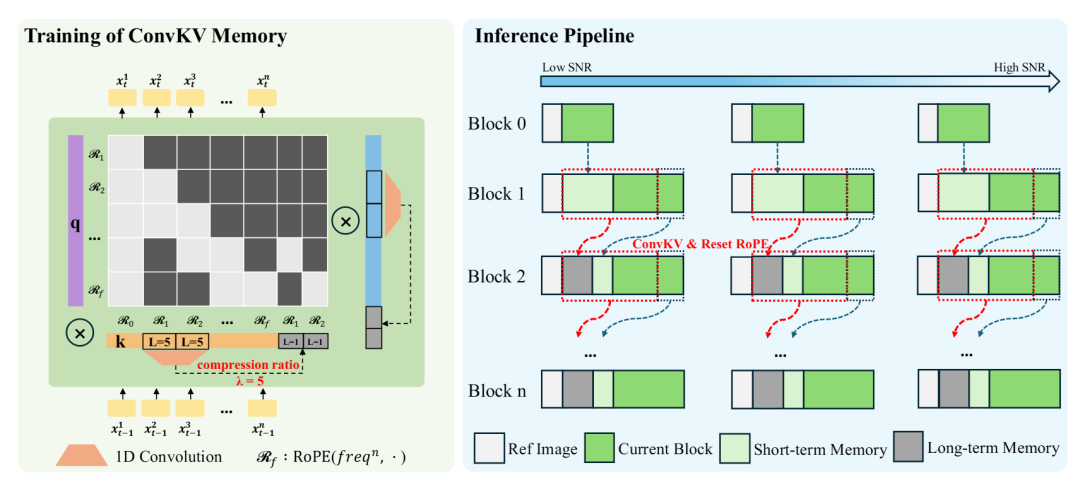
- ConvKV Memory(卷积式 KV 记忆):为了解决推理显存随序列长度线性增长的问题,该技术将历史的attention KV记忆从简单的线性缓存,改造为“短期精确 + 长期压缩”的组合:
- 近期KV:保留一个高精度的短期窗口,确保局部运动细节和一致性的稳定。
- 远期KV:通过轻量的1D卷积按固定压缩比(例如论文中的 λ=5)进行滚动压缩,将遥远的历史信息压缩进一个固定长度的表示中。这直接实现了常量显存推理,是支持小时级生成的技术基础。
- RoPE Reset(位置对齐):为了配合ConvKV Memory的“压缩+滑动窗口”机制,模型通过重置RoPE位置编码来对齐历史与当前序列的位置信息,有效避免了长序列生成中的位置漂移问题,进一步强化了长时稳定性。
02 模型训练
SoulX-LiveAct的训练目标并非仅仅追求短视频片段的生成质量,而是显式地对齐流式推理中的长时误差传播,使模型在“生成时间越长越不稳定”的场景下,依然能保持身份与细节的稳定。
- Neighbor Forcing 对齐训练分布:在训练时,强制模型在同扩散步的语境下,接收来自“相邻帧”的条件潜在表示。这种做法减少了AR链中因跨步噪声空间不一致带来的优化震荡,让模型能更好地学习到稳定的时序承接规则。
- 长时一致性导向的自回归训练构造:训练样本按chunk方式组织,显式地覆盖“连续chunk合成 → 误差累积 → 再纠正”的完整过程。这使得模型在训练阶段就充分暴露并学会如何处理长时漂移问题,而不是仅仅在短片段上拟合高质量生成。
- Memory-Aware 训练(与推理一致):在训练阶段就引入与推理完全一致的ConvKV Memory使用方式(短期窗口+长期压缩)。这让模型从一开始就学会在“被压缩的历史记忆”条件下,如何保持身份与细节的一致性,避免了因训练/推理不一致导致的性能下降。
03 实时推理加速
LiveAct的加速设计强调“延迟稳定”,核心思路是把长时上下文从线性可变缓存变为可控的固定内存,从而让实时流式推理的性能不随生成时长而恶化。
- 恒定显存(Constant-Memory Inference):ConvKV Memory将历史KV从线性增长变为固定预算,使得推理显存占用不再随视频时长增加而增长,这是实现小时级在线生成的必要条件。
- 稳定延迟(Stable Latency):短期窗口KV保证了局部生成质量,长期压缩KV维护了全局一致性。两者的组合确保了每个chunk的计算与通信成本保持稳定,不会因为视频越长而拖慢处理速度。
- 端到端实时能力:在512×512分辨率下,系统可在 2×H100/H200 的硬件条件下实现 20 FPS 的流式推理,并达到约 0.94秒 的端到端延迟,以及 27.2 TFLOPs/frame 的计算成本。
04 评估
通过在HDTF(侧重面部口型与真实感)与EMTD(包含全身动作)两类基准上的定量对比,SoulX-LiveAct展示了其在口型同步、动画质量与实时效率上的综合领先优势。
定量结果分析
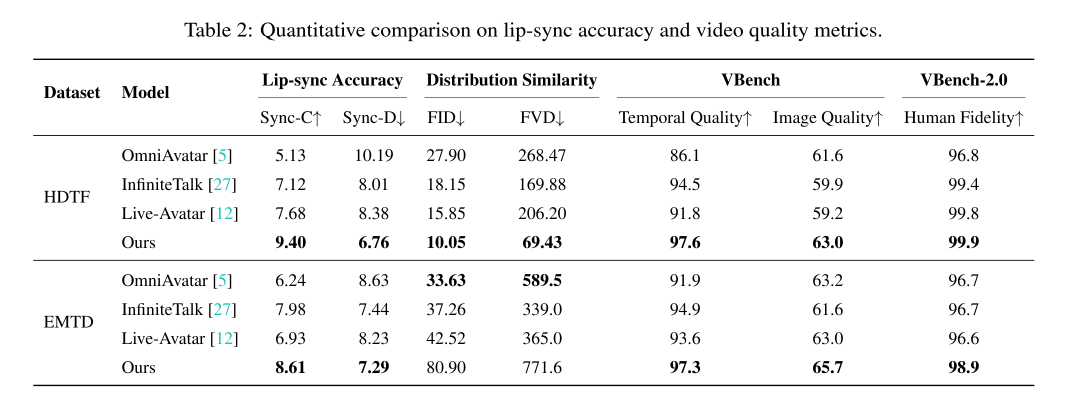
在HDTF数据集上,SoulX-LiveAct取得了 9.40 的 Sync-C(越高越好)与 6.76 的 Sync-D(越低越好),同时在分布相似性指标上达到 10.05 FID / 69.43 FVD。在VBench评测上,其获得了 97.6 的 Temporal Quality(时序质量)与 63.0 的 Image Quality(图像质量),在VBench-2.0上的 Human Fidelity(人体保真度)达到 99.9,显示出更稳定的时序质量与更强的人体及身份一致性。
在EMTD(全身动作)数据集上,SoulX-LiveAct依然保持最优的同步表现(8.61 Sync-C / 7.29 Sync-D),并在VBench上达到 97.3 Temporal Quality / 65.7 Image Quality,Human Fidelity 达到 98.9,证明其对复杂的全身动作与表情交互场景具有良好的鲁棒性。
效率对比
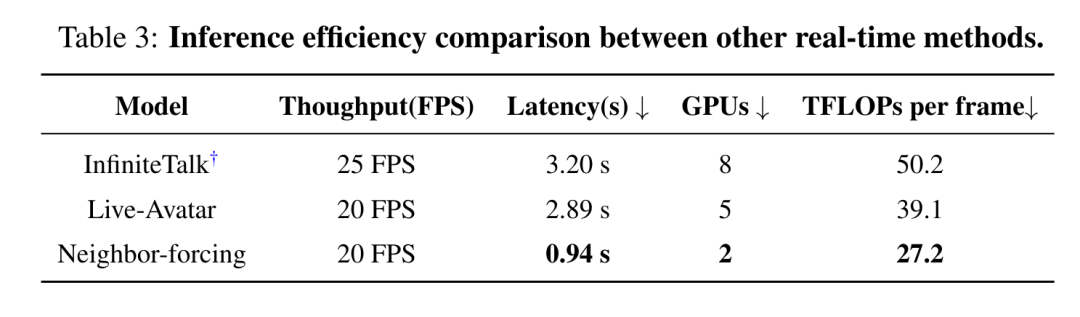
更为关键的是,作为面向“小时级实时生成”的系统方案,SoulX-LiveAct在推理效率上优势明显。如下表所示,其成本被压低至 27.2 TFLOPs / frame,仅需 2 张 H100/H200 即可实现 20 FPS 的实时流式推理与 0.94秒 的端到端延迟。这一表现显著优于需要8张卡且延迟更高的InfiniteTalk(25 FPS / 3.20s / 50.2 TFLOPs)以及需要5张卡的Live-Avatar(20 FPS / 2.89s / 39.1 TFLOPs),将“长时稳定 + 实时可用”真正拉进了可部署的实用区间。

05 实际应用场景:SoulX-LiveAct 带来的变革
(1)7×24 小时“长期在线”数字人直播间
场景:直播陪伴、互动主持、虚拟播报。
应用:传统流式方案一旦拉长到十几分钟以上,常出现“脸漂、细节丢失、口型逐步漂移”问题。SoulX-LiveAct通过 Neighbor Forcing + ConvKV Memory 实现“恒定显存”的长时流式生成,在小时级输出中依然维持身份与细节稳定,同时以 20 FPS、0.94秒 的低延迟满足实时互动需求(如响应弹幕、对话和即兴反应)。
(2)沉浸式视频对话:AI 虚拟导师 / 客服 / 智慧柜员
场景:在线教育、金融客服、政务大厅、企业数字前台。
应用:视频对话的“信任感”很大程度上来源于稳定的表情、口型与身份一致性。SoulX-LiveAct在HDTF/EMTD上取得领先的 Sync-C/Sync-D 分数,并在VBench-2.0上维持接近满分的人体保真度表现,能让“面对面”的虚拟互动显得更自然、更可信。
(3)长内容生产:播客/课程/解说的“小时级视频一键生成”
场景:长播客、课程录制、知识解说、企业培训。
应用:这类长视频内容最怕“越到后面画面越崩”。SoulX-LiveAct的长视频一致性分析显示,相比基线方法容易出现的身份漂移与配饰消失等问题,LiveAct能更稳定地保持人物身份与细节(如衣物纹理、配饰等)贯穿全程,适合批量生成“从开头到结尾都保持一致”的长视频内容。
(4)游戏与虚拟世界中的“实时驱动”NPC
场景:开放世界NPC、虚拟社交、互动剧情。
应用:游戏中的NPC不仅要会说台词,更要“说得像、动得像、并且一直像同一个角色”。SoulX-LiveAct在全身数据集EMTD上的同步与质量指标领先,并支持实时流式推理,非常适合在游戏或虚拟空间里实现长时间在线、且具备丰富情绪与动作表达的数字角色交互。
结语
SoulX-LiveAct通过Neighbor Forcing和ConvKV Memory两项创新,为长时稳定的实时数字人生成提供了系统性的解决方案。它不仅大幅提升了视频质量与一致性,更通过恒定显存和稳定延迟的设计,让小时级实时生成变得切实可行。该模型已在GitHub上开源,为社区研究与应用提供了新的强大工具。对于开发者而言,这意味着在构建数字人直播、互动客服、长视频生成等应用时,有了一个兼顾质量、效率与稳定性的新选择。技术的不断迭代,正推动数字人从“能看”迈向“好用、耐用”的新阶段。更多关于人工智能生成视频的技术讨论,欢迎到云栈社区交流。
 发表于 2026-3-21 06:44:11
|
查看: 149|
回复: 0
发表于 2026-3-21 06:44:11
|
查看: 149|
回复: 0
