Cloudflare的联合创始人兼CEO Matthew Prince在社交媒体上对谷歌的新研究发表了看法,称其为“谷歌的DeepSeek时刻”。他认为,AI推理在速度、内存使用、功耗以及多租户利用率等方面,仍然存在巨大的优化空间。
谷歌研究团队发布的 TurboQuant 论文,介绍了一组先进且具有坚实理论基础的量化算法。这套算法能对大语言模型(LLM)和向量搜索引擎实现大规模压缩,有望将大语言模型的键值(KV)缓存内存减少至少6倍,并带来高达8倍的速度提升,且保证零精度损失,重新定义了AI效率的边界。

在AI模型中,向量是理解和处理信息的基本单元。简单属性可以用低维向量描述,而“高维”向量则用于捕获图像特征、词语含义等复杂信息。虽然高维向量功能强大,但其巨大的内存消耗也带来了瓶颈,尤其是在键值缓存(key-value cache)方面。键值缓存就像一个高速“数字备忘录”,用于存储常用信息以便计算机即时检索,而无需每次都遍历庞大的慢速数据库。
向量量化是一种经典的强大数据压缩技术,能够有效减小高维向量的尺寸。这项技术可以解决AI面临的两个关键问题:其一,通过实现更快的相似性查找来增强驱动大规模AI和搜索引擎的向量搜索能力;其二,通过减小键值对的尺寸来缓解KV缓存瓶颈,从而实现更快的相似性搜索并降低内存成本。
然而,传统的向量量化方法通常会引入自身的“内存开销”。因为大多数方法需要为每个数据块计算并存储(全精度)量化常数,这种开销可能会为每个数字额外增加1到2个比特,从而部分抵消了向量量化的初衷。
为了突破这一限制,谷歌的研究人员提出了TurboQuant。这是一种旨在最优解决向量量化中内存开销挑战的新型压缩算法。该算法巧妙地结合了量化型约翰逊-林登斯特劳斯变换(Quantized Johnson-Lindenstrauss, QJL)和PolarQuant两项核心技术来实现其效果。初步测试表明,这三种技术在减少键值缓存瓶颈的同时,都展现出不牺牲AI模型性能的巨大潜力。这对于所有依赖压缩的用例,特别是在搜索和Transformer架构主导的AI领域,可能产生深远影响。
TurboQuant的工作原理
TurboQuant是一种能够在保持准确性的前提下,实现模型尺寸大幅缩减的压缩方法,非常适用于支持KV缓存压缩和向量搜索。它的实现主要分为两个关键步骤:
高质量压缩(基于PolarQuant方法):TurboQuant首先对数据向量进行随机旋转。这个巧妙的步骤简化了数据的几何结构,使得可以对向量的每个部分独立应用高质量的标准量化器。量化器是一种将大量连续值(如精确小数)映射到较小离散符号集合的工具,音频压缩和JPEG图像压缩都是其常见应用。在这个阶段,TurboQuant使用大部分压缩能力来捕获原始向量的核心概念和主要强度。
消除隐藏误差:完成高质量压缩后,TurboQuant会利用少量的残余压缩能力(通常仅为1比特)将QJL算法应用于第一阶段留下的微小误差上。这个QJL阶段扮演了“数学误差检查器”的角色,能够有效消除偏差,从而产生出更准确的注意力分数。
为了深入理解TurboQuant如何实现如此高的效率,我们需要进一步了解其两大核心技术:QJL和PolarQuant。
QJL:零开销的1比特技巧
QJL使用一种称为约翰逊-林登斯特劳斯变换的数学技术,在保留数据点间基本距离和关系的同时,对复杂的高维数据进行降维。它将每个结果向量数值缩减为单个符号比特(+1或-1)。该算法本质上创建了一种需要零内存开销的高速速记。为了保持准确性,QJL采用了一种特殊的估计器,策略性地平衡高精度查询与低精度简化后的数据,使得模型能够精确计算用于决定输入中哪些部分重要的注意力分数。
PolarQuant:压缩的“新角度”
PolarQuant采用了完全不同的思路来解决内存开销问题。它不再使用标准的笛卡尔坐标系来查看内存向量,而是将向量转换为极坐标。这类似于将导航指令“向东走3个街区,向北走4个街区”替换为“总共走5个街区,方向为37度角”。转换后,信息被分为两部分:半径(表示核心数据的强度)和角度(表示数据的方向或含义)。
由于角度的分布模式是已知且高度集中的,模型不再需要执行昂贵的数据归一化步骤。因为它将数据映射到了一个固定的、可预测的“圆形”网格上,而非边界不断变化的“方形”网格。这一特性使得PolarQuant能够消除传统量化方法必须承担的内存开销。
PolarQuant充当了高效的压缩桥梁,将笛卡尔坐标输入转换为紧凑的极坐标“速记”以进行存储和处理。其机制首先对d维向量中的坐标对进行分组并映射到极坐标系,然后递归地对成对收集的半径进行极坐标变换,直到数据被提炼成单个最终半径和一组描述性角度。
实验与结果
研究团队在标准的长上下文基准测试集上对所有三种算法进行了严格评估。实验数据表明,TurboQuant在点积失真和召回率方面实现了接近最优的评分性能,同时最小化了KV内存占用。下图展示了TurboQuant、PolarQuant和基线方法KIVI在多样化任务中的聚合性能分数对比。
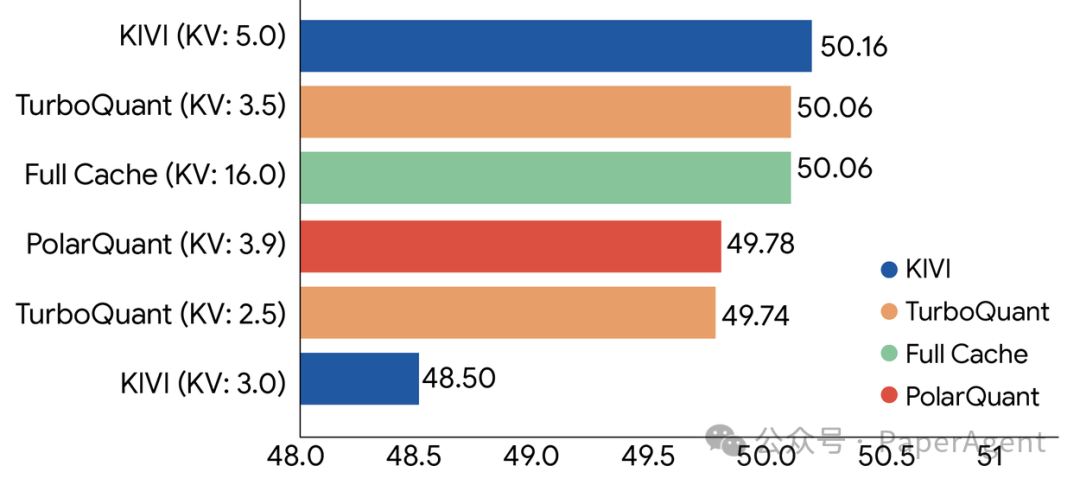
TurboQuant在Llama-3.1-8B-Instruct模型上相对于各种压缩方法(括号内标注比特宽度)展示了稳健的KV缓存压缩性能。
在长上下文“大海捞针”任务中的结果表明,TurboQuant在所有基准测试中均实现了完美的下游结果,同时将KV内存大小减少了至少6倍。PolarQuant在这项任务上也几乎达到了零损失。
TurboQuant证明了它可以将KV缓存量化至仅3比特,无需任何训练或微调,且不会对模型准确性造成任何损害,同时实现了比原始LLM更快的运行时速度。它的实现极其高效,运行时开销可忽略不计。下图说明了使用TurboQuant计算注意力logits所能获得的加速效果。
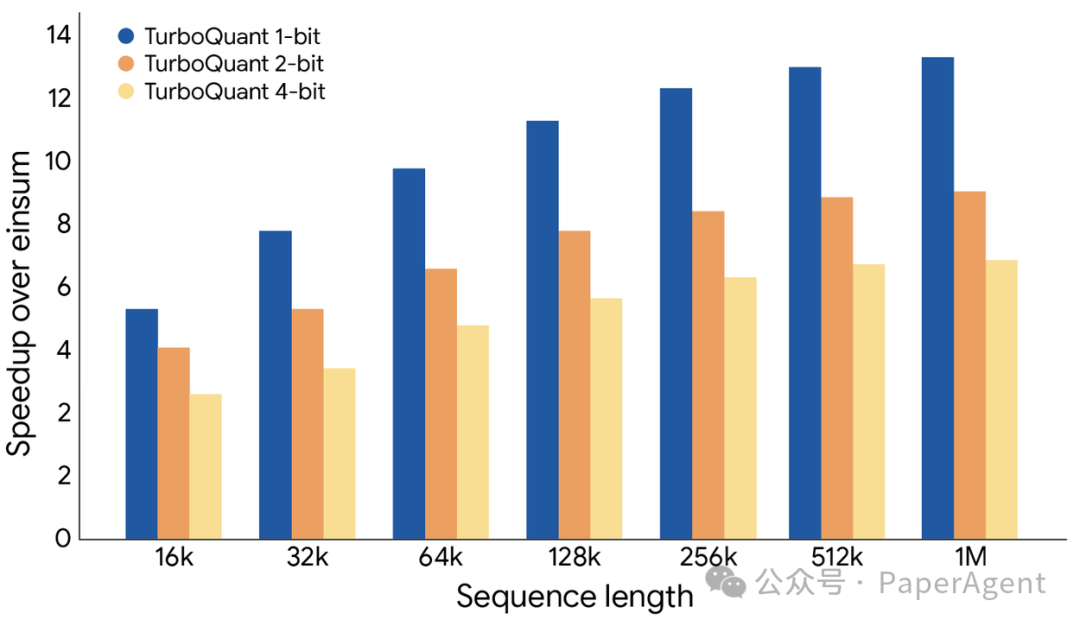
TurboQuant展示了在各种比特宽度下计算键值缓存内注意力logits的显著性能提升,相对于高度优化的JAX基线进行测量。
具体而言,在H100 AI推理优化GPU加速器上,4比特的TurboQuant相比32位未量化键值缓存实现了高达8倍的性能提升。这使其非常适合支持向量搜索等用例,能够显著加快索引构建过程。
研究团队还在高维向量搜索中评估了TurboQuant相对于最先进方法(如PQ和RabbitQ)的有效性。尽管这些基线方法使用了低效的大型码本和针对特定数据集的调整,但TurboQuant始终实现了优于基线方法的召回率。
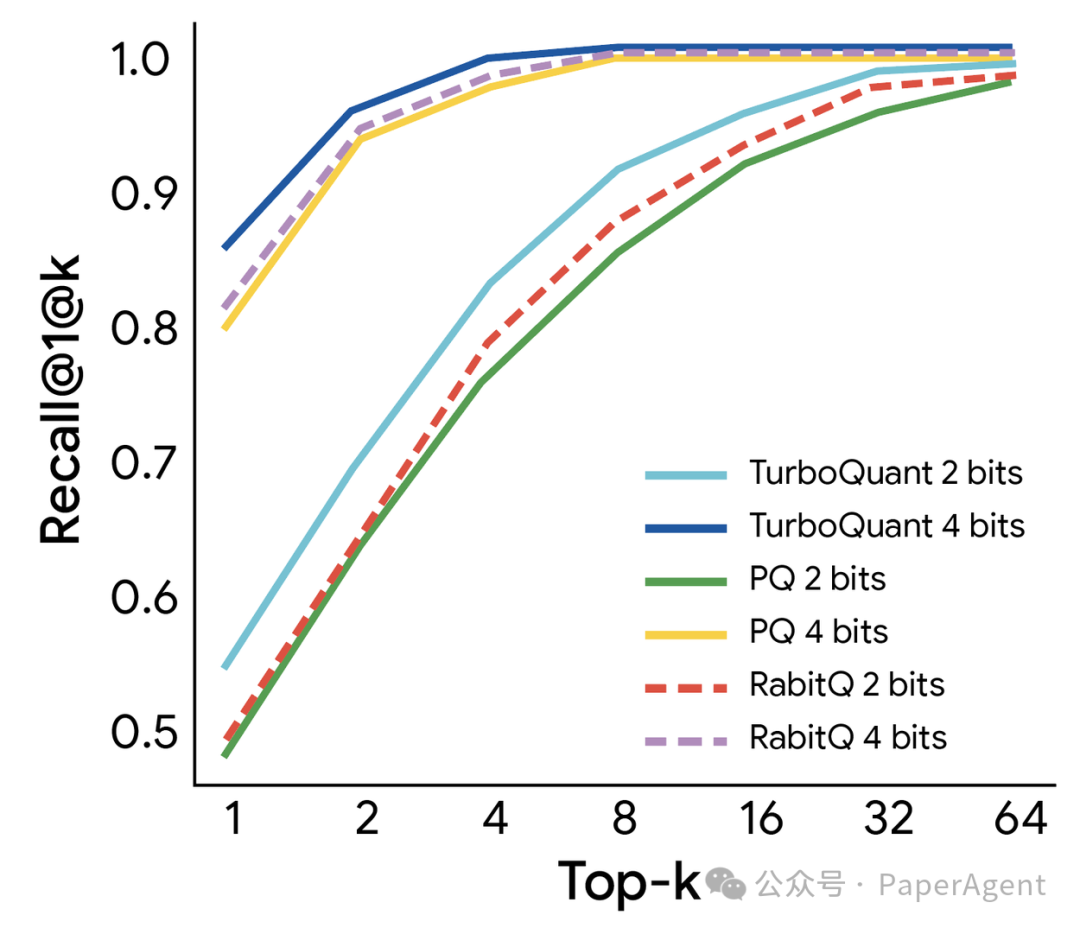
TurboQuant展示了稳健的检索性能,在GloVe数据集(d=200)上相对于各种最先进的量化基线实现了最优的1@k召回率。
这些结果证实了TurboQuant在高维搜索任务中的稳健性和效率。它展示了高维搜索的变革性潜力,通过以数据无关的方式提供接近最优的失真率,为可实现的速度设定了新基准。这使得最近邻引擎能够以3比特系统的效率运行,同时保持重量级模型的精度。
更多技术细节和完整的理论分析,请参见发布于arXiv的论文:
https://arxiv.org/abs/2504.19874
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
对于关注前沿AI推理优化技术的开发者而言,TurboQuant无疑是一个值得深入研究的突破。它不仅提供了性能提升的实用方案,其背后的量化理论也为未来的算法设计指明了方向。欢迎大家来到云栈社区的对应板块进行更深入的交流和讨论。
 发表于 2026-3-26 19:57:21
|
查看: 158|
回复: 0
发表于 2026-3-26 19:57:21
|
查看: 158|
回复: 0
