视觉-语言模型(VLMs),例如大名鼎鼎的 CLIP,彻底改变了我们处理零样本图像识别的方式。这些模型在大规模(通常是数十亿级别)的图像-文本对数据集上训练,从而吸收了广泛的通用知识,获得了识别在训练中从未“见过”的物体的惊人能力。
然而,当我们试图通过Prompt Tuning过程,将这些“全能选手”适配到具体的下游任务时,往往会遇到一个棘手的问题:模型虽然变成了特定任务的专家,却可能遗忘了原有的通用智能。这个现象被形象地称为“Base-to-New”泛化困境,本质上是一种灾难性遗忘。
论文《Visual-Language Prompt Tuning with Knowledge-guided Context Optimization》正是针对这一挑战提出了解决方案。它深入探讨了问题根源,并提出了一种名为KgCoOp(知识引导上下文优化)的简洁有效的约束机制。在实际应用中,机器学习系统常常被部署在类别不断更新的环境中。如果一个模型在面对新类别时表现一塌糊涂,其可靠性和实用性将大打折扣。因此,提升模型的泛化能力,是构建鲁棒视觉-语言系统的关键。
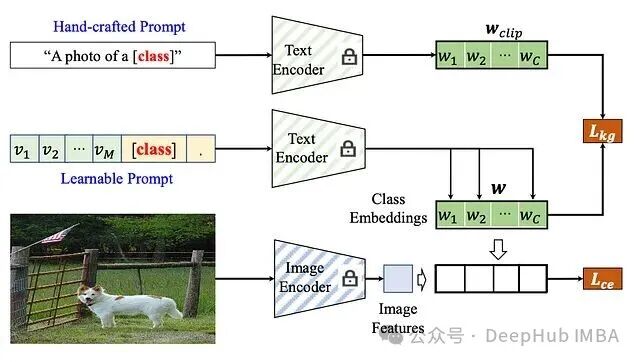
上图展示了 Knowledge-guided Context Optimization(KgCoOp)框架的核心思想:通过一个知识引导损失(L_kg)对可学习的提示向量进行正则化,从而在微调过程中保持模型的泛化能力。
为什么标准的CoOp在新类别上会失败?
Context Optimization(CoOp)是Prompt Tuning的一种经典实现。它用一个可学习的上下文向量序列,替换了固定的手工模板(比如“一张[类别]的照片”)。这种微调方式通常在训练阶段见过的基类上表现优异,但代价往往是灾难性的知识遗忘。
在有限的标注样本上进行微调时,模型倾向于学习仅对这几个特定类别有判别性的文本特征,这导致了其文本表示严重偏离了原始的通用知识。跨越11个基准数据集的实验数据揭示了一个清晰的趋势:标准的微调方法(CoOp)虽然提升了基类的准确率,却将新类别上的性能打压到了比原始零样本模型还要低的水平。
以下是零样本模型与标准微调方法的性能对比:

(数据基于ViT-B/16模型在11个数据集上的平均值)
从“遗忘”的几何角度理解
研究进一步发现,新类别性能下降的程度,与可学习提示嵌入(记作 $w_{coop}$)和原始手工CLIP嵌入(记作 $w_{clip}$)之间的欧几里得距离直接正相关。
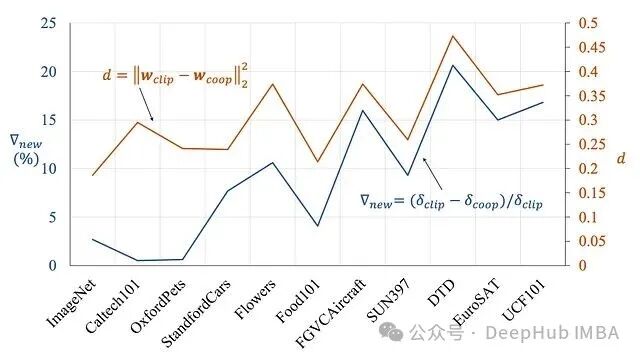
这张图对比了Base-to-New的泛化性能,直观显示了标准Prompt Tuning如何提升已见类别性能,但同时降低了未见类别的准确率。
一个关键结论是:学习到的提示与手工提示之间的距离越大,模型在未见类别上的性能退化就越严重。
在DTD(纹理数据集)和EuroSAT(卫星影像数据集)等任务上,学习到的提示偏离CLIP锚点最远,其泛化差距也最大。这启发我们:如果能够将可学习提示“约束”在原始通用知识的附近,就有可能维持其原有的泛化能力。
Knowledge-guided Context Optimization (KgCoOp) 详解
KgCoOp 正是基于上述洞察,引入了一种新颖的正则化框架。该框架不再允许提示向量在优化过程中“自由漂移”,而是增加了一个知识引导损失 $L_{kg}$,其目标就是最小化可学习提示与手工提示之间的距离。
A. 预备知识:CLIP 与 CoOp
在零样本CLIP中,给定图像嵌入 $x$,预测其为类别 $y$ 的概率 $p(y|x)$ 计算公式为:
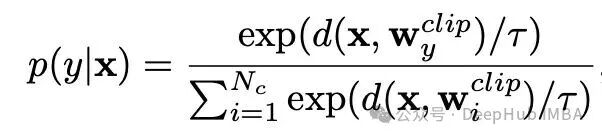
其中 $d(x, w_y^{clip})$ 代表余弦相似度,$w^{clip}$ 是由手工模板生成的嵌入。CoOp 将这些固定模板替换为 $M$ 个可学习的上下文向量 $V = \\{v_1, v_2, …, v_M \\}$。此时的提示变为 $t_i^{coop} = \\{v_1 , v_2 , ..., v_M , c_i \\}$,其中 $c_i$ 是类别名称对应的词元。
B. KgCoOp 的核心公式
KgCoOp 提出,通过减少可学习提示与手工提示之间的“物理距离”,可以有效缓解底层知识的遗忘。因此,其训练目标是在标准的交叉熵损失 $L_{ce}$ 之上,叠加这一新的约束项:
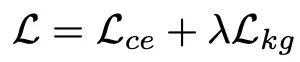
其中引入的知识引导损失 $L_{kg}$,被定义为微调后得到的类别嵌入 $w_i$ 与原始的 CLIP 锚点 $w_i^{clip}$ 之间的均方欧几里得距离:
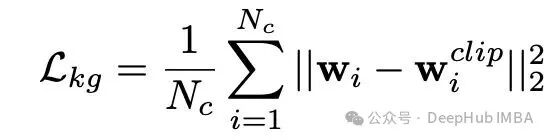
在最小化这个距离的过程中,KgCoOp 强制模型在进行任务特定优化的同时,必须“记住”其从大规模预训练中学到的通用视觉-语言特征。这为高效模型训练中的知识保持提供了新思路。
实验设置与基准测试
研究在11个多样化的图像分类基准上对 KgCoOp 进行了全面评估。实验采用了 ResNet-50 和 ViT-B/16 作为骨干网络,主要测试条件设置为 16-shot。
覆盖的数据集范围广泛,包括 ImageNet、Caltech101 这样的通用对象识别,OxfordPets、StanfordCars、Flowers102、Food101、FGVCAircraft 等细粒度分类,以及 EuroSAT(卫星影像)、UCF101(动作识别)、DTD(纹理)、SUN397(场景)等专业领域任务。
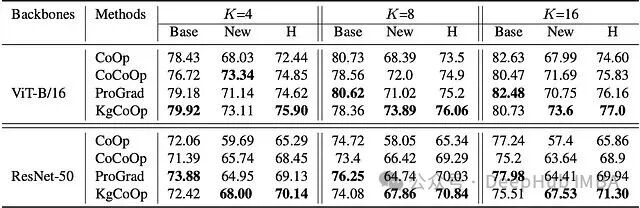
(基于ViT-B/16和ResNet-50骨干网络,在所有11个数据集上,不同K-shot设置下的平均性能对比)
测试结果显示,KgCoOp 在所有测试设置的平均调和均值上取得了最高分。虽然像 ProGrad 这样的方法在基类上表现略好,但在处理新类别时,其性能与 KgCoOp 存在明显差距。具体来看,在 ViT-B/16 骨干网络配合 16-shot 设置的场景下,KgCoOp 将新类别的准确率相较于 CoOp 基线提升了 5.61%,比另一个先进方法 CoCoOp 也高出 1.91%。这些数据有力地证明了 KgCoOp 能更好地平衡任务特定性能和通用性,有效缓解了 Base-New 困境。
在领域泛化场景中的表现
领域泛化(DG)测试主要用于评估模型在类别标签不变,但数据分布发生偏移时的鲁棒性。实验流程是:使用 16-shot 样本在标准 ImageNet 数据集上训练,然后在四个分布外的变体数据集(ImageNetV2、ImageNet-Sketch、对抗样本集 ImageNet-A 和渲染集 ImageNet-R)上进行评估。
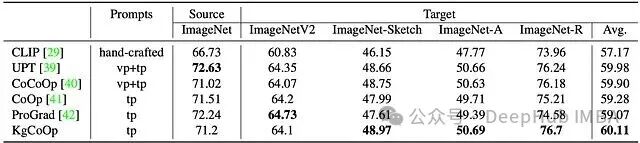
(在领域泛化场景下的提示学习对比,“vp”和“tp”分别表示视觉提示和文本提示。)
深入分析:效率与泛化的权衡
超参数 $\lambda$ 的敏感性分析
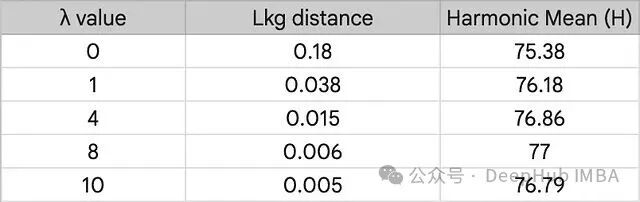
定量分析揭示了一个直接规律:增大 $\lambda$ 可以减小 $L_{kg}$ 距离,迫使学习到的提示进一步贴近手工提示。距离的缩小直接带来了调和均值的提升,并在 $\lambda = 8.0$ 时达到峰值。然而,继续加大 $\lambda$ 会使约束过于严苛,反而阻碍模型学习当前任务特有的判别特征,导致性能回落。这表明,只要约束在一个合理范围内,最小化学习知识与通用知识之间的偏差,是维持泛化能力的关键。
计算效率对比

计算两个嵌入向量之间的欧几里得距离带来的额外开销微乎其微。相比之下,CoCoOp 因为需要为每个训练实例单独生成图像条件的上下文,训练速度慢了近 26 倍(160 ms/图)。ProGrad 需要计算梯度并进行对齐检查,耗时也较高(22 ms/图)。KgCoOp 则保持了与基础 CoOp 相近的训练速度(6 ms/图),几乎以最低的时间成本达到了顶级的性能。
$L_{kg}$ 损失的普适性
$L_{kg}$ 约束并非一个孤立技巧,它可以作为插件集成到其他 Prompt Tuning 框架中。下面的表格显示,在 ViT-B/16 上,为 CoCoOp 和 ProGrad 添加知识引导约束后,它们在新类别上的性能和调和均值都获得了一致提升。
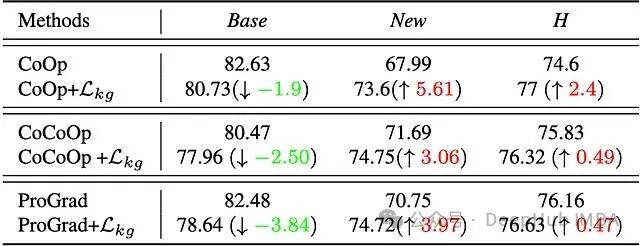
具体而言,CoCoOp 结合 $L_{kg}$ 后,新类别准确率从 71.69% 升至 74.75%,调和均值提升了 0.49%。ProGrad 结合 $L_{kg}$ 后,新类别准确率从 70.75% 升至 74.72%,调和均值从 76.16% 增至 76.63%。这证明标准文本提示微调中观察到的“灾难性遗忘”是跨架构的普遍问题,而 KgCoOp 的约束思想具备横向拓展到更多提示体系的潜力。对于希望深入研究其技术细节的开发者,可以参考相关的技术文档。
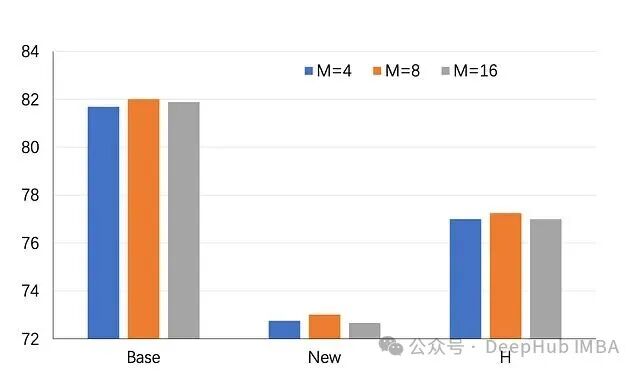
上下文长度与初始化策略的影响
为了与现有基线公平比较,实验默认使用上下文长度 $M=4$。但在消融分析中发现,将长度设置为 $M=8$ 能在已见和未见类别上挖掘出更大的性能潜力。如果算力允许,适当增加序列长度是一个低成本的性能提升点。
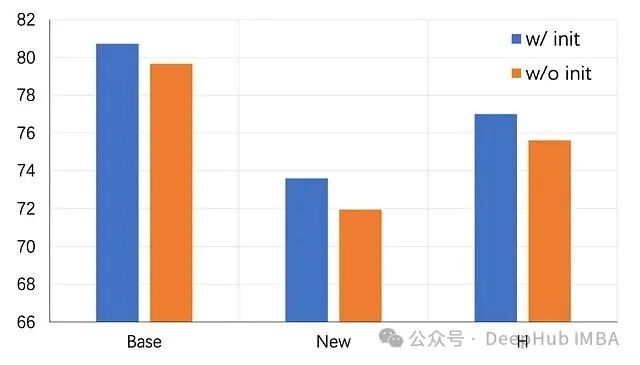
局限性与未来展望
KgCoOp 在提升未见类别泛化能力的同时,依然面临稳定性与适应性的经典博弈。强化知识引导约束虽然能让新类别评分更亮眼,但往往会在一定程度上压低基类的性能上限。这种此消彼长反映了硬性约束的副作用:它通过限制学习到的提示与原始表征的距离来防止过拟合,但也可能削弱模型为适应极端特定场景而进行深度调整的灵活性。
引入超参数 $\lambda$ 也意味着多了一层调参负担。设定不当,轻则导致欠拟合,重则让提示学习的自适应能力名存实亡。
总结与工程实践启示
开发能够根据任务和数据自动调整约束强度的机制,仍是未来重要的研究方向。如果能在迭代中引入数据驱动的超参数自适应策略,模型在稳定性和灵活性之间的切换将更加从容。
KgCoOp 提供了一套务实的调优路径。面对一个强大的基座模型,建议首先运行零样本基线,摸清其泛化能力的初始水平。在面临算力瓶颈或对推理延迟要求严格的生产环境中,KgCoOp 因其高效性,是一个值得优先考虑的轻量化方案。
总而言之,维护微调参数与预训练源知识之间的几何对齐关系,是一种经过验证的轻量级技术。仅凭一个简单的欧几里得距离损失,它就有效地为模型在新领域的能力兜住了下限,减少了对大量新样本数据的依赖。这为解决提示微调中的灾难性遗忘问题,提供了一个简洁而强有力的工具。
 发表于 2026-3-24 01:04:21
|
查看: 197|
回复: 0
发表于 2026-3-24 01:04:21
|
查看: 197|
回复: 0
