想发大模型论文,却还在“模型规模”上打转?那你跟顶会大概率无缘了。研究风向已经悄然转变,“能力深化与场景适配”才是当下的王道。
仔细观察近两年的顶会顶刊,你会发现审稿人的关注点已经高度聚焦于:大模型的技术架构创新、能力边界拓展、多模态深度融合、推理效率优化以及系统的安全可控性。因此,对于希望深耕此领域的研究者和开发者而言,紧密跟踪前沿进展至关重要。
为了助力大家的研究,本文梳理了当前大模型领域最热门的10大方向,并汇总了相关的120篇高质量论文,其中大部分都附有原文链接和开源代码。这些方向涵盖:原生统一全模态模型、世界模型、VLA (Vision-Language-Action) 模型、Agent 系统、强化学习、隐式/显式推理、高效推理、安全性与可控性等前沿课题。
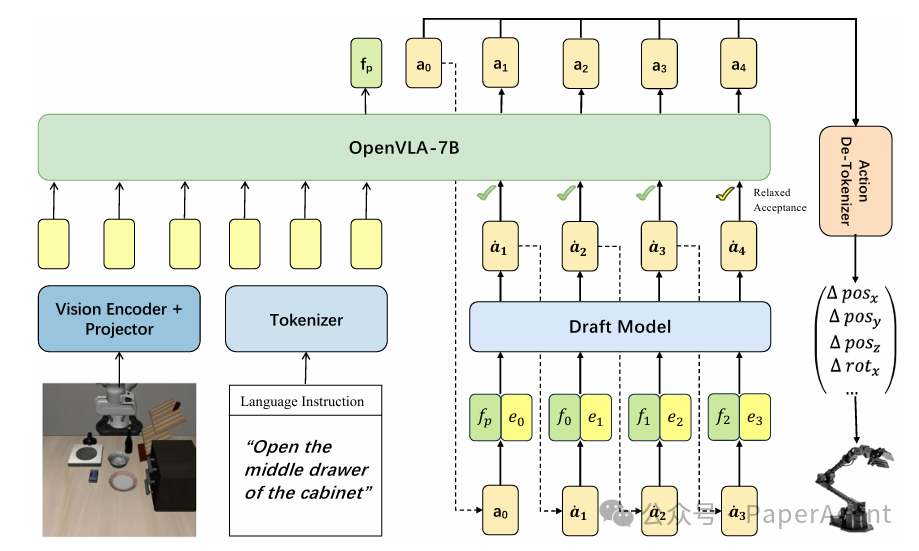
VLA模型:让AI看懂世界并执行动作
Spec-VLA: Speculative Decoding for Vision-Language-Action Models with Relaxed Acceptance
核心内容:
视觉-语言-动作模型(VLA)因其庞大的参数量和自回归解码特性,常面临高计算成本的挑战。这项研究首次将投机解码(Speculative Decoding, SD)框架适配并改进,提出了 Spec-VLA,旨在解决SD框架直接应用于VLA动作预测任务时加速效果不明显的痛点。研究者基于VLA模型动作令牌(action tokens)的相对距离,设计了一种松弛接受机制(Relaxed Acceptance),有效提升了令牌接受长度。
实验结果表明,该框架相比 Open VLA 基线模型,将接受长度提升了 44%,实现了 1.42 倍的推理加速,且完全没有损失任务成功率。这验证了投机执行在VLA动作预测场景的巨大应用潜力。相关代码已遵循 Apache 协议开源。
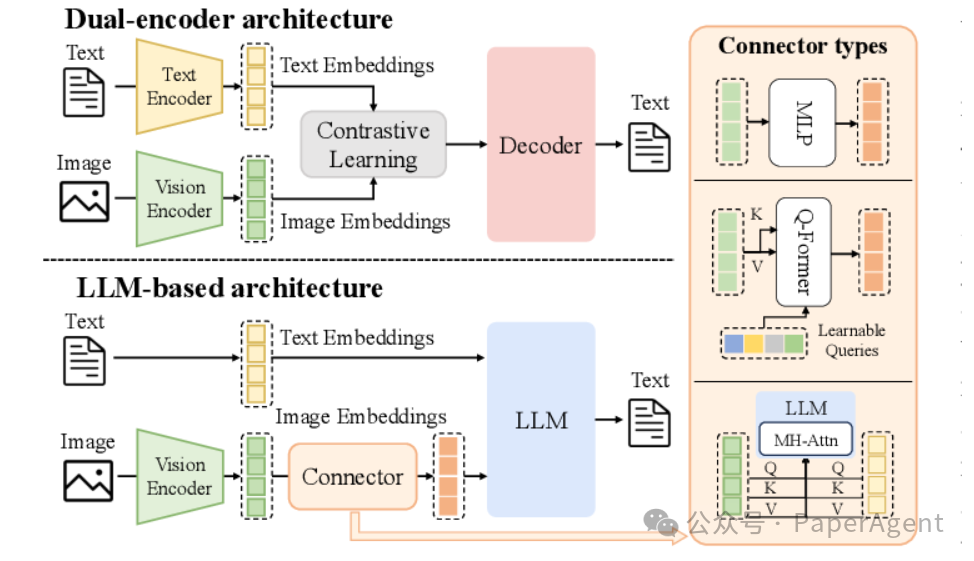
原生统一全模态模型:轻量化与多能力集成
Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
核心内容:
这篇论文提出了一个名为 Mobile-O 的紧凑型视觉-语言-扩散模型,旨在为移动设备提供统一的多模态理解与生成能力。其核心创新点包括:
- Mobile Conditioning Projector (MCP) 模块:通过深度可分离卷积和分层对齐技术,实现视觉与语言特征的高效融合。
- 创新的四元组统一后训练方案:(生成提示, 图像, 问题, 答案)。该方案仅需少量训练样本,即可同步提升模型的视觉理解与图像生成性能。
Mobile-O 仅包含 1.6B 参数,却在多项基准测试中表现出色:在 GenEval 基准上达到 74% 的成绩,超越 Show-O 和 JanusFlow 分别达 5% 和 11%,且运行速度快了 6-11 倍;在 7 个视觉理解基准上,平均性能领先 15.3% 和 5.1%。在 iPhone 17 Pro 上,它能实现约 3 秒生成一张 512×512 图像,内存占用低于 2GB,为边缘设备的实时多模态应用铺平了道路。模型、代码和数据集均已开源,为社区研究提供了宝贵资源,这正是 开源实战 所鼓励的实践精神。
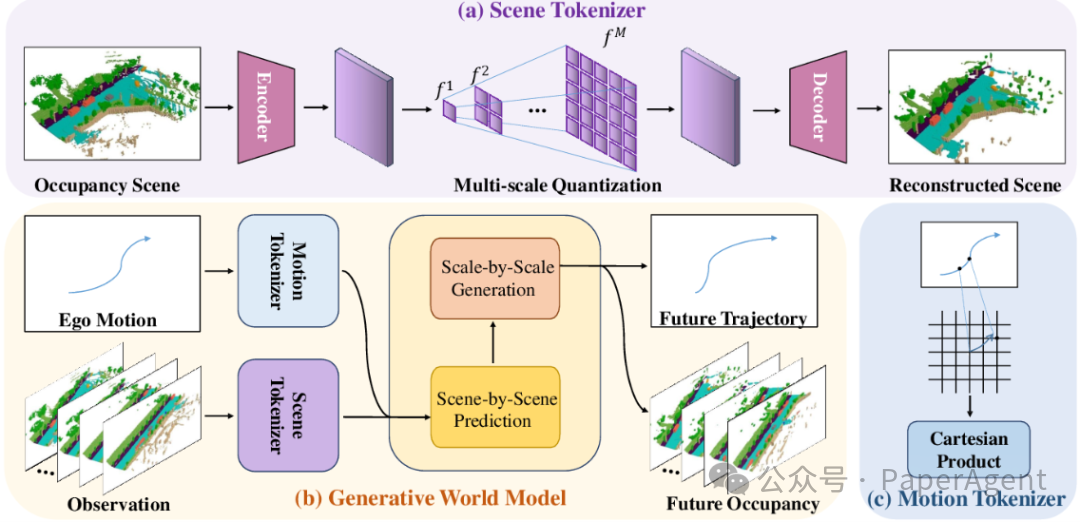
世界模型:为自动驾驶构建可预测的虚拟环境
OccTENS: 3D Occupancy World Model via Temporal Next-Scale Prediction
核心内容:
这篇论文为自动驾驶领域提出了一个 3D 占用世界模型 OccTENS。它旨在解决现有自回归占用模型存在的推理效率低、长时序生成质量退化以及缺乏位姿可控性等问题。
研究者将占用世界模型重构为 “时间下一尺度预测”(TENS) 任务,把复杂的时序序列建模拆解为“空间逐层生成”和“时间逐帧预测”两个相对简单的子问题。为此设计的 TensFormer 架构,能够灵活高效地建模占用序列的时间因果性和空间关联性。同时,论文提出的“整体位姿聚合策略”将车辆自运动与占用信息统一进行序列建模,从而实现了位姿可控的占用生成和自动驾驶运动规划。
模型主要由多尺度场景分词器、运动分词器和生成式世界模型构成。在 nuScenes 数据集上的实验表明,OccTENS 在 4D 占用预测任务中大幅超越了 OccWorld、OccLLaMA 等先进方法,为实现高性能、可控制、高效率的自动驾驶感知与决策系统提供了新的方案。深入理解其模型架构和训练方法,离不开对 技术文档 的仔细研读。
隐式/潜空间推理:探究大模型内部的思考过程
DYNAMICS WITHIN LATENT CHAIN-OF-THOUGHT: AN EMPIRICAL STUDY OF CAUSAL STRUCTURE
核心内容:
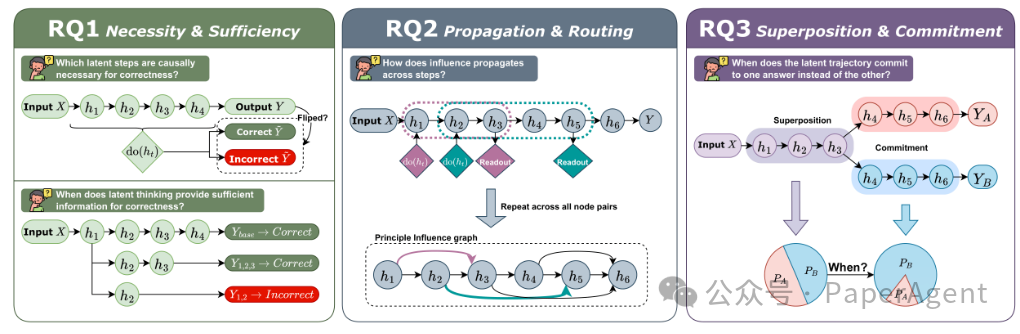
潜在思维链(Latent CoT)的中间计算过程往往难以评估,传统方法多依赖关联性探针。该论文提出将潜在CoT视为表征空间中一个可被操控的因果过程,通过将其建模为结构因果模型(SCM)中的变量,并借助逐步干预来分析其影响,以此探究三个核心问题:
- 必要性与充分性:哪些潜在步骤对最终答案的正确性具有因果必要性?答案在何时可以被早期判定?
- 传播与路由:影响如何在步骤间传播?其内部因果结构与显式思维链有何不同?
- 叠加与承诺:中间表征是否会同时保留多个竞争答案的“叠加态”?输出层与表征层的“决策承诺”时机有何差异?
研究在数学和通用推理任务上,对 Coconut 和 CODI 两种代表性范式进行了实验。研究发现,潜在步骤的“计算预算”更偏向于具有非局部路由特性的阶段化功能,而非简单的同质化网络加深。此外,早期输出层的倾向性(偏倚)与后期表征层的最终承诺之间存在持续的差距。这项工作为理解 Transformer 等架构内部更复杂的推理机制提供了全新的、因果化的分析视角。
总结与展望
以上仅是10大热门方向中的几个缩影。从追求“更大”到追求“更精、更专、更高效”,这120篇论文清晰地勾勒出大模型研究的演进路径:多模态融合正从拼接走向原生统一,AI智能体(Agent)系统从理论走向复杂任务实战,模型推理从黑箱走向可解释、可干预,而一切前沿探索最终都要面对落地部署的效率与安全挑战。
这份论文合集就像一张前沿技术地图,希望能帮助大家快速定位研究热点,启发创新思路。科研之路,始于高质量的文献阅读与复现实践。如果想深入交流这些方向或分享你的见解,欢迎来 云栈社区 的相关板块参与讨论。
 发表于 2026-3-26 19:53:38
|
查看: 180|
回复: 0
发表于 2026-3-26 19:53:38
|
查看: 180|
回复: 0
