随着支持更长上下文的多模态大语言模型(MLLM)兴起,高分辨率图像和长视频处理带来了效率难题:它们产生的视觉 Token 数量远超文本,在自注意力机制二次复杂度的制约下,迅速成为了计算瓶颈。
现有研究通常采用渐进式剪枝来减少视觉 Token,但这些方法大多采用固定策略,忽视了一个关键事实:MLLM 的不同层在处理多模态信息时,功能上存在显著差异。
通过对 MLLM 内部信息流的深入分析,研究者们发现模型层级功能分化明显:浅层主要负责传递视觉特征,中层集中进行跨模态融合,而深层则承担语义整合与推理任务。视觉信息在不同层间的演化过程呈现出明显的非均匀性。
基于这一洞察,宁波东方理工大学(宁波数字孪生研究院)沈晓宇团队提出了 HiDrop 框架。该框架的核心思想是让压缩策略与模型的层级功能对齐,具体通过延迟注入、凹金字塔式剪枝和提前退出三项设计来实现。
实验效果令人瞩目:在压缩掉约 90% 的视觉 Token 后,HiDrop 依然能保持 98.3% 的原始模型性能,同时实现了 1.72× 的训练加速和 2.2× 的预填充加速。
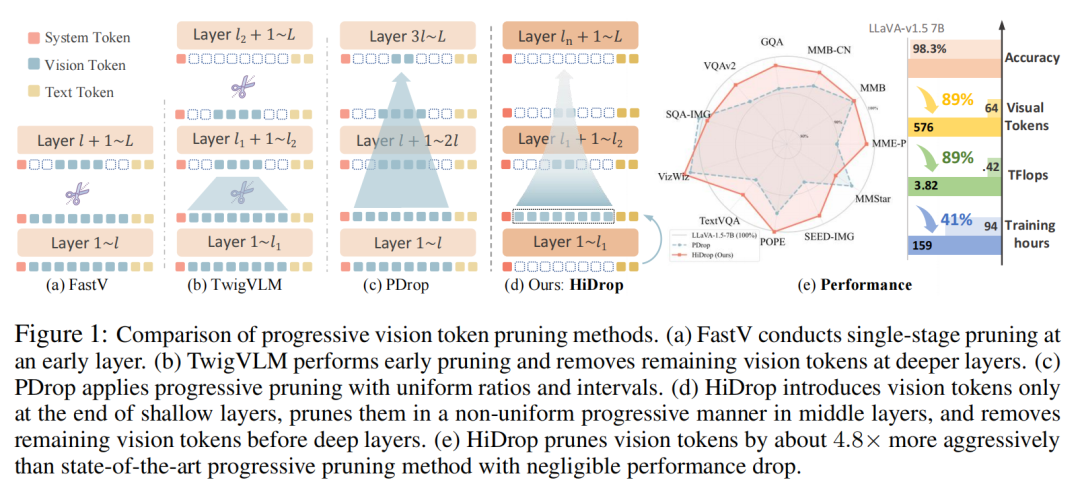
图 1:不同视觉 Token 剪枝策略的对比。(a) FastV 在早期单层剪枝;(b) TwigVLM 在浅层剪枝并移除深层剩余标记;(c) PDrop 在各层采用均匀比例和间隔的渐进剪枝;(d) HiDrop(本文方法)仅在浅层末尾注入视觉Token,在中层进行非均匀渐进剪枝,并在深层之前移除剩余Token;(e) 性能雷达图显示,HiDrop 能以比当前最优方法激进约 4.8 倍的强度进行剪枝,且性能损失可忽略。
目前,这项研究成果已被顶级会议 ICLR 2026 接收。
核心发现:揭示MLLM内部信息处理的动态机制
为了理解 MLLM 是如何处理和整合视觉信息的,作者首先分析了模型表征在不同层级中的动态演化过程。具体来说,他们通过计算各模态表示在层间的余弦相似度,来衡量模态内部表征的变化;同时,通过观察固定指令在配对不同图像时文本嵌入的变化,来评估视觉信息对文本表示的跨模态影响。
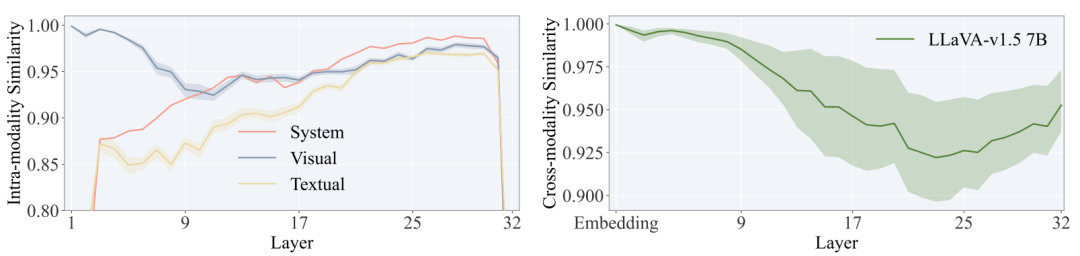
图 2:MLLM 各层的信息表征动态。左图展示了模态内部表征的逐层精化过程,右图则反映了视觉与语言之间的跨模态交互强度。
-
浅层:视觉信息的“搬运工”
- 从左图可见,浅层视觉 Token 的表征具有很高的自相似性,只在连续层间发生微小变化,这表明大语言模型(LLM)在此阶段对视觉信息的主动处理微乎其微。
- 从右图可见,浅层中固定指令的文本嵌入对于不同的配对图像几乎保持不变,表明跨模态影响同样可以忽略,有意义的融合尚未开始。
- 结论:浅层更像是一个视觉信息的“传递通道”,主要负责将视觉特征向深层传播,而非进行实质性的语义处理。
-
中层:跨模态融合的“主战场”
- 与浅层的被动不同,中层成为了跨模态融合的关键阶段。此时,视觉信息开始显著影响文本表示,说明模型正在主动整合视觉与语言,完成语义层面的对齐与融合。
- 但进一步分析发现,这个过程具有明显的稀疏性:仅有少量关键的视觉 Token 对文本表示产生决定性影响,而大量的视觉 Token 则相对冗余。这使得中层成为了视觉 Token 压缩的黄金窗口。
-
深层:语义推理的“执行者”
- 当跨模态融合在中层基本完成后,模型进入以抽象语义推理为主的阶段。此时,视觉信息对文本表示的直接影响逐渐减弱,模型更多依赖已经融合好的语义表示进行高层推理。
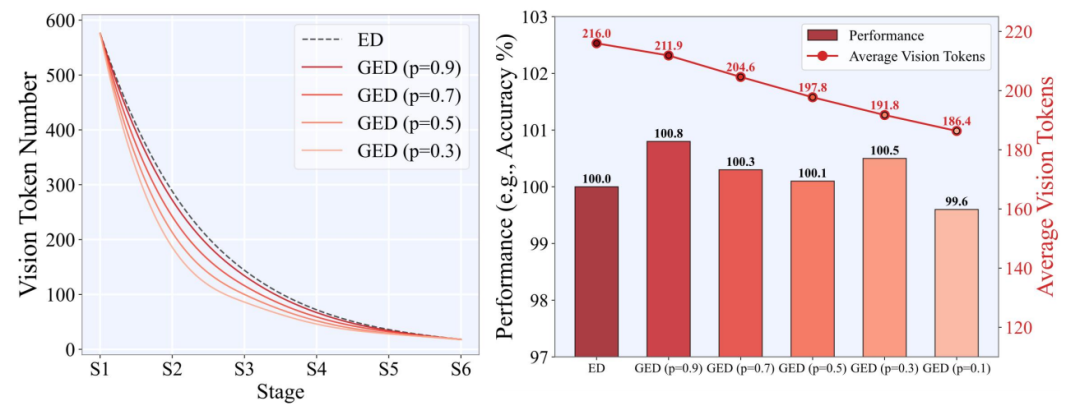
图 3:中层视觉 Token 的稀疏性分析。左图:不同参数下视觉标记数量的压缩曲线。右图:即使在高压缩率下,模型性能仍保持稳定,表明剪枝具有良好的鲁棒性。
综合来看,MLLM 的信息处理呈现出清晰的层级结构:浅层传递、中层融合、深层推理。这一发现为设计更高效的视觉 Token 压缩策略指明了方向。
核心方法:HiDrop的三段式层级对齐压缩策略
基于对 MLLM 层级信息处理动态的分析,作者提出了 HiDrop 框架。该框架将与模型结构对齐的视觉 Token 压缩策略,划分为浅层、中层和深层三个阶段,使计算资源的分配与实际的信息处理过程精准匹配。
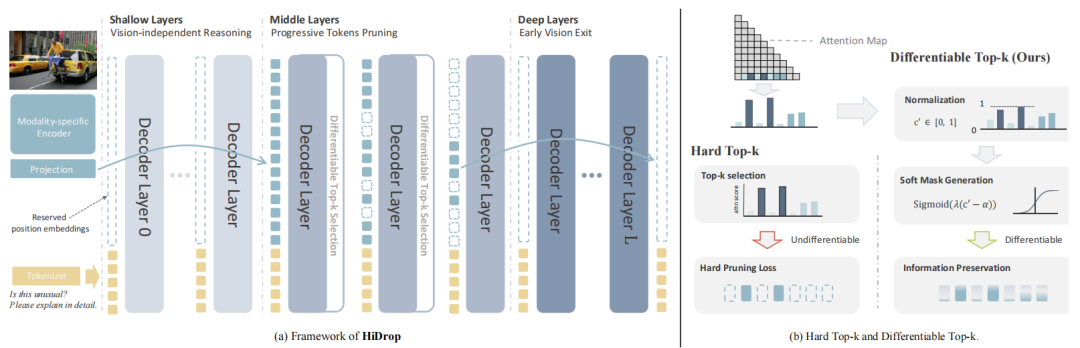
图 4:HiDrop 框架概述。(a) 框架示意图,浅层专注于视觉无关推理,中间层通过凹金字塔式方案多阶段剪枝冗余标记,深层实现早期视觉退出。(b) Hard Top-k 算子与 Differentiable Top-k 算子的对比,后者能实现自适应选择并更好地保留信息。
1. 浅层:视觉延迟注入
既然浅层对视觉信息的处理有限,HiDrop 选择不在一开始就注入全部视觉Token,而是延迟到更深层再引入。注入点被设置在跨模态融合的起始处(通过分析视觉表征层间相似性曲线识别)。由于浅层本就不承担融合任务,这种延迟注入在减少计算量的同时,几乎不影响性能。
2. 中层:凹金字塔式剪枝
中层是融合的关键,且视觉Token贡献稀疏。因此,HiDrop 在此阶段采用激进的凹金字塔式剪枝策略:先快速削减大量冗余Token,后续减缓剪枝速度。同时,引入 Differentiable Top-k 算子实现自适应选择,在保留关键信息的同时降低开销。
为了确定哪些层最适合剪枝,作者提出了 层间视觉注意力相似性 指标,通过衡量视觉Token注意力在相邻层间的稳定性来识别过滤层,并根据该曲线的局部极值确定具体的剪枝位置。
3. 深层:视觉提前退出
当融合基本完成后,模型进入推理阶段,视觉Token的影响减弱。因此,HiDrop 在深层提前移除剩余的视觉Token,让后续层仅处理融合后的语义表示。
退出点通过从深到浅的掩码分析来确定,选择性能趋于稳定的点,以减少深层注意力计算。结合浅层的“延迟注入”和深层的“提前退出”,HiDrop 实际上形成了一个聚焦的视觉处理窗口,将视觉计算集中在最有效的中层。消融实验证明,该窗口策略能实现良好的效率-性能平衡。
此外,HiDrop 还优化了动态Token选择带来的工程挑战,例如采用持久化位置编码保持位置一致性、保持与FlashAttention的兼容性,并通过并行解耦视觉计算来进一步缩短预填充时间。
实验结果:更高压缩率,更优性能,更佳效率
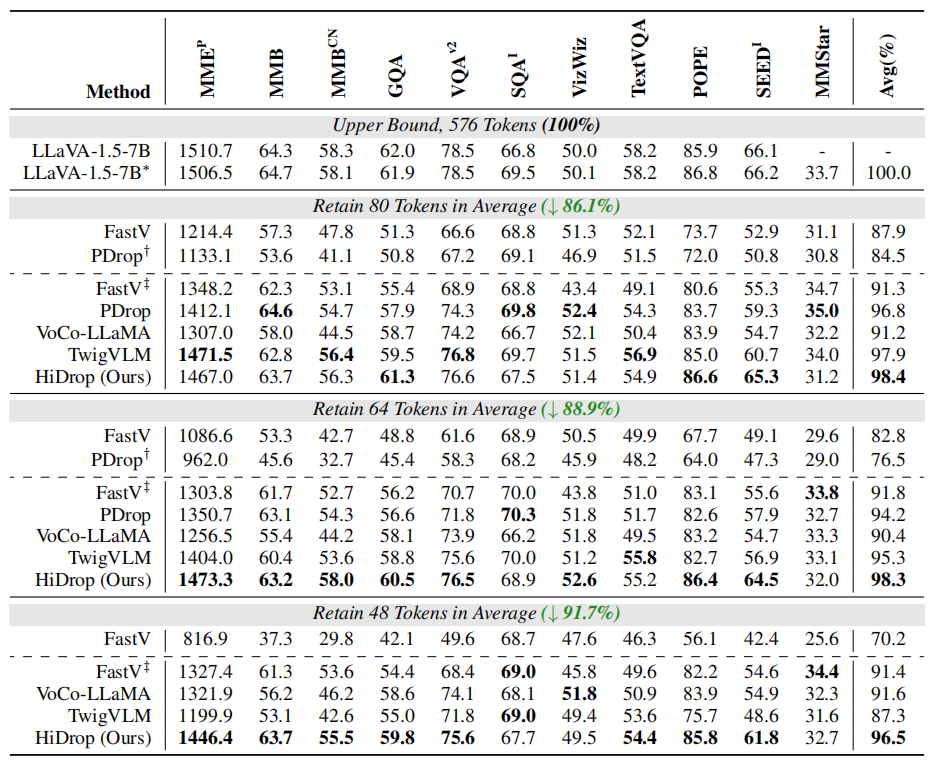
在多个多模态基准测试上,HiDrop 在更高的压缩率下仍保持了优异性能。实验表明,当平均视觉Token压缩率达到 88.9% 时,模型仍能保持 98.3% 的原始性能;即使压缩率提升至 91.7%,其表现依然优于对比方法 PDrop 在 88.9% 压缩率下的结果,展现了更优的压缩-性能权衡。
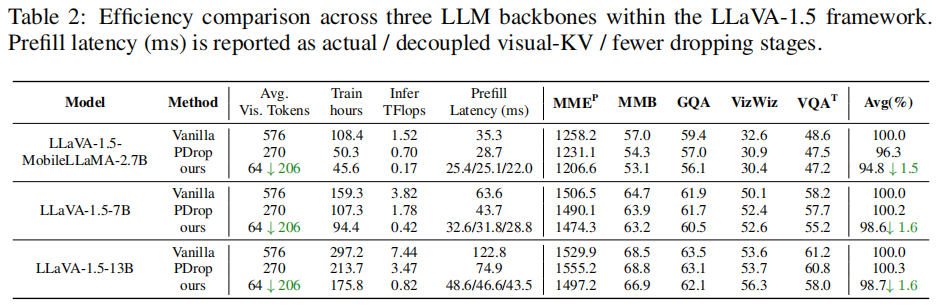
除了保性能,HiDrop 在效率提升上表现更为突出。该方法将平均视觉Token数量减少了约 90%,大幅降低了推理FLOPs。在 LLaVA-1.5-7B 模型上,实现了约 1.7× 的训练加速和 2.2× 的预填充加速。
总结
本文从剖析 MLLM 内部信息处理动态入手,清晰揭示了视觉信息在不同层级中的功能差异,并据此提出了 HiDrop 这一高效的压缩框架。实验结果证明,HiDrop 能在实现极高视觉Token压缩率的同时,几乎无损地保持模型性能,并显著提升训练与推理效率。这项研究有力地表明,深入理解模型内部的信息流结构,是设计下一代高效多模态模型的关键方向。
对这类前沿的模型优化技术感兴趣?欢迎在 云栈社区 与更多开发者和研究者交流探讨。
 发表于 2026-3-24 01:20:38
|
查看: 163|
回复: 0
发表于 2026-3-24 01:20:38
|
查看: 163|
回复: 0
