2025年12月,清华大学TSAIL实验室与生数科技联合开源了视频生成加速框架TurboDiffusion。该框架宣称能在单张消费级显卡上,以1.8秒的速度生成5秒视频,将AI视频生成效率从分钟级提升至秒级。这一突破性进展的核心在于其创新的稀疏注意力与量化技术,但“无损加速”的真实性与生态兼容性,仍是决定其能否真正开启AI视频实用化时代的关键疑问。
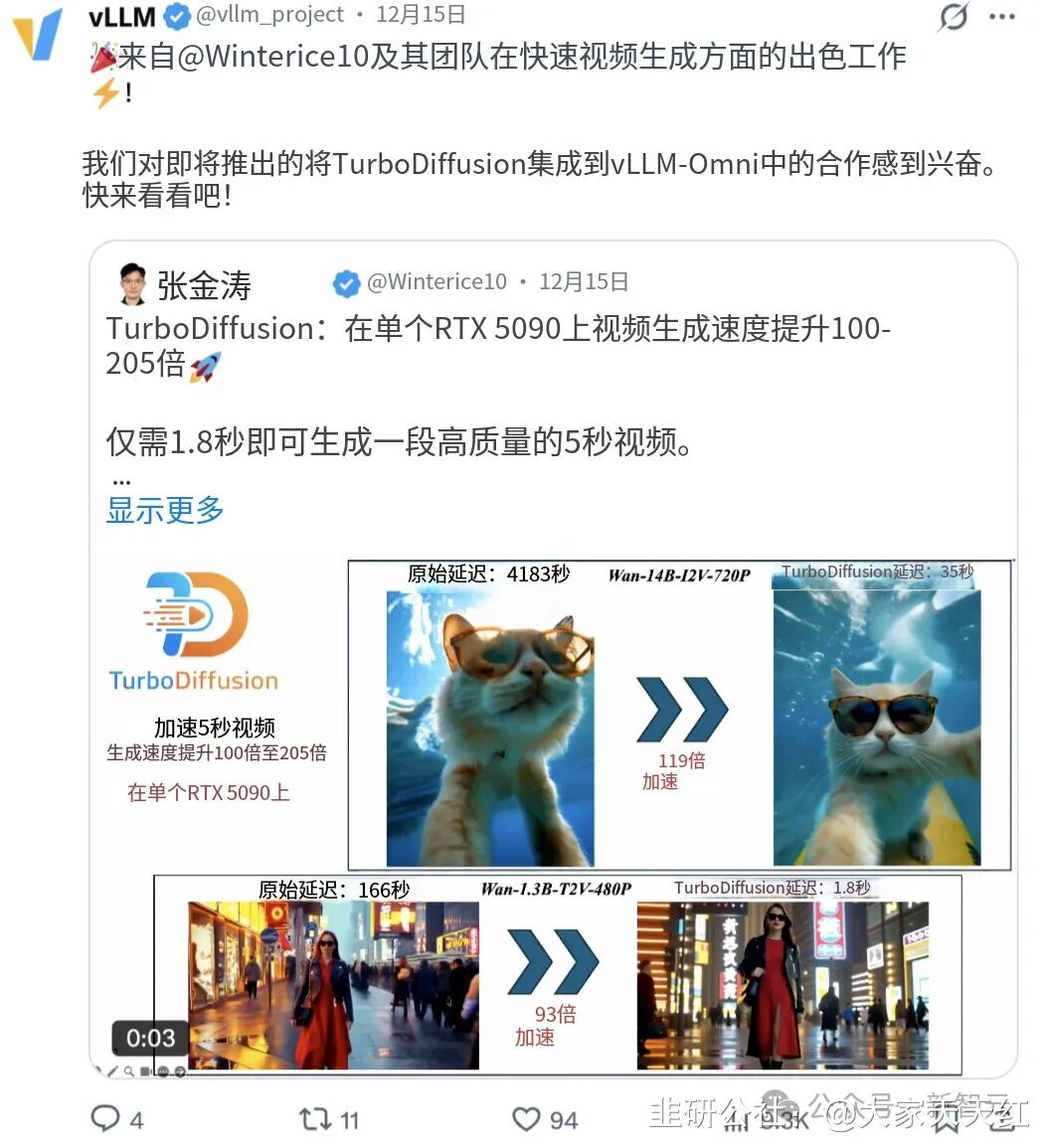
图:社交平台用户关于TurboDiffusion速度提升的讨论
生成一段5秒的AI视频,需要多久?就在几天前,答案还是动辄数分钟甚至一小时。但就在2025年12月23日,清华大学TSAIL实验室与生数科技联合开源的 TurboDiffusion,将这个答案改写为 1.8秒。
这不仅仅是一次优化,更像是一场效率的“核爆”。它意味着,你刚敲完一行文字描述,一个高清视频可能就已经渲染完毕。AI视频生成,正从需要“等待渲染”的分钟级时代,正式跨入可以“实时响应”的秒级时代。
过去,高质量视频生成堪称算力的“奢侈品”。以资料中提到的14B参数模型生成5秒720P视频为例,标准流程需要 4549秒(超过1小时)。这不仅是时间的消耗,更是高昂硬件成本的门槛,将绝大多数个人创作者和中小企业拒之门外。
TurboDiffusion带来的改变是颠覆性的。根据其开源资料中的实测数据:
- 1.3B模型,5秒480P视频:从184秒缩短至 1.9秒,加速约97倍。
- 14B大模型,5秒720P视频:从超过1小时的4549秒,压缩到 38秒,加速近120倍。
- 在消费级旗舰显卡RTX 5090上,甚至实现了端到端 近200倍的加速比。
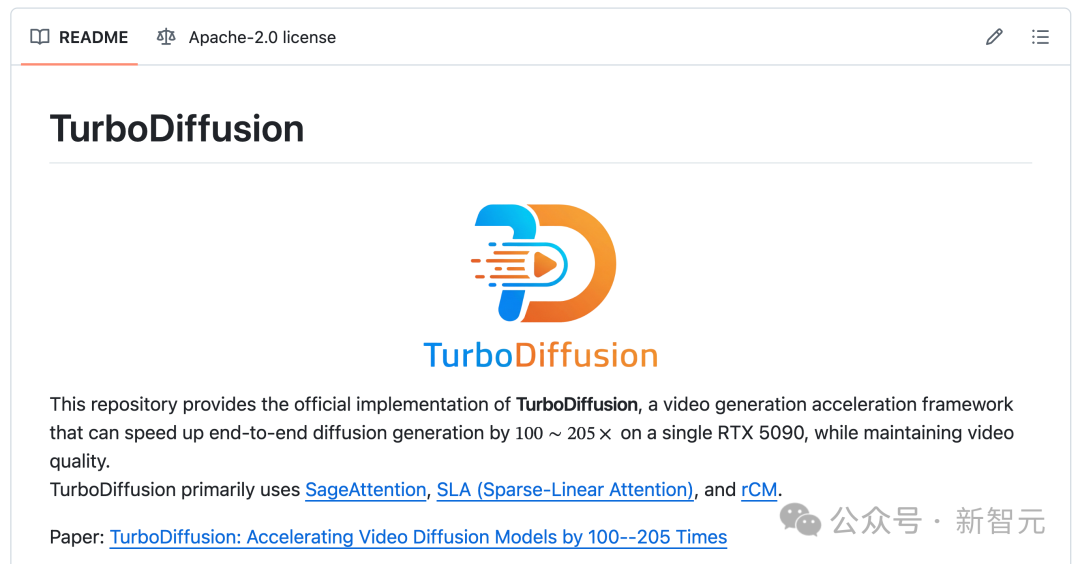
图:TurboDiffusion项目在GitHub上的README文件
这些数字背后,是一个根本性的转变:视频生成从一项需要“计划”和“等待”的批处理任务,变成了可以“交互”和“迭代”的实时创作过程。
短视频博主能快速测试不同风格,游戏开发者能实时生成场景素材——创作流程的“延迟”被极大压缩,灵感与成品之间的路径被瞬间打通。
然而,速度的提升往往伴随着质量的妥协。以往的模型加速技术,如降低分辨率、粗暴减少采样步数,常常导致视频模糊、逻辑混乱或细节丢失。“加速”与“画质”如同天平的两端,此消彼长。
TurboDiffusion之所以引发轰动,关键在于它宣称在实现百倍加速的同时,做到了 “几乎不影响生成质量” 。从公开的对比示例看,加速后的视频在画面连贯性、细节保留上,与原始慢速模型生成的成果在视觉上差异极小。
这打破了传统加速技术的核心瓶颈。 其秘诀在于,它没有采用“伤筋动骨”的阉割式方案,而是通过一套 算法与系统协同优化的组合拳,从计算本质上去除冗余:
- 让计算“更聪明”:而非单纯“更少”。它通过稀疏注意力等技术,让模型学会聚焦在关键信息上,避免在无关紧要的计算上浪费算力。
- 对数据“精打细算”:采用低比特量化,在几乎不损失信息的前提下,大幅减少数据搬运和计算的开销。
这种思路的转变,标志着AI工程化从“暴力堆算力”进入“精细化算力管理”的新阶段。TurboDiffusion证明,极致的速度不一定需要牺牲创造力,它可以通过极致的效率来实现。

图:TurboDiffusion开源项目中可用的模型及最佳分辨率
技术拆解:四大黑科技如何实现百倍加速
宣称的百倍加速并非单一魔法,而是 四重技术栈的系统性叠加。它们从计算、存储到生成逻辑,对传统视频扩散模型进行了一场彻底的“效率手术”,共同指向一个目标:用算法创新,而非单纯堆砌算力,来换取极致的生成速度。
SageAttention与稀疏计算:让模型“只看重点”
视频生成慢的根源在于Transformer的注意力机制。传统方法需要计算视频中所有像素点之间的关联,计算量随分辨率和帧数呈爆炸式增长。
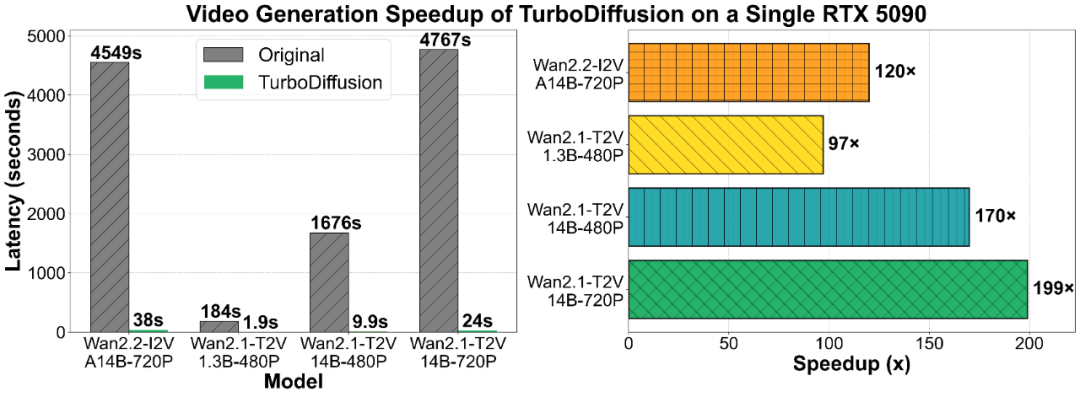
图:TurboDiffusion在不同模型上的延迟对比与加速倍数
TurboDiffusion的解法是 让模型学会“选择性计算”,其核心是两项正交叠加的技术:
- SageAttention(低比特量化注意力):这是清华大学TSAIL团队的核心突破。它将注意力计算中的浮点运算(如FP16)转换为更低比特的整数运算(如INT8/INT4),从而 充分压榨GPU中专门为低精度矩阵运算优化的Tensor Core性能。这项技术已集成至NVIDIA TensorRT,证明了其工业级可靠性。它解决的是“算得更快”的问题。
- Sparse-Linear Attention(稀疏线性注意力,SLA):这项技术则旨在“算得更少”。通过可训练的稀疏化方法,模型在推理时 自动忽略约90%的非关键注意力连接,只聚焦于约10%的核心关联。由于稀疏计算与低比特量化互不冲突,SLA可以构建在SageAttention之上,带来 叠加的17-20倍稀疏注意力加速。
本质洞察:这两项技术的结合,标志着大模型推理优化从“硬件驱动”转向 “算法与系统协同设计” 。未来的高效模型,必须像人脑一样具备“信息筛选”能力,而非对海量数据进行无差别的蛮力处理。
步数蒸馏与W8A8量化:在压缩与精度间找到平衡
如果说前两项技术优化了“怎么算”,后两项则直接对“算多少”和“算多胖”动刀。

图:介绍TurboDiffusion的学术论文标题页
- rCM步数蒸馏:传统扩散模型需要50-100步迭代去噪。TurboDiffusion采用 正则化一致性模型(rCM) 进行知识蒸馏,将复杂的多步生成过程“压缩”到一个仅需 3-4步 的轻量模型中。这相当于把蜿蜒的盘山公路,改建成了直达的隧道,是端到端时间缩短一个数量级的关键。
- W8A8 INT8量化:这项技术是对模型的“终极减肥”。它将模型权重和激活值从16位浮点数统一量化为 8位整数,使 模型体积和显存占用压缩近半,同时进一步利用GPU的INT8计算单元加速。
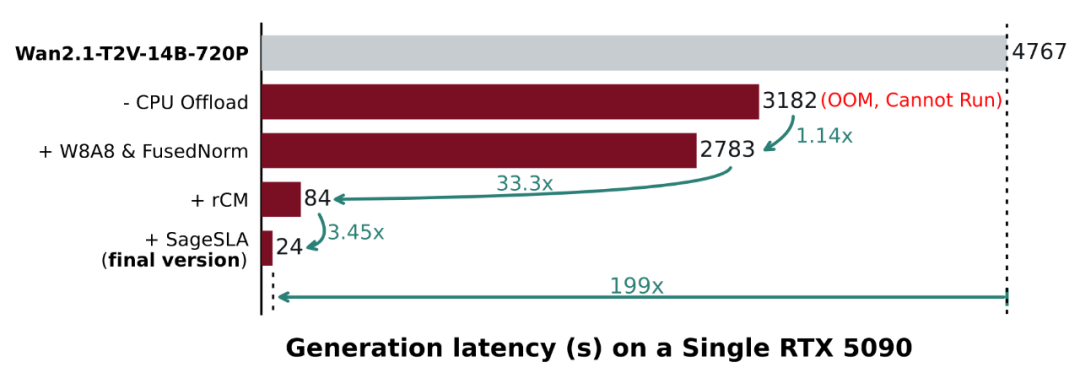
图:各项技术优化对最终生成延迟的贡献分解
然而,这里潜藏着“无损加速”的最大争议与挑战:
- “无损”的真实性存疑:量化与蒸馏本质是 有损压缩。尽管论文宣称“视觉质量相当”,但在追求影视级细节、复杂物理运动或长时序逻辑连贯性的场景下, 微小的质量损失可能被放大。“近乎无损”是一个需要严格定义和场景化验证的表述。
- 生态兼容性难题:这套“稀疏化+量化+蒸馏”的组合拳技术栈复杂,并非即插即用。如何适配市面上千差万别的视频生成模型(如Sora、Pika等变体)和硬件平台,是其从“实验室标杆”走向“大众工具”的最大障碍。
批判性视角:TurboDiffusion清晰地揭示了一个趋势——AI工程正步入 “精算时代” 。其核心逻辑是:用可控的、微小的质量妥协,换取数量级的效率提升,以打开实用化的大门。 这或许将导致追求极致质量的“学院派”与追求可用性的“工程派”产生技术路线的分野。秒级生成的狂欢之下,一场关于“何为可用质量”的重新定义,已然开始。
图:媒体对TurboDiffusion技术发布的报道
开源影响与审视:秒级时代是拐点还是泡沫?
当一项技术宣称能将AI视频生成从分钟级压缩至秒级,并选择开源,我们迎来的究竟是生产力革命的真正拐点,还是又一个被过度解读的技术泡沫?TurboDiffusion将这个问题抛给了整个行业。
开源是其最有力的“加速器”。这不仅是代码的公开,更是一次 生产力的民主化分发。它将原本属于顶尖实验室和科技巨头的“秒级生成”能力,下放给了全球开发者和中小团队,直接冲击了AI视频创作的成本与资源结构。
然而,拐点的标志从来不是性能的峰值,而是技术能否跨越从“实验室演示”到“稳定生产工具”之间的鸿沟。光环之下,关于“无损加速”的真实性质疑与生态兼容性的现实挑战,构成了审视其价值的两面。
降低应用门槛:从实验室走向个人与商业场景
TurboDiffusion最直接的冲击,是 打破了AI视频生成的硬件与成本壁垒。此前,生成高质量视频是“重资产”游戏,严重依赖昂贵的云端GPU集群。如今,一张消费级的RTX 5090显卡就能实现实用速度,游戏规则彻底改变。
- 对个人与中小团队:这意味着可以在本地进行快速迭代。构思一个短视频创意,几分钟内就能看到数十个不同版本的视觉预览,创作流程从“等待渲染”变为“实时交互”。这为独立开发者、内容创作者和中小工作室打开了低成本、高频次试错的大门。
- 对垂直行业:教育、电商、营销等行业的内容制作逻辑将被重塑。例如,教育机构可以快速生成教学动画,电商团队可以自动化生成海量商品展示视频。AI视频正从“炫技演示”转变为可规模化的生产力工具。
- 激发长尾创新:当技术变得触手可及,创新的主体将从大厂实验室扩散到无数应用场景。可以预见,基于TurboDiffusion的二次开发、定制化工具和垂直行业解决方案将大量涌现。
结论是清晰的:TurboDiffusion无疑是一个强大的技术拐点,但它并非“银弹”。 它开启了AI视频秒级生成的时代,大幅降低了应用门槛,但其真正的价值,将在开源社区解决上述质量疑虑、完成广泛的生态适配、并催生出真正改变工作流的“杀手级应用”之后,才能被完全确认。
你认为,TurboDiffusion要真正掀起浪潮,其面临的最大障碍是技术本身的“隐形损耗”,还是生态整合的工程难题?欢迎在云栈社区分享你的看法。
 发表于 2025-12-31 10:06:49
|
查看: 315|
回复: 0
发表于 2025-12-31 10:06:49
|
查看: 315|
回复: 0
