
我们常听到一种说法:机器人学习速度太慢,做不好精细动作,这让它们“进厂打螺丝”的进度一直受阻。但现在,这个问题可能找到了突破口。
近日,具身智能领域的明星公司Physical Intelligence公布了一项新进展。他们利用一种名为“RL token”的创新方法,让机器人仅需十几分钟到几小时的真实世界练习,就能熟练掌握插网线、拧微型螺丝、插充电线等高精度操作。


过去一年,机器人在叠衣服、端盘子等粗略任务上表现不俗,但一到需要高精度的环节就容易“掉链子”。比如,“拿起螺丝刀”对机器人来说轻而易举,但“将螺丝刀严丝合缝地对准一颗极小的螺丝”则异常困难。在真实的工厂环境中,这种对精准、灵巧和速度的要求恰恰是最核心、最不可妥协的部分,也是体力劳动中最具挑战性的环节。

传统方法想让机器人掌握这类精细活,通常需要工程师重新训练庞大的“主脑”——即处理所有信息的视觉语言大模型(VLA)。这个过程不仅计算量巨大,而且效率低下,进展缓慢。
Physical Intelligence 的研究人员另辟蹊径,他们想出了一个更高效的办法:不再费时费力地重新训练整个主脑,而是为它加装一个专门负责优化精细动作的“外挂”模块,也就是RL token。
依靠这种方法,机器人的技能进化速度实现了质的飞跃。在各项任务中最需要精细操作的步骤上,机器人的执行速度提升到了原来的3倍,甚至超过了人类远程操控机器人干活的速度。Physical Intelligence表示,RLT(Reinforcement Learning Token)技术让他们的模型离“在真实工作岗位上边干边学”的终极目标更近了一步。
核心技术:RL Token如何工作?
Physical Intelligence 此前已证明,通过名为 Recap 的方法,VLA模型能够借助强化学习从经验中学习。但Recap主要针对长周期任务,而在实际应用中,我们更希望机器人能利用极短时间的数据,快速攻克某项技能里最困难的个别环节。
例如,在机器人执行精密组装任务时,我们或许只想微调“把螺丝刀对准螺丝”这一个具体动作,这远比将整个VLA大模型从头微调一遍要高效得多。这种精准的自适应训练,理论上可以直接在机器人部署后边工作边进行。
理想的进化过程应在机器人“大脑”内部完成,并能从每次尝试中最大化学习收益。然而,要在几小时内端到端地训练整个庞大复杂的VLA模型,无论从算力还是实操角度看都极具挑战。
Physical Intelligence 的核心思路是:不让VLA大模型亲自下场学习,而是让它学会“总结汇报”,从而配合一个极其轻量、可实时更新的小模型来完成强化学习微调。他们训练VLA模型(具体版本为Pi 0.6)输出一个“RL token”。这个token就像VLA内部复杂思考过程的“一份极简摘要”,然后被提供给能够进行实时强化学习训练的小模型使用。
具体而言,这个RL token会输入给负责输出动作的Actor网络和负责评估打分的Critic网络。这两个网络采用了一种数据效率极高的off-policy强化学习算法进行训练。正因Actor和Critic处理的是高度压缩的摘要信息,它们可以被设计得非常轻量,直接在机器人本体上每秒更新数百次。这种极快的响应速度,使得强化学习能在机器人每次试错后立刻调整其行为策略。
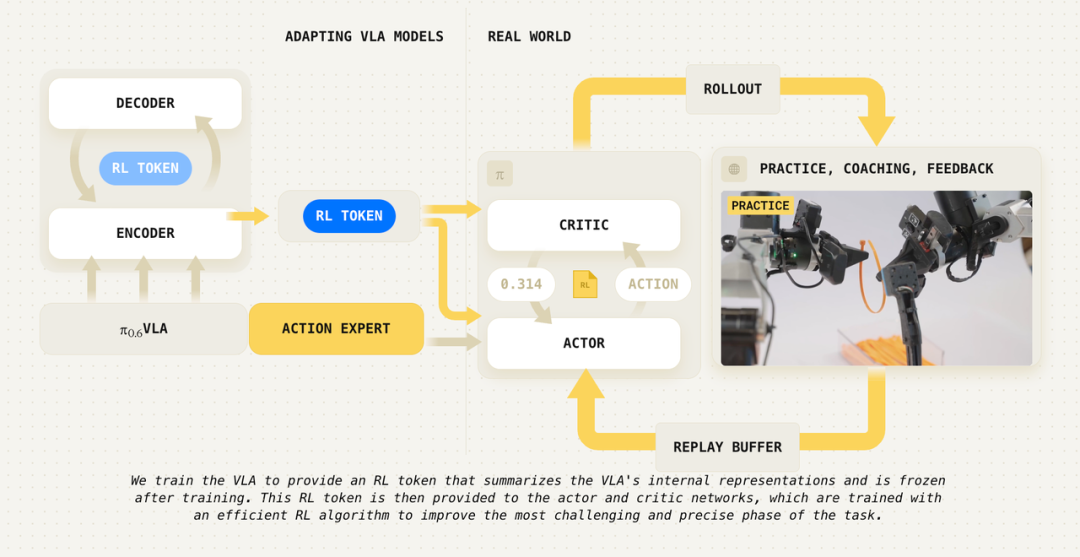
RLT技术首先会对预训练的VLA进行改造:为其添加一个由编码器和解码器组成的Transformer结构。这个结构被训练去通过一个“信息瓶颈”来预测大模型的内部特征(embeddings),从而压缩生成一个极简的表达,即RL token。这个token浓缩了当前观察画面中,强化学习的Actor和Critic做出决策所需的所有关键信息。这样一来,即便是非常小的Actor和Critic网络,也能站在大模型丰富的语义理解基础之上,学会如何改进动作。
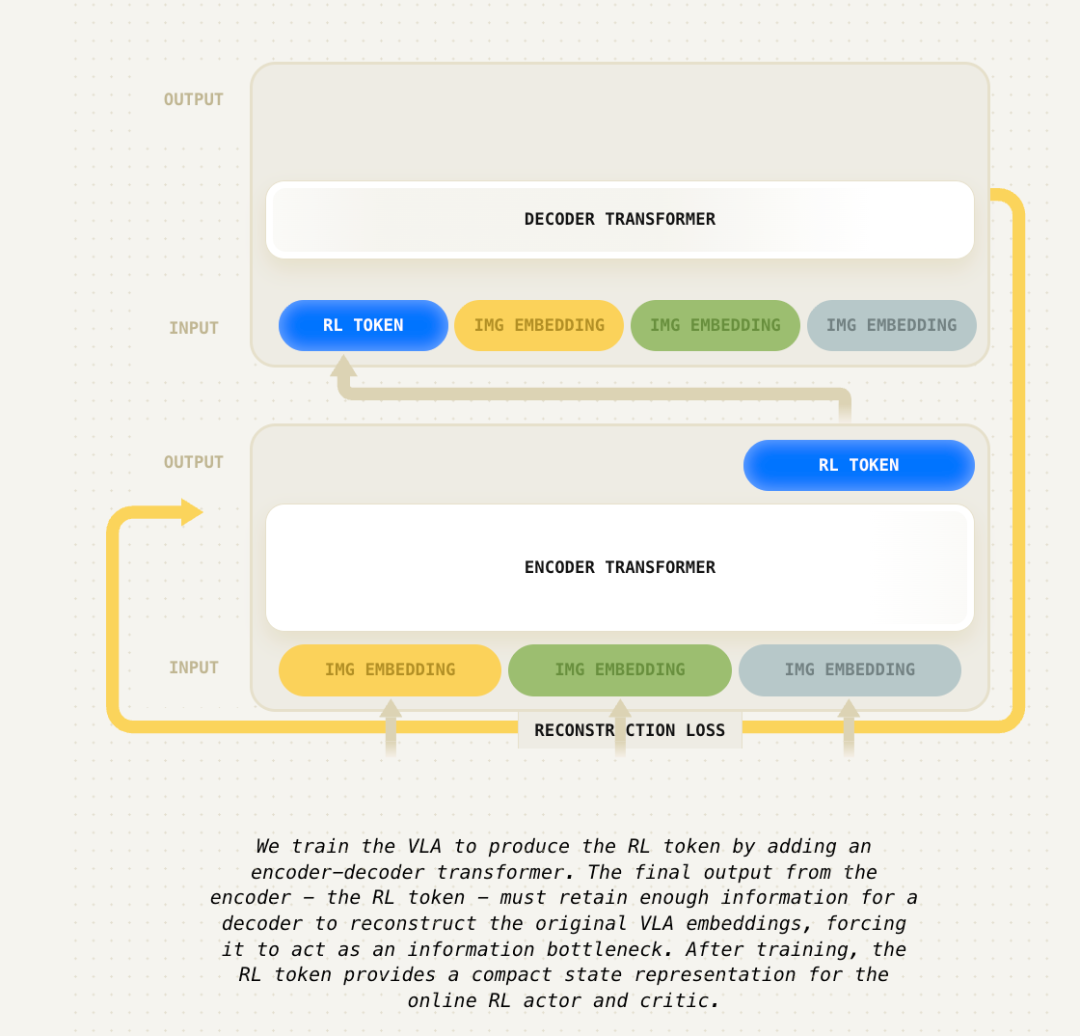
获得RL token后,研究人员只需让机器人在现实世界中积累几小时甚至几分钟的数据,就能通过在线强化学习来训练小型的Actor和Critic网络。为了让这个过程效率最大化,他们做了精心的设计:在线强化学习的Actor网络必须在与VLA相同的动作空间中工作,与VLA的先验行为保持兼容,并且能从有限的真实世界数据中高效学习。
具体实现包括以下几个关键点:
- 预测“动作块”: 强化学习策略预测的是一连串的“动作块”(action chunks),这与VLA习惯的动作输出结构保持一致,而不是控制底层每一个细微的关节运动。这使得在线策略能够直接调整任务中具有时间跨度的连贯动作序列。
- 学会“修改”而非“推翻”: 强化学习策略并非从零开始探索。Actor网络会接收VLA预测出的动作作为参考输入,因此它学习的是如何“编辑修改”VLA的动作,而不是全盘替换。研究人员将策略更新的方向限制在参考动作附近,这样当VLA原本的动作已经可靠时,机器人的探索就不会过于激进;只有当Critic网络明确发现了更好的方案时,才会偏离原计划。
- 防止“抄作业”: 为了避免小模型在训练初期“偷懒”而简单地模仿VLA的动作,他们引入了“参考动作dropout”机制,迫使Actor网络保持独立生成动作的能力。
- 融入人类干预: 最后,可以选择性地让人直接介入强化学习的更新过程。当机器人卡壳或犯错时,人类的纠正动作会被直接纳入并反馈到训练中。
正是这些设计选择,使得在线强化学习变成了一个可复用的“通用配方”。它无需针对具体任务进行专门的工程适配,就能直接挂载到预训练好的VLA模型上,去应对各种不同的挑战。
攻克精细操作的“最后关键一毫米”
研究人员在四项对关键时刻精度要求极高的挑战性任务上测试了RLT:使用电动螺丝刀将微小的M3螺丝拧入机械臂、系紧扎带、插入网线以及插入电源线。


在这些任务中,通用的基础VLA模型通常能很好地完成大部分“粗略”动作,但任务最终的成败与快慢,往往取决于一个需要大量物理接触的关键阶段。在这个阶段,位置、角度哪怕有毫厘之差,或者时机稍有不对,都会导致彻底失败。
以拧螺丝为例,机器人必须在位置和旋转角度上都达到亚毫米级的精准度,才能使螺丝刀尖完美嵌入螺丝槽。要知道,螺丝刀尖距离机器人的夹持点有10厘米远,手腕关节的微小偏差传递到末端会被放大。而且,从机器人自带的手腕摄像头视角看,这些细微的接触过程甚至难以清晰辨识。

在四项任务中,基础VLA模型在初期表现良好(如稳稳拿起工具),但在最需要精度的“临门一脚”阶段就会失败。RLT技术正是为此设计:研究者不再让它重新学习整个任务流程,而是利用在线强化学习专门攻克这些“硬骨头”环节。实际测试表明,机器人仅利用15分钟的真实世界交互数据,就能显著优化每个任务中最困难部分的性能。
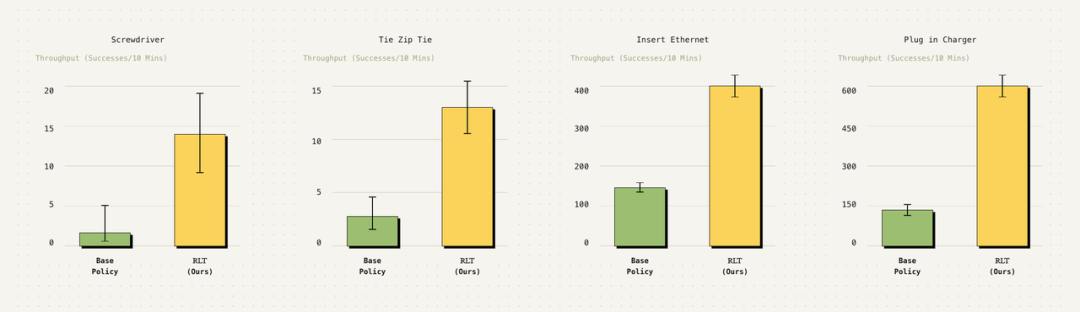
他们将RLT应用于这四项任务的关键阶段,评估了其在短暂插入动作和更长时间跨度任务上的效果。结果显示,在所有任务中,相比基础模型,RLT在速度和成功率上都实现了显著提升。下图展示了训练前后的性能对比,指标为“吞吐量”(即每10分钟内成功完成任务的次数)。
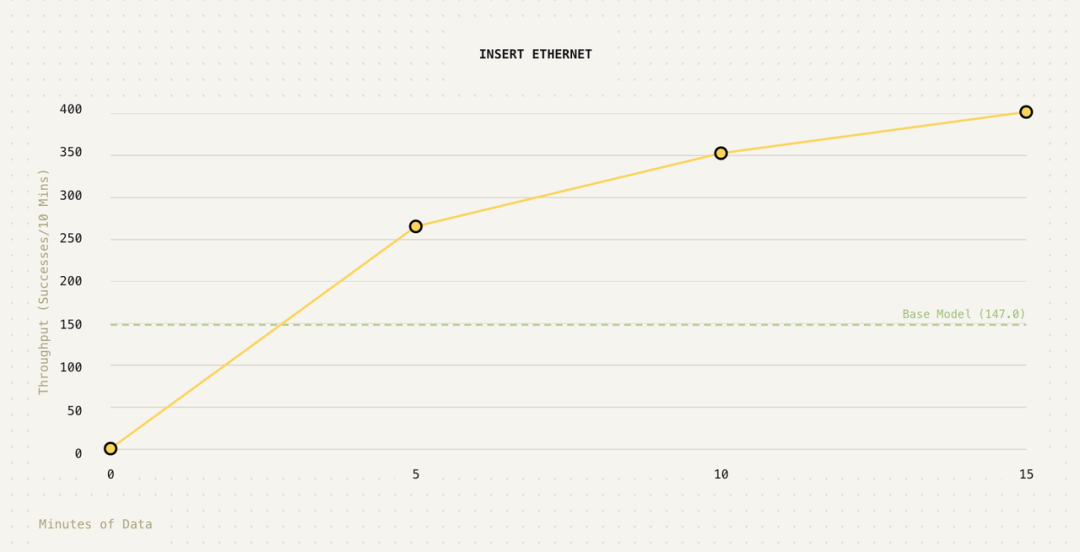
下方的进度曲线图展示了RLT在“插入网线”任务上吞吐量的提升过程。整个训练周期为2小时,但真正包含机器人动作的有效数据仅为15分钟,其余时间主要用于机器复位重置和其他计算开销。
令人印象深刻的是,RLT不仅仅超越了基础模型,它在“插入网线”任务上的执行速度甚至超过了人类远程操作的速度!正如下图的执行时长分布所示,由最终强化学习策略完成的测试中,有一半比数据集中任何一次人类示范操作都要快。
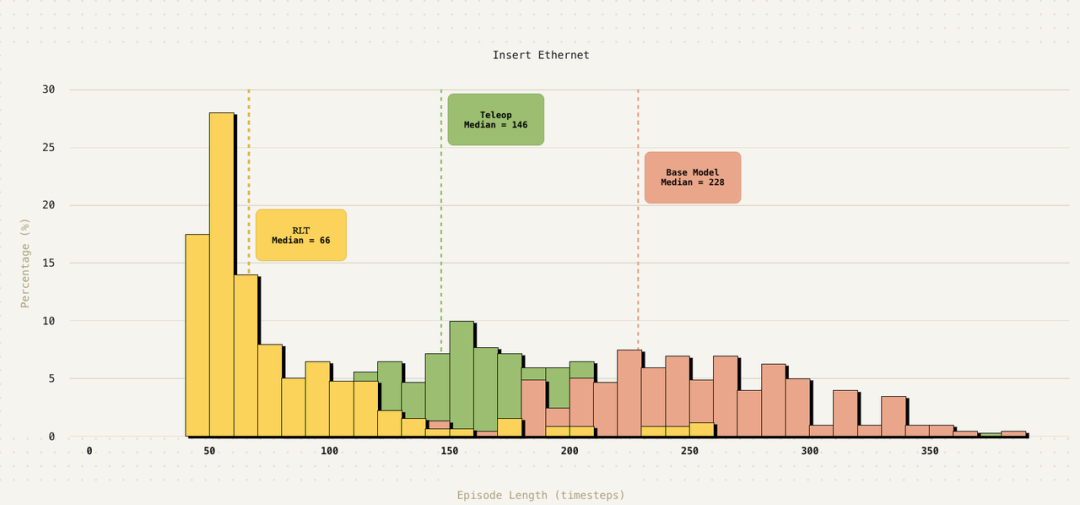
这项研究表明,通过将大模型的知识压缩与小模型的快速适应性学习相结合,机器人掌握复杂精细操作的门槛和时间成本被大幅降低。机器人“进厂打工”的进程,或许比我们预想的要快得多。技术的快速迭代,如RLT所示范的边干边学能力,正在为云栈社区的开发者们打开具身智能应用的新想象空间。
参考链接: https://www.pi.website/research/rlt
 发表于 2026-3-21 15:47:36
|
查看: 389|
回复: 0
发表于 2026-3-21 15:47:36
|
查看: 389|
回复: 0
