
在当前的 人工智能 浪潮中,扩散模型(Diffusion Models)已成为图像与视频生成领域的基石,其生成的高保真内容令人惊叹。然而,一个普遍的“痛点”在于:从海量数据中预训练出来的基础模型,往往难以直接满足下游任务对特定风格、质量或人类偏好的精细要求。如何对庞大的扩散模型进行高效、稳定的后训练(Fine-tuning),一直是业界面临的核心挑战。
近期,北京大学彭一杰教授团队在ICLR 2026上提出了一种全新的优化范式——递归似然比(Recursive Likelihood Ratio, RLR)优化器。这项研究为解决扩散模型后训练的内存与效率困境提供了一个兼具理论保证和实践价值的方案,并已被接收为Oral报告。

现有方法的两难困境
扩散模型通过一系列递归的去噪步骤生成数据,这个过程被称为扩散链。要对模型进行后训练,传统上需要计算整个长链(例如50步)的梯度。如果使用标准的反向传播(BP),内存消耗会随着链长线性增长,变得极其昂贵。以训练Stable Diffusion 1.4为例,仅50个时间步的全BP就可能需要约1TB的GPU内存,这在现实中几乎无法实现。
为了应对这一问题,现有方法主要走了两条路线,但都留下了新的难题:
- 截断反向传播(Truncated BP):为了节省内存,只对扩散链的最后若干步进行梯度计算。但这种方法会引入结构性偏差,导致梯度估计不准。在极端情况下,这种偏差会引发模型“崩溃”,生成内容退化为一团噪声。
- 基于强化学习(RL)的方法:这类方法(如DDPO)通过策略梯度进行优化,内存需求较低。但其梯度估计的方差极高,导致样本效率低下,训练收敛缓慢且不稳定。
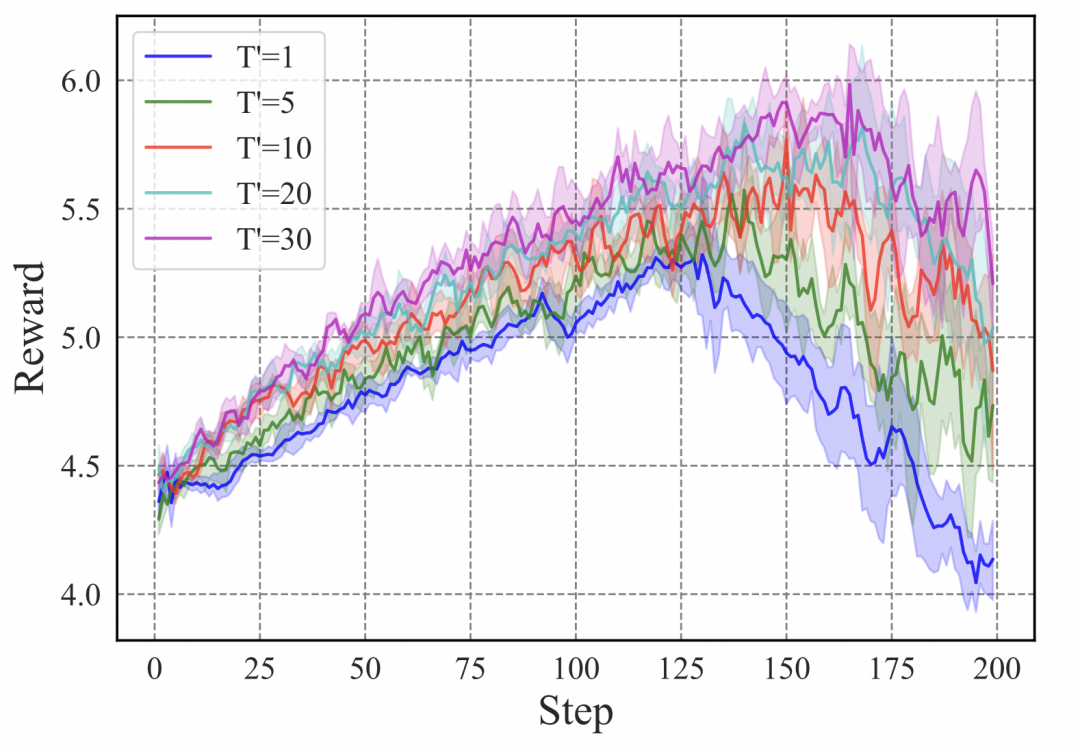
上图清晰地展示了截断BP的缺陷:随着训练进行,奖励曲线在后期会快速下降,意味着模型性能发生崩溃。
RLR优化器:半阶梯度估计的新范式
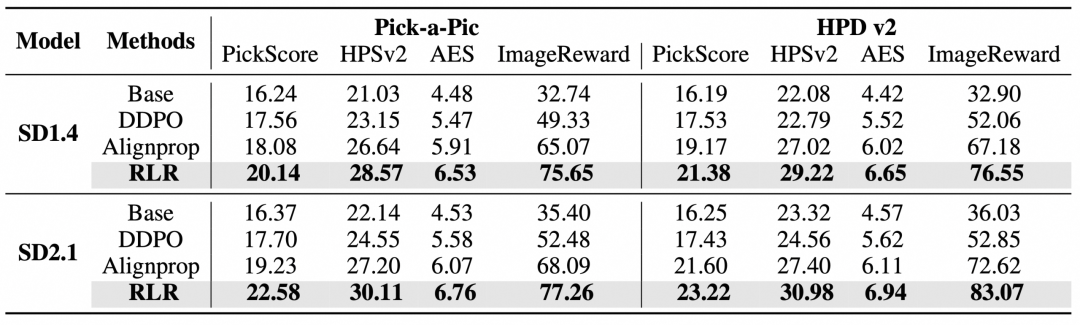
为了从根本上突破内存与性能难以兼顾的困境,研究团队提出了递归似然比(RLR)优化器。其核心思想是设计一种“半阶”(Half-Order)梯度估计器,巧妙地利用扩散模型固有的随机噪声特性,重构计算图,从而实现无偏、低方差的梯度估计。
RLR优化器将整个扩散链的梯度计算分解为三个模块的协同:
- 一阶估计(First-Order):在生成过程的第一个时间步,直接对奖励模型进行精确的反向传播。这一步充分利用了模型的结构信息,确保了关键初始步骤的梯度精度。
- 半阶估计(Half-Order):这是RLR的创新核心。算法会随机在扩散链上选取一个长度为
h 的局部子链,对这个子链进行精确的梯度计算。这个子链像一个“滑动窗口”,能够精准捕捉到多尺度的视觉信息,同时有效控制方差。
- 零阶估计(Zero-Order):对于链上剩余的时间步,采用高效的参数扰动策略来估计梯度。这种方法无需缓存中间变量,极大地节省了内存,并保证了整体梯度估计的无偏性。
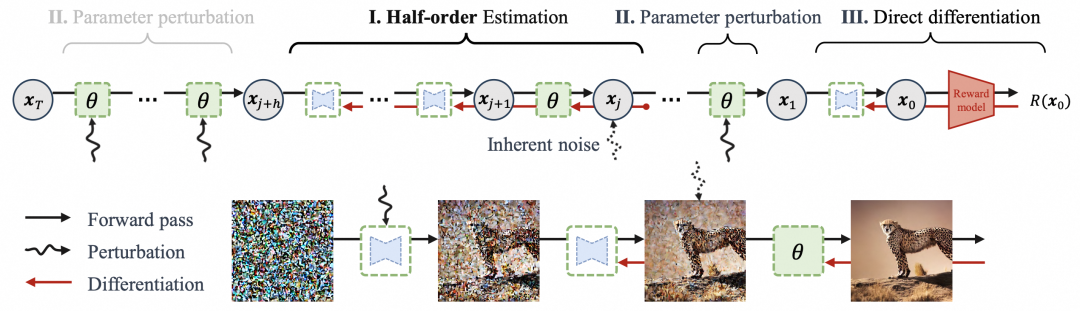
内存与方差的定量权衡:如何选择最优的 h?
半阶估计中的局部子链长度 h,是RLR优化器实现性能调控的关键“旋钮”。h 越大,梯度估计越精确(方差越低),但内存开销也越大;h 越小,内存越省,但估计方差会升高。
研究团队没有将 h 的选取留给经验,而是将其形式化为一个带内存预算约束的方差最小化优化问题,从理论上为 h 的选择提供了严格的数学依据。
$$
\min_{h \in \mathbb{N}_0: G(h) \in \mathcal{G}_{\text{RLR}}} \sum_{t=1}^{T} \operatorname{Var}\left(g_t\right) + 2 \sum_{t \neq t^{\prime}} \sqrt{\operatorname{Var}\left(g_t\right) \operatorname{Var}\left(g_{t^{\prime}}\right)} \quad \text{s.t.} \quad B_h h + B_z (T - 1 - h) \leq B,
$$
通过求解上述问题,团队推导出了最优子链长度 $h^*$ 的解析解,并在主流硬件配置(如8张V100 GPU,总内存约30-40GB)下进行了验证。实验发现,h=2 是一个工程上的“黄金值”。在这个设置下,半阶子链足以捕获扩散过程的关键尺度信息,将梯度方差降至饱和区间。若盲目地将 h 增加到3或4,单步训练时间会从1.61分钟急剧增加到5.65甚至9.23分钟,但奖励分数的提升却微乎其微,性价比极低。
坚实的理论保证
RLR优化器并非简单的工程技巧,其背后有完备的理论支撑。研究团队严格证明了RLR估计器的无偏性,这意味着其梯度估计在期望上是准确的,不会像截断BP那样引入系统性偏差。
定理 6.3 (RLR的无偏性). RLR估计量是一个无偏估计量:
$$
\nabla_{\theta} \mathbb{E}[R(\phi_{1:T}(x_T; \theta))] = \mathbb{E}_{z_{1:T}, j \sim U(1, T-h)} \left[ D_{\theta}^{\top} \phi_1(x_1, z_1; \theta) \frac{d R(x_0)}{d x_0} - R(x_0) D_{\theta}^{\top} \phi_{j:j+h}(x_{j+h}, z_{j:j+h}; \theta) \nabla_z \ln f(z_j) - \sum_{i \in C} R(x_i) \nabla_z \ln f(z_i) \right].
$$
同时,团队还给出了其方差上界和收敛速率的理论分析,确保了优化过程的稳定性和效率。
定理 6.4 (收敛速率). 假设奖励函数 $R(\cdot)$ 是 L-光滑的。通过适当地选择步长,RLR的收敛速率由下式给出:
$$
\frac{1}{K+1} \sum_{k=0}^{K} \mathbb{E}\left[\left\|\nabla R\left(\theta_k\right)\right\|^2\right] \leq \sqrt{\frac{8 L \Delta_0 \sigma_{\mathrm{RLR}}^2}{K+1}}+\frac{2 L \Delta_0}{K+1},
$$
其中 $K$ 是迭代次数,$\theta_k$ 是第 $k$ 次迭代的可训练参数,$\Delta_0 = |R(\theta_0) - R^*|$ 是初始性能与最优性能之间的差距。
惊艳的实验表现
理论的美好需要实践的检验。研究团队在文本到图像(Text2Image)和文本到视频(Text2Video)两大核心任务上进行了全面实验,对比了DDPO、AlignProp、VADER等主流方法。
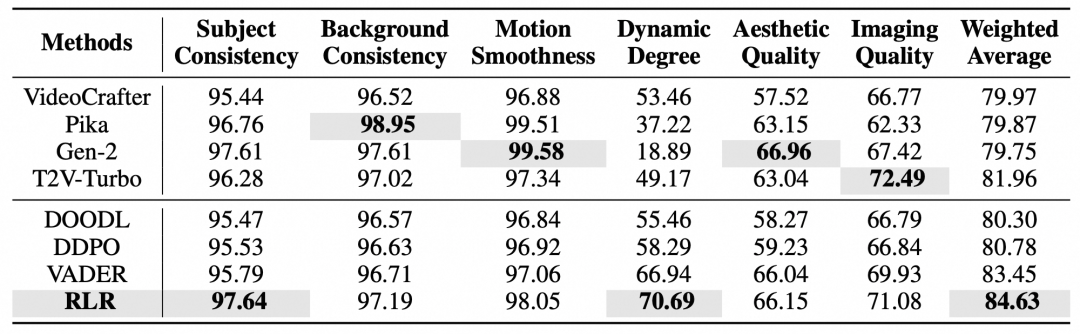
文本到图像任务:在Pick-a-Pic和HPD v2数据集上,使用Stable Diffusion 1.4和2.1作为基座模型,RLR在PickScore、HPSv2、AES、ImageReward等所有人类偏好评估指标上均全面领先。例如,在HPD v2数据集上,RLR将SD 1.4的ImageReward分数从基线的32.90提升至76.55,显著优于DDPO(52.06)和AlignProp(67.18)。
文本到视频任务:在VBench基准测试中,RLR在主体一致性、背景一致性、运动平滑度、动态程度等6个核心指标上表现卓越,加权平均分数达到 84.63。尤其是在衡量视频动作幅度的“动态程度”指标上,RLR取得了70.69的高分,大幅超越了其他对比方法。
扩散思维链:挖掘RLR潜力的提示词技术
为了进一步释放RLR优化器的潜力,团队还配套提出了一种“扩散思维链”(Diffusion Chain-of-Thought)提示词技术。其思路是将一个复杂的生成提示(如“一只在碎石上的手”)分解为粗粒度、中粒度、细粒度的多尺度提示序列。
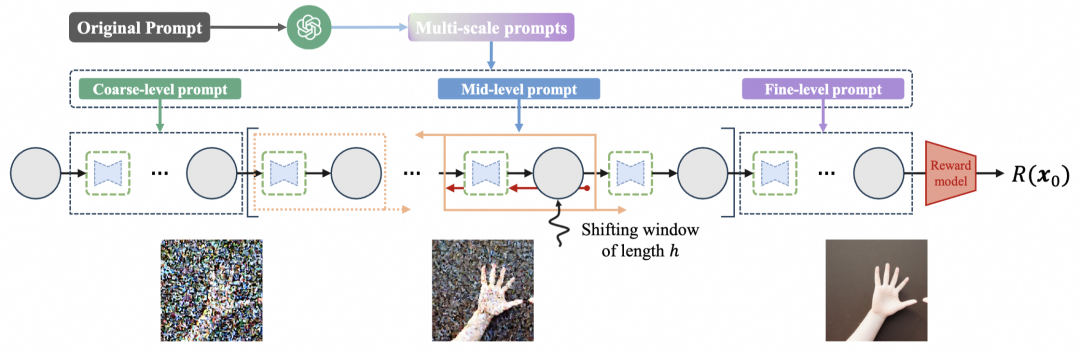
RLR的半阶估计模块(滑动窗口)可以精准地对齐这些不同尺度的提示,在训练过程中针对特定尺度的生成缺陷进行梯度更新。这项技术在手部生成等需要高度细节和一致性的困难任务上,带来了显著的性能提升。
总结与展望
北京大学彭一杰团队提出的RLR优化器,通过创新的半阶梯度估计范式,为扩散模型的后训练提供了一个高效、稳定且理论完备的解决方案。它巧妙地平衡了内存开销与梯度估计精度,一举解决了传统截断BP的偏差问题和RL方法的高方差难题。
这项工作的意义不仅在于其优异的实验性能,更在于它为深度学习模型,特别是生成模型的高效优化打开了新思路。随着模型规模的持续增长,此类能够定量权衡计算资源与模型性能的优化技术,其价值将愈发凸显。对相关领域感兴趣的朋友,可以访问 云栈社区 的智能与数据板块,了解更多前沿技术与深度讨论。
 发表于 2026-3-10 13:21:49
|
查看: 207|
回复: 0
发表于 2026-3-10 13:21:49
|
查看: 207|
回复: 0
