
4月27日,小米正式发布 Xiaomi-Robotics-0 真机后训练(Post-training)全流程并开源。
Xiaomi-Robotics-0 是小米于2026年2月发布的 VLA模型,发布首月便登上了 HuggingFace 全球 VLA 模型下载榜第六名。该模型包含 4.7B 参数,旨在解决机器人在实时作业场景下推理延迟、动作连贯性不足、能力遗忘等问题。
小米表示,真机后训练是打通 VLA 模型(视觉-语言-动作模型)迈向落地“最后一公里”的关键。 团队全面公布整套训练流程,旨在降低机器人智能化技术门槛,加速具身智能产业落地。
在本次真机后训练中,小米团队引入的自适应加权机制 (Adaptive Loss Re-weighting)、Λ 型掩码 (Λ-Shape Attention Mask) 和前缀动作随机遮蔽 (Random Masking) 三项技术,有效破解了业内普遍存在的“偷懒效应”问题。Xiaomi-Robotics-0 仅需 20 小时任务数据即可让机器人连续完成多组耳机收纳任务。
以下是 Xiaomi-Robotics-0 的相关技术链接:
基于预训练基座,仅需20小时任务数据就能学会精细操作
在收纳耳机任务中,Xiaomi-Robotics-0 面临着两项核心挑战:
1、耳机与收纳槽位尺寸匹配精密、公差小,模型必须达到亚毫米级的空间感知精度,才能把耳机精准地放回耳机槽中。
2、耳机与盒体表面光滑,粗糙度最低至 Ra0.03μm(堪比高品质单反镜头镜片),机器人在收纳耳机时极易出现位置偏移,模型必须能快速修正动作偏差,避免装配失败。
针对以上挑战,该团队依托包含约 2 亿步机器人运动轨迹数据和超 8000 万条视觉及语言样本的预训练基座,仅通过 20 小时任务数据 完成真机后训练,便能让 Xiaomi-Robotics-0 掌握收纳耳机的精细操作,并连续完成多组耳机收纳任务。

三项技术攻克“偷懒效应”,打造机器人的通用能力
小米表示,为了实现机器人动作的无缝衔接,该团队在部署阶段采用了异步推理(Asynchronous Execution)方案,即让机器人在执行当前动作时,同步推理下一步动作。
同时,为了确保模型前后两次推理生成的动作轨迹不突然发生变化,该团队在训练中引入了动作前缀(Action Prefixing),它能够让机器人基于已有动作轨迹生成全新动作,实现多类动作之间的无缝衔接、丝滑切换。
不过,在引入动作前缀之后,一个业内通病——“偷懒效应” 也随之而来。偷懒效应指的是模型容易过度依赖动作惯性而选择性地忽视实时视觉反馈。
为了解决这个问题,小米团队引入了以下三项技术,以此来平衡机器人的动作连贯性与响应灵敏度:
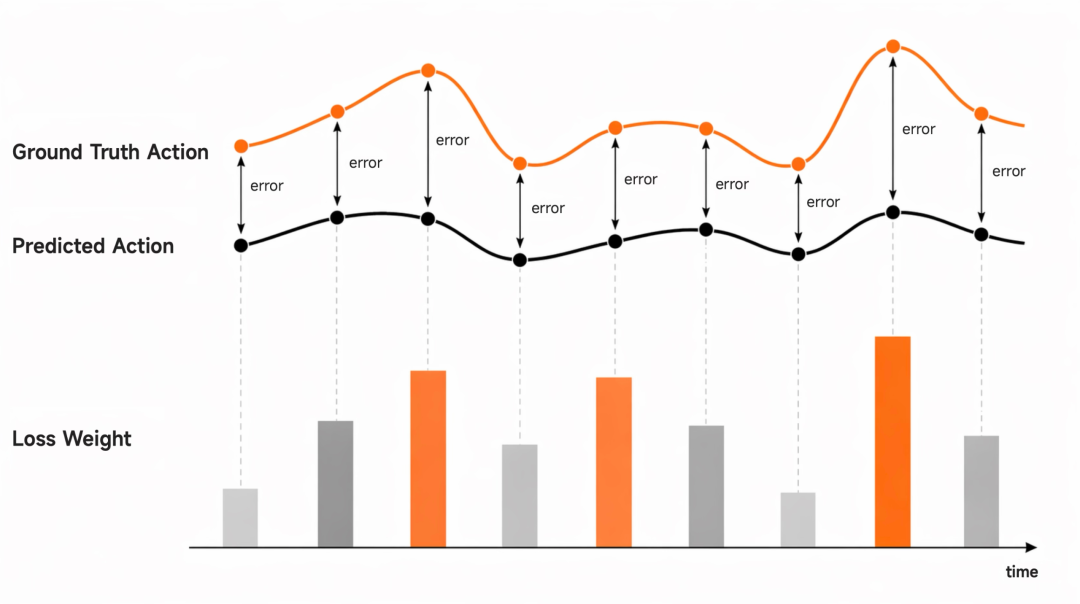
- 自适应加权机制 (Adaptive Loss Re-weighting):
根据模型预测值与真实轨迹的偏差,动态调整 Loss 权重(误差的惩罚力度),引导模型针对性地修正关键误差、补齐能力短板。
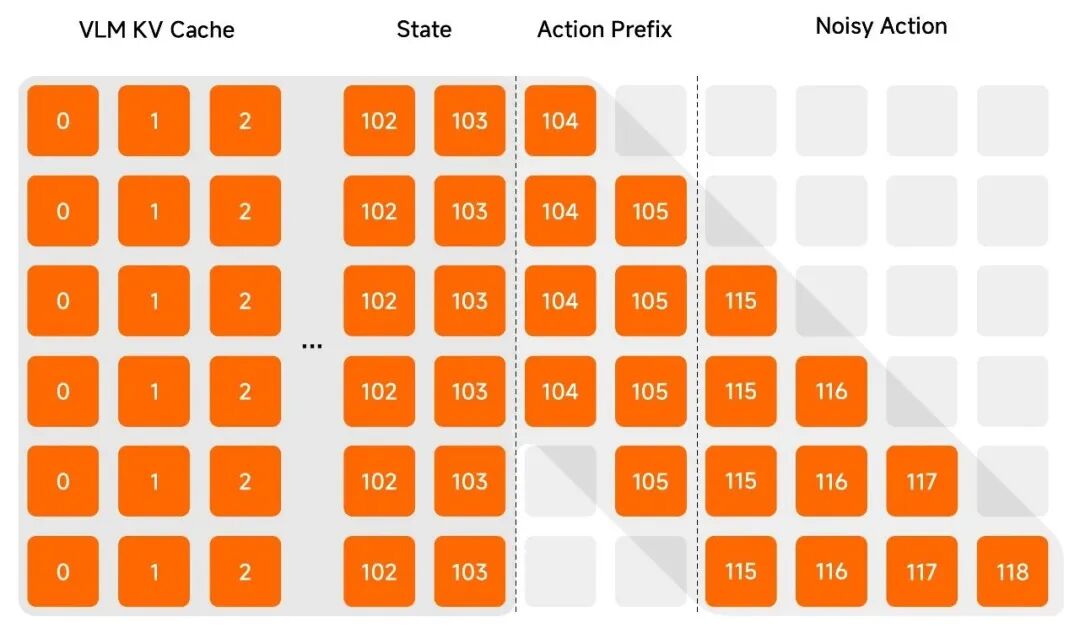
- Λ 型掩码 (Λ-Shape Attention Mask):
通过特殊的注意力机制,确保模型在参考前段动作末尾的同时,保持对当前视觉信号的高度专注,防止陷入单纯的“路径依赖”。
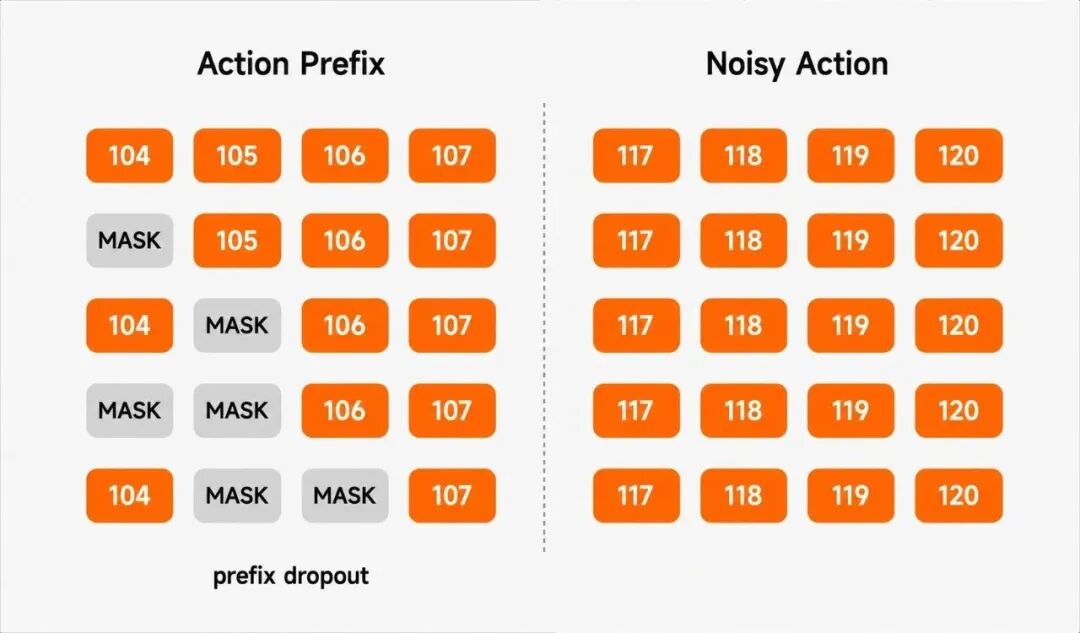
- 前缀动作随机遮蔽 (Random Masking):
在训练中对既有的动作前缀进行随机 Dropout(即随机、不定时地让机器人运动控制网络中的部分神经元失效,不参与计算和更新),倒逼模型深入挖掘摄像头画面与传感器信号,学会通用能力,而非盲目跟从动作惯性。
结语:降低训练成本,为解决“偷懒效应”提供了新的技术方案
小米发布 Xiaomi-Robotics-0 真机后训练全流程并开源,不仅有助于开发者们利用 Xiaomi-Robotics-0 在各式各样的场景中,通过极低的真机后训练成本,训练出属于自己的“专属机器人”,还为业内解决机器人的“偷懒效应”提供了新的技术方案。
小米透露,其将在多样化的硬件本体上持续开展跨本体通用能力的部署、测试与验证,并不断迭代模型,全面强化具身智能的泛化能力与落地效果。
更多具身智能与开源机器人的前沿技术解析,欢迎访问 云栈社区。 |  发表于 2026-4-29 01:25:43
|
查看: 92|
回复: 0
发表于 2026-4-29 01:25:43
|
查看: 92|
回复: 0
