当前,视觉-语言-动作(VLA)模型需要让机器人能够理解多模态指令、进行长程规划,并在动态环境中自适应地执行任务。然而,传统的端到端训练方式直接将输入映射到动作,缺乏显式的推理过程,这严重制约了模型处理复杂、长程动态任务的能力。
为了突破这一瓶颈,NVIDIA与台湾大学的研究团队联合提出了ThinkAct模型。这是一个基于大语言视觉模型(MLLM)的双系统VLA框架,通过强化驱动的视觉潜在规划,巧妙连接了高层推理与底层动作执行,赋予MLLM在真实世界中“先思考后行动”的能力。
大量在具身推理和机器人操作基准上的实验证明,ThinkAct在复杂的机器人任务中,展现出了卓越的少样本适应、长程规划以及自主纠错能力。

方法
ThinkAct的核心是双系统架构,旨在桥接结构化的推理与可执行的动作。具体而言,它通过基于动作对齐奖励的强化学习来增强MLLM的长程规划能力,该奖励来源于视觉目标完成度与轨迹分布的匹配。此外,ThinkAct还能利用人类和机器人的演示视频,激发基于视觉观察的具身推理。
为了有效连接推理与执行层,模型将中间推理步骤压缩为紧凑的潜在轨迹。这个轨迹捕获了高层任务意图,使得下游的动作网络能够高效地适应新环境。通过强化结构化推理并专注于真实世界的动作对齐,ThinkAct不仅能够解决长程操作任务,还能在物理场景中实现少样本动作适应和自我纠正。

1.1 用于具身推理的强化视觉潜在规划
为了实现能在多样化环境中泛化的具身推理,团队采用强化学习来增强MLLM的推理能力。现有方法通常让MLLM在生成底层动作前进行推理,并使用任务成功率作为奖励信号,但这种方法往往局限于特定仿真环境。
为解决这一挑战,团队设计了一种创新的动作对齐视觉反馈机制。它能够捕捉长程目标,并鼓励规划过程与视觉关联。具体来说,将高层规划表示为时空轨迹,该轨迹捕获了视觉场景中夹爪末端执行器的运动,以此作为引导具身推理的视觉-动作指导。
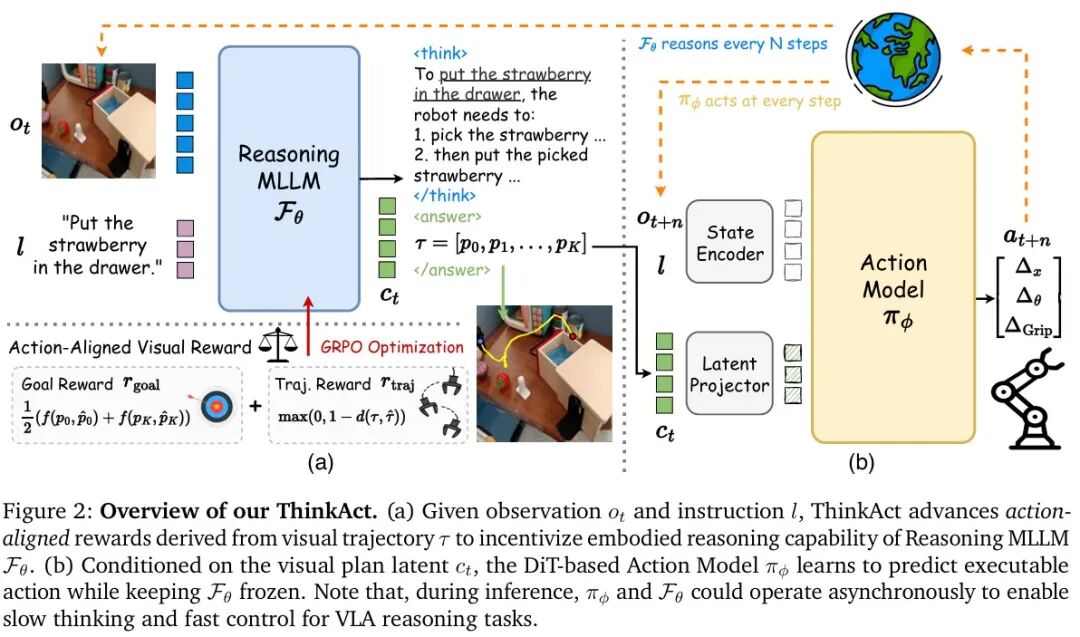
为了增强MLLM $F_θ$ 的具身推理能力,研究使用分组相对策略优化(GRPO)进行强化微调。给定输入 $(o_t, l)$,GRPO首先从原始MLLM $F_{θ_{old}}$ 采样M个不同的响应 $\{z_1, z_2, …, z_M\}$。每个响应使用以下奖励函数进行评估:
$r = 0.9r_{visual} + 0.1r_{format}, where\ r_{visual} = ω_{goal} r_{goal} + ω_{traj} r_{traj}. (3)$
得到一组奖励信号 $\{r_1,r_2,…,r_M\}$。因此,通过最大化以下目标来优化 $F_θ$:
$J_{GRPO}(θ) = 1/M ∑_{i=1}^M (F_θ(z_i|o_t,l)/F_{θ_{old}}(z_i|o_t,l)) A_i - β D_{KL}(F_θ(z_i|o_t,l) || F_{θ_{old}}(z_i|o_t,l))), where\ A_i = (r_i - mean(\{r_1,...,r_M\})) / std(\{r_1,...,r_M\})$
为了进一步获取通用的具身知识,ThinkAct可以灵活地利用公开可用的问答数据,通过将其格式化为问答式准确性奖励,来增强机器人在视觉问答(VQA)或故障检测等方面的能力。完成强化微调后,MLLM能够生成长链思维(CoT)步骤,同时将文本推理抽象为紧凑的视觉计划潜变量 $c_t$,以捕获长程时空规划意图。
1.2 推理增强的动作适应
利用MLLM推理出的高层具身意图,目标是以 “先思考后行动” 的方式,将推断出的视觉潜在规划 $c_t$ 与目标环境的动作模型 $π_φ$ 连接起来,从而把具身推理嵌入到物理世界的可执行动作中。
具体而言,构建一个基于Transformer架构的动作模型 $π_φ$,该模型基于当前状态(由视觉观察和语言指令组成)来预测动作。虽然 $π_φ$ 仅凭感知就可在目标环境中运行,但通过一个潜在投影器(latent projector)将其与动作模型的输入空间相连,可以有效地利用推理指导,从而增强其在目标环境中的底层动作执行。因此,仅需使用带标注的动作演示,以模仿学习的方式更新状态编码器、潜在投影器和动作模型:
$ℒ_{IL}(φ) = E_{(o_i,l,a_i)}[ℓ(π_φ(c_t, o_i, l), a_i)]$
1.3 学习策略与推理
受相关研究启发,ThinkAct采用多阶段训练策略。在强化学习之前,两个模块独立初始化。MLLM $F_θ$ 使用监督数据进行冷启动,学习如何解释视觉轨迹并以正确的格式生成推理和答案。另一方面,动作模型 $π_φ$ 在 Open X-Embodiment (OXE) 数据集上进行预训练,为底层动作执行奠定基础。
在监督微调(SFT)冷启动之后,MLLM $F_θ$ 使用动作对齐的奖励进行调优,以指导生成有效的潜在规划。在推理增强的动作适应阶段,冻结 $F_θ$,同时根据潜在视觉规划 $c_t$ 的条件,在目标环境数据上更新动作模型 $π_φ$ 及其状态编码器和潜在投影器。
在推理时,给定视觉观察和指令,ThinkAct生成视觉规划潜变量 $c_t = F_θ(o_t, l)$,该潜变量作为条件输入动作模块 $π_φ$,从而预测出一系列适合当前环境的可执行动作。
实验
2.1 机器人操作
为评估ThinkAct在机器人操作任务上的有效性,研究人员在SimplerEnv和LIBERO基准上进行了测试。SimplerEnv包含Google-VM(视觉匹配)、Google-VA和Bridge-VM三种任务,引入了颜色、材质、光照和相机位姿的变化以测试模型鲁棒性。对于LIBERO基准,评估其Spatial、Object、Goal和Long子任务,以测试模型在空间布局、物体变化、目标多样性和长程规划方面的泛化能力。
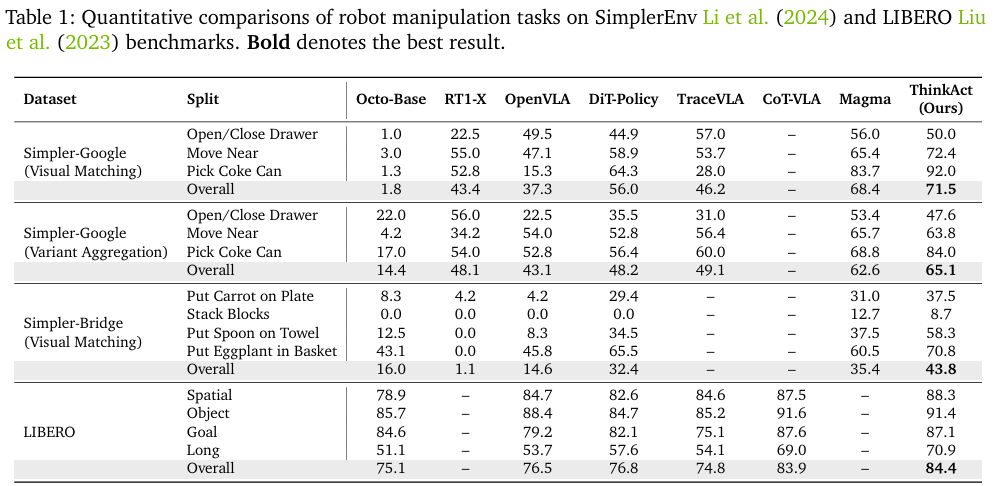
实验结果如上表所示。在SimplerEnv上,ThinkAct在Google-VM、Google-VA和Bridge-VM上的成功率分别比基线动作模型DiT-Policy高出15.5%、16.9%和11.4%。ThinkAct在三种任务上的总成功率分别为71.5%、65.1%和43.8%,在所有对比方法中位列第一。
在LIBERO基准上,ThinkAct取得了84.4% 的最佳总成功率,优于DiT-Policy和近期性能优秀的CoT-VLA,证明了该模型在多样化机器人操作任务中的强大有效性。
2.2 具身推理
在 EgoPlan-Bench2、RoboVQA、OpenEQA 三个基准上,研究人员评估了ThinkAct在具身场景中的推理能力。
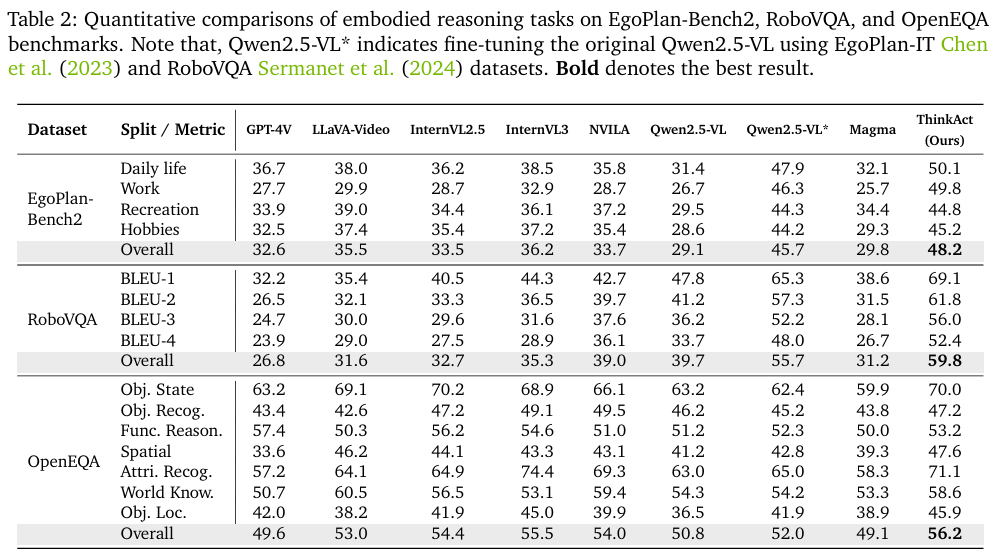
- EgoPlan-Bench2 评估模型在家庭场景中的多步规划能力,ThinkAct总成功率为48.2%,比第二名Qwen2.5-VL*的45.7%高出2.5%。
- RoboVQA 侧重于机器人操作中的长程任务推理,ThinkAct总成功率为59.8%,比第二名Qwen2.5-VL*的55.7%高出4.1%。
- OpenEQA 侧重于评估模型在多样化环境中的零样本具身理解能力,ThinkAct实现了更好的泛化和场景理解,在该基准上也取得了最佳性能,总成功率为56.2%。
2.3 定性结果
下图展示了Simpler-Bridge和LIBERO-Long任务中的两个操作示例的推理过程和执行轨迹可视化。

在LIBERO-Long任务 “拿起书并将其放入后面的隔间” 中,ThinkAct将指令分解为子任务:(1)拿起书;(2)从左向右移动;(3)将书放入隔间。这个任务清晰地体现了ThinkAct的长程规划能力,可视化轨迹也证实了夹爪在执行过程中紧密遵循了推理引导的规划。
为了证明强化学习对推理过程的直接影响,下图对比了在具身推理任务上进行强化学习微调前后的ThinkAct表现。

2.4 ThinkAct分析
推理增强少样本适应
根据前面的观察,ThinkAct能够描述环境并将任务指令分解为可执行的子目标。为了验证这种推理能力是否提升了动作模型的适应性,研究团队在LIBERO基准上进行了少样本适应实验。具体来说,使用LIBERO-Spatial和LIBERO-Object评估模型对未知环境的适应能力,使用LIBERO-Goal测试模型对新技能的适应能力。在每个任务上仅使用10个演示样本对动作模型进行微调,并在100次试验中评估性能。
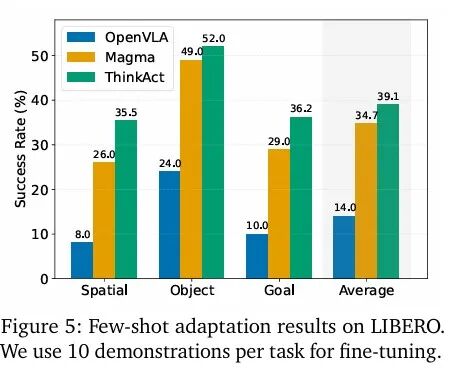
如上图所示,ThinkAct始终优于对比方法,在所有任务中取得了最高的成功率。与Magma相比,在LIBERO-Goal上高出 7.3%,在LIBERO-Spatial上高出9.5%,这强有力地证明了推理能力对于在新技能和新环境中进行少样本泛化是有效的。
推理引发的自主纠正
故障检测和自主纠正是机器人操作中的关键挑战。为了评估ThinkAct是否能够对错误执行进行反思并纠正,研究人员让推理MLLM在执行过程中观察更多上下文信息,将其输入从单张图像扩展为短视频片段。这种时序上下文使ThinkAct能够检测故障、重新思考并重新规划。
在一个 “要求机器人将盒子放入篮子” 的任务演示中,夹爪在中途意外掉落了盒子。模型识别出了该故障,并发出“让我们重新考虑如何完成这项任务”的思考,随后生成了一个修正规划,引导夹爪回到掉落位置重新抓取盒子。最终,机器人成功完成了任务。这证明了ThinkAct能够通过推理来反思错误行为并进行自我纠正。
总结
NVIDIA与台湾大学提出的基于MLLM的双系统VLA模型ThinkAct,通过结合动作对齐的强化学习和推理增强的动作适应,使具身智能体能够“先思考再行动”,并在动态环境中鲁棒地执行动作。在大量的具身推理和机器人操作任务上的实验,全面展示了ThinkAct强大的长程规划、少样本适应、故障检测和自主纠正能力。
这项研究为通往更具思考性和适应性的具身智能,提供了一条富有前景的技术路径。对深度学习和强化学习在机器人领域应用感兴趣的开发者,可以关注云栈社区的人工智能板块,获取更多前沿技术讨论与资源。
 发表于 2026-3-21 05:36:28
|
查看: 155|
回复: 0
发表于 2026-3-21 05:36:28
|
查看: 155|
回复: 0
